 Es ist praktisch, eine Seite aus einem Reisepass, eine Visitenkarte eines Kollegen, eine Vereinbarung mit einer Bank oder einen Scheck aus einem Restaurant auf einem Smartphone zu fotografieren. Wichtige Dokumente sind immer griffbereit und können gedruckt oder versendet werden. Es wird jedoch immer schwieriger, die benötigten Dateien schnell in der Handygalerie zu finden. In der Regel sammeln Benutzer eine ganze Sammlung von Memes und Bildern mit Katzen, gemischt mit Fotos von Stromrechnungen, SNILS usw. Mitarbeiter von Unternehmen, beispielsweise Feldmanager einer Bank oder einer Anwaltskanzlei, haben ähnliche Situationen. Nur anstelle von Bildern von Fotzen - Hunderte von Fotos von Kundenvereinbarungen und anderen Dokumenten. Wie finde ich die erforderliche Kopie, um sie an Kollegen im Büro zu senden, oder wie drucke ich ein Foto eines Führerscheins im richtigen Maßstab und nicht im gesamten A4? Wir müssen basteln.
Es ist praktisch, eine Seite aus einem Reisepass, eine Visitenkarte eines Kollegen, eine Vereinbarung mit einer Bank oder einen Scheck aus einem Restaurant auf einem Smartphone zu fotografieren. Wichtige Dokumente sind immer griffbereit und können gedruckt oder versendet werden. Es wird jedoch immer schwieriger, die benötigten Dateien schnell in der Handygalerie zu finden. In der Regel sammeln Benutzer eine ganze Sammlung von Memes und Bildern mit Katzen, gemischt mit Fotos von Stromrechnungen, SNILS usw. Mitarbeiter von Unternehmen, beispielsweise Feldmanager einer Bank oder einer Anwaltskanzlei, haben ähnliche Situationen. Nur anstelle von Bildern von Fotzen - Hunderte von Fotos von Kundenvereinbarungen und anderen Dokumenten. Wie finde ich die erforderliche Kopie, um sie an Kollegen im Büro zu senden, oder wie drucke ich ein Foto eines Führerscheins im richtigen Maßstab und nicht im gesamten A4? Wir müssen basteln.
Es ist viel einfacher, alle diese Aufgaben mit einer Anwendung auszuführen. Aus diesem Grund haben wir ABBYY FineScanner AI aktualisiert . Jetzt kann er Fotos aus der Smartphone-Galerie automatisch in 7 Gruppen von Dokumenten sortieren und durch Textabfragen schnell nach den erforderlichen Fotos suchen.
Heute werden wir Ihnen ausführlich erklären, wie wir jede dieser Funktionen erstellt haben, welche Technologien wir verwendet haben und wie das ABBYY NeoML-Framework dabei geholfen hat. Wir werden auch zeigen, wie es in der Anwendung funktioniert. Und am Ende werden wir unsere Pläne für die Entwicklung von FineScanner teilen und Ihnen einige Fragen stellen.
Stellen Sie alles in die Regale der Väter
Laut einer Studie von Appsflyer stiegen die Nutzung mobiler Geräte und das Herunterladen von Apps , einschließlich Nicht- Spielen , im Jahr 2020 sprunghaft an. Für die Remote-Zusammenarbeit benötigen Mitarbeiter nicht nur Unternehmens-Messenger, sondern auch praktische mobile Tools für eine effiziente Informationsverarbeitung, Druck, Remote-Workflow und Datenspeicherung.
