Beschreibung
Tiefe neuronale Netze haben sich bei der Verarbeitung sensorischer Daten wie Bilder und Audio als effektiv erwiesen. Für tabellarische Daten sind Baummodelle jedoch beliebter. Eine gute Eigenschaft von Baummodellen ist ihre natürliche Interpretierbarkeit. In diesem Artikel stellen wir Deep Neural Decision Trees (DNDT) vor - baumartige Modelle, die von neuronalen Netzen implementiert werden. DNDT wird intern als Baum interpretiert. Da es sich jedoch auch um ein neuronales Netzwerk (NN) handelt, kann es einfach mit dem NN-Toolkit implementiert und unter Verwendung eines Gradientenabstiegsalgorithmus anstelle eines Greedy-Algorithmus (eines Greedy-Partitionierungsalgorithmus) trainiert werden. Wir bewerten DNDT anhand mehrerer tabellarischer Datensätze, testen seine Wirksamkeit und untersuchen die Ähnlichkeiten und Unterschiede zwischen DNDTs und herkömmlichen Entscheidungsbäumen. Interessant,dass DNDT sowohl auf geteilter als auch auf funktionaler Ebene selbstlernend ist.
1. Einleitung
Die Interpretierbarkeit von Vorhersagemodellen ist wichtig, insbesondere wenn es um Ethik geht - rechtliche, medizinische und finanzielle, geschäftskritische Anwendungen, bei denen wir die Relevanz des Modells manuell überprüfen möchten. Tiefe neuronale Netze (Lecun et al., 2015 [18]; Schmidhuber, 2015 [25]) haben in vielen Bereichen wie Computer Vision, Sprachverarbeitung und Sprachmodellierung hervorragende Ergebnisse erzielt. Aufgrund der mangelnden Interpretierbarkeit kann diese Modellfamilie jedoch nicht in Anwendungen als "Black Box" verwendet werden, für die wir das Prognoseverfahren kennen müssen, um den Entscheidungsprozess zu überprüfen. Darüber hinaus ist es in einigen Bereichen wie Business Intelligence (BI) oft wichtiger zu wissen, wie sich jeder Faktor auf die Prognose auswirkt, als auf die Schlussfolgerung selbst. Entscheidungsbaum (DT) -basierte Methoden wie C4.5 (Quinlan,1993 [23]) und CART (Breiman et al., 1984 [5]) haben in dieser Hinsicht einen klaren Vorteil, da die Struktur des Baumes leicht verfolgt werden kann und genau, wie die Vorhersage gemacht wird.
– (DNDT), . DNDT- , DNDT . , DNDT (NN), , DT: DNDT NN; , «» . DNDT - GPU « », NN (back-propagation).
2.
. , , . / . C4. 5 (Quinlan, 1993 [23]) CART (Breiman et al., 1984 [5]). , , . , « » (Breiman, 2001 [6]) XGBoost (Chen & Guestrin, 2016 [8]), . .
. , , , (, ) , (Weller, 2017 [26]; Doshi-Velez, 2017 [11]). , (Bostrom & Yudkowsky, 2014 [4]) , , . . - (Ribeiro et al., 2016 [24]), , , (Dash et al., 2015 [10]; Malioutov et al., 2017 [19]), (Kim et al., 2016 [15]) (Kim et al., 2017 [16]).
. . Bul & Kontschieder (2014) [7] « » ( Neural Decision Forests NDF) , . Deep-NDF (Kontschieder et al., 2015 [17]) , ( CNNs) ( ). DNDT . -, () ( ). (back propagation). -, ( ), , (≥ 2) . , , , , . , (Bul & Kontschieder, 2014 [7]; Kontschieder et al., 2015 [17]) . . , Kontschieder et al. (2015 [17]), , , .
, (2017 [2]), «» , . «» , «» , , .
. DT «» (Quinlan, 1993; Breiman et al., 1984 [23]). , «» (Norouzi et al., 2015 [20]). , , (Norouzi et al., 2015 [20]) RNN (Xiong et al., 2017 [28]). , DNDT , , , DT, SGD. , , DT ( ), DNDT , .
3.
3.1.
, , - (Dougherty et al., 1995) (), DNDT. , x , . , .
, x, N + 1 . n , . [β1, β2,…, βn] , β1 < β2 < · · · < βn. β , . , β.
softmax.
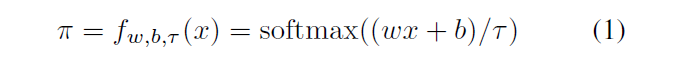
w- , , w = [1; 2; : : : ; n + 1]. b ,
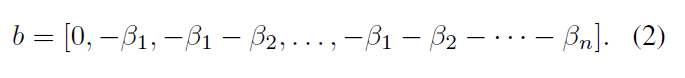
τ> 0 - . τ → 0 .
,



