Wir haben schon lange interessiert an dem Thema Apache Kafka als Data Warehouse der Verwendung von einem theoretischen Standpunkt aus betrachtet, zum Beispiel hier . Umso interessanter ist es, Sie auf eine Übersetzung von Material aus dem Twitter-Blog (Original - Dezember 2020) aufmerksam zu machen, das eine unkonventionelle Verwendung von Kafka als Datenbank für die Verarbeitung und Reproduktion von Ereignissen beschreibt. Wir hoffen, dass der Artikel interessant ist und Ihnen neue Gedanken und Lösungen bei der Arbeit mit Kafka gibt .
Einführung
Wenn Entwickler öffentlich verfügbare Twitter-Daten über die Twitter-API nutzen, verlassen sie sich auf Zuverlässigkeit, Geschwindigkeit und Stabilität. Aus diesem Grund hat Twitter vor einiger Zeit die Account Activity Replay API für die Account Activity API eingeführt, um Entwicklern die Gewährleistung der Stabilität ihrer Systeme zu erleichtern. Die Account Activity Replay API ist ein Datenwiederherstellungstool, mit dem Entwickler Ereignisse abrufen können, die bis zu fünf Tage alt sind. Diese API stellt Ereignisse wieder her, die aus verschiedenen Gründen nicht übermittelt wurden, einschließlich Serverabstürzen, die beim Versuch aufgetreten sind, in Echtzeit zu übermitteln.
Die Ingenieure von Twitter waren nicht nur bestrebt, APIs zu erstellen, die von den Entwicklern gut angenommen werden, sondern auch:
- Steigerung der Produktivität von Ingenieuren;
- Machen Sie das System einfach zu warten. Insbesondere, um die Notwendigkeit eines Kontextwechsels für Entwickler, SRE-Ingenieure und alle anderen, die sich mit dem System befassen , zu minimieren .
Aus diesem Grund wurde bei der Erstellung eines Wiedergabesystems, das für die API verwendet wird, beschlossen, das vorhandene System für die Echtzeitarbeit als Grundlage zu verwenden, auf dem die Kontoaktivitäts-API basiert. Auf diese Weise war es möglich, bestehende Entwicklungen wiederzuverwenden und Kontextwechsel und Schulungen zu minimieren, was viel bedeutender wäre, wenn für die beschriebene Arbeit ein völlig neues System geschaffen würde.
Die Echtzeitlösung basiert auf einer Publish-Subscribe-Architektur. Zu diesem Zweck entstand unter Berücksichtigung der Aufgaben und der Schaffung eines Informationsspeichers, aus dem gelesen werden soll, die Idee, die bekannte Streaming-Technologie - Apache Kafka - zu überdenken.
Kontext
In Echtzeit auftretende Ereignisse werden in zwei Rechenzentren erzeugt. Wenn diese Ereignisse ausgelöst werden, werden sie in Publish-Subscribe-Themen geschrieben, die aus Redundanzgründen in zwei Rechenzentren repliziert werden.
Es müssen nicht alle Ereignisse übermittelt werden. Daher werden alle Ereignisse von einer internen Anwendung gefiltert, die Ereignisse aus den relevanten Themen verwendet, sie anhand einer Reihe von Regeln im Schlüssel- und Wertspeicher überprüft und entscheidet, ob das Ereignis über eine öffentliche API an einen bestimmten Entwickler übermittelt werden soll. Ereignisse werden über einen Webhook übermittelt, und jede Webhook-URL gehört einem Entwickler, der durch eine eindeutige ID gekennzeichnet ist.
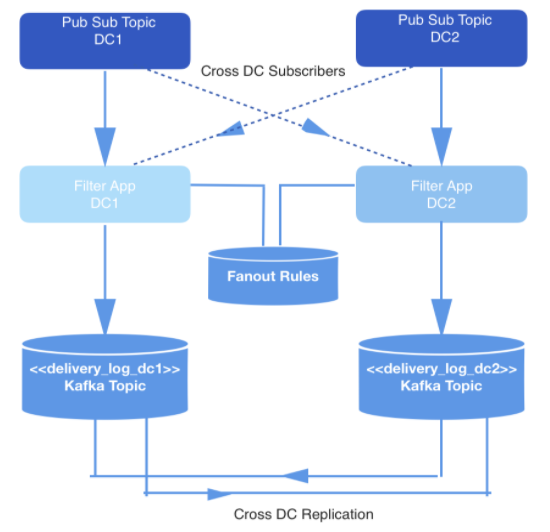
Zahl: 1: Datengenerierungspipeline
Speicherung und Segmentierung
Wenn Sie ein Wiedergabesystem erstellen, für das ein solches Data Warehouse erforderlich ist, wird normalerweise eine auf Hadoop und HDFS basierende Architektur ausgewählt. In diesem Fall wurde Apache Kafka aus zwei Gründen gewählt:
- Das System für das Arbeiten in Echtzeit basiert auf einem Publish-Subscribe-Prinzip, das für das Kafka-Gerät organisch ist
- Das Ereignisvolumen, das im Wiedergabesystem gespeichert werden muss, wird nicht in Petabyte angegeben. Wir speichern Daten nicht länger als ein paar Tage. Der Umgang mit MapReduce-Jobs für Hadoop ist außerdem teurer und langsamer als der Verbrauch von Daten in Kafka, und die erste Option entspricht nicht den Erwartungen der Entwickler.