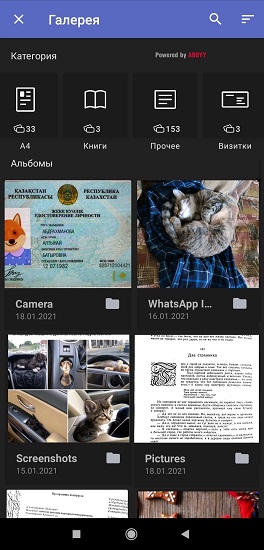
Laut Umfragen von FineScanner-Benutzern und Interviews mit ihnen werden meistens ein- und mehrseitige A4-Seiten (Verträge, Rechnungen, offizielle Briefe usw.), Pässe und Führerscheine, Bücher, Schecks und Visitenkarten mit der Anwendung gescannt. 40% der Befragten fotografieren Dokumente etwa einmal im Monat und 20% - einmal pro Woche. Basierend auf Statistiken haben wir eine Liste der Arten von Dokumenten zusammengestellt, die Benutzer am häufigsten mit einer Kamera aufnehmen und in der Smartphone-Galerie für sich selbst oder für die Arbeit speichern. Und dann haben wir FineScanner beigebracht, Fotos in Gruppen zu unterteilen. Der Prozess besteht aus zwei Phasen, findet vollständig im Hintergrund statt und erfordert keine Internetverbindung.
einer). FineScanner klassifiziert zuerst Fotos aus der Benutzergalerie
Nach dem ersten Start der Anwendung und dem Erhalt aller Berechtigungen des Benutzers analysieren die integrierten neuronalen Netze automatisch Fotos auf dem Smartphone und verteilen sie in 7 Kategorien: A4-Format, Bücher, Visitenkarten, Ausweise, Quittungen, handgeschriebenen Text und "Andere" (Plakate, Postkarten werden in diesem Ordner gespeichert, Farbmagazine usw.).

Unser neuronales Netzwerk in der ABBYY NeoML-Engine , über das wir in Habré ausführlich gesprochen haben, arbeitet an der intelligenten Klassifizierung von Bildern . Der Mechanismus besteht aus zwei neuronalen Netzen: Das erste erkennt das Vorhandensein von Text im Bild, das zweite bestimmt die Art der Dokumente. Die Netzwerkarchitektur basiert auf MobilenetV3-Blöcken.
Für uns war es wichtig, handschriftliche Dokumente von gedruckten zu trennen, daher unterteilt das erste Raster die Dateien in drei Klassen:
- Bild mit handgeschriebenem Text,
- Bild mit gedrucktem Text,
- Bild ohne Text (Katzen, Selfies und die Umwelt).
Im ersten Raster haben wir zusätzlich Informationen zum mittleren Zuschnitt (ein Teil des Bildes aus der Mitte, in hoher Auflösung zugeschnitten) verwendet, um das Vorhandensein von Text im Bild zu bestimmen. Wir haben genau so einen Ausschnitt gemacht, weil in dem Beispiel (wir werden weiter unten darüber sprechen) auf allen Fotos der Text hauptsächlich im zentralen Teil war. Dieses Bild wird zusammen mit der Miniaturansicht einem separaten Zweig des Netzwerks zugeführt und hilft bei der Entscheidung, ob das Bild Text enthält oder nicht.
Das zweite Raster definiert die Dokumenttypen:
- A4-Dokument (mit einigen Zeichnungen),
- 4 ( , — , ),
- ( - ),
- ( , , ),
- ,
- ID (, .) – , ,
- ( . ).
Der Datensatz zum Trainieren neuronaler Netze wurde von unseren Mitarbeitern gesammelt und markiert. Die Stichprobe bestand aus etwa 40.000 Fotos (Visitenkarten, Flyer, Bankkarten, Zertifikate, Versicherungen usw.), die mit einem Smartphone aufgenommen wurden.
Aufgrund des neuronalen Netzwerks hat das Gewicht der Anwendung unwesentlich zugenommen - nur um 3 MB. Wir haben speziell versucht, das neuronale Netzwerk kompakt zu machen. Ich wollte die Anwendung nicht zu sehr aufblähen, um solch eine etwas "experimentelle" Funktion zu erhalten.
2). Nach der Klassifizierung wird der Text auf den gefundenen Fotos von Dokumenten erkannt.
Zu diesem Zweck verwenden wir unsere ABBYY Mobile Capture SDK-Technologie , die sowohl in TextGrabber für OCR- oder Videosequenzen als auch in Business Card Reader für die Verarbeitung von Visitenkarten funktioniert . FineScanner hat dieses SDK bereits für die schnelle Offline-Dokumentenerkennung verwendet. Diesmal haben wir es in vollen Zügen genutzt: Es kann Text in Tausenden von Bildern erkennen. Natürlich versuchen wir es vorsichtig und vorsichtig zu machen, damit der Prozess das Gerät nicht lädt und den Akku nicht verschlingt. Darüber hinaus haben wir beschlossen, die in die Cloud hochgeladenen Fotos des Benutzers vorerst nicht herunterzuladen, sondern nur die lokal auf dem Gerät verfügbaren Fotos zu verarbeiten.