x

, 1 «» x, . , « » (Chung et al., 2017 [9]), , , , .
- «» ( ) , Straight-Through (ST) Gumbel-Softmax (Jang et al., 2017): , Gumbel-Max, (backward pass) Gumbel-Softmax (. Bengio (2013 [3]) .
.1 , x [0, 1] 0.33 0.66 . 1 2, o1 = x, o2 = 2x − 0.33, o3 = 3x − 0.99.
![Abbildung 1. Ein konkretes Beispiel für unsere Soft-Binning-Funktion mit Schnittpunkten bei 0,33 und 0,66. Die x-Achse ist der Wert der kontinuierlichen Eingangsvariablen x2 [0; einer]. Oben links: ursprüngliche Logit-Werte; oben rechts: Werte nach Anwendung der Softmax-Funktion mit m = 1; Unten links: t = 0,1; unten rechts: t = 0,01.](https://habrastorage.org/getpro/habr/upload_files/ab5/1bd/c1f/ab51bdc1f73be966aff6556d810533d3.PNG "Abbildung 1. Ein konkretes Beispiel für unsere Soft-Binning-Funktion mit Schnittpunkten bei 0,33 und 0,66. Die x-Achse ist der Wert der kontinuierlichen Eingangsvariablen x2 [0; einer]. Oben links: ursprüngliche Logit-Werte; oben rechts: Werte nach Anwendung der Softmax-Funktion mit m = 1; Unten links: t = 0,1; unten rechts: t = 0,01.")
3.2
, , ⊗. ,

xd fd (xd), ,
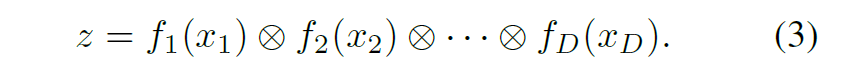
z «» , , x. , , z . DNDT . 2.
. : DNDT - , , – . : DT – , . 6 .")
3.3
. , . , (. 2, ) SGD.
. DNDT - . , - Kronecker . "" , «» (Ho, 1998 [13]) - . , . , «», : , . DNDT.
4.
4.1
DNDT ≈ 20 TensorFlow PyTorch. , DNDT " " GPU - , , .
4.2
DNDT ( TensorFlow (Abadi et al., 2015) [1]) ( Scikit-learn (Pedregosa et al., 2011 [22])) 14 , Kaggle UCI ( . . 1).
(DT) : 'gini' – 'best'. (NN) 50 . DNDT - ( ), 1 . 4.4. 12 , DNDT, 10 , 10 . .
4.3
DNDT, . 1. .2.
DT. DT , , .
) UCI: (#inst.), (#feat.) (#cl.)")
 , .")
, . DNDT , «» , . , , . , . « » (Wolpert, 1996[27]).
4.4
DNDT . , , , , xd, xd.
, DNDT. , . -Car Evaluation, Pima, Iris Haberman 1 5 , . 3. , . , DNDT : .
 , DNDT.")
, . . 4, , . , , DNDT , .
.")
4.5
DNDT , . , , DT, , - . , DNDT . DNDT 10 , - , .
- , , (, 0 iris) DNDT (. . 3 ). , DNDT , . () : , , , .
 der Fälle, in denen DNDT jede Funktion ignoriert")
4.6
, 4.5, , DNDT DT . gini (), (. 5), (.3).
 erzeugten Merkmale.")
, , DNDT DT , , Iris 3 . , , , DT 0 , DNDT . DNDT 2 , DT. . . 2, DNDT DT 70,9% 66,1% .
, DNDT DT, Tau . , .4, .

