AOT- und JIT-Compiler
Prozessoren können nur einen begrenzten Satz von Anweisungen ausführen - Maschinencode. Damit ein Programm von einem Prozessor ausgeführt werden kann, muss es als Maschinencode dargestellt werden.
Es gibt kompilierte Programmiersprachen wie C und C ++. In diesen Sprachen geschriebene Programme werden als Maschinencode verteilt. Nachdem das Programm geschrieben wurde, übersetzt ein spezieller Prozess - der AOT-Compiler (Ahead-of-Time), der normalerweise einfach als Compiler bezeichnet wird, den Quellcode in Maschinencode. Der Maschinencode kann auf einem bestimmten Prozessormodell ausgeführt werden. Prozessoren mit einer gemeinsamen Architektur können denselben Code ausführen. Spätere Prozessormodelle unterstützen im Allgemeinen Anweisungen von früheren Modellen, jedoch nicht umgekehrt. Beispielsweise kann Maschinencode, der AVX-Anweisungen für die Intel Sandy Bridge-Prozessoren verwendet, nicht auf älteren Intel-Prozessoren ausgeführt werden. Es gibt verschiedene Möglichkeiten, um dieses Problem zu lösen, z. B. das Übertragen kritischer Teile des Programms in eine Bibliothek mit Versionen für die Hauptprozessormodelle.Oft werden Programme jedoch einfach für relativ alte Prozessormodelle kompiliert und nutzen die neuen Befehlssätze nicht.
Im Gegensatz zu kompilierten Programmiersprachen gibt es interpretierte Sprachen wie Perl und PHP. Mit diesem Ansatz kann derselbe Quellcode auf jeder Plattform ausgeführt werden, für die ein Interpreter vorhanden ist. Der Nachteil dieses Ansatzes ist, dass interpretierter Code langsamer ist als Maschinencode, der dasselbe tut.
Die Java-Sprache bietet einen anderen Ansatz, eine Kreuzung zwischen kompilierten und interpretierten Sprachen. Java-Anwendungen werden zu einem Zwischencode auf niedriger Ebene kompiliert - Bytecode.
Der Name Bytecode wurde gewählt, da genau ein Byte zum Codieren jeder Operation verwendet wird. In Java 10 gibt es ungefähr 200 Operationen.
Der Bytecode wird dann von der JVM sowie einem interpretierten Sprachprogramm ausgeführt. Da der Bytecode jedoch ein genau definiertes Format hat, kann die JVM ihn zur Laufzeit zu Maschinencode kompilieren. Natürlich können ältere Versionen der JVM keinen Maschinencode mit den nachfolgenden neuen Prozessoranweisungen generieren. Um ein Java-Programm zu beschleunigen, muss es nicht einmal neu kompiliert werden. Es reicht aus, es auf einer neueren JVM auszuführen.
HotSpot JIT-Compiler
Verschiedene JVM-JIT-Implementierungen können den Compiler auf unterschiedliche Weise implementieren. In diesem Artikel befassen wir uns mit Oracle HotSpot JVM und seiner JIT-Compiler-Implementierung. Der Name HotSpot stammt von dem Ansatz, den die JVM zum Kompilieren von Bytecode verwendet. In der Regel werden in einer Anwendung nur kleine Teile des Codes häufig genug ausgeführt, und die Leistung der Anwendung hängt hauptsächlich von der Ausführungsgeschwindigkeit dieser bestimmten Teile ab. Diese Teile des Codes werden als Hot Spots bezeichnet und vom JIT-Compiler kompiliert. Diesem Ansatz liegen mehrere Urteile zugrunde. Wenn der Code nur einmal ausgeführt wird, ist das Kompilieren dieses Codes Zeitverschwendung. Ein weiterer Grund sind Optimierungen. Je öfter die JVM Code ausführt, desto mehr Statistiken werden gesammelt, mit denen Sie optimierten Code generieren können.Darüber hinaus teilt der Compiler die Ressourcen der virtuellen Maschine mit der Anwendung selbst, sodass die für die Profilerstellung und Optimierung aufgewendeten Ressourcen zur Ausführung der Anwendung selbst verwendet werden können, wodurch ein gewisses Gleichgewicht eingehalten werden muss. Die Arbeitseinheit für den HotSpot-Compiler ist eine Methode und eine Schleife.
