Für einige Bereiche, wie z. B. NLP, war das Arbeitspferd Transformer, das sehr viel GPU-Speicher benötigt. Realistische Modelle passen einfach nicht in den Speicher. Die letzte Methode namens Sharded [lit. 'segmentiert'] wurde in Microsofts Zero-Paper vorgestellt , in dem eine Methode entwickelt wurde, die die Menschheit näher an 1 Billion Parameter bringt.
Speziell für den Start eines neuen Kurses über maschinelles LernenTeilen Sie mit uns einen Artikel über Sharded, der Ihnen zeigt, wie Sie ihn heute mit PyTorch verwenden können, um Modelle mit doppeltem Speicher und in nur wenigen Minuten zu trainieren. Diese Funktion in PyTorch ist jetzt dank einer Zusammenarbeit zwischen den FairScale Facebook AI Research- und PyTorch Lightning-Teams verfügbar .

Für wen ist dieser Artikel?
Dieser Artikel richtet sich an alle, die PyTorch zum Trainieren von Modellen verwenden. Sharded funktioniert mit jedem Modell, unabhängig davon, welches Modell trainiert werden soll: NLP (Transformator), visuell (SIMCL, Swav, Resnet) oder sogar Sprachmodelle. Hier ist eine Momentaufnahme des Leistungsgewinns, den Sie mit Sharded für alle Modelltypen sehen können.
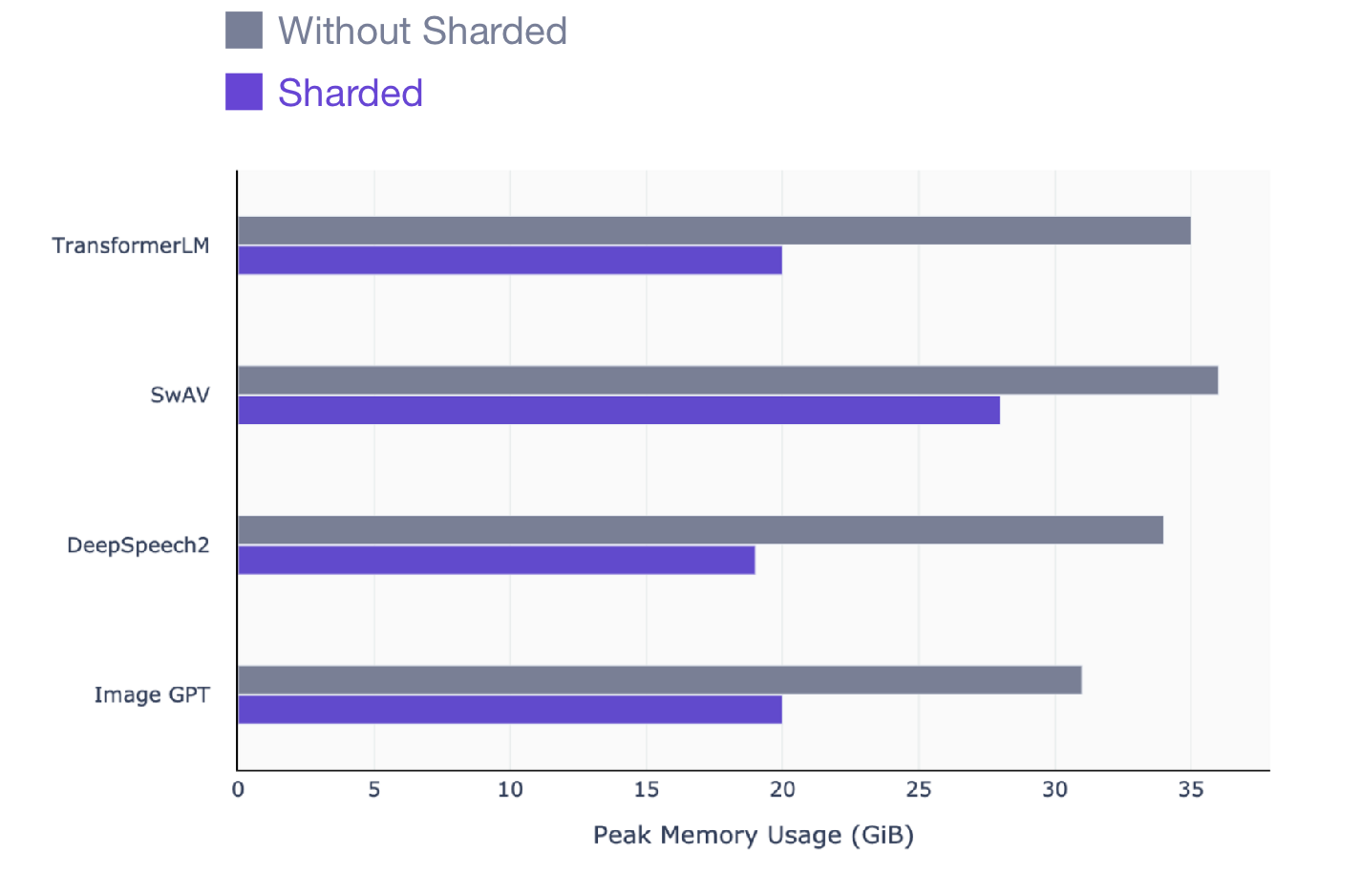
SwAV ist eine datengesteuerte Lernmethode auf dem neuesten Stand der Technik in der Bildverarbeitung .
DeepSpeech2 ist eine moderne Technik für Sprachmodelle.
Image GPT ist eine fortschrittliche Methode für visuelle Modelle.
Transformer ist eine fortschrittliche Verarbeitungstechnik für natürliche Sprachen.
Verwendung von Sharded mit PyTorch
Für diejenigen, die nicht viel Zeit haben, um die intuitive Erklärung der Funktionsweise von Sharded zu lesen, erkläre ich sofort, wie Sharded mit Ihrem PyTorch-Code verwendet wird. Ich fordere Sie jedoch dringend auf, das Ende des Artikels zu lesen, um zu verstehen, wie Sharded funktioniert.
Sharded kann mit mehreren GPUs verwendet werden, um die verfügbaren Vorteile voll auszuschöpfen. Das Training auf mehreren GPUs kann jedoch entmutigend und sehr schmerzhaft sein.