4.7 GPU
, DNDT - , DT. , , (. . 6).

5.
DNDT. , NN , . , DT, DNDT , SGD GPU. . ; DNDT , CNN, ; , SGD DNDT , «» DT ; , NN DT.
Abadi, Mart´ın, Agarwal, Ashish, Barham, Paul, Brevdo, Eugene, Chen, Zhifeng, Citro, Craig, Corrado, Greg S., Davis, Andy, Dean, Jeffrey, Devin, Matthieu, Ghemawat, Sanjay, Goodfellow, Ian, Harp, Andrew, Irving, Geoffrey, Isard, Michael, Jia, Yangqing, Jozefowicz, Rafal, Kaiser, Lukasz, Kudlur, Manjunath, Levenberg, Josh, Mane, Dandelion, Monga, Rajat, Moore, ´ Sherry, Murray, Derek, Olah, Chris, Schuster, Mike, Shlens, Jonathon, Steiner, Benoit, Sutskever, Ilya, Talwar, Kunal, Tucker, Paul, Vanhoucke, Vincent, Vasudevan, Vijay, Viegas, Fernanda, Vinyals, Oriol, Warden, Pete, Wattenberg, Martin, Wicke, Martin, Yu, Yuan, and Zheng, Xiaoqiang. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. URL https://www.tensorflow.org/.
Balestriero, R. Neural Decision Trees. ArXiv e-prints, 2017.
Bengio, Yoshua. Estimating or propagating gradients through stochastic neurons. CoRR, abs/1305.2982, 2013.
Bostrom, Nick and Yudkowsky, Eliezer. The ethics of artificial intelligence, pp. 316334. Cambridge University Press, 2014.
Breiman, L., H. Friedman, J., A. Olshen, R., and J. Stone, C. Classification and Regression Trees. Chapman & Hall, New York, 1984.
Breiman, Leo. Random forests. Machine Learning, 45(1): 5–32, October 2001.
Bul, S. and Kontschieder, P. Neural decision forests for semantic image labelling. In CVPR, 2014.
Chen, Tianqi and Guestrin, Carlos. Xgboost: A scalable tree boosting system. In KDD, 2016.
Chung, J., Ahn, S., and Bengio, Y. Hierarchical Multiscale Recurrent Neural Networks. In ICLR, 2017.
Dash, S., Malioutov, D. M., and Varshney, K. R. Learning interpretable classification rules using sequential rowsampling. In ICASSP, 2015.
Doshi-Velez, Finale; Kim, Been. Towards a rigorous science of interpretable machine learning. ArXiv e-prints, 2017.
Dougherty, James, Kohavi, Ron, and Sahami, Mehran. Supervised and unsupervised discretization of continuous features. In ICML, 1995.
Ho, Tin Kam. The random subspace method for constructing decision forests. IEEE Transactions on Pattern Analysis and Machine Intelligence, 20(8):832–844, 1998.
Jang, E., Gu, S., and Poole, B. Categorical Reparameterization with Gumbel-Softmax. In ICLR, 20
Kim, B., Gilmer, J., Viegas, F., Erlingsson, U., and Wattenberg, M. TCAV: Relative concept importance testing with Linear Concept Activation Vectors. ArXiv e-prints, 2017.
Kim, Been, Khanna, Rajiv, and Koyejo, Sanmi. Examples are not enough, learn to criticize! Criticism for interpretability. In NIPS, 2016.
Kontschieder, P., Fiterau, M., Criminisi, A., and Bul, S. R. Deep neural decision forests. In ICCV, 2015.
Lecun, Yann, Bengio, Yoshua, and Hinton, Geoffrey. Deep learning. Nature, 521(7553):436–444, 5 2015.
Malioutov, Dmitry M., Varshney, Kush R., Emad, Amin, and Dash, Sanjeeb. Learning interpretable classification rules with boolean compressed sensing. In Transparent Data Mining for Big and Small Data, pp. 95–121. Springer International Publishing, 2017.
Norouzi, Mohammad, Collins, Maxwell D., Johnson, Matthew, Fleet, David J., and Kohli, Pushmeet. Efficient non-greedy optimization of decision trees. In NIPS, 2015.
Paszke, Adam, Gross, Sam, Chintala, Soumith, Chanan, Gregory, Yang, Edward, DeVito, Zachary, Lin, Zeming, Desmaison, Alban, Antiga, Luca, and Lerer, Adam. Automatic differentiation in pytorch. In NIPS Workshop on Autodiff, 2017.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Duchesnay, E. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011.
Quinlan, J. Ross. C4.5: Programs for Machine Learning. Morgan Kaufmann Publishers Inc., 1993.
Ribeiro, Marco Tulio, Singh, Sameer, and Guestrin, Carlos. ”why should i trust you?”: Explaining the predictions of any classifier. In KDD, 2016.
Schmidhuber, J. Deep Learning in neuronalen Netzen: Ein Überblick. Neural Networks, 61: 85–117, 2015.
Weller, Adrian. Herausforderungen für Transparenz. Im ICML-Workshop zur menschlichen Interpretierbarkeit beim maschinellen Lernen, pp. 55–62, 2017.
Wolpert, David H. Das Fehlen a priori Unterscheidungen zwischen Lernalgorithmen. Neural Computation, 8 (7): 1341 & ndash; 1390, 1996.
Xiong, Zheng, Zhang, Wenpeng und Zhu, Wenwu. Entscheidungsbäume lernen mit verstärkendem Lernen. Im NIPS-Workshop zum Meta-Lernen, 2017.