- Ermöglicht das Schreiben von Code in einer vertrauten Sprache, verwendet jedoch gleichzeitig Funktionen, die nur in einer anderen Sprache vorhanden sind.
- Ermöglicht die direkte Zusammenarbeit mit einem Kollegen, der in einer anderen Sprache programmiert.
- Es macht es möglich, mit zwei Sprachen zu arbeiten und schließlich zu lernen, sie fließend zu sprechen.

Was brauchen wir
Zum Arbeiten benötigen Sie folgende Komponenten:
- R und Python natürlich.
- IDE RStudio (Sie können dies in anderen IDEs tun, aber in RStudio ist es einfacher).
- Ihr bevorzugter Python-Umgebungsmanager (ich verwende hier conda).
- Pakete
rmarkdown
undreticulate
installiert in R.
Beim Schreiben von R-Markdown-Dokumenten arbeiten wir in RStudio, navigieren aber gleichzeitig zwischen in R und Python geschriebenen Codefragmenten. Ich zeige Ihnen ein paar einfache Beispiele.
Einrichten der Python-Umgebung
Wenn Sie mit der Python-Programmierung vertraut sind, wissen Sie, dass sich jede in Python ausgeführte Arbeit auf eine bestimmte Umgebung beziehen muss, die alle für die Arbeit erforderlichen Pakete enthält. Es gibt viele Möglichkeiten, Pakete in Python zu verwalten. Die beiden beliebtesten sind virtualenv und conda. Hier gehe ich davon aus, dass wir conda verwenden und dass es als Python-Umgebungsmanager installiert ist.
Sie können das Reticulate-Paket in R verwenden, um Conda-Umgebungen über die R-Befehlszeile einzurichten, wenn Sie möchten (mit Funktionen wie
conda_create()
). Als normaler Python-Programmierer bevorzuge ich es jedoch, meine Umgebungen manuell einzurichten.
Angenommen, wir erstellen eine Conda-Umgebung mit dem Namen
r_and_python
und installieren sie in
pandas
und
statsmodels
... Also die Befehle im Terminal:
conda create -name r_and_python conda activate r_and_python conda install pandas conda install statsmodels
Nach der Installation
pandas
,
statsmodels
(und alle anderen Pakete , die Sie benötigen), die Umwelt ist die Einrichtung abgeschlossen. Führen Sie nun conda info im Terminal aus und wählen Sie den Pfad zu Ihrer Umgebung aus. Sie benötigen es im nächsten Schritt.
Einrichten Ihres R-Projekts für die Arbeit mit R und Python
Wir werden ein R-Projekt in RStudio starten, aber wir möchten Python im selben Projekt ausführen können. Um sicherzustellen, dass der Python-Code in der gewünschten Umgebung ausgeführt wird, müssen Sie die Systemumgebungsvariable
RETICULATE_PYTHON
für die in dieser Umgebung ausführbare Python-Datei festlegen . Dies ist der Pfad, den Sie im vorherigen Abschnitt gewählt haben, gefolgt von
/bin/python3
.
Der beste Weg, um sicherzustellen, dass diese Variable dauerhaft in Ihrem Projekt festgelegt ist, besteht darin, eine im Projekt benannte Textdatei zu erstellen
.Rprofile
und diese Zeile hinzuzufügen.
Sys.setenv(RETICULATE_PYTHON=”path_to_environment/bin/python3")
Ersetzen Sie pathtoenvironment durch den Pfad, den Sie im vorherigen Abschnitt ausgewählt haben. Speichern Sie die Datei
.Rprofile
und starten Sie die R-Sitzung neu. Jedes Mal, wenn Sie eine Sitzung oder ein Projekt neu starten, wird sie gestartet und
.Rprofile
Ihre Python-Umgebung eingerichtet. Wenn Sie dies testen möchten, können Sie die Zeile Sys.getenv ("RETICULATE_PYTHON") ausführen.
Code schreiben - erstes Beispiel
Jetzt können Sie ein R Markdown-Dokument in Ihrem Projekt einrichten
.Rmd
und Code in zwei verschiedenen Sprachen schreiben. Zuerst müssen Sie die Retikulatbibliothek in Ihren ersten Code laden.
```{r} library(reticulate) ```
Wenn Sie jetzt Python-Code schreiben möchten, können Sie ihn mit normalen Anführungszeichen umschließen, ihn jedoch als Python-Code-Snippet markieren
{python}
und mit verwenden , wenn Sie in R schreiben möchten
{r}
.