Der einfachste Weg, Ihren Code mit Sharded aufzuladen, besteht darin, Ihr Modell in PyTorch Lightning zu konvertieren (dies ist nur ein Refactoring). Hier ist ein 4-minütiges Video, das Ihnen zeigt, wie Sie Ihren PyTorch-Code in Lightning konvertieren.
Sobald Sie dies getan haben, ist das Aktivieren von Sharded auf 8 GPUs so einfach wie das Ändern eines einzelnen Flags: Es sind keine Änderungen an Ihrem Code erforderlich.

Wenn Ihr Modell aus einer anderen Deep-Learning-Bibliothek stammt, funktioniert es weiterhin mit Lightning (NVIDIA Nemo, fast.ai, Hugging Face). Sie müssen lediglich das Modell in LightningModule importieren und mit dem Lernen beginnen.
from argparse import ArgumentParser
import torch
import torch.nn as nn
import pytorch_lightning as pl
from pytorch_lightning.metrics.functional import accuracy
from transformers import BertModel
class LitBertClassifier(pl.LightningModule):
def __init__(self, n_classes, pretrained_model_name='bert-base-uncased'):
super().__init__()
self.save_hyperparameters()
self.bert = BertModel.from_pretrained(pretrained_model_name)
self.drop = nn.Dropout(p=0.3)
self.out = nn.Linear(self.bert.config.hidden_size, n_classes)
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, input_ids, attention_mask):
outputs = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
return_dict=False
)
pooled_output = outputs[1]
output = self.drop(pooled_output)
return self.out(output)
def training_step(self, batch, batch_idx):
loss, acc = self._shared_step(batch, batch_idx)
self.log("acc", acc)
return loss
def validation_step(self, batch, batch_idx):
_, acc = self._shared_step(batch, batch_idx)
self.log("val_acc", acc)
def _shared_step(self, batch, batch_idx):
input_ids = batch["input_ids"]
attention_mask = batch["attention_mask"]
targets = batch["targets"]
outputs = self.forward(
input_ids=input_ids,
attention_mask=attention_mask
)
_, preds = torch.max(outputs, dim=1)
loss = self.loss_fn(outputs, targets)
acc = accuracy(preds, targets)
return loss, acc
def configure_optimizers(self):
return torch.optim.AdamW(self.parameters(), lr=2e-5)
if __name__ == '__main__':
# TODO: add your own dataset
train_dataloader = ...
