
Manchmal dauert der Timeout-Prozess Tage bis Wochen, bis die wahren Ursachen identifiziert und behoben werden können. Wenn Sie diesen Prozess nur um wenige Stunden beschleunigen, werden die Verluste bereits erheblich reduziert. Um eine Präsentation darüber zu veranschaulichen, wie Ingenieure ein Problem lösen, werfen wir einen Blick auf synthetische Daten von nur 20 Sensoren unten. In diesem Diagramm gibt es zwei Sensoren, die statistisch stark miteinander verbunden sind. Nehmen wir an, einer von ihnen ist die eigentliche Ursache für Auslöseereignisse.
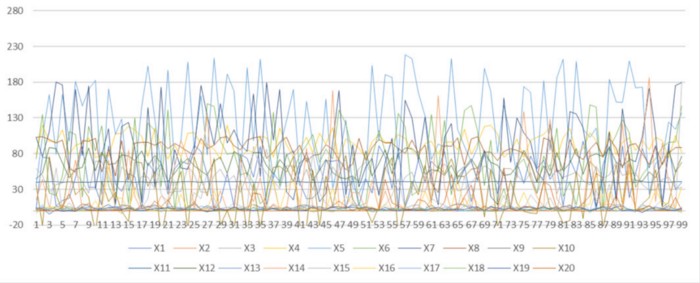
Synthetische Daten zur Simulation von Messwerten von Pflanzensensoren In
der Grafik ist es leider schwierig festzustellen, welche zwei Sensoren miteinander verbunden sind, oder? Da eine kleine Öl- und Gasanlage über 1.000 bis 3.000 Sensoren verfügt, ist dies einer der wirklichen Engpässe für O & M-Ingenieure (einschließlich mir) bei der Identifizierung solcher Sensoren und Ursachen. Denken Sie daran, Millionen von Dollar können gespart werden, wenn wir diese Beziehungen schneller finden können.
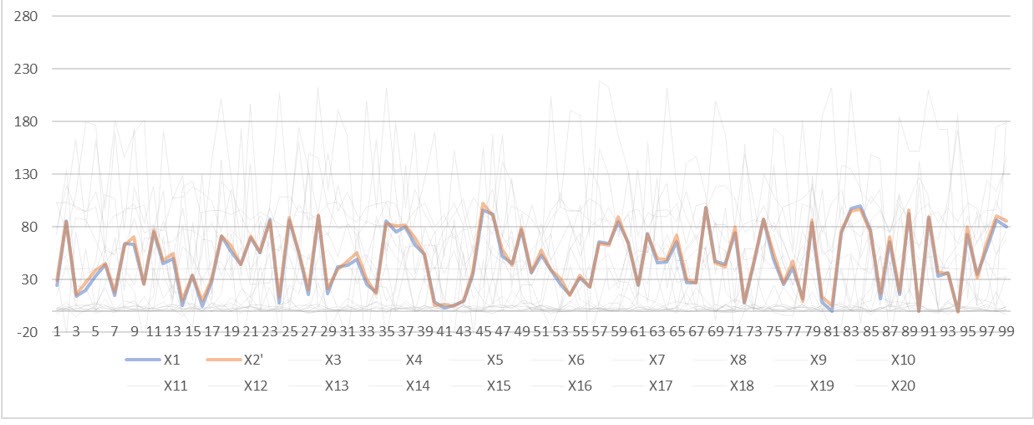
Zwei statistisch verwandte Sensoren von 20 anderen gängigen Sensoren
Ich werde Ihnen zwei Techniken vorstellen, mit denen wir versucht haben, einen akzeptablen Erfolg zu erzielen, um unter anderem die Beziehung zwischen diesen beiden passenden Sensoren aufzuzeigen. Lassen Sie mich zunächst erklären, warum dies für Ingenieure und Bediener wichtig ist.
Erstens ist es für jeden Ausfall in einer modernen Öl- und Gasanlage richtig, dass der Kontrollraum über ein ausgeklügeltes Kontrollsystem verfügt, das die Markierung "First Lockout" anzeigen kann. Dies ist das „erste Etikett“ des Sensors, das das Auslöseereignis auslöst (z. B. Alarm für hohen Auslassdruck des Kompressors, Alarm bei niedrigem und niedrigem Druck am kritischen Abscheider).
Bedeutung
Dieser erste Sperrsensor ist für O & M-Ingenieure sehr wichtig, um mögliche Ursachen für Anlagenstillstände zu untersuchen. In den meisten Fällen können Ingenieure und Bediener das Problem der Anlagenabschaltung einfach durch Betrachten dieser ersten Sperrmarkierung lösen. In vielen Fällen wird uns dies jedoch nicht viel bringen, da die Öl- und Gasverarbeitung so komplex ist, dass das Auftreten dieser ersten Blockierungsmarke das letzte ist, was passiert, während wir wissen möchten, was passiert ist, bevor es ausgelöst wurde.
Erste Lösung: hierarchisches Clustering
Sobald wir den ersten Blockierungssensor und die Zeitspanne vor dem Abschaltereignis untersucht haben, können wir anhand dieser Informationen eine Clustering-Methode durchführen, um festzustellen, welche Sensoren sich wie die ersten Blockierungssensoren verhalten. Wir glauben, dass hierarchisches Clustering und Dendrogrammgenerierung ein nützlicher Visualisierungsansatz ist, der einem nicht datenwissenschaftlichen Benutzer Informationen bereitstellen kann. Ein Beispiel ist in der folgenden Abbildung dargestellt.
