
Es gibt viele Artikel, in denen erklärt wird, wozu Python GIL (The Global Interpreter Lock) dient (ich meine CPython). Kurz gesagt, die GIL verhindert, dass sauberer Multithread-Python-Code mehrere Prozessorkerne verwendet.
Wir bei Vaex führen jedoch die meisten rechenintensiven Aufgaben in C ++ mit deaktivierter GIL aus. Dies ist bei Hochleistungs-Python-Bibliotheken üblich, bei denen Python nur als Klebstoff auf hoher Ebene fungiert.
Die GIL muss explizit deaktiviert werden, und es liegt in der Verantwortung des Programmierers, die er vergessen kann, was zu einer ineffizienten Kapazitätsauslastung führt. Vor kurzem war ich selbst in der Rolle des Vergesslichen und habe in Apache Arrow ein ähnliches Problem gefunden (Dies ist eine Vaex-Abhängigkeit. Wenn die GIL in Arrow nicht deaktiviert ist, tritt bei uns (und allen anderen) ein Leistungseinbruch auf.)
Wenn Sie mit 64 Kernen arbeiten, ist die Vaex-Leistung manchmal alles andere als ideal. Möglicherweise werden 4000% der CPU anstelle von 6400% verwendet, was für mich nicht geeignet ist. Anstatt zufällig Schalter einzufügen, um diesen Effekt zu untersuchen, möchte ich verstehen, was passiert, und wenn das Problem in der GIL liegt, möchte ich verstehen, warum und wie es Vaex verlangsamt.
Warum schreibe ich das?
Ich plane, eine Reihe von Artikeln zu schreiben, die einige der Tools und Techniken zum Profilieren und Verfolgen von Python mit nativen Erweiterungen behandeln und erläutern, wie diese Tools kombiniert werden können, um die Python-Leistung bei aktivierter und deaktivierter GIL zu analysieren und zu visualisieren.
Hoffentlich wird dies dazu beitragen, die Ablaufverfolgung, Profilerstellung und andere Leistungsmessungen im Sprachökosystem sowie die Leistung des gesamten Python-Ökosystems zu verbessern.
Bedarf
Linux
Sie benötigen Root-Zugriff auf den Linux-Computer (sudo ist ausreichend). Oder bitten Sie Ihren Systemadministrator, die folgenden Befehle für Sie auszuführen. Für den Rest dieses Artikels sind Benutzerrechte ausreichend.
Perf
Stellen Sie sicher, dass Sie perf installiert haben, zum Beispiel unter Ubuntu. Sie können dies folgendermaßen tun:
$ sudo yum install perf
Kernel-Konfiguration
Als Benutzer ausführen:
# Enable users to run perf (use at own risk)
$ sudo sysctl kernel.perf_event_paranoid=-1
# Enable users to see schedule trace events:
$ sudo mount -o remount,mode=755 /sys/kernel/debug
$ sudo mount -o remount,mode=755 /sys/kernel/debug/tracing
Python-Pakete
Wir werden VizTracer und per4m verwenden
$ pip install "viztracer>=0.11.2" "per4m>=0.1,<0.2"
Verfolgen Sie den Zustand von Threads und Prozessen mit perf
Es gibt keine Möglichkeit, den Status der GIL in Python herauszufinden (außer die Verwendung von Polling ), da es dafür keine API gibt. Wir können den Status vom Kernel aus überwachen, und dafür benötigen wir das Perf- Tool .
Mit seiner Hilfe (auch als perf_events bekannt) können wir auf Änderungen im Status von Prozessen und Threads warten (wir sind nur an Schlaf und Ausführung interessiert) und diese protokollieren. Perf mag einschüchternd aussehen, aber es ist ein mächtiges Werkzeug. Wenn Sie mehr darüber erfahren möchten, empfehle ich, den Artikel von Julia Evans oder Brendan Greggs Website zu lesen .
Um sich einzuschalten, wenden wir zunächst perf auf ein einfaches Programm an :
import time
from threading import Thread
def sleep_a_bit():
time.sleep(1)
def main():
t = Thread(target=sleep_a_bit)
t.start()
t.join()
main()
Wir hören nur auf wenige Ereignisse, um den Lärm zu reduzieren (beachten Sie die Verwendung von Platzhaltern):
$ perf record -e sched:sched_switch -e sched:sched_process_fork \
-e 'sched:sched_wak*' -- python -m per4m.example0
[ perf record: Woken up 2 times to write data ]
[ perf record: Captured and wrote 0,032 MB perf.data (33 samples) ]
Und wir werden den Befehl perf script verwenden, um ein lesbares Ergebnis auszugeben, das zum Parsen geeignet ist.