val_dataloader = ...
bert = LitBertClassifier()
trainer = pl.Trainer(gpus=8, plugins='ddp_sharded')
trainer.fit(bert, train_dataloader)
Intuitive Erklärung, wie Sharded funktioniert
Es werden verschiedene Ansätze verwendet, um eine große Anzahl von GPUs effektiv zu trainieren. Bei einem Ansatz (DP) wird jedes Paket auf GPUs aufgeteilt. Hier ist eine DP-Abbildung, in der jeder Teil des Pakets an eine andere GPU gesendet und das Modell mehrmals auf jede GPU kopiert wird.

DP-Training
Dieser Ansatz ist jedoch schlecht, da die Modellgewichte über das Gerät übertragen werden. Darüber hinaus unterstützt die erste GPU alle Optimierungszustände. Zum Beispiel behält Adam eine zusätzliche vollständige Kopie der Gewichte Ihres Modells.
Bei einer anderen Technik (parallele Datenverteilung, DDP) wird jede GPU auf eine Teilmenge der Daten trainiert und die Gradienten werden zwischen den GPUs synchronisiert. Diese Methode funktioniert auch auf vielen Maschinen (Knoten). In dieser Abbildung empfängt jede GPU eine Teilmenge der Daten und initialisiert für alle GPUs die gleichen Modellgewichte. Nach dem Rücklauf werden dann alle Verläufe synchronisiert und aktualisiert.
