
Systeme zum Konvertieren von Textabfragen in SQL
Was sollte ein solches System können:
- Suchen Sie im Text nach Entitäten, die Datenbankentitäten entsprechen: Tabellen, Spalten, manchmal Werte.
- Tabellen verknüpfen, Formularfilter.
- Definieren Sie einen Satz zurückgegebener Daten, dh erstellen Sie eine Auswahlliste.
- Bestimmen Sie die Stichprobenreihenfolge und die Anzahl der Zeilen.
- Identifizieren Sie zusätzlich zu den relativ offensichtlichen Abhängigkeiten einige absolut implizite Abhängigkeiten oder Filter, die für alle außer den Designern des Basisschemas undurchsichtig sind (siehe die Bedingung für das Feld bonustyp im Bild oben).
- Beheben Sie Mehrdeutigkeiten bei der Auswahl von Entitäten. "Geben Sie mir Daten zu Ivanov" - sollten Sie Informationen über eine Gegenpartei oder einen Mitarbeiter mit diesem Nachnamen anfordern? Mitarbeiterdaten für Februar - Beschränken Sie die Stichprobe nach Einstellungsdatum oder Verkaufsdatum? usw.
Das heißt, im ersten Schritt müssen Sie die Abfrage genau wie bei der Arbeit mit allen anderen NLP-Systemen analysieren und dann entweder im laufenden Betrieb SQL generieren oder eine am besten geeignete Absicht finden, in deren Funktion eine zuvor vorbereitete parametrisierte SQL-Abfrage geschrieben wird. Auf den ersten Blick sieht die erste Option viel beeindruckender aus. Lassen Sie uns genauer darüber sprechen.
Die Besonderheit solcher Systeme besteht darin, dass in ihnen tatsächlich nur eine Absicht registriert ist, die für alles ausgelöst wird, was zumindest eine gewisse Beziehung zum Modell hat, mit einer Superfunktion, die SQL für alle Arten von Abfragen generiert. SQL kann basierend auf beliebigen Regeln, algorithmisch oder unter Beteiligung neuronaler Netze erstellt werden.
Algorithmen und Regeln
Auf den ersten Blick ist die Konvertierung eines analysierten Satzes in SQL ein rein algorithmisches Problem, das heißt, es kann problemlos gelöst werden. Es scheint, dass wir alles haben, was wir brauchen, um ein starkes Modell in ein anderes umzuwandeln: anerkannte Entitäten, Referenzen, Co-Referenzen usw. Leider erschweren die Nuancen und Mehrdeutigkeiten wie immer alles und machen in diesem Fall den 100% universellen Ansatz fast unwirksam. Modelle sind unvollkommen (siehe Beispiele oben und weiter unten im Artikel), Entitäten überschneiden sich sowohl in Namen als auch in ihrer Bedeutung, das Wachstum der Komplexität mit einer Zunahme der Anzahl von Entitäten und der Komplexität der Basis wird nichtlinear.
Neuronale Netze
Die Verwendung neuronaler Netze für solche Systeme ist ein sich schnell entwickelnder Bereich. Im Rahmen dieses Artikels werde ich mich auf Links und kurze Schlussfolgerungen beschränken.
Ich rate Ihnen, eine kurze Reihe von Artikeln zu lesen: 1 , 2 , 3 , 4 , 5 , sie enthalten einiges an Theorie, eine Geschichte darüber, wie Schulungen und Tests auf Qualität durchgeführt werden, einen kurzen Überblick über Lösungen. Außerdem hier - mehr über SparkNLP. Hier - zur Photon-Lösung von SalesForce. Laut der Referenz ein weiterer Vertreter der Open-Source-Community - Allennlp. Hier- Daten zur Qualität von Systemen, dh Testraten. Hier finden Sie Daten zur Verwendung von NLP-Bibliotheken und insbesondere ähnlichen Lösungen in einem Unternehmen.
Diese Richtung hat eine große Zukunft, aber auch hier mit Vorbehalten - noch nicht für alle Modelltypen. Wenn Sie bei der Arbeit mit einem Modell keine vollständig strengen Zahlen und garantierten genauen, wiederholbaren und vorhersehbaren Ergebnisse erhalten müssen (z. B. müssen Sie einen Trend bestimmen, Indikatoren vergleichen, Abhängigkeiten identifizieren usw.), ist alles in Ordnung. Der Nichtdeterminismus und die Wahrscheinlichkeit der Antworten schränken jedoch die Verwendung eines solchen Ansatzes für eine Reihe von Systemen ein.