Angenommen, Sie führen in unserem ersten Beispiel ein Python-Modell für einen Datensatz mit Testergebnissen von Schülern aus.
```{python} import pandas as pd import statsmodels.api as sm import statsmodels.formula.api as smf # obtain ugtests data url = “http://peopleanalytics-regression-book.org/data/ugtests.csv" ugtests = pd.read_csv(url) # define model model = smf.ols(formula = “Final ~ Yr3 + Yr2 + Yr1”, data = ugtests) # fit model fitted_model = model.fit() # see results summary model_summary = fitted_model.summary() print(model_summary) ```
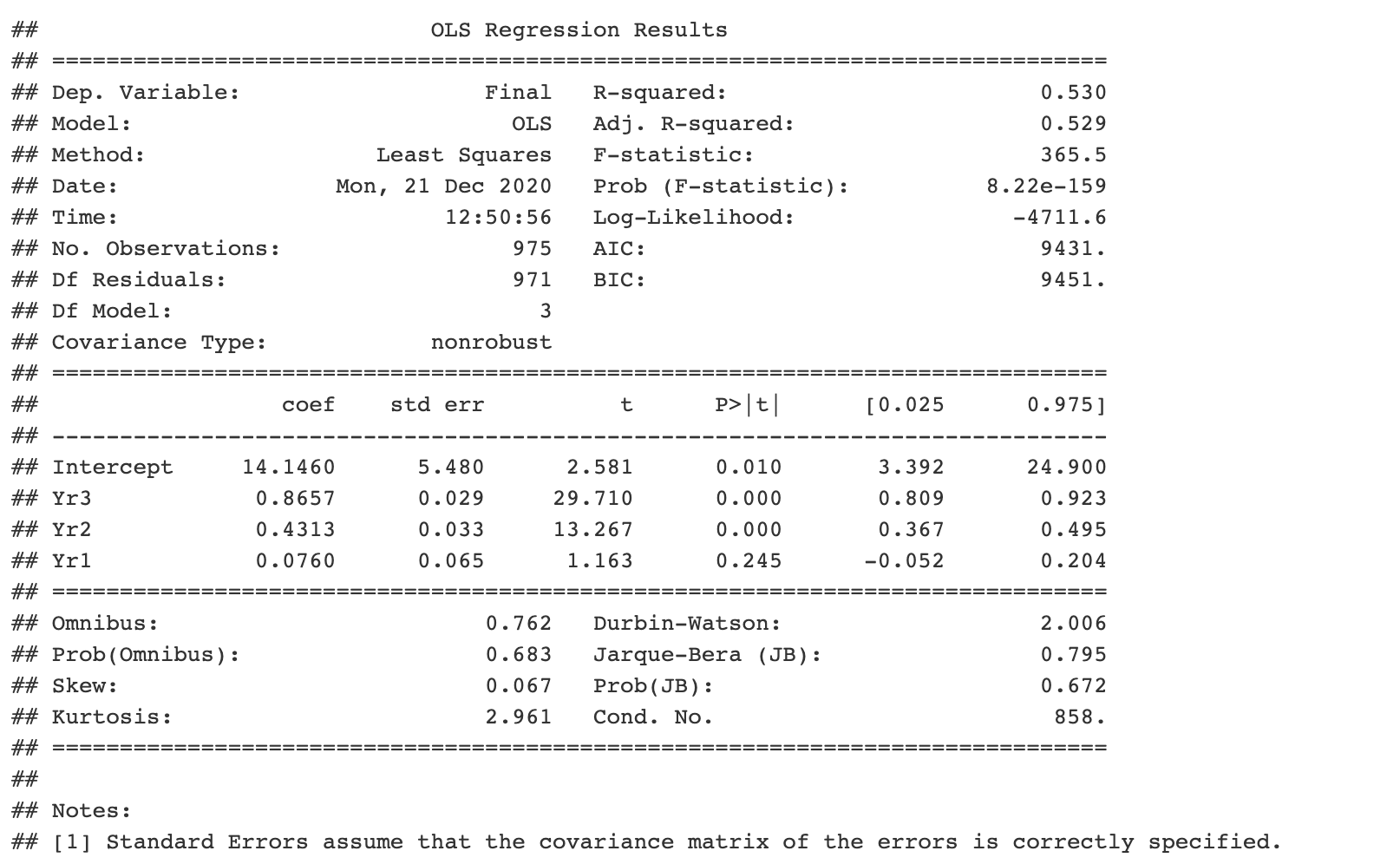
Das ist großartig, aber nehmen wir an, Sie mussten Ihren Job wegen etwas Dringenderem kündigen und ihn Ihrem Kollegen, dem R-Programmierer, übergeben. Sie hatten gehofft, Sie könnten das Modell diagnostizieren.