Die Einheit des kompilierten Codes heißt nmethod (kurz für native Methode).
Abgestufte Zusammenstellung
Tatsächlich verfügt die HotSpot-JVM nicht über einen, sondern über zwei Compiler: C1 und C2. Ihre anderen Namen sind Client und Server. In der Vergangenheit wurde C1 in GUI-Anwendungen und C2 in Serveranwendungen verwendet. Compiler unterscheiden sich darin, wie schnell sie mit dem Kompilieren von Code beginnen. C1 beginnt, den Code schneller zu kompilieren, während C2 optimierten Code generieren kann.
In früheren Versionen der JVM mussten Sie einen Compiler mit den Flags -client für den Client und -server oder -d64 auswählenfür den Serverraum. JDK 6 führte den mehrstufigen Kompilierungsmodus ein. Grob gesagt liegt sein Wesen in einem sequentiellen Übergang vom interpretierten Code zum vom Compiler C1 und dann von C2 erzeugten Code. In JDK 8 werden die Flags -client, -server und -d64 ignoriert, und in JDK 11 wurde das Flag -d64 entfernt und führt zu einem Fehler. Sie können den gestuften Kompilierungsmodus mit dem Flag -XX: -TieredCompilation deaktivieren .
Es gibt 5 Kompilierungsstufen:
- 0 - interpretierter Code
- 1 - C1 vollständig optimiert (keine Profilerstellung)
- 2 - C1 unter Berücksichtigung der Anzahl der Methodenaufrufe und Schleifeniterationen
- 3 - C1 mit Profilerstellung
- 4 - C2
Typische Abfolgen von Übergängen zwischen Ebenen sind in der Tabelle aufgeführt.
| Reihenfolge
|
Beschreibung
|
|---|---|
| 0-3-4 | Dolmetscher, Stufe 3, Stufe 4. Am häufigsten. |
| 0-2-3-4 | , 4 (C2) . 2. , 3 , , 4. |
| 0-2-4 | , 3 . 4 3. 2 4. |
| 0-3-1 | . 3, , 4 . 1. |
| 0-4 | . |
Code cache
Der vom JIT-Compiler kompilierte Maschinencode wird in einem Speicherbereich gespeichert, der als Code-Cache bezeichnet wird. Außerdem wird der Maschinencode der virtuellen Maschine selbst gespeichert, z. B. der Interpretercode. Die Größe dieses Speicherbereichs ist begrenzt, und wenn er voll ist, wird die Kompilierung gestoppt. In diesem Fall werden einige der "heißen" Methoden weiterhin vom Interpreter ausgeführt. Im Falle eines Überlaufs zeigt die JVM die folgende Meldung an:
Java HotSpot(TM) 64-Bit Server VM warning: CodeCache is full. Compiler has been disabled.
Eine andere Möglichkeit, einen Überlauf dieses Speicherbereichs festzustellen, besteht darin, die Compiler-Protokollierung zu aktivieren (wie dies beschrieben wird, wird unten erläutert).
Der Code-Cache kann auf die gleiche Weise wie andere Speicherbereiche in der JVM konfiguriert werden. Die Anfangsgröße wird durch den Parameter -XX: InitialCodeCacheSize angegeben . Die maximale Größe wird durch den Parameter -XX: ReservedCodeCacheSize angegeben . Standardmäßig beträgt die Anfangsgröße 2496 KB. Die maximale Größe beträgt 48 MB, wenn die gestufte Kompilierung deaktiviert ist, und 240 MB, wenn sie aktiviert ist.
Seit Java 9 ist der Code-Cache in drei Segmente unterteilt (die Gesamtgröße ist immer noch durch die oben beschriebenen Grenzwerte begrenzt):
- JVM internal (non-method code). , JVM, , . . 5.5 MB. -XX:NonNMethodCodeHeapSize.