Beispiele für die Arbeit mit Systemen, die auf neuronalen Netzen basieren
Oft zeigen Unternehmen, die Dienstleistungen dieser Art anbieten, hervorragende Ergebnisse bei gut gemachten Videos und bieten dann an, sie für ein detailliertes Gespräch zu kontaktieren. Es gibt aber auch Online-Demos im Internet. Es ist besonders praktisch, mit Photon zu experimentieren , da in diesem Fall das Basisdiagramm direkt vor Ihren Augen liegt. Die zweite Demo, die ich öffentlich gesehen habe, stammt von Allennlp. Das Parsen einiger Abfragen ist in seiner Raffinesse überraschend, einige Optionen sind etwas weniger erfolgreich. Der Gesamteindruck ist gemischt. Versuchen Sie, mit diesen Demos zu spielen, wenn Sie interessiert sind, und bilden Sie sich Ihre Meinung.
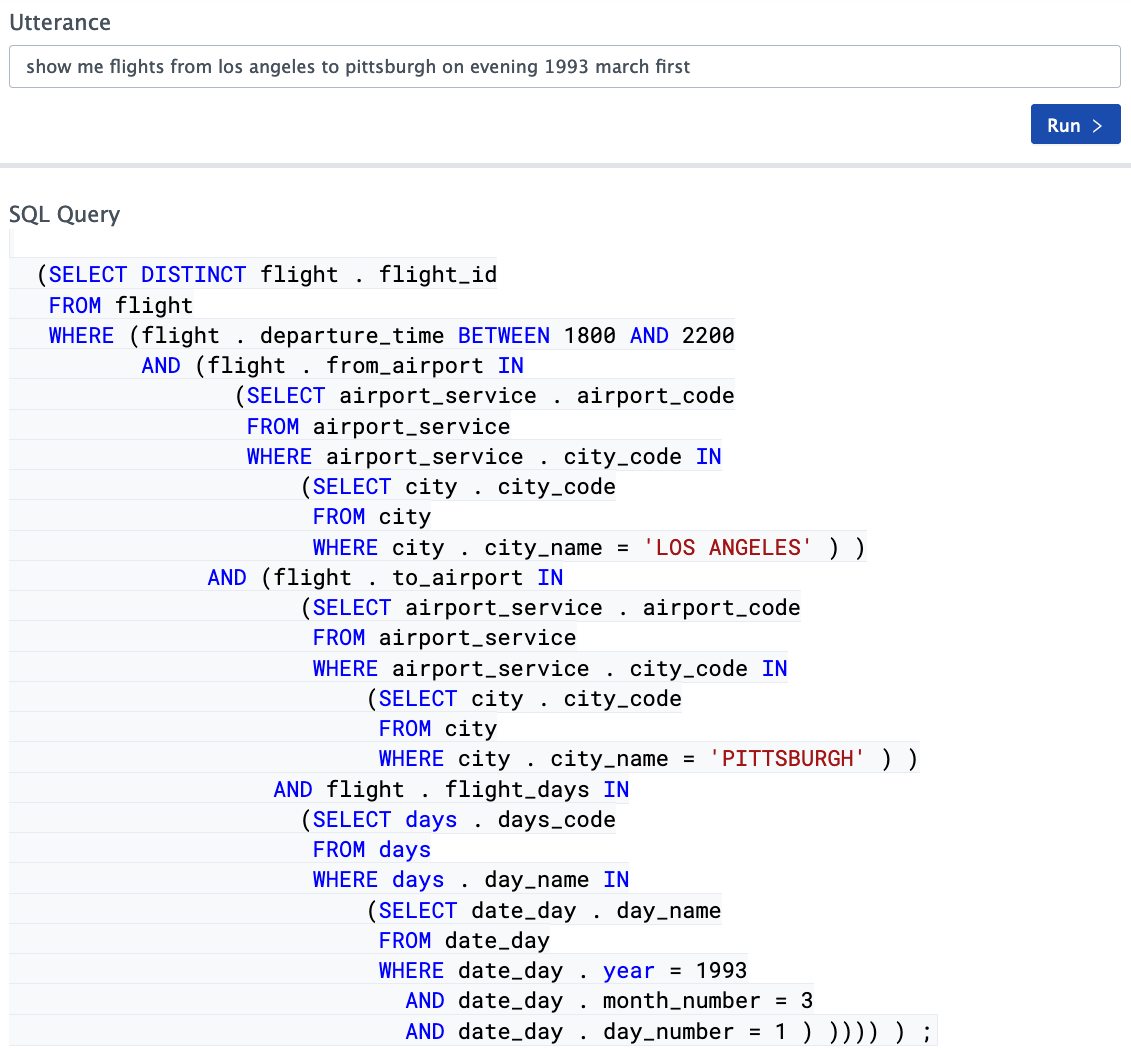
Im Allgemeinen ist die Situation sehr interessant. Systeme zur automatischen Übersetzung von unstrukturierten Textabfragen in SQL basierend auf neuronalen Netzen werden immer besser, die Qualität der bestandenen Testsätze wird immer höher, aber ihr Wert überschreitet bestenfalls 70% nicht ( Spinnen-Datensatz - heute etwa 69% der Tag). Kann dieses Ergebnis als gut angesehen werden? Aus der Sicht der Entwicklung solcher Systeme sind die Ergebnisse natürlich beeindruckend, aber es ist bei weitem nicht möglich, sie in realen Systemen ohne Modifikation für alle Arten von Aufgaben zu verwenden.