Versteckter Text
$ perf script
:3040108 3040108 [032] 5563910.979408: sched:sched_waking: comm=perf pid=3040114 prio=120 target_cpu=031
:3040108 3040108 [032] 5563910.979431: sched:sched_wakeup: comm=perf pid=3040114 prio=120 target_cpu=031
python 3040114 [031] 5563910.995616: sched:sched_waking: comm=kworker/31:1 pid=2502104 prio=120 target_cpu=031
python 3040114 [031] 5563910.995618: sched:sched_wakeup: comm=kworker/31:1 pid=2502104 prio=120 target_cpu=031
python 3040114 [031] 5563910.995621: sched:sched_waking: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563910.995622: sched:sched_wakeup: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563910.995624: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=R+ ==> next_comm=kworker/31:1 next_pid=2502104 next_prio=120
python 3040114 [031] 5563911.003612: sched:sched_waking: comm=kworker/32:1 pid=2467833 prio=120 target_cpu=032
python 3040114 [031] 5563911.003614: sched:sched_wakeup: comm=kworker/32:1 pid=2467833 prio=120 target_cpu=032
python 3040114 [031] 5563911.083609: sched:sched_waking: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563911.083612: sched:sched_wakeup: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563911.083613: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=R ==> next_comm=ksoftirqd/31 next_pid=198 next_prio=120
python 3040114 [031] 5563911.108984: sched:sched_waking: comm=node pid=2446812 prio=120 target_cpu=045
python 3040114 [031] 5563911.109059: sched:sched_waking: comm=node pid=2446812 prio=120 target_cpu=045
python 3040114 [031] 5563911.112250: sched:sched_process_fork: comm=python pid=3040114 child_comm=python child_pid=3040116
python 3040114 [031] 5563911.112260: sched:sched_wakeup_new: comm=python pid=3040116 prio=120 target_cpu=037
python 3040114 [031] 5563911.112262: sched:sched_wakeup_new: comm=python pid=3040116 prio=120 target_cpu=037
python 3040114 [031] 5563911.112273: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
python 3040116 [037] 5563911.112418: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112450: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112473: sched:sched_wake_idle_without_ipi: cpu=31
swapper 0 [031] 5563911.112476: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
python 3040114 [031] 5563911.112485: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
python 3040116 [037] 5563911.112485: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112489: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112496: sched:sched_switch: prev_comm=python prev_pid=3040116 prev_prio=120 prev_state=S ==> next_comm=swapper/37 next_pid=0 next_prio=120
swapper 0 [031] 5563911.112497: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
python 3040114 [031] 5563911.112513: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
swapper 0 [037] 5563912.113490: sched:sched_waking: comm=python pid=3040116 prio=120 target_cpu=037
swapper 0 [037] 5563912.113529: sched:sched_wakeup: comm=python pid=3040116 prio=120 target_cpu=037
python 3040116 [037] 5563912.113595: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563912.113620: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
swapper 0 [031] 5563912.113697: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
Schauen Sie sich die vierte Spalte an (Zeit in Sekunden): Das Programm ist eingeschlafen (eine Sekunde vergangen). Hier sehen wir den Eingang zum Schlafzustand:
python 3040114 [031] 5563911.112513: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
Dies bedeutet, dass der Kernel den Status des Python-Threads in
S
(= Sleeping) geändert hat .
Eine Sekunde später erwachte das Programm:
swapper 0 [031] 5563912.113697: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
Um zu verstehen, was passiert, müssen Sie natürlich die Werkzeuge sammeln. Ja, das Ergebnis kann auch einfach mit per4m analysiert werden , aber bevor wir fortfahren, möchte ich den Ablauf eines etwas komplexeren Programms mit VizTracer visualisieren .
VizTracer
Es ist ein Python-Tracer, der die Arbeit eines Programms in einem Browser visualisieren kann. Wenden wir es auf ein komplexeres Programm an :
import threading
import time
def some_computation():
total = 0
for i in range(1_000_000):
total += i
return total
def main():
thread1 = threading.Thread(target=some_computation)
thread2 = threading.Thread(target=some_computation)
thread1.start()
thread2.start()
time.sleep(0.2)
for thread in [thread1, thread2]:
thread.join()
main()
Das Ergebnis der Tracer-Operation:
$ viztracer -o example1.html --ignore_frozen -m per4m.example1 Loading finish Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1.html ... Dumping trace data to json, total entries: 94, estimated json file size: 11.0KiB Generating HTML report Report saved.
So sieht der resultierende HTML-Code aus:
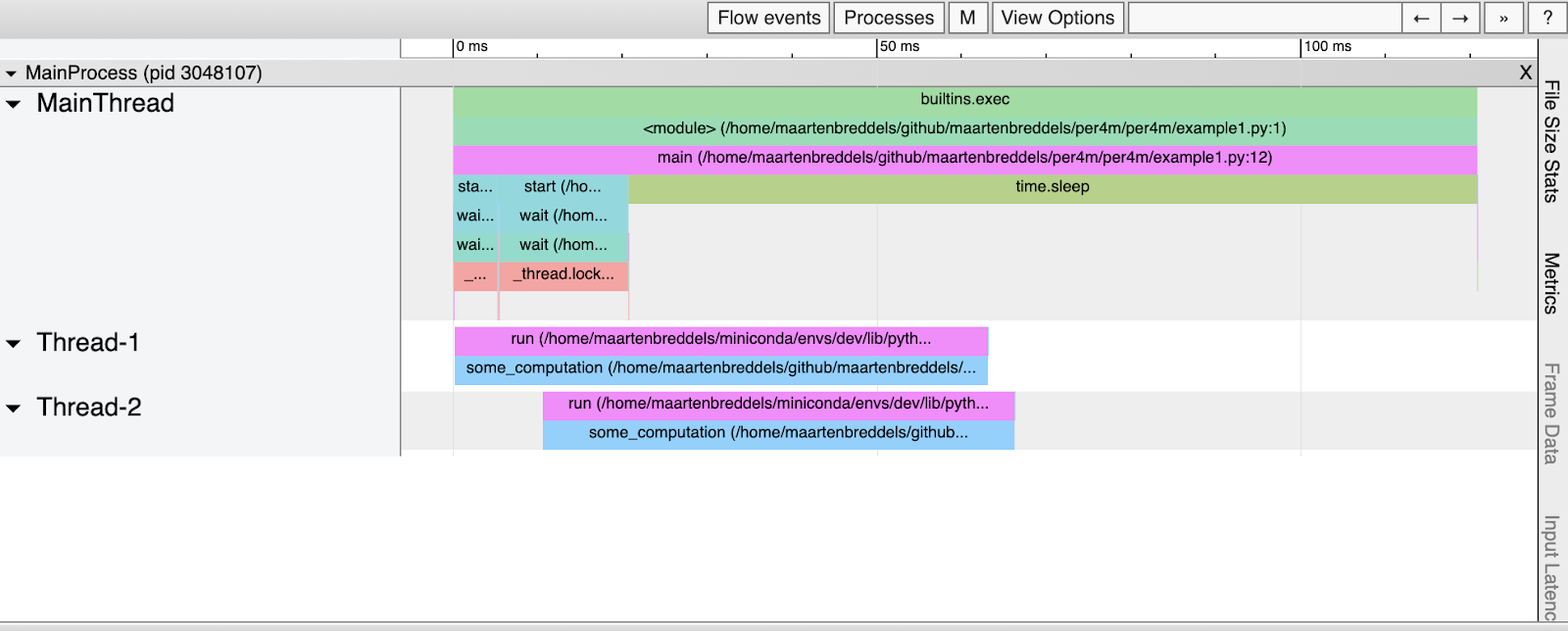
Es scheint
some_computation
parallel (zweimal) ausgeführt worden zu sein, obwohl wir wissen, dass die GIL dies verhindert. Was ist hier los?