- Profiled code. . non-method code . 21.2 MB 117.2 MB . -XX:ProfiledCodeHeapSize.
- Non-profiled code. . non-method code . 21.2 MB 117.2 MB . -XX: NonProfiledCodeHeapSize.
Sie können die Protokollierung des Kompilierungsprozesses mit dem Flag -XX: + PrintCompilation aktivieren (standardmäßig deaktiviert). Wenn dieses Flag gesetzt ist, schreibt die JVM jedes Mal, wenn eine Methode oder Schleife kompiliert wird, eine Nachricht in den Standardausgabestream (STDOUT). Die meisten Nachrichten haben das folgende Format: Zeitstempel compilation_id-Attribute tiered_level method_name size deopt.
Das Zeitstempelfeld ist die Zeit seit dem Start der JVM.
Das Feld compilation_id ist die interne ID des Problems. Es wächst normalerweise mit jeder Nachricht nacheinander, aber manchmal kann die Reihenfolge nicht in Ordnung sein. Dies kann passieren, wenn mehrere Kompilierungsthreads parallel ausgeführt werden.
Das Attributfeld besteht aus fünf Zeichen, die zusätzliche Informationen zum kompilierten Code enthalten. Wenn eines der Attribute nicht zutreffend ist, wird stattdessen ein Leerzeichen angezeigt. Folgende Attribute existieren:
- % - OSR (On-Stack-Ersatz);
- s - die Methode ist synchronisiert;
- ! - Die Methode enthält einen Ausnahmebehandler.
- b - Kompilierung im Blockierungsmodus;
- n - Die kompilierte Methode ist ein Wrapper für die native Methode.
OSR steht für On-Stack-Austausch. Die Kompilierung ist ein asynchroner Prozess. Wenn die JVM entscheidet, dass eine Methode kompiliert werden muss, wird sie in die Warteschlange gestellt. Während die Methode kompiliert wird, führt die JVM sie weiterhin vom Interpreter aus. Beim nächsten erneuten Aufruf der Methode wird ihre kompilierte Version ausgeführt. Im Falle eines langen Zyklus ist es unpraktisch, auf den Abschluss der Methode zu warten - sie wird möglicherweise überhaupt nicht abgeschlossen. Die JVM kompiliert den Hauptteil der Schleife und sollte mit der Ausführung der kompilierten Version beginnen. Die JVM speichert den Status von Threads auf einem Stapel. Für jede aufgerufene Methode wird auf dem Stapel ein neues Stapelrahmenobjekt erstellt, in dem die Methodenparameter, lokalen Variablen, der Rückgabewert und andere Werte gespeichert sind. Während der OSR wird ein neuer Stapelrahmen erstellt, der den vorherigen ersetzt.
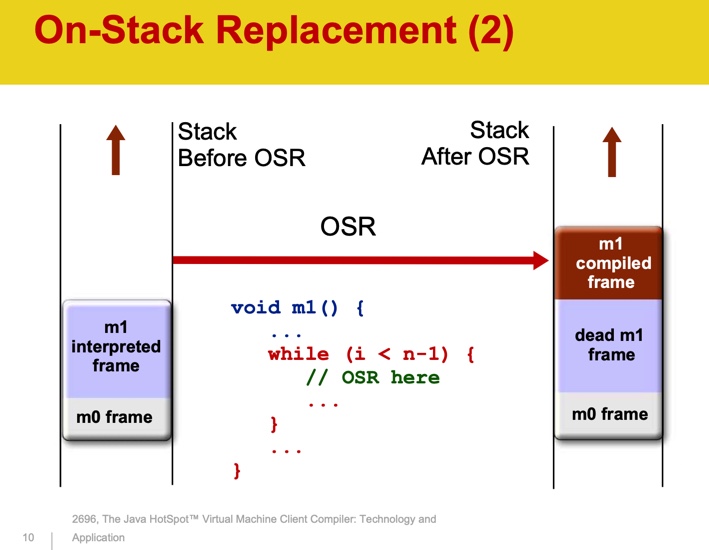
Quelle: Der Java HotSpotTM-Clientcompiler für virtuelle Maschinen: Technologie und Anwendung
Die Attribute "s" und "!" Ich denke, sie brauchen keine Erklärung.