Apache NlpCraft Tools
Wie kann das Apache NlpCraft- Projekt beim Aufbau und der Organisation solcher Systeme helfen ? Wenn es keine Fragen zum ersten Teil des Problems gibt (Parsen einer Textabfrage), ist alles wie gewohnt. Für den zweiten Teil (Bildung von SQL-Abfragen basierend auf NLP-Daten) bietet NlpCraft keine 100% vollständige Lösung, sondern nur Tools, die bei der unabhängigen Lösung dieses Problems helfen ...
Wo soll ich anfangen? Wenn wir den Entwicklungsprozess so weit wie möglich automatisieren möchten, helfen uns die Metadaten des Datenbankschemas und die Daten selbst. Wir werden auflisten, welche Informationen wir aus der Datenbank extrahieren können, und der Einfachheit halber werden wir uns auf Tabellen beschränken, wir werden nicht versuchen, Trigger, gespeicherte Prozeduren usw. zu analysieren.
- — . , .
- (null / not null) (where clause).
- , foreign keys , 1:1, 1:0, 1:n, n:m. joins.
- . , , .. , select list.
- . . - — , — enumeration, . .
- . , . .
- Primary and unique keys — , , , .
- (, , Oracle) — .
- Einschränkungen überprüfen - Die Kenntnis der Einschränkungen kann dazu beitragen, dieselben Filter für diese Spalten zu erstellen.
Wenn Sie also Metadaten erhalten haben, wissen Sie bereits viel über die Entitäten des Modells. In einer idealen Welt wissen Sie beispielsweise fast alles über die folgende Tabelle:
CREATE TABLE users (
id number primary key,
first_name varchar(32) not null,
last_name varchar(64) not null unique,
birthday date null,
salary_level_id number not null foreign key on salary_level(id)
);
In Wirklichkeit wird nicht alles so rosig sein, Namen werden abgekürzt und unlesbar sein, Datentypen werden sich oft als völlig unerwartet herausstellen, und denormalisierte Felder und hastig hinzugefügte Tabellen wie 1: 0 werden hier und da verstreut. Um realistisch zu sein, können daher die meisten Datenbanken, die seit langer Zeit in Produktion sind, nur mit großer Schwierigkeit zur Erkennung von Entitäten ohne vorherige Vorbereitung verwendet werden. Dies gilt für alle Systeme und basiert auf neuronalen Netzen, vielleicht sogar mehr als andere.
In dieser Situation ist es ratsam, dem NLP-Modul Zugriff auf ein etwas verfeinertes Schema zu gewähren - einen vorbereiteten Satz von Ansichten mit den richtigen Feldnamen, einen erforderlichen und ausreichenden Satz von Tabellen und Spalten, Sicherheitsprobleme usw.
