Die übliche Art des Paging ist der Versatz oder die Seitenzahl. Sie stellen eine Anfrage wie folgt:
GET /api/products?page=10 {"items": [...100 products]}
und dann das:
GET /api/products?page=11 {"items": [...another 100 products]}
Bei einer einfachen Verschiebung stellt sich heraus
?offset=1000
und
?offset=1100
- die gleichen Eier, nur im Profil. Hier gehen wir entweder direkt zur SQL-Abfrage des Typs
OFFSET 1000 LIMIT 100
oder multiplizieren mit der Seitengröße (Wert
LIMIT
). Dies ist ohnehin keine optimale Lösung, da jede Datenbank diese 1000 Zeilen überspringen muss. Und um sie zu überspringen, müssen Sie sie identifizieren. Es spielt keine Rolle, ob es sich um PostgreSQL, ElasticSearch oder MongoDB handelt, es muss sie bestellen, neu berechnen und wegwerfen.
Dies ist unnötige Arbeit. Es wiederholt sich jedoch immer wieder, da dieses Design einfach zu implementieren ist. Sie ordnen Ihre API direkt einer Datenbankanforderung zu.
Was ist dann zu tun? Wir konnten sehen, wie die Datenbanken funktionieren! Sie haben das Konzept eines Cursors - es ist ein Zeiger auf eine Zeichenfolge. So können Sie die Datenbank kann sagen : „Gib mir 100 Zeilen nach hinten dies .“ Eine solche Abfrage ist für die Datenbank viel praktischer, da mit hoher Wahrscheinlichkeit eine Zeile durch ein Feld mit einem Index identifiziert wird. Und Sie müssen diese Zeilen nicht abrufen und überspringen, sondern gehen direkt daran vorbei.
Beispiel:
GET /api/products {"items": [...100 products], "cursor": "qWe"}
Die API gibt eine (undurchsichtige) Zeichenfolge zurück, mit der die nächste Seite abgerufen werden kann:
GET /api/products?cursor=qWe {"items": [...100 products], "cursor": "qWr"}
In Bezug auf die Implementierung gibt es viele Möglichkeiten. In der Regel haben Sie einige Abfragekriterien, z. B. eine Produkt-ID. In diesem Fall codieren Sie es mit einem reversiblen Algorithmus (z. B. Hash-IDs ). Und wenn Sie eine Abfrage mit einem Cursor erhalten, dekodieren Sie sie und generieren eine Abfrage wie
WHERE id > :cursor LIMIT 100
.
Kleiner Leistungsvergleich. Hier ist das Ergebnis des Offsets: Und hier ist das Ergebnis der Operation : Eine Differenz von mehreren Größenordnungen! Die tatsächlichen Zahlen hängen natürlich von der Größe der Tabelle, der Filter und der Speicherimplementierung ab. Hier ist ein großartiger Artikel
=# explain analyze select id from product offset 10000 limit 100;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Limit (cost=1114.26..1125.40 rows=100 width=4) (actual time=39.431..39.561 rows=100 loops=1)
-> Seq Scan on product (cost=0.00..1274406.22 rows=11437243 width=4) (actual time=0.015..39.123 rows=10100 loops=1)
Planning Time: 0.117 ms
Execution Time: 39.589 ms
where
=# explain analyze select id from product where id > 10000 limit 100;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
Limit (cost=0.00..11.40 rows=100 width=4) (actual time=0.016..0.067 rows=100 loops=1)
-> Seq Scan on product (cost=0.00..1302999.32 rows=11429082 width=4) (actual time=0.015..0.052 rows=100 loops=1)
Filter: (id > 10000)
Planning Time: 0.164 ms
Execution Time: 0.094 ms
Weitere technische Details finden Sie auf Folie 42 für einen Leistungsvergleich.
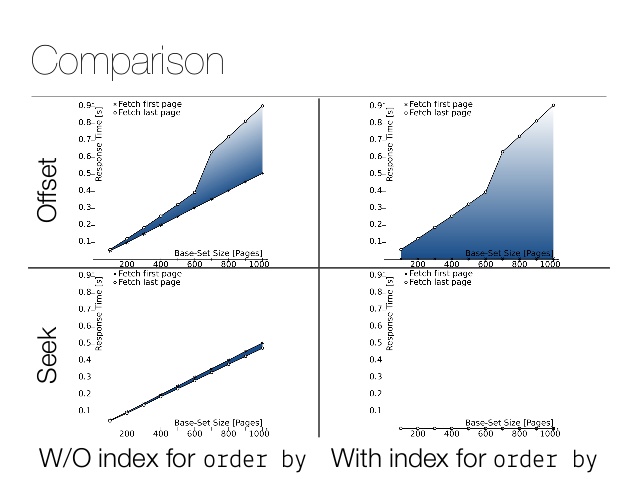
Natürlich fragt niemand Produkte nach ID ab - sie werden normalerweise nach Relevanz abgefragt (und dann nach ID als entscheidendem Parameter ). In der realen Welt erfordert die Auswahl einer Lösung die Betrachtung spezifischer Daten. Anfragen können nach Kennung sortiert werden (da sie monoton ansteigen). Auf diese Weise können auch Artikel aus der Liste zukünftiger Einkäufe sortiert werden - zum Zeitpunkt der Erstellung der Liste. In unserem Fall werden die Produkte von ElasticSearch geladen, das natürlich einen solchen Cursor unterstützt.
Der Nachteil ist, dass Sie mit der zustandslosen API keinen Link zur vorherigen Seite erstellen können. Bei der Benutzerpaginierung führt kein Weg an diesem Problem vorbei. Wenn es also wichtig ist, Schaltflächen für die vorherige / nächste Seite und "Direkt zu Seite 10 gehen" zu haben, müssen Sie die alte Methode verwenden. In anderen Fällen kann die By-Cursor-Methode die Leistung erheblich verbessern, insbesondere bei sehr großen Tabellen mit sehr tiefer Paginierung.