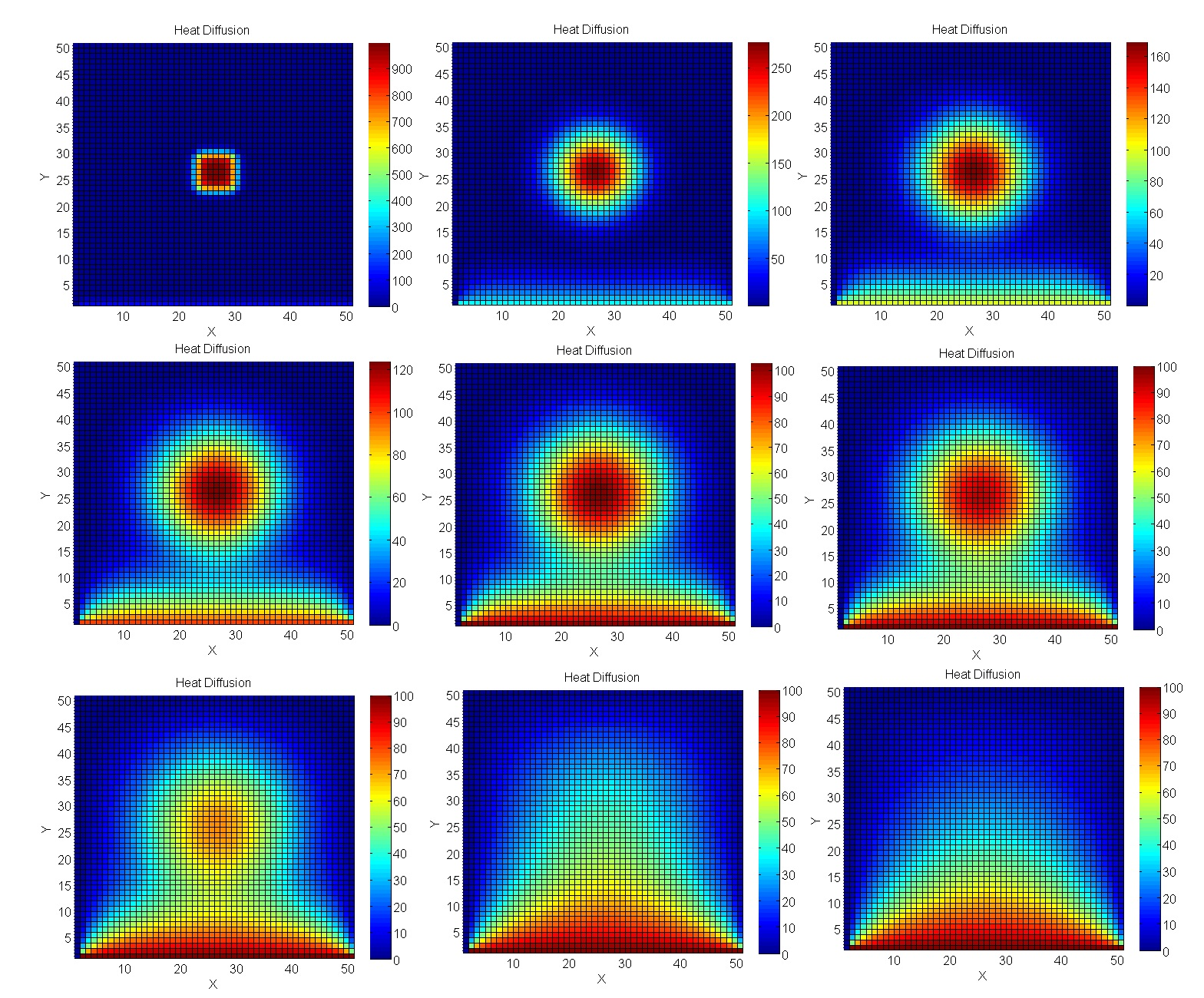

Erhitzen wir Metallplatten auf der GPU
Jeder weiß, dass Python nicht von selbst mit Geschwindigkeit glänzt. Meiner Meinung nach ist die Sprache in ihrer Lesbarkeit ausgezeichnet, aber die Hauptnische ihrer Anwendung besteht darin, dass Sie die meiste Zeit auf Dateneingabe / -ausgabe warten. Konventionell können Sie in Rust oder C leistungsstarken Code schreiben, aber in 99% der Fälle wird nur gewartet.
Python eignet sich jedoch auch hervorragend als syntaktischer Klebstoff auf hoher Ebene. In diesem Fall ruft sein gemächlich interpretierter Teil Hochgeschwindigkeitscode auf, der in kompilierten Programmiersprachen geschrieben ist. In der Regel werden hierfür herkömmliche Bibliotheken wie NumPy verwendet.