Beginnen wir mit dem Entwerfen
Die wichtigste und sehr einfache Idee ist, dass es fast unmöglich ist, alle Benutzeranforderungen abzudecken. Wenn der Benutzer ein Ziel festlegt, um das System zu täuschen, und eine Frage stellen möchte, die es verwirrt, wird er dies leicht tun. Die Aufgabe des Entwicklers besteht darin, ein Gleichgewicht zwischen den Fähigkeiten des zu entwickelnden Systems und der Komplexität seiner Implementierung herzustellen. Daher auch ein sehr einfacher Rat: Versuchen Sie nicht, eine universelle Absicht zu unterstützen, die alle Fragen beantwortet, mit einer universellen Methode, die SQL für alle diese Optionen generiert. Versuchen Sie, die 100% ige Vielseitigkeit aufzugeben. Dadurch wird das Projekt etwas weniger farbenfroh, aber realisierbarer.
- Fragen Sie die Benutzer und schreiben Sie 30-40 der häufigsten Arten von Fragen auf.
- , , , ..
- . SQL, 20-30 . , . SQL ML text2Sql, .
- . — , , , . — SQL . C — , .
Mit einem solchen Arbeitsvolumen und ausreichenden Ressourcen wird die zur Lösung eines solchen Problems erforderliche Zeit in Tagen gemessen, und am Ende haben Sie eine 80% ige Abdeckung der Benutzeranforderungen und eine relativ hohe Leistungsqualität. Kehren Sie dann zum ersten Punkt zurück und fügen Sie weitere Absichten hinzu.
Der einfachste Weg zu erklären, warum es sich lohnt, mehrere Absichten zu unterstützen, ist ein Beispiel. Fast immer interessieren sich Benutzer für eine bestimmte Anzahl von Berichten, die nicht dem Standard entsprechen, so etwas wie "Vergleiche mich so und so für so und so einen Zeitraum, aber nicht in so und so einem Zeitraum und gleichzeitig ...". Kein System kann sofort SQL für eine solche Abfrage generieren. Sie müssen sie entweder irgendwie trainieren oder solche Fälle auswählen und separat programmieren. Die Möglichkeit, auf eine begrenzte Anzahl komplexer Anfragen zu antworten, ist für Ihre Benutzer sehr wichtig. Suchen Sie erneut nach einem Gleichgewicht, nicht nach der Tatsache, dass genügend Ressourcen vorhanden sind, um alle derartigen Anforderungen zu erfüllen. Wenn Sie diese Wünsche jedoch vollständig ignorieren, wird die Funktionalität des Systems auf ein inakzeptables Maß beschränkt. Wenn Sie das richtige Verhältnis finden,Ihr System benötigt eine begrenzte Entwicklungszeit und ist nicht nur ein paar Tage lang ein lustiges Spielzeug, sondern eher ärgerlich als nützlich. Ein sehr wichtiger Punkt ist, dass Sie Absichten für knifflige Anforderungen nicht sofort, sondern nacheinander hinzufügen können. Wir haben MVP mit nur einer universellen Absicht gleichzeitig.
Toolkit und API
Apache NlpCraft bietet ein Toolkit zur Vereinfachung der Datenbankmanipulation.
Gebrauchsprozedur:
- Generieren Sie eine Modellvorlage aus der Datenbank-JDBC-URL. Wie oben erwähnt, ist es manchmal besser, eine Reihe von Ansichten mit einer „korrekteren“ Darstellung der Daten vorzubereiten und Zugriff auf diese Menge zu gewähren. Der einfachste Weg, eine Vorlage zu generieren, ist die Verwendung des CLI- Dienstprogramms . Wir starten das Dienstprogramm, geben das Datenbankschema, den JDBC-Treiber, eine Liste der verwendeten und ignorierten Tabellen und andere Parameter als Parameter an. Weitere Informationen finden Sie in der Dokumentation .
- JSON YAML , , , , .., , .
:
- id: "tbl:orders" groups: - "table" synonyms: - "orders" metadata: sql:name: "orders" sql:defaultselect: - "order_id" - "customer_id" - "employee_id" sql:defaultsort: - "orders.order_id#desc" sql:extratables: - "customers" - "shippers" - "employees" description: "Auto-generated from 'orders' table." ..... - id: "col:orders_order_id" groups: - "column" synonyms: - "{order_id|order <ID>}" - "orders {order_id|order <ID>}" - "{order_id|order <ID>} <OF> orders" metadata: sql:name: "order_id" sql:tablename: "orders" sql:datatype: 4 sql:isnullable: false sql:ispk: true description: "Auto-generated from 'orders.order_id' column."
- — , , . , . , , , , , , .. .