Haben Sie keine Angst. Sie können auf alle Python-Objekte zugreifen, die Sie in der allgemeinen Liste py erstellt haben. Wenn also ein R-Block in Ihrem R-Markdown-Dokument erstellt wird, haben Kollegen Zugriff auf Ihre Modellparameter:
```{r} py$fitted_model$params ```

oder die ersten paar Reste:
```{r} py$fitted_model$resid[1:5] ```

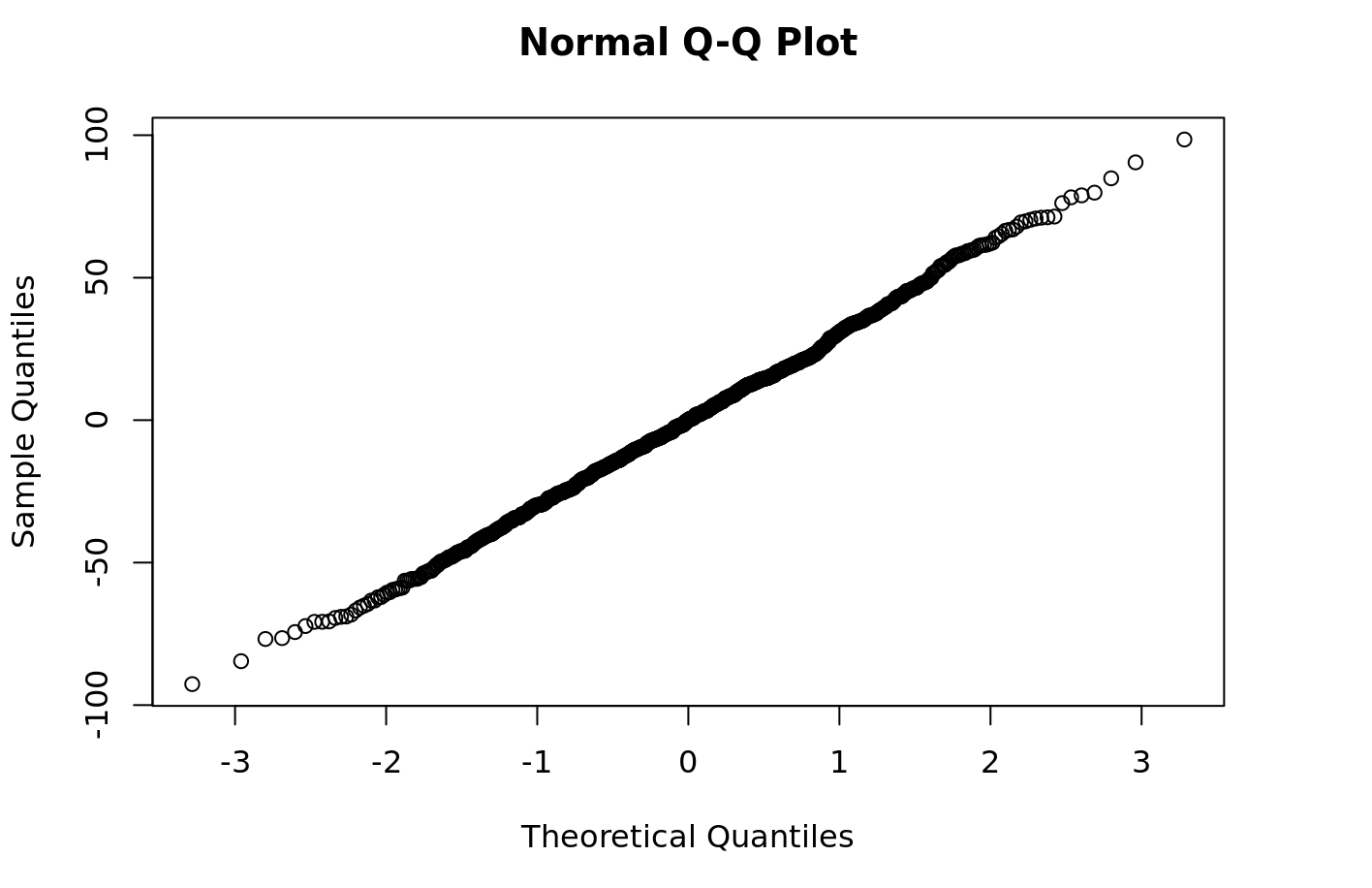
Jetzt können Sie auf einfache Weise einige Diagnosen für das Modell durchführen, z. B. das Zeichnen der Residuen Ihres Quantil-Quantil-Modells:
```{r} qqnorm(py$fitted_model$resid) ```
Code schreiben - zweites Beispiel
Sie haben einige Python-Datierungsdaten analysiert und einen Pandas-Datenrahmen mit allen darin enthaltenen Daten erstellt. Laden Sie der Einfachheit halber die Daten und sehen Sie sie sich an:
```{python} import pandas as pd url = “http://peopleanalytics-regression-book.org/data/speed_dating.csv" speed_dating = pd.read_csv(url) print(speed_dating.head()) ```

Sie haben jetzt ein einfaches logistisches Regressionsmodell in Python ausgeführt, um zu versuchen, die dec-Lösung mit einigen anderen Variablen zu verknüpfen. Sie verstehen jedoch, dass diese Daten tatsächlich hierarchisch sind und dass dieselbe individuelle ID mehrere Bekannte haben kann.