Wir werden jedoch noch ein wenig weiter gehen und versuchen, Berechnungen in CUDA zu parallelisieren und eine seltsame, aber funktionierende Mischung aus C ++, stdpar und dem nvc ++ - Compiler von Nvidia zu verwenden. Versuchen wir gleichzeitig, die Leistung zu bewerten. Nehmen wir zwei Probleme: Sortieren von Zahlen und die Jacobi-Methode, mit der wir die Erwärmung einer Metallplatte berechnen.
Aufruf von C ++ aus Python
Unser Sortiercode sieht folgendermaßen aus:
# distutils: language=c++
from libcpp.algorithm cimport sort
def cppsort(int[:] x):
sort(&x[0], &x[-1] + 1)
In der ersten Zeile geben wir ausdrücklich an, dass Cython C ++ und nicht das Standard-C verwenden soll. In der zweiten Zeile importieren wir die Sortierfunktion aus C ++, und dann folgt die Logik selbst. Platzieren Sie den Code in der Datei cppsort.pyx. Bitte beachten Sie, dass sich die Erweiterung von der üblichen py unterscheidet, da wir sie kompilieren oder Cythonize in der Cython-Terminologie ausführen.
Die Kompilierung kann manuell erfolgen oder in setup.py enthalten sein, wo wir die Vorbereitung unserer Umgebung vollständig beschreiben.
In setup.py sieht es so aus:
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules = cythonize("cppsort.pyx")
)
Aber wir können dies einfach über die Befehlszeile tun:
cythonize -i cppsort.pyx
Unter der Haube wird so etwas passieren:

- Cython übersetzt Python-Code in C ++ und generiert eine gültige cppsort.cpp.
- Der C ++ - Compiler (in diesem Fall g ++) kompiliert C ++ - Code in das Python-Erweiterungsmodul
- Das Python-Erweiterungsmodul wird als reguläres Python-Modul in den Code importiert.
Nach der Kompilierung können wir die Sortierung importieren und sofort testen:
from cppsort import cppsort
import numpy as np
x = np.array([4, 3, 2, 1], dtype="int32")
print(x)
cppsort(x)
print(x)
Das Array [4, 3, 2, 1] wird mit C ++ std :: sort erfolgreich nach [1, 2, 3, 4] sortiert.
Gehen wir zur GPU?
C ++ - Standardbibliotheksalgorithmen können mit dem Argument der parallelen Ausführungsrichtlinie aufgerufen werden . Dieses Argument teilt dem Compiler mit, dass Sie den Algorithmus in parallele Prozesse aufteilen möchten.
Abgesehen davon hat C ++ mehrere Optionen für diese Richtlinie:
- std :: execute :: seq: Sequentielle Ausführung. Parallelität ist verboten.
- std :: execute :: unseq: Vektorisierte Ausführung innerhalb des aufrufenden Threads.
- std :: execute :: par: Parallele Ausführung auf einem oder mehreren Threads.
- std :: execute :: par_unseq: Parallele Ausführung auf einem oder mehreren Threads. Jeder Stream wird nach Möglichkeit vektorisiert.
In diesem Fall müssen Sie den Rennzustand und den Deadlock selbst überwachen. Der Standard-G ++ - Compiler versucht, die Berechnung auf die CPU-Kerne zu verteilen. Wir können jedoch einen proprietären Compiler von Nvidia - nvc ++ - nehmen und ihm die Option "-stdpar" geben. stdpar ist Nvidias C ++ - Standardparallelität mit paralleler Codeausführung auf der GPU.
Schreiben wir den Code neu, wobei wir die Notwendigkeit berücksichtigen, eine lokale Kopie des Arrays zu erstellen, da die GPU nicht auf das Array im NumPy-Framework zugreifen kann.
from libcpp.algorithm cimport sort, copy_n
from libcpp.vector cimport vector
from libcpp.execution cimport par
def cppsort(int[:] x):
cdef vector[int] temp
temp.resize(len(x))
copy_n(&x[0], len(x), temp.begin())
sort(par, temp.begin(), temp.end())
copy_n(temp.begin(), len(x), &x[0])

Jetzt muss dies erneut kompiliert werden, aber mit nvc ++. Dieses Mal schreiben wir eine normale setup.py und nennen sie:
CC=nvc++ python setup.py build_ext --inplace
Wir importieren in den Code und versuchen aufzurufen:
x = np.array([4, 3, 2, 1], dtype="int32")
cppsort(x) # GPU
Performance
Traditionell sind GPUs gut, wenn es viele der gleichen Arten von Lightweight-Computing gibt. Schwere Aufgaben, einzelne GPU-Aufgaben funktionieren nicht. Darüber hinaus lohnt es sich, das Datenvolumen zu berücksichtigen. Wenn Sie nur wenige Daten haben, erhalten Sie einen hohen Overhead für den Parallelisierungsprozess, die E / A zwischen der CPU und der GPU. Infolgedessen wird ein solcher Code höchstwahrscheinlich auf einer nackten CPU am effizientesten ausgeführt, manchmal sogar innerhalb eines einzelnen Kerns, wenn nur sehr wenige Daten vorhanden sind. Aber auf großen Arrays wird die GPU definitiv die Nase vorn haben.