- Basierend auf dem Rich-Modell kann der Entwickler eine kompakte API verwenden, die die Erstellung von SQL-Abfragen in der Intent-Funktion erheblich erleichtert - siehe ein detailliertes Beispiel .
Unten finden Sie aus Gründen der Übersichtlichkeit einen Code-Ausschnitt:
@NCIntent(
"intent=commonReport " +
"term(tbls)~{groups @@ 'table'}[0,7] " +
"term(cols)~{
id == 'col:date' ||
id == 'col:num' ||
id == 'col:varchar'
}[0,7] " +
"term(condNums)~{id == 'condition:num'}[0,7] " +
"term(condVals)~{id == 'condition:value'}[0,7] " +
"term(condDates)~{id == 'condition:date'}[0,7] " +
"term(condFreeDate)~{id == 'nlpcraft:date'}? " +
"term(sort)~{id == 'nlpcraft:sort'}? " +
"term(limit)~{id == 'nlpcraft:limit'}?"
)
def onCommonReport(
ctx: NCIntentMatch,
@NCIntentTerm("tbls") tbls: Seq[NCToken],
@NCIntentTerm("cols") cols: Seq[NCToken],
@NCIntentTerm("condNums") condNums: Seq[NCToken],
@NCIntentTerm("condVals") condVals: Seq[NCToken],
@NCIntentTerm("condDates") condDates: Seq[NCToken],
@NCIntentTerm("condFreeDate") freeDateOpt: Option[NCToken],
@NCIntentTerm("sort") sortTokOpt: Option[NCToken],
@NCIntentTerm("limit") limitTokOpt: Option[NCToken]
): NCResult = {
val ext = NCSqlExtractorBuilder.build(SCHEMA, ctx.getVariant)
val query =
SqlBuilder(SCHEMA).
withTables(tbls.map(ext.extractTable): _*).
withAndConditions(extractValuesConditions(ext, condVals): _*).
...
// SQL
// .
}
Hier ist ein Fragment der Standardabsichtsfunktion, die auf ein in der Anforderung definiertes Basiselement reagiert und ausgelöst wird, wenn während des Abgleichs keine strengeren Übereinstimmungen gefunden wurden. Es zeigt die Verwendung der SQL-Elementextraktor-API, die beim Erstellen von SQL-Abfragen sowie beim Arbeiten mit dem SQL Builder-Beispiel beteiligt ist.
Ich möchte noch einmal betonen, dass Apache NlpCraft kein vorgefertigtes Tool zum Übersetzen einer analysierten Textabfrage in SQL bietet. Diese Aufgabe liegt zumindest in der aktuellen Version außerhalb des Projektumfangs. Der Code für den Abfrage-Generator ist in Beispielen verfügbar, nicht in der API. Er weist erhebliche Einschränkungen auf, besteht jedoch auch aus nur 500 Codezeilen mit Kommentaren oder etwa 300 ohne diese. Gleichzeitig kann selbst diese einfachste Implementierung trotz aller Einfachheit und sogar Einschränkung das erforderliche SQL für eine sehr große Anzahl der unterschiedlichsten Arten von Benutzerabfragen generieren. In dieser Version empfehlen wir unseren Benutzern, ähnliche Systeme zu erstellen, um dieses Beispiel zu verwendenals Vorlage und entwickeln Sie es nach Ihren Bedürfnissen. Ja, dies ist keine Aufgabe für einen Abend, aber Sie erhalten ein Ergebnis von unvergleichlich höherer Qualität als bei der direkten Verwendung universeller Lösungen.
Ich wiederhole, dass Sie in der Standard-Intent-Funktion entweder nur die Beispiele aus dem Beispiel ändern können (laut Überprüfungen kann die Funktionalität durchaus ausreichen) oder Lösungen mit neuronalen Netzen verwenden.
Fazit
Der Aufbau eines Systems für den Zugriff auf eine Datenbank ist keine leichte Aufgabe, aber Apache NlpCraft hat bereits einen erheblichen Teil der Routinearbeit übernommen, und vor allem aus diesem Grund wird die Entwicklung eines Systems von angemessener Qualität messbare Zeit und Ressourcen erfordern. Ob die Apache NlpCraft-Community die Richtung für die Automatisierung der Übersetzung von Textabfragen in SQL entwickeln und dieses einfache SQL-Beispiel auf eine vollwertige API erweitern wird - Zeit- und Benutzeranforderungen, die den Plan und die Richtung des Projekts bilden, werden angezeigt.