Kombination von VizTracer- und Perf-Ergebnissen
Wenden wir perf wie in example0.py an. Fügen Sie erst jetzt ein Argument hinzu
-k CLOCK_MONOTONIC
, um dieselbe Uhr wie VizTracer zu verwenden, und bitten Sie es, JSON anstelle von HTML zu generieren:
$ perf record -e sched:sched_switch -e sched:sched_process_fork -e 'sched:sched_wak*' \
-k CLOCK_MONOTONIC -- viztracer -o viztracer1.json --ignore_frozen -m per4m.example1
Wir verwenden dann per4m, um die Ergebnisse des Perf-Skripts in JSON zu konvertieren, das VizTracer lesen kann:
$ perf script | per4m perf2trace sched -o perf1.json
Wrote to perf1.json
Kombinieren wir nun mit VizTracer die beiden JSON-Dateien:
$ viztracer --combine perf1.json viztracer1.json -o example1_state.html Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1.html ... Dumping trace data to json, total entries: 131, estimated json file size: 15.4KiB Generating HTML report Report saved.
Folgendes haben wir:
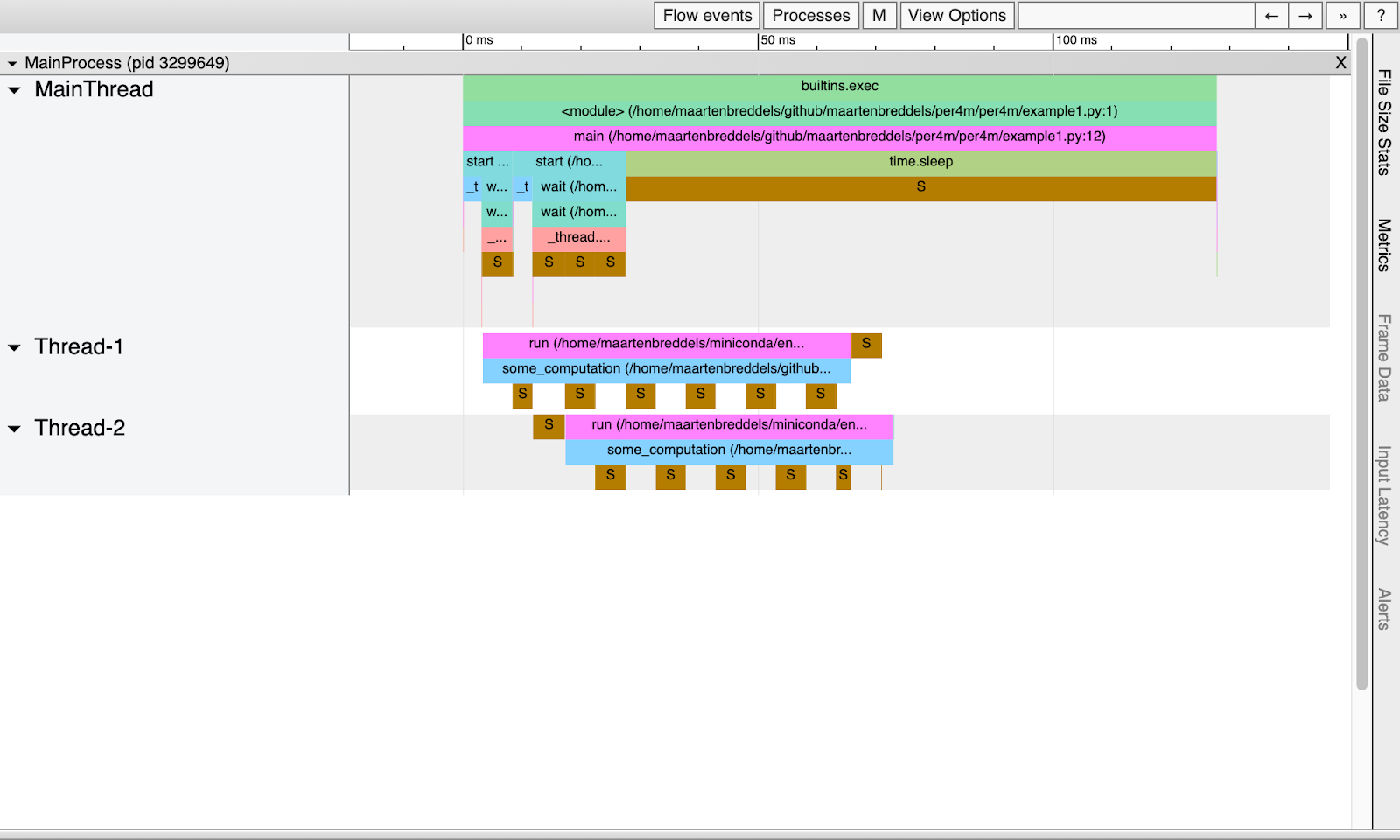
Offensichtlich schlafen Threads aufgrund der GIL regelmäßig und laufen nicht parallel.