Hier gibt es einen guten Vergleich der Sortierung. Die NumPy-Geschwindigkeit wurde als Einheit genommen, und dann wurde die Vielzahl der Geschwindigkeitserhöhung bei jeder Methode relativ dazu berechnet.
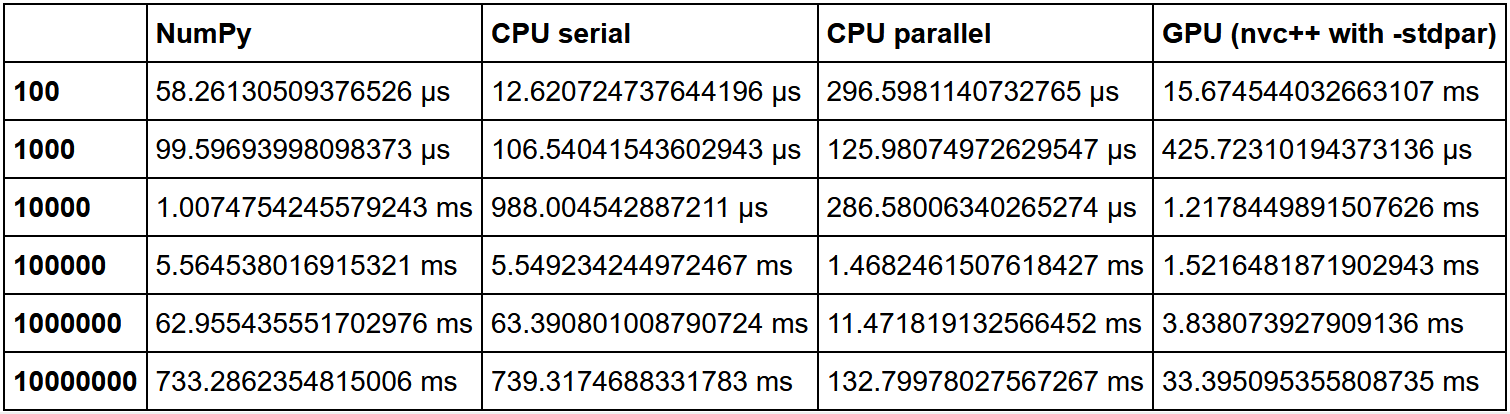
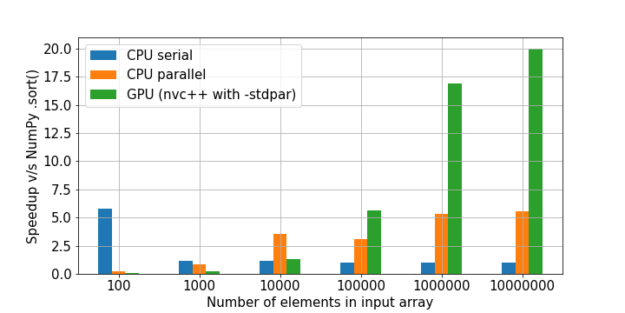
Wie wir sehen können, wird die Hypothese bestätigt, dass der Gewinn bei der Verwendung der GPU für eine große Datenmenge zunimmt.
Wir berechnen die Erwärmung der Platte
Nehmen wir ein Problem näher an die reale technische Modellierung heran - Berechnungen mit der Jacobi-Methode. Insbesondere eignen sie sich hervorragend zur Berechnung von Temperaturprozessen im 2D-Raum.
Simulationscode
"""
simulates heat equation on rectangle returning a heat map at a number of times
boundary and initial conditions are 0, source represents burner on a stove
This program is based on the script FEniCS tutorial demo program: Diffusion of a Gaussian hill.
u'= Laplace(u) + f in a square domain
u = u_D = 0 on the boundary
u = u_0 = 0 at t = 0
u_D = f = stove burner flame
This program succesfully runs in the fenics docker image, see the book Solving PDEs in Python.