Sie wissen also, dass Sie ein logistisches Regressionsmodell mit gemischten Effekten ausführen müssen, aber Sie können kein Python-Programm finden, das dies tut!
Und wieder keine Angst, senden Sie das Projekt an einen Kollegen und er wird die Lösung in R schreiben.
```{r} library(lme4) speed_dating <- py$speed_dating iid_intercept_model <- lme4:::glmer(dec ~ agediff + samerace + attr + intel + prob + (1 | iid), data = speed_dating, family = “binomial”) coefficients <- coef(iid_intercept_model)$iid ```
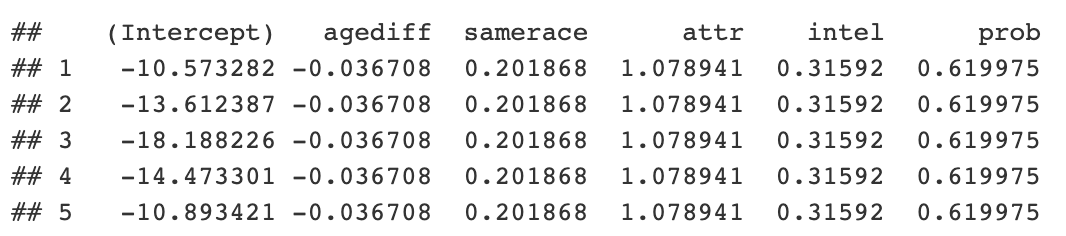
Jetzt können Sie den Code erhalten und die Gewinnchancen anzeigen. Es ist auch möglich, auf Python R-Objekte innerhalb eines generischen r-Objekts zuzugreifen.
```{python} coefs = r.coefficients print(coefs.head()) ```
Diese beiden Beispiele zeigen, wie Sie nahtlos zwischen R und Python im selben R Markdown-Dokument navigieren können. Wenn Sie das nächste Mal über die Arbeit an einem sprachübergreifenden Projekt nachdenken, sollten Sie alle Schritte in R Markdown ausführen. Dies erspart Ihnen viel Mühe beim Umschalten zwischen zwei Sprachen und hilft Ihnen, Ihre gesamte Arbeit als fortlaufende Erzählung an einem Ort zu halten.
Sie können das fertige R Markdown - Dokument um Sprachintegration gebaut sehen - mit Schnipseln von R und Python und Objekten zwischen ihnen bewegen - geschrieben hier . Das Github-Repository mit dem Quellcode ist hier .
Die Beispieldaten im Dokument stammen von my Die People Analytics-Regressionsmodellierungsreferenz .

Andere Berufe und Kurse
BERUF
KURSE
- Java-Entwicklerberuf
- Frontend-Entwicklerberuf
- Beruf Webentwickler
- Beruf Ethischer Hacker
- C ++ Entwicklerberuf
- Profession Unity Spieleentwickler
- Der Beruf des iOS-Entwicklers von Grund auf neu
- Professioneller Android-Entwickler von Grund auf neu
KURSE
- Kurs für maschinelles Lernen
- Fortgeschrittenenkurs "Maschinelles Lernen Pro + Deep Learning"
- Python für Webentwicklungskurs
- JavaScript-Kurs
- « Machine Learning Data Science»
- DevOps