Die Gesamtzeit für die gesamte Verarbeitung der Galerie hängt von der Anzahl der Fotos und Dokumente sowie von der Generierung des Telefons ab und beträgt zum ersten Mal durchschnittlich 10 bis 30 Minuten. In Zukunft werden nur neue Fotos gescannt, und es wird bereits viel weniger davon geben, nicht Tausende von Stücken.
Suchen Sie ein Dokument anhand seines Textes
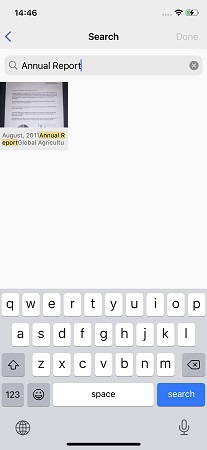 Das Sortieren von Bildern nach Typ ist eine gute Sache, aber was ist, wenn sich Hunderte von Bildern im Ordner "Bücher" befinden, Sie aber eines finden müssen, beispielsweise ein würziges Shakshuka-Rezept, das aus einer seltenen kulinarischen Enzyklopädie stammt? Oder finden Sie im A4-Ordner einen vor zwei Jahren unterzeichneten Mietvertrag?
Das Sortieren von Bildern nach Typ ist eine gute Sache, aber was ist, wenn sich Hunderte von Bildern im Ordner "Bücher" befinden, Sie aber eines finden müssen, beispielsweise ein würziges Shakshuka-Rezept, das aus einer seltenen kulinarischen Enzyklopädie stammt? Oder finden Sie im A4-Ordner einen vor zwei Jahren unterzeichneten Mietvertrag?
In solchen Fällen haben wir FineScanner beigebracht, wie der Text des Dokuments durchsucht wird. Darüber hinaus wurde die Option mit der Suche nach einer genauen Abfrage Wort für Wort sofort verworfen. In der Regel ist es nicht schwierig, auf gut fotografierten Dokumenten nach Text zu suchen, aber in der Galerie eines Smartphones kann alles vorhanden sein - stark gedrehte oder unscharfe Fotos. Es ist nicht schwierig, die sogenannte "klare Suche" danach zu organisieren, aber die Ergebnisse werden traurig sein. Groß- und Kleinschreibung (mit Großbuchstaben) kann und sollte natürlich ignoriert werden, aber es gibt beispielsweise Rechtschreibfehler von Benutzern beim Schreiben einer Anfrage.
Damit die Anwendung dieses Fehlerspektrum verschluckt, haben wir eine "Fuzzy-Suche" durchgeführt. Sie wollten keine eigene vollwertige Suchmaschine schreiben, also schauten sie sich die vorhandenen Ansätze und Bibliotheken an. Um unser Problem zu lösen, kam der gute Diff-Algorithmus Eugene Myers (Myers Diff-Algorithmus).
Der Diff-Algorithmus wird nicht zum Suchen verwendet, sondern zum Vergleichen von zwei Texten oder zwei Versionen desselben Dokuments.
Sie haben die fertige Implementierung von hier übernommen . Es stimmt, ich musste die Berechnung des Levenshtein-Abstands zwischen der Suchabfrage und dem gefundenen Teilstring hinzufügen und die Schwellenwerte so auswählen, dass es keine völlig wilden Optionen gab. Dadurch funktioniert unsere Textsuche klar, schnell und in Echtzeit.
AR-Lineal in der iOS-Version oder wie man die Größe eines Dokuments bestimmt, ohne mit einem Tamburin zu tanzen
 Bei der Entwicklung neuer Funktionen in FineScanner haben wir die Wünsche der Benutzer berücksichtigt. Beispielsweise müssen sie häufig Dokumente nicht nur in den üblichen Größen (A4, A5, A6, Visitenkarte), sondern auch in nicht standardmäßigen Dokumenten drucken: Broschüren, Flyer, SNILS usw. Und beim Drucken solcher Dateien treten Schwierigkeiten auf entstehen: Zum Beispiel wird das Foto auf den gesamten A4 gestreckt, obwohl die ursprünglichen Proportionen unterschiedlich sind.