to animate: convert -delay 4 -loop 100 heatequation10*.png heatstovelinn.gif
to crop:convert heatstovelinn.gif -coalesce -repage 0x0 -crop 810x810+95+15 +repage heatstovelin.gif
"""
from fenics import *
import time
import matplotlib.pyplot as plt
from matplotlib import cm
# Create mesh and define function space
nx = ny = 100
mesh = RectangleMesh(Point(-2, -2), Point(2, 2), nx, ny)
V = FunctionSpace(mesh, 'P', 1)
# Define boundary, source, initial
def boundary(x, on_boundary):
return on_boundary
bc = DirichletBC(V, Constant(0), boundary)
u_0 = interpolate(Constant(0), V)
f = Expression('exp(-sqrt(pow((a*pow(x[0], 2) + a*pow(x[1], 2)-a*1),2)))', degree=2, a=5) #steep guassian centred on the unit sphere
final_time = 0.035
num_pics = 72
for i in range(num_pics):
T = final_time*(i+1.0)/(num_pics+1) #solve time even space
#T = final_time*1.1**(i-num_pics+1) #solve time log space
num_steps = 30
dt = T / num_steps # time step size
# Define variational problem
u = TrialFunction(V)
v = TestFunction(V)
F = u*v*dx + dt*dot(grad(u), grad(v))*dx - (u_0 + dt*f)*v*dx
a, L = lhs(F), rhs(F)
# Time-stepping
u = Function(V)
t = 0
for n in range(num_steps):
t += dt #step
solve(a == L, u, bc) #solve
u_0.assign(u) #update
#plot solution
plot(u,cmap=cm.hot,vmin=0,vmax=0.07)
plt.axis('off')
plt.savefig('heatequation10%s.png'%(i+10),figsize=(8, 8), dpi=220,bbox_inches='tight', pad_inches=0,transparent=True)
Schreiben wir einen ähnlichen Löser in Cython für die nachfolgende Kompilierung mit CUDA:
# distutils: language=c++
# cython: cdivision=True
from libcpp.algorithm cimport swap
from libcpp.vector cimport vector
from libcpp cimport bool, float
from libc.math cimport fabs
from algorithm cimport for_each, any_of, copy
from execution cimport par, seq
cdef cppclass avg:
float *T1
float *T2
int M, N
avg(float* T1, float *T2, int M, int N):
this.T1, this.T2, this.M, this.N = T1, T2, M, N
inline void call "operator()"(int i):
if (i % this.N != 0 and i % this.N != this.N-1):
this.T2[i] = (
this.T1[i-this.N] + this.T1[i+this.N] + this.T1[i-1] + this.T1[i+1]) / 4.0
cdef cppclass converged:
float *T1
float *T2
float max_diff
converged(float* T1, float *T2, float max_diff):
this.T1, this.T2, this.max_diff = T1, T2, max_diff
inline bool call "operator()"(int i):
return fabs(this.T2[i] - this.T1[i]) > this.max_diff
def jacobi_solver(float[:, :] data, float max_diff, int max_iter=10_000):
M, N = data.shape[0], data.shape[1]
cdef vector[float] local
cdef vector[float] temp
local.resize(M*N)
temp.resize(M*N)
cdef vector[int] indices = range(N+1, (M-1)*N-1)
copy(seq, &data[0, 0], &data[-1, -1], local.begin())
copy(par, local.begin(), local.end(), temp.begin())
cdef int iterations = 0
cdef float* T1 = local.data()
cdef float* T2 = temp.data()
keep_going = True
while keep_going and iterations < max_iter:
iterations += 1
for_each(par, indices.begin(), indices.end(), avg(T1, T2, M, N))
keep_going = any_of(par, indices.begin(), indices.end(), converged(T1, T2, max_diff))
swap(T1, T2)
if (T2 == local.data()):
copy(seq, local.begin(), local.end(), &data[0, 0])
else:
copy(seq, temp.begin(), temp.end(), &data[0, 0])
return iterations
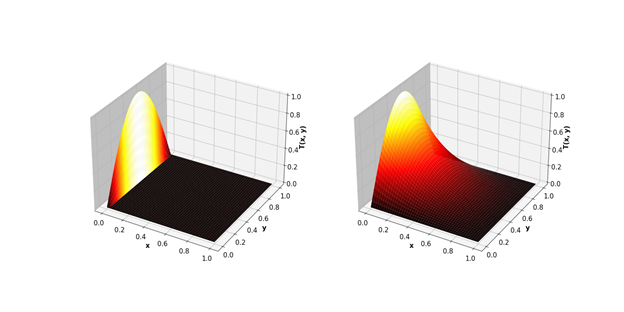

Infolgedessen ist die GPU-Lücke noch bedeutender.
Minuspunkte
- Das Schreiben dieser Art von Code ist etwas komplizierter als eine reine Python-Version und erfordert ein Verständnis der Funktionsweise von Parallel Computing auf einer GPU.
- Es ist erforderlich, Daten in ein separates Array zu kopieren, um sie auf die GPU zu übertragen, auf die die Grafikkarte keinen Zugriff hat. Dies kann bei sehr großen Arrays ein Problem sein.