Hinweis : Die Ruhephase ist ungefähr 5 ms lang, was dem Standardintervall von sys.getswitch entspricht
GIL-Definition
Unser Prozess geht in den Ruhezustand, aber wir sehen keinen Unterschied zwischen den Schlafzuständen, die durch einen Anruf
time.sleep
oder die GIL ausgelöst werden . Es gibt verschiedene Möglichkeiten, den Unterschied zu erkennen. Schauen wir uns zwei davon an.
Durch die Stapelverfolgung
Mit Hilfe
perf record -g
(oder besser mit
perf record --call-graph dwarf
, das impliziert
-g
) erhalten wir die Stapelspuren für jedes Perf-Ereignis.
$ perf record -e sched:sched_switch -e sched:sched_process_fork -e 'sched:sched_wak*'\
-k CLOCK_MONOTONIC --call-graph dwarf -- viztracer -o viztracer1-gil.json --ignore_frozen -m per4m.example1
Loading finish
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/viztracer1-gil.json ...
Dumping trace data to json, total entries: 94, estimated json file size: 11.0KiB
Report saved.
[ perf record: Woken up 3 times to write data ]
[ perf record: Captured and wrote 0,991 MB perf.data (164 samples) ]
Wenn wir uns das Ergebnis des Perf-Skripts ansehen (das wir aus Leistungsgründen hinzugefügt haben
--no-inline
), erhalten wir viele Informationen. Schauen Sie sich das Statusänderungsereignis an , es stellt sich heraus, dass take_gil aufgerufen wurde !
Versteckter Text
$ perf script --no-inline | less
...
viztracer 3306851 [059] 5614683.022539: sched:sched_switch: prev_comm=viztracer prev_pid=3306851 prev_prio=120 prev_state=S ==> next_comm=swapper/59 next_pid=0 next_prio=120
ffffffff96ed4785 __sched_text_start+0x375 ([kernel.kallsyms])
ffffffff96ed4785 __sched_text_start+0x375 ([kernel.kallsyms])
ffffffff96ed4b92 schedule+0x42 ([kernel.kallsyms])
ffffffff9654a51b futex_wait_queue_me+0xbb ([kernel.kallsyms])
ffffffff9654ac85 futex_wait+0x105 ([kernel.kallsyms])
ffffffff9654daff do_futex+0x10f ([kernel.kallsyms])
ffffffff9654dfef __x64_sys_futex+0x13f ([kernel.kallsyms])
ffffffff964044c7 do_syscall_64+0x57 ([kernel.kallsyms])
ffffffff9700008c entry_SYSCALL_64_after_hwframe+0x44 ([kernel.kallsyms])
7f4884b977b1<a href="https://www.maartenbreddels.com/cdn-cgi/l/email-protection"> [email protected]@GLIBC_2.3.2+0x271 (/usr/lib/x86_64-linux-gnu/libpthread-2.31.so)
55595c07fe6d take_gil+0x1ad (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfaa0b3 PyEval_RestoreThread+0x23 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c000872 lock_PyThread_acquire_lock+0x1d2 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe71f3 _PyMethodDef_RawFastCallKeywords+0x263 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe7313 _PyCFunction_FastCallKeywords+0x23 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d657 call_function+0x3b7 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6b00 _PyFunction_FastCallKeywords+0x520 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6b00 _PyFunction_FastCallKeywords+0x520 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060ae4 _PyEval_EvalFrameDefault+0x3f4 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c074e5d builtin_exec+0x33d (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe7078 _PyMethodDef_RawFastCallKeywords+0xe8 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe7313 _PyCFunction_FastCallKeywords+0x23 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c066c39 _PyEval_EvalFrameDefault+0x6549 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb77e0 _PyEval_EvalCodeWithName+0xc80 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6b62 _PyFunction_FastCallKeywords+0x582 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060ae4 _PyEval_EvalFrameDefault+0x3f4 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb81e2 PyEval_EvalCode+0x22 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0c51d1 run_mod+0x31 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0cf31d PyRun_FileExFlags+0x9d (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0cf50a PyRun_SimpleFileExFlags+0x1ba (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0d05f0 pymain_main+0x3e0 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0d067b _Py_UnixMain+0x3b (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
7f48849bc0b2 __libc_start_main+0xf2 (/usr/lib/x86_64-linux-gnu/libc-2.31.so)
55595c075100 _start+0x28 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
…
Hinweis : Wird auch genannt
pthread_cond_timedwait
und wird von https://github.com/sumerc/gilstats.py für eBPF verwendet, wenn Sie an anderen Mutexen interessiert sind.