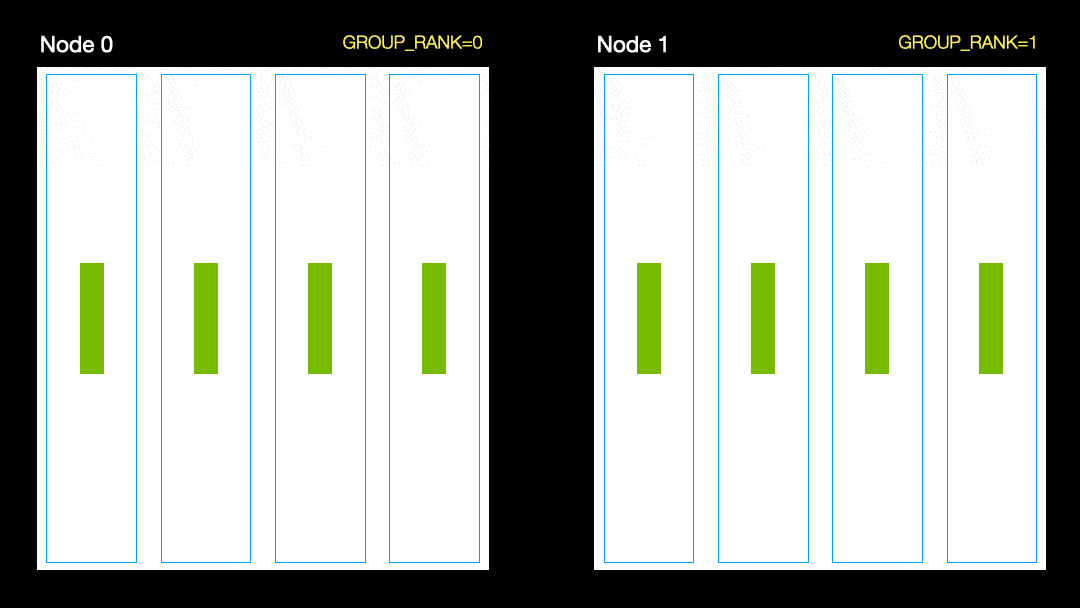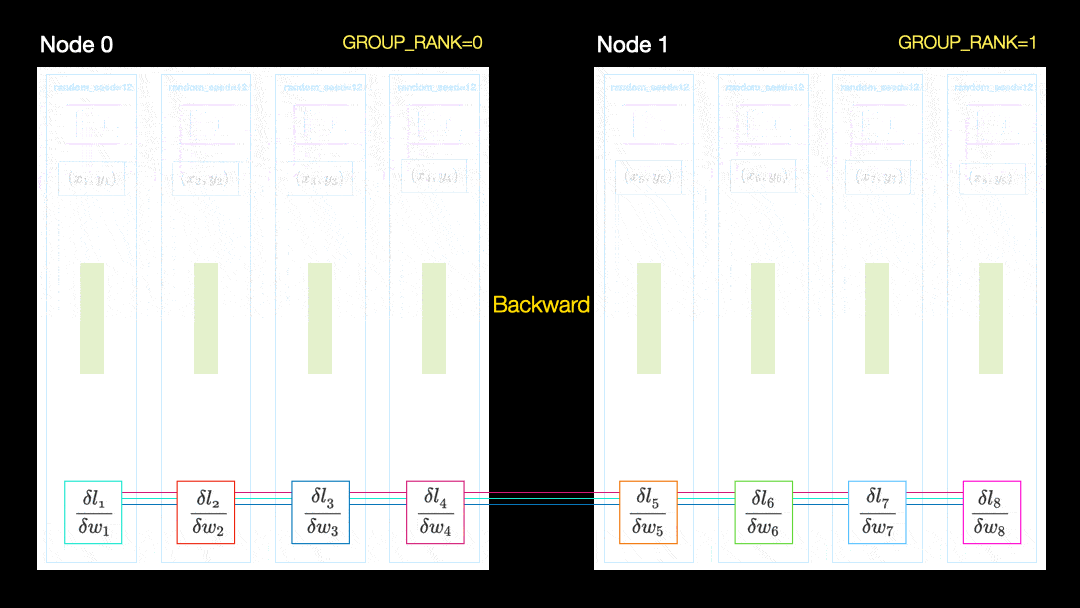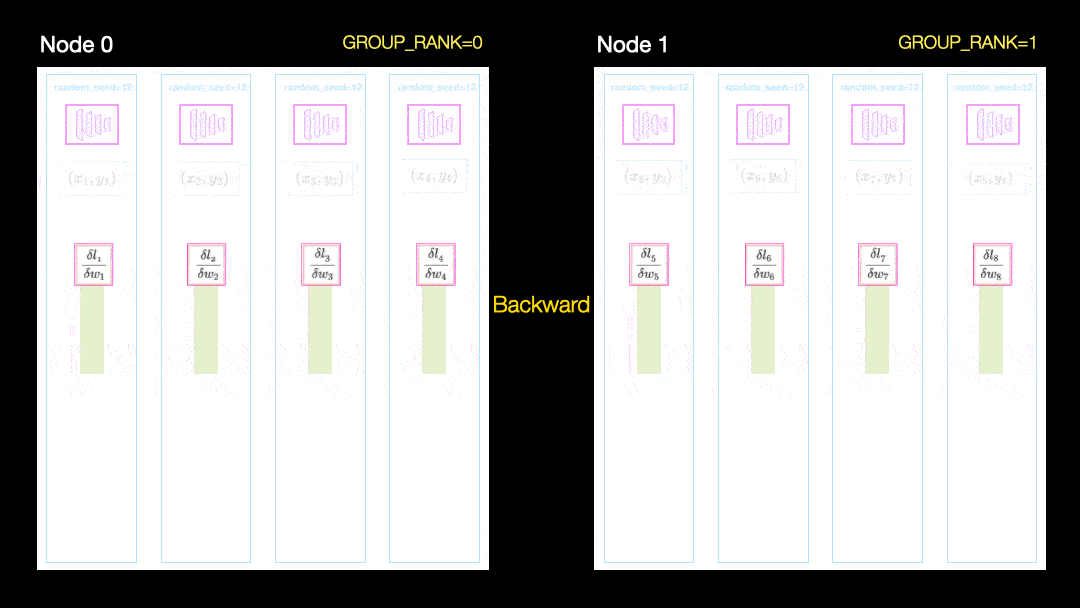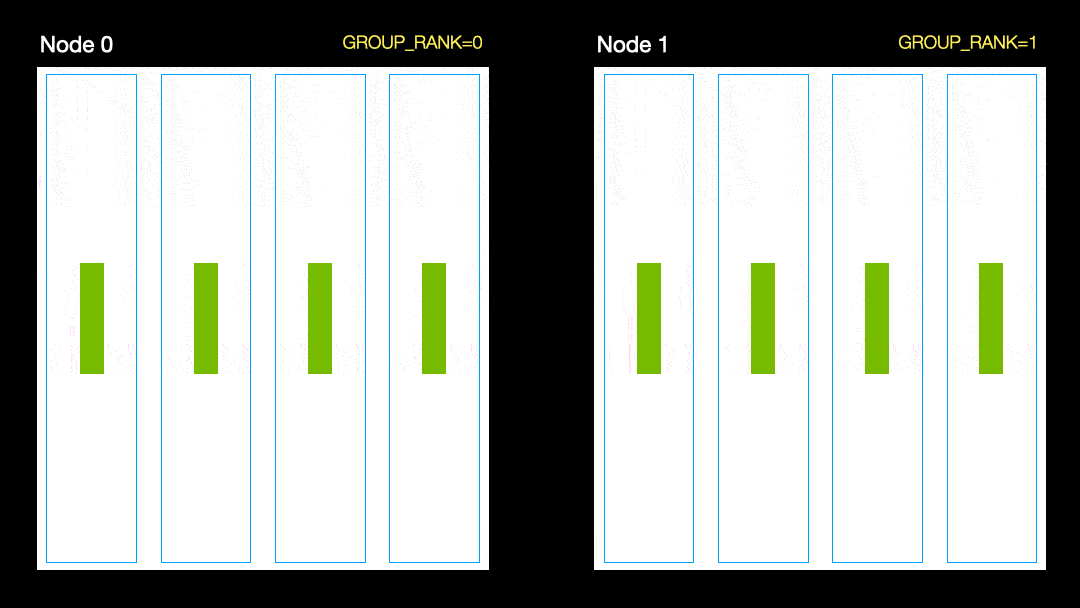
Parallele Datenverteilung
Diese Methode weist jedoch immer noch ein Problem auf: Jede GPU muss eine Kopie aller Optimierungszustände (etwa das 2-3-fache der Modellparameter) sowie aller Vorwärts- und Rückwärtsaktivierungen verwalten.
Sharded entfernt diese Redundanz. Es funktioniert genauso wie DDP, mit der Ausnahme, dass der gesamte Overhead (Gradienten, Optimierungsstatus usw.) nur für einen Bruchteil der Gesamtparameter berechnet wird und somit die Redundanz beim Speichern des gleichen Gradienten und der gleichen Zustände beseitigt wird Optimierer auf allen GPUs. Mit anderen Worten, jede GPU speichert nur eine Teilmenge von Aktivierungen, Optimierungsparametern und Gradientenberechnungen.
Verwenden eines verteilten Modus

In PyTorch Lightning ist das Umschalten des Verteilungsmodus trivial.
Wie Sie sehen, gibt es bei jedem dieser Optimierungsansätze viele Möglichkeiten, das verteilte Lernen optimal zu nutzen.
Die gute Nachricht ist, dass alle diese Modi in PyTorch Lightning verfügbar sind, ohne dass Codeänderungen erforderlich sind. Sie können jeden von ihnen ausprobieren und gegebenenfalls an Ihr spezifisches Modell anpassen.
Eine Methode, die es nicht gibt, ist das Parallelmodell. Diese Methode sollte jedoch gewarnt werden, da sie sich als viel weniger effektiv als segmentiertes Training erwiesen hat und mit Vorsicht angewendet werden sollte. In einigen Fällen kann es funktionieren, aber im Allgemeinen ist es am besten, Sharding zu verwenden.
Der Vorteil von Lightning ist, dass Sie nie hinter den neuesten Fortschritten in der KI-Forschung zurückbleiben! Das Open Source-Team und die Community sind bestrebt, die neuesten Fortschritte mit Lightning durch Lightning zu teilen.

Andere Berufe und Kurse