Das Attribut "b" bedeutet, dass die Kompilierung nicht im Hintergrund stattgefunden hat und in modernen Versionen der JVM nicht zu finden ist.
Das Attribut "n" bedeutet, dass die kompilierte Methode ein Wrapper um eine native Methode ist.
Das Feld tiered_level enthält die Ebenennummer, auf der der Code kompiliert wurde, oder kann leer sein, wenn die gestufte Kompilierung deaktiviert ist.
Das Feld Methodenname enthält den Namen der kompilierten Methode oder den Namen der Methode, die die kompilierte Schleife enthält.
Das Größenfeld enthält die Größe des kompilierten Bytecodes und nicht die Größe des resultierenden Maschinencodes. Die Größe ist in Bytes.
Das Deopt-Feld wird nicht in jeder Nachricht angezeigt, es enthält den Namen der durchgeführten Deoptimierung und kann Nachrichten wie "Nicht betreten" und "Zombie gemacht" enthalten.
Manchmal erscheinen die folgenden Einträge im Protokoll: Zeitstempel compile_id COMPILE SKIPPED: Grund. Sie bedeuten, dass beim Kompilieren der Methode ein Fehler aufgetreten ist. Es gibt Zeiten, in denen dies erwartet wird:
- Code-Cache gefüllt - Der Code-Cache-Speicherbereich muss vergrößert werden.
- Gleichzeitiges Laden von Klassen - Die Klasse wurde zur Kompilierungszeit geändert.
In allen Fällen, mit Ausnahme eines Code-Cache-Überlaufs, versucht die JVM erneut zu kompilieren. Wenn dies nicht der Fall ist, können Sie versuchen, den Code zu vereinfachen.
Falls der Prozess ohne das Flag -XX: + PrintCompilation gestartet wurde, können Sie den Kompilierungsprozess mit dem Dienstprogramm jstat anzeigen . Jstat bietet zwei Optionen zum Anzeigen von Kompilierungsinformationen.
Der Parameter -compiler zeigt eine Zusammenfassung der Compileroperation an (5003 ist die Prozess-ID):
% jstat -compiler 5003 Compiled Failed Invalid Time FailedType FailedMethod 206 0 0 1.97 0
Dieser Befehl zeigt auch die Anzahl der Methoden an, die nicht kompiliert werden konnten, und den Namen der letzten Methode.
Der Parameter -printcompilation gibt Informationen zur zuletzt kompilierten Methode aus. In Kombination mit dem zweiten Parameter, der Wiederholungsperiode der Operation, können Sie den Kompilierungsprozess über die Zeit beobachten. Im folgenden Beispiel wird der Befehl -printcompilation jede Sekunde (1000 ms) ausgeführt:
% jstat -printcompilation 5003 1000 Compiled Size Type Method 207 64 1 java/lang/CharacterDataLatin1 toUpperCase 208 5 1 java/math/BigDecimal$StringBuilderHelper getCharArray
Pläne für den zweiten Teil
Im nächsten Teil werden wir uns die Zählerschwellen ansehen, bei denen die JVM mit dem Kompilieren beginnt, und wie Sie sie ändern können. Wir werden auch untersuchen, wie die JVM die Anzahl der Compiler-Threads auswählt, wie Sie sie ändern können und wann Sie dies tun sollten. Lassen Sie uns zum Schluss einen kurzen Blick auf einige der vom JIT-Compiler durchgeführten Optimierungen werfen.
Referenzen und Links
- Java-Leistung: Ausführliche Hinweise zum Optimieren und Programmieren von Java 8, 11 und darüber hinaus, Scott Oaks. ISBN: 978-1-492-05611-9.
- Java optimieren: Praktische Techniken zur Verbesserung der Leistung von JVM-Anwendungen, Benjamin J. Evans, James Gough und Chris Newland. ISBN: 978-1-492-02579-5.
- JEP 197: Segmentierter Code-Cache
- Der Java HotSpotTM-Client-Compiler für virtuelle Maschinen: Technologie und Anwendung