Noch ein Hinweis : Beachten Sie, dass es hier keine Python-Stack-Ablaufverfolgung gibt, sondern dass wir
_PyEval_EvalFrameDefault
mehr haben. In Zukunft möchte ich schreiben, wie ein Stack-Trace eingefügt wird.
Das Konvertierungstool
per4m perf2trace
versteht dies und generiert ein anderes Ergebnis, wenn der Trace Folgendes enthält
take_gil
:
$ perf script --no-inline | per4m perf2trace sched -o perf1-gil.json
Wrote to perf1-gil.json
$ viztracer --combine perf1-gil.json viztracer1-gil.json -o example1-gil.html
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1.html ...
Dumping trace data to json, total entries: 131, estimated json file size: 15.4KiB
Generating HTML report
Report saved.
Wir bekommen:
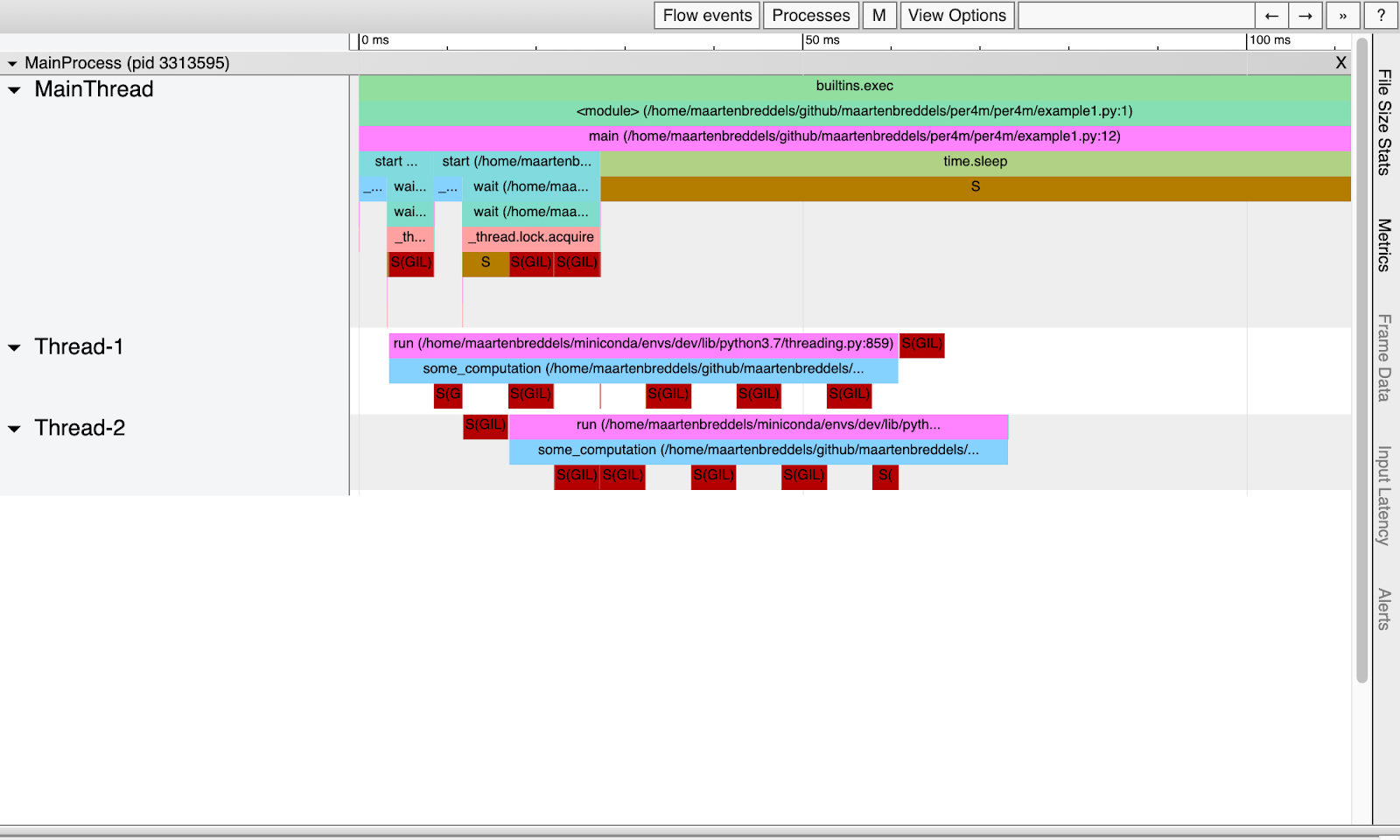
Jetzt können wir genau sehen, wo die GIL ins Spiel kommt!
Durch Sondieren (kprobes / uprobes)
Wir wissen , wann Prozesse schlafen gehen (aufgrund der GIL oder aus anderen Gründen), aber wenn Sie mehr wissen möchten , wenn das GIL ein- oder ausgeschaltet ist, dann müssen Sie wissen , wenn die Ergebnisse sind aufgerufen und zurückgekehrt
take_gil
und
drop_gil
. Diese Spur kann durch Prüfen mit perf erhalten werden. In einer Benutzerumgebung sind Probes Uprobes, die analog zu kprobes sind und, wie Sie vielleicht vermutet haben, in der Kernelumgebung funktionieren. Auch hier ist Julia Evans eine großartige Quelle für zusätzliche Informationen .