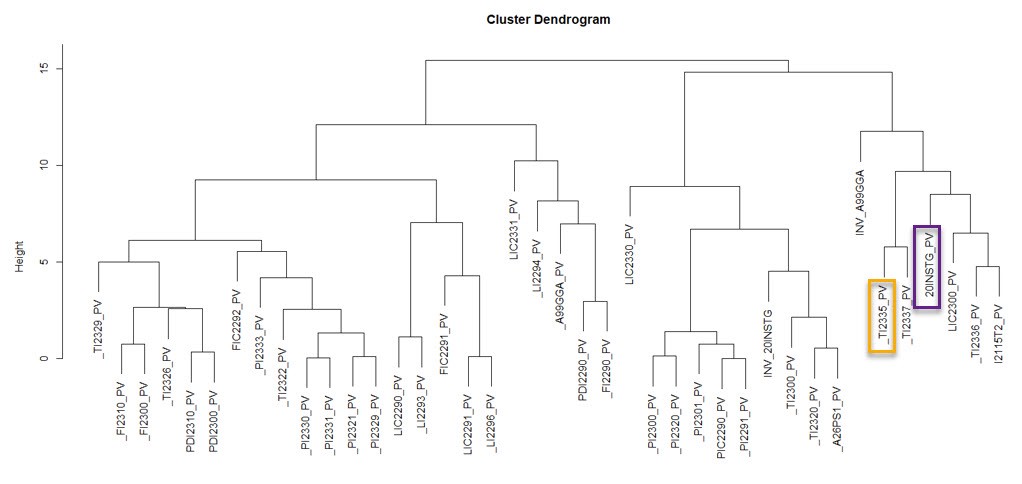
Dendrogramm-Clustering nach hierarchischer Clustering-Methode
Diese Methode ist nicht nur nützlich, um die Grundursache eines ungeplanten Ausfalls zu ermitteln, sondern kann auch angewendet werden, um zugehörige Sensoren zu finden, die sich anders verhalten als normalerweise. Angenommen, der TI2335-Sensor zeigt einen unbekannten Temperaturanstieg im Saugwäscher an und wir möchten herausfinden, was die Hauptursache für den abnormalen Anstieg ist. Mit dieser Methode können wir die geeigneten Sensoren finden, die wir betrachten können. Anstatt zwischen 1000 und 3000 Sensoren zu suchen, können sich Ingenieure nur auf Sensoren konzentrieren, die sich in der Nähe abnormaler Sensoren befinden, oder auf die ersten blockierenden Sensoren. Dann kann die Fehlerbehebungszeit erheblich reduziert werden. Leider ist diese Methode nicht in allen Fällen anwendbar. Also haben wir einige andere Methoden ausprobiert.
Zweite Lösung: Granger-Kausaltest

Sir Clive Granger
Der Granger- Kausaltest ist ein statistischer Hypothesentest zur Bestimmung, ob ein Zeitreihendatensatz zur Vorhersage einer anderen Reihe nützlich ist. Es wurde 1969 von Sir Clive Granger veröffentlicht und erhielt 2003 den Nobelpreis für seine Arbeit.
Wenn ein Ökonom Statistiken sammelt und in Variablen umwandelt, tritt ein häufiges Problem auf. Er kann nicht bestimmen, welche Variable unabhängig und welche abhängig ist. Mit anderen Worten, wir wissen nicht, welcher Faktor den anderen Faktor verursacht.
Ein Beispiel ist klarer: Wenn Ökonomen versuchen, einen Zusammenhang zwischen der Bruttoinlandsproduktion (BIP) und dem Aktienindex zu finden. Wenn die Wirtschaft floriert, steigen auch das BIP und der Aktienindex. Wenn die Wirtschaft eines Landes rückläufig ist, werden auch das BIP und der Aktienindex sinken. Eins verursacht jedoch das andere. Einige argumentieren, dass das BIP die unabhängige Variable sein sollte, da es die reale Inlandsproduktion und den realen Inlandsverbrauch widerspiegelt. Im Gegenteil, andere glauben, dass je höher der Aktienindex, desto mehr Anleger in die Wirtschaft des Landes investieren werden, da dies die Zuverlässigkeit ist, auf die Anleger immer achten. Dieses Problem führt zu einer völlig anderen Finanzstrategie des Landes - in die Entwicklung der lokalen Wirtschaft oder in die Entwicklung des Aktienmarktes zu investieren.

Granger Ursache-Wirkungs-Test Sir Granger konnte einen statistischen Weg finden, um zu testen, ob eine Variable eine andere beeinflusst, ob es sich um eine oder zwei Richtungen handelt, und gewann dafür den Nobelpreis. Wenn ein solches Problem auftritt, kann jemand diesen Test verwenden, um nach anderen seltsamen Problemen zu suchen. Zum Beispiel, um herauszufinden, was vorher kam: das Huhn oder das Ei in Thurman und Fischer (1988).
Obwohl unser Problem nicht so bizarr ist wie die oben beschriebenen, als ich versuchte, den Granger-Kausaltest in unserem Problem zu verwenden. Das heißt, mit diesem Test können Sie einige Sensoren aussortieren, die nicht miteinander in Beziehung stehen, und die zugehörigen Sensoren anhand des erhaltenen p-Werts bewerten. Für eine Gruppe von Prozessparametern ist das Ergebnis ziemlich zufriedenstellend