Bei der Entwicklung neuer Funktionen in FineScanner haben wir die Wünsche der Benutzer berücksichtigt. Beispielsweise müssen sie häufig Dokumente nicht nur in den üblichen Größen (A4, A5, A6, Visitenkarte), sondern auch in nicht standardmäßigen Dokumenten drucken: Broschüren, Flyer, SNILS usw. Und beim Drucken solcher Dateien treten Schwierigkeiten auf entstehen: Zum Beispiel wird das Foto auf den gesamten A4 gestreckt, obwohl die ursprünglichen Proportionen unterschiedlich sind.
Die gängigsten Dokumentgrößen können aus einer vorgefertigten Liste im Anhang ausgewählt werden. Es gibt 8 Arten davon. Alle anderen - Postkarten, Visa usw. - kann jetzt automatisch gemessen werden. Zu diesem Zweck haben wir ARKit (Line in Augmented Reality) in die neue Version von FineScanner für iOS integriert. Für die Entwicklung haben wir die Apple API in Verbindung mit unserem Crop-Modul ABBYY Mobile Capture SDK verwendet, mit dem Sie Dokumentgrenzen auch auf weißem Hintergrund definieren und vervollständigen können, wenn sie von Hand geschlossen werden. Das Lineal bestimmt die physische Größe des Dokuments, um es in den Eigenschaften anzugeben und es beim Drucken auf einem Drucker korrekt auf Papier anzuzeigen.
So funktioniert es:
Wie unsere Geschäftskunden FineScanner nutzen
Unsere B2C-Kunden werden als erste die neue Funktionalität ausprobieren, und Unternehmen werden die Anwendung etwas später verwenden. Dies ist hauptsächlich auf strenge Sicherheitsrichtlinien für Unternehmen zurückzuführen.
Unsere Kunden aus großen Unternehmen verwenden ihre Versionen von ABBYY FineScanner unter der Kontrolle verschiedener MDM-Plattformen (Mobile Device Management, dh Lösungen, mit denen Sie die Schutzstufen von Unternehmensinformationen vor unbefugtem Zugriff und unbefugtem Vertrieb konfigurieren und feststellen können, ob Auf einem mobilen Gerät gespeicherte Informationen stehen für Anwendungen von Drittanbietern zur Verfügung. Beispielsweise verwenden PwC-Auditing- oder Unternehmensberatungsmitarbeiter einen mobilen Scannerzur schnellen Digitalisierung von Dokumenten. Während der Audits fotografieren sie beispielsweise Verträge oder Bestellungen in nur wenigen Sekunden, konvertieren sie in durchsuchbare PDF-Dateien und senden sie zur zusätzlichen Überprüfung und Datenanalyse an Unternehmens-Repositories.
Für die Bequemlichkeit unserer Kunden bereiten wir jetzt die Veröffentlichung einer Version von FineScanner mit Unterstützung für die beliebtesten MDM-Systeme vor - Microsoft InTune, Mobile Iron, Workspace One und andere.
Für die Zukunft
Wir hoffen, dass der aktualisierte FineScanner dazu beiträgt, das Digitalisieren und Erkennen von Dokumenten und Büchern direkt auf Ihrem Smartphone zu vereinfachen sowie die benötigten Dateien in der Galerie schnell zu finden und auszudrucken.
Wir sammeln regelmäßig Benutzeranfragen für FineScanner, um zu verstehen, wie das Produkt weiterentwickelt werden kann. Laut unserer letzten Umfrage sendet die Hälfte der Benutzer fotografierte Dokumente an ihre eigene oder eine andere E-Mail und arbeitet weiterhin mit ihnen am Computer, z. B. zum Drucken oder Speichern. Darüber hinaus erwarten über 70%, dass FineScanner in ABBYY FineReader PDF integriert wird . Es wurde für uns interessant herauszufinden, was die Chabrowiten darüber denken.