Installieren Sie 4 Sonden:
sudo perf probe -f -x `which python` python:take_gil=take_gil
sudo perf probe -f -x `which python` python:take_gil=take_gil%return
sudo perf probe -f -x `which python` python:drop_gil=drop_gil
sudo perf probe -f -x `which python` python:drop_gil=drop_gil%return
Added new events:
python:take_gil (on take_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
python:take_gil_1 (on take_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:take_gil_1 -aR sleep 1
Failed to find "take_gil%return",
because take_gil is an inlined function and has no return point.
Added new event:
python:take_gil__return (on take_gil%return in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:take_gil__return -aR sleep 1
Added new events:
python:drop_gil (on drop_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
python:drop_gil_1 (on drop_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:drop_gil_1 -aR sleep 1
Failed to find "drop_gil%return",
because drop_gil is an inlined function and has no return point.
Added new event:
python:drop_gil__return (on drop_gil%return in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:drop_gil__return -aR sleep 1
Es gibt einige Beschwerden, und wegen der Inline diejenigen
drop_gil
,
take_gil
mehr Sonden / Ereignisse wurden hinzugefügt (das heißt, wird die Funktion mehrmals in der Binärdatei dargestellt), aber alles funktioniert.
Hinweis : Ich hatte möglicherweise Glück, dass meine Python-Binärdatei (von conda-forge) so kompiliert wurde, dass das entsprechende
take_gil
/
drop_gil
(und ihre Ergebnisse) erfolgreich zur Lösung dieses Problems beitrug .
Bitte beachten Sie, dass Sonden die Leistung nicht beeinträchtigen und den Code nur dann in einem anderen Zweig ausführen, wenn sie "aktiv" sind (z. B. wenn wir sie von perf aus überwachen). Während der Überwachung werden die betroffenen Seiten für den überwachten Prozess kopiert und an den richtigen Stellen Kontrollpunkte eingefügt(INT3 für x86-Prozessoren). Der Checkpoint löst ein Ereignis für Perf mit geringem Aufwand aus. Wenn Sie die Sonden entfernen möchten, führen Sie den folgenden Befehl aus:
$ sudo perf probe --del 'python*'
Jetzt kennt perf neue Ereignisse, die es abhören kann. Lassen Sie es uns also noch einmal mit einem zusätzlichen Argument ausführen
-e 'python:*gil*'
:
$ perf record -e sched:sched_switch -e sched:sched_process_fork -e 'sched:sched_wak*' -k CLOCK_MONOTONIC \
-e 'python:*gil*' -- viztracer -o viztracer1-uprobes.json --ignore_frozen -m per4m.example1
Hinweis : Wir haben es entfernt
--call-graph dwarf
, andernfalls ist perf nicht rechtzeitig und wir verlieren Ereignisse.
Dann konvertieren wir es mit per4m perf2trace in JSON, was für VizTracer verständlich ist, und erhalten gleichzeitig neue Statistiken.
$ perf script --no-inline | per4m perf2trace gil -o perf1-uprobes.json
...
Summary of threads:
PID total(us) no gil% has gil% gil wait%
-------- ----------- ----------- ------------ -------------
3353567* 164490.0 65.9 27.3 6.7
3353569 66560.0 0.3 48.2 51.5
3353570 60900.0 0.0 56.4 43.6
High 'no gil' is good, we like low 'has gil',
and we don't want 'gil wait'. (* indicates main thread)
...
Wrote to perf1-uprobes.json
Der Unterbefehl
per4m perf2trace gil
gibt als Ergebnis auch gil_load an . Daraus erfahren wir, dass beide Threads erwartungsgemäß etwa die Hälfte der Zeit auf die GIL warten.
Mit derselben perf.data-Datei, die von perf aufgezeichnet wurde, können wir auch Informationen über den Status eines Threads oder Prozesses generieren. Da wir jedoch ohne Stack-Traces ausgeführt wurden, wissen wir nicht, ob der Prozess aufgrund der GIL geschlafen hat oder nicht.
$ perf script --no-inline | per4m perf2trace sched -o perf1-state.json
Wrote to perf1-state.json
Lassen Sie uns abschließend alle drei Ergebnisse zusammenfassen:
$ viztracer --combine perf1-state.json perf1-uprobes.json viztracer1-uprobes.json -o example1-uprobes.html Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1-uprobes.html ... Dumping trace data to json, total entries: 10484, estimated json file size: 1.2MiB Generating HTML report Report saved.
VizTracer gibt eine gute Vorstellung davon, wer die GIL hatte und wer darauf gewartet hat:

Über jedem Thread wird geschrieben, wann der Thread oder Prozess auf die GIL wartet und wann sie eingeschaltet ist (markiert als LOCK). Beachten Sie, dass sich diese Zeiträume mit Zeiträumen überschneiden, in denen der Thread oder Prozess aktiv ist (ausgeführt wird!). Beachten Sie auch, dass nur ein Thread oder Prozess im laufenden Zustand angezeigt wird, wie dies aufgrund der GIL der Fall sein sollte.
Die Zeit zwischen Aufrufen
take_gil
, dh zwischen Sperren (und damit zwischen dem Schlafen oder Aufwachen), ist genau die gleiche wie in der obigen Tabelle in der Spalte gil wait%. Die GIL-Einschaltdauer für jeden Thread mit der Bezeichnung LOCK entspricht der Zeit in der Spalte gil%.