In diesem Fall fällt die Hauptlast auf die Echtzeit-Datenwiedergabe-Pipeline, um sicherzustellen, dass die Ereignisse, die an jeden Entwickler übermittelt werden müssen, in Kafka gespeichert werden. Nennen wir das Thema Kafka Delivery_log. Für jedes Rechenzentrum gibt es ein solches Thema. Diese Themen werden aus Redundanzgründen repliziert, sodass eine Replikationsanforderung von einem einzelnen Datencenter aus ausgegeben werden kann. Auf diese Weise gespeicherte Ereignisse werden vor der Zustellung dedupliziert.
In diesem Kafka-Thema erstellen wir viele Partitionen mit dem standardmäßigen semantischen Sharding. Daher entsprechen Partitionen dem webhookId-Hash des Entwicklers, und diese ID dient als Schlüssel für jeden Eintrag. Es sollte statisches Sharding verwenden, wurde jedoch am Ende aufgrund des erhöhten Risikos, dass eine Partition mehr Daten als andere enthält, aufgegeben, wenn einige Entwickler im Verlauf ihrer Aktivitäten mehr Ereignisse generieren als andere. Stattdessen wurde eine feste Anzahl von Partitionen ausgewählt, um die Daten zu verteilen, und die Partitionierungsstrategie wurde auf der Standardeinstellung belassen. Dies verringert das Risiko unausgeglichener Partitionen und muss nicht alle Partitionen im Kafka-Thema lesen.
Im Gegensatz dazu ermittelt der Wiedergabedienst basierend auf der Webhook-ID, für die die Anforderung gestellt wird, die spezifische Partition, von der gelesen werden soll, und löst einen neuen Kafka-Consumer für diese Partition aus. Die Anzahl der Partitionen in einem Thema ändert sich nicht, da das Hashing von Schlüsseln und die Ereignisverteilung davon abhängen.
Um den Speicherplatz zu minimieren, werden Informationen unter Verwendung des schnellen Algorithmus komprimiert , da bekannt ist, dass die meisten Informationen in der beschriebenen Aufgabe auf der Verbraucherseite verarbeitet werden. Darüber hinaus lässt sich snappy schneller dekomprimieren als andere von Kafka unterstützte Komprimierungsalgorithmen: gzip und lz4....
Anfragen und Bearbeitung
In einem auf diese Weise entworfenen System sendet die API Wiederholungsanforderungen. Als Teil der Nutzdaten jeder validierten Anforderung werden eine Webhook-ID und eine Reihe von Daten bereitgestellt, für die Ereignisse abgespielt werden sollen. Diese Abfragen werden lange Zeit in MySQL gespeichert und in die Warteschlange gestellt, bis sie vom Wiedergabedienst erfasst werden. Der in der Anforderung angegebene Datenbereich wird verwendet, um den Versatz zu bestimmen, bei dem mit dem Lesen von der Festplatte begonnen werden soll. Die
offsetForTimes
Objektfunktion wird
Consumer
verwendet, um die Offsets abzurufen.
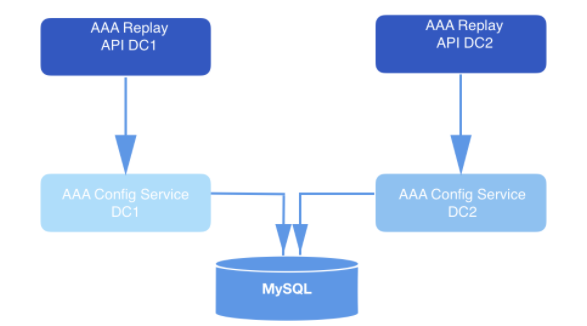
Zahl: 2: Wiedergabesystem. Es empfängt die Anforderung und sendet sie zur weiteren Langzeitspeicherung in der Datenbank an den Konfigurationsdienst (Datenzugriffsschicht).