Kraken loslassen ... ghm, GIL
Wir haben gesehen, wie die GIL bei einem reinen Python-Programm mit Multithreading die Leistung einschränkt, indem nur jeweils ein Thread oder Prozess ausgeführt wird (natürlich für einen Python-Prozess und möglicherweise in Zukunft für einen (Sub-) Interpreter). . Nun wollen wir sehen, was passiert, wenn Sie die GIL deaktivieren, wie es beim Ausführen von NumPy-Funktionen passiert.
Das zweite Beispiel wird ausgeführt,
some_numpy_computation
das die NumPy-Funktion M = 4 Mal parallel auf zwei Threads aufruft, während der Hauptthread reinen Python-Code ausführt.
import threading
import time
import numpy as np
N = 1024*1024*32
M = 4
x = np.arange(N, dtype='f8')
def some_numpy_computation():
total = 0
for i in range(M):
total += x.sum()
return total
def main(args=None):
thread1 = threading.Thread(target=some_numpy_computation)
thread2 = threading.Thread(target=some_numpy_computation)
thread1.start()
thread2.start()
total = 0
for i in range(2_000_000):
total += i
for thread in [thread1, thread2]:
thread.join()
main()
Anstatt dieses Skript mit perf und VizTracer auszuführen, verwenden wir ein Dienstprogramm
per4m giltracer
, das alle oben genannten Schritte automatisiert. Sie wird es ein bisschen schlauer machen. Grundsätzlich führen wir perf zweimal aus, einmal ohne Stack-Trace und das zweite Mal damit, und importieren das Modul / Skript, bevor wir seine Hauptfunktion ausführen, um einen uninteressanten Trace wie denselben Import zu entfernen. Dies geschieht schnell genug, damit wir keine Ereignisse verlieren.
$ giltracer --state-detect -o example2-uprobes.html -m per4m.example2 ...
Streams insgesamt:
PID total(us) no gil% has gil% gil wait%
-------- ----------- ----------- ------------ -------------
3373601* 1359990.0 95.8 4.2 0.1
3373683 60276.4 84.6 2.2 13.2
3373684 57324.0 89.2 1.9 8.9
High 'no gil' is good, we like low 'has gil',
and we don't want 'gil wait'. (* indicates main thread)
...
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example2-uprobes.html ...
...
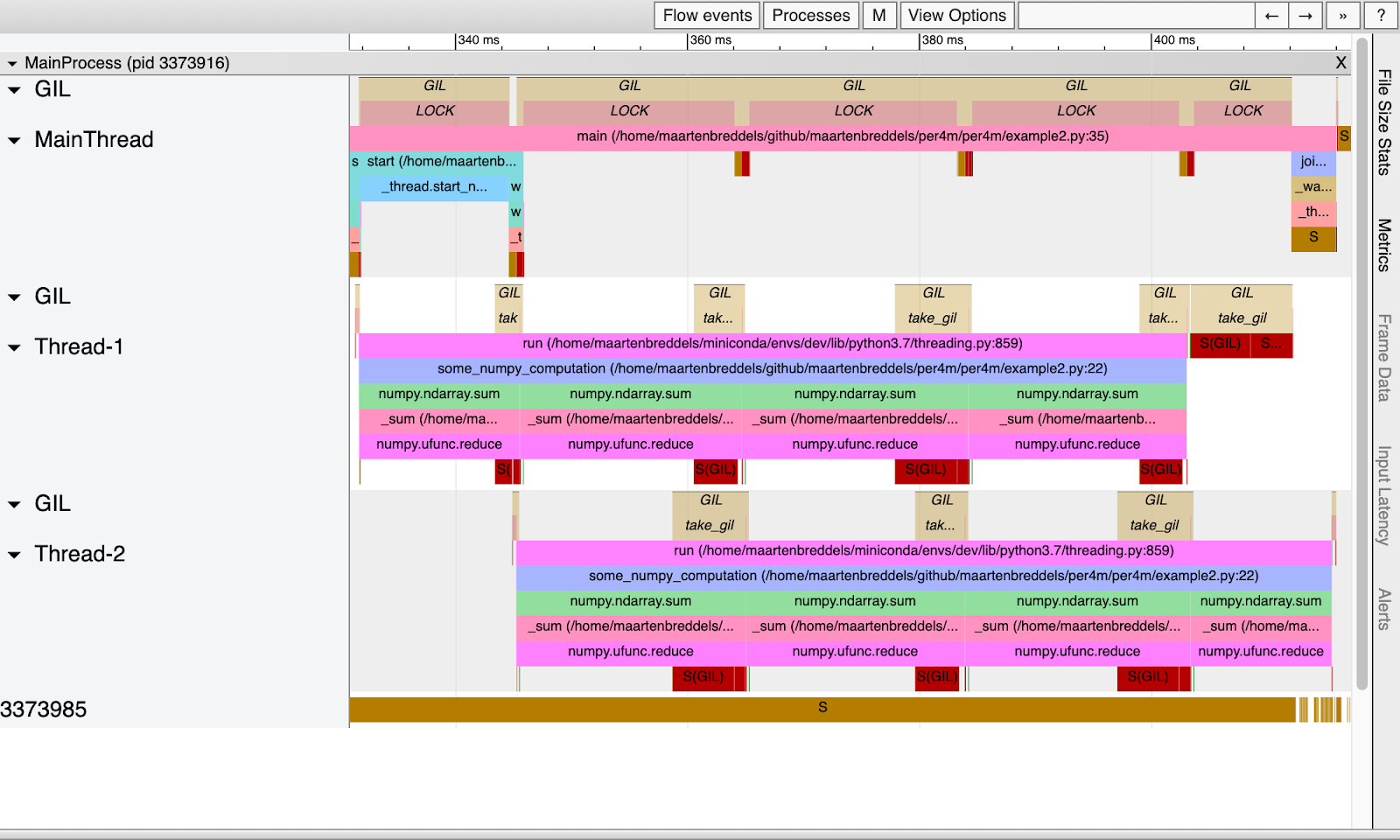
Obwohl der Hauptthread Python-Code ausführt (GIL ist dafür aktiviert, was mit dem Wort LOCK bezeichnet wird), werden auch andere Threads parallel ausgeführt. Beachten Sie, dass im reinen Python-Beispiel ein Thread oder Prozess gleichzeitig ausgeführt wird. Und hier werden tatsächlich drei Threads parallel ausgeführt. Dies ist möglich, weil die in C / C ++ / Fortran enthaltenen NumPy-Routinen die GIL deaktiviert haben.