Wiederholungsdienstinstanzen verarbeiten jede Wiederholungsanforderung. Die Instanzen werden mithilfe von MySQL miteinander koordiniert, um den nächsten in der Datenbank gespeicherten Wiedergabedatensatz zu verarbeiten. Jeder Replay-Worker-Prozess fragt MySQL regelmäßig ab, um festzustellen, ob ein Job zu verarbeiten ist. Die Anfrage geht von Staat zu Staat. Eine Anforderung, die nicht zur Verarbeitung abgeholt wurde, befindet sich im Status OFFEN. Die Anforderung, die gerade aus der Warteschlange entfernt wurde, befindet sich im Status STARTED. Die aktuell verarbeitete Anfrage befindet sich im Status ONGOING. Eine Anforderung, die alle Übergänge durchlaufen hat, befindet sich im Status ABGESCHLOSSEN. Der Wiedergabe-Workflow nimmt nur Anforderungen auf, die noch nicht mit der Verarbeitung begonnen haben (dh Anforderungen im Status OFFEN).
Nachdem der Worker-Prozess die Anforderung zur Verarbeitung aus der Warteschlange entfernt hat, wird sie regelmäßig in die MySQL-Tabelle abgegriffen, wobei Zeitstempel verbleiben und damit gezeigt wird, dass der Wiedergabeauftrag noch verarbeitet wird. In Fällen, in denen eine reproduzierende Workflow-Instanz stirbt, bevor die Verarbeitung einer Anforderung abgeschlossen ist, werden diese Jobs neu gestartet. Infolgedessen werden bei den Wiedergabeprozessen nicht nur Anforderungen im Status OFFEN in die Warteschlange gestellt, sondern auch diejenigen Anforderungen erfasst, die in den Status STARTED oder ONGOING übertragen wurden, aber nach einer bestimmten Anzahl von Minuten keine Rückmeldung in der Datenbank erhalten haben.
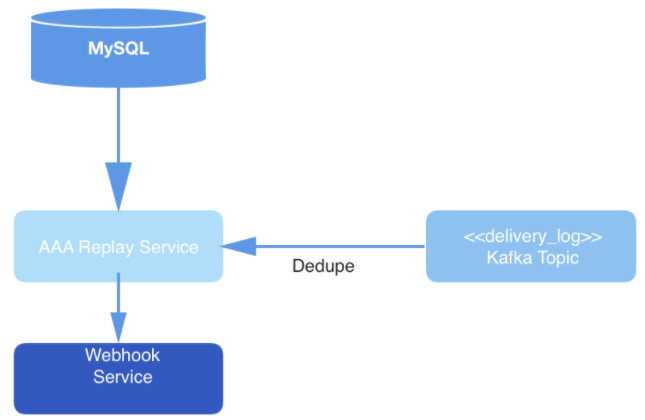
Zahl: 3: Datenübermittlungsschicht: Der Wiedergabedienst fragt MySQL nach einem neuen Anforderungsverarbeitungsjob ab, verwendet die Anforderung aus dem Kafka-Thema und liefert Ereignisse über den Webhook-Dienst.
Schließlich werden Ereignisse aus dem Thema beim Lesen dedupliziert und dann unter der URL des Webhooks eines bestimmten Benutzers veröffentlicht. Die Deduplizierung wird durchgeführt, indem ein Cache mit Leseereignissen verwaltet wird, die dann gehasht werden. Wenn ein Ereignis mit einem Hash auftritt, das mit dem bereits im Hash enthaltenen identisch ist, wird es nicht ausgeliefert.
Im Allgemeinen ist diese Verwendung von Kafka nicht traditionell. Im Rahmen des beschriebenen Systems arbeitet Kafka jedoch erfolgreich als Datenspeicher und beteiligt sich an der Arbeit einer API, die sowohl zur Benutzerfreundlichkeit als auch zum einfachen Zugriff auf Daten bei der Wiederherstellung von Ereignissen beiträgt. Die Stärken des Systems für den Echtzeitbetrieb haben sich im Rahmen einer solchen Lösung als nützlich erwiesen. Darüber hinaus entspricht die Datenwiederherstellungsrate in einem solchen System vollständig den Erwartungen der Entwickler.