Die GIL wirkt sich jedoch weiterhin auf Threads aus, da bei der Rückkehr der NumPy-Funktion zu Python die GIL erneut abgerufen werden muss, wie in den langen Blöcken zu sehen ist
take_gil
. Dies dauert 10% der Zeit jedes Threads.
Jupyter-Integration
Da in meinem Workflow häufig ein MacBook ausgeführt wird (das nicht perf ausführt, aber dtrace unterstützt), das remote mit einem Linux-Computer verbunden ist, verwende ich Jupyter-Notebook, um Code remote auszuführen. Und da ich ein Jupyter-Entwickler bin, musste ich einen Wrapper mit machen
cell magic
.
# this registers the giltracer cell magic
%load_ext per4m
%%giltracer
# this call the main define above, but this can also be a multiline code cell
main()
Saving report to /tmp/tmpvi8zw9ut/viztracer.json ...
Dumping trace data to json, total entries: 117, estimated json file size: 13.7KiB
Report saved.
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0,094 MB /tmp/tmpvi8zw9ut/perf.data (244 samples) ]
Wait for perf to finish...
perf script -i /tmp/tmpvi8zw9ut/perf.data --no-inline --ns | per4m perf2trace gil -o /tmp/tmpvi8zw9ut/giltracer.json -q -v
Saving report to /home/maartenbreddels/github/maartenbreddels/fastblog/_notebooks/giltracer.html ...
Dumping trace data to json, total entries: 849, estimated json file size: 99.5KiB
Generating HTML report
Report saved.
Download giltracer.html
Öffnen Sie giltracer.html in einem neuen Tab (funktioniert möglicherweise aus Sicherheitsgründen nicht).
Fazit
Mit perf können wir den Status von Prozessen oder Threads bestimmen, um zu verstehen, für welchen von ihnen die GIL in Python aktiviert ist. Mithilfe von Stapelspuren können Sie feststellen, dass die GIL die Ursache für den Schlaf war und nicht
time.sleep
zum Beispiel.
Durch die Kombination von Uprobes mit perf können Sie den Aufruf und die Rückgabe von Funktionsergebnissen verfolgen
take_gil
und
drop_gil
noch mehr Einblick in die Auswirkungen der GIL auf Ihr Python-Programm erhalten.
Unsere Arbeit wird durch das experimentelle per4m-Paket erleichtert, das das Perf-Skript in das JSON-Format VizTracer konvertiert, sowie durch einige Orchestrierungswerkzeuge.
Viel Bukaf, nicht gemeistert
Wenn Sie nur die Auswirkungen der GIL sehen möchten, führen Sie dies einmal aus:
sudo yum install perf
sudo sysctl kernel.perf_event_paranoid=-1
sudo mount -o remount,mode=755 /sys/kernel/debug
sudo mount -o remount,mode=755 /sys/kernel/debug/tracing
sudo perf probe -f -x `which python` python:take_gil=take_gil
sudo perf probe -f -x `which python` python:take_gil=take_gil%return
sudo perf probe -f -x `which python` python:drop_gil=drop_gil
sudo perf probe -f -x `which python` python:drop_gil=drop_gil%return
pip install "viztracer>=0.11.2" "per4m>=0.1,<0.2"
Anwendungsbeispiel:
# module
$ giltracer per4m/example2.py
# script
$ giltracer -m per4m.example2
# add thread/process state detection
$ giltracer --state-detect -m per4m.example2
# without uprobes (in case that fails)
$ giltracer --state-detect --no-gil-detect -m per4m.example2
Zukunftspläne
Ich wünschte, ich müsste diese Tools nicht entwickeln. Hoffentlich konnte ich jemanden dazu inspirieren, bessere Produkte als meine zu entwickeln. Ich möchte mich auf das Schreiben von Hochleistungscode konzentrieren. Ich habe jedoch solche Pläne für die Zukunft:
- Suchen Sie in VizTracer nach einem Leistungsmesser, um Cache-Fehler oder Prozessausfallzeiten zu ermitteln.
- Implementieren Sie Python-Stack-Trace in Perf-Traces, um ihn mit Tools wie http://www.brendangregg.com/offcpuanalysis.html zu kombinieren
- Wiederholen Sie dieselbe Übung mit dtrace, um sie unter macOS zu verwenden.
- Ermitteln Sie automatisch, welche C-Funktionen die GIL nicht deaktivieren ( https://github.com/vaexio/vaex/pull/1114 , https://github.com/apache/arrow/pull/7756 ).
- , https://github.com/h5py/h5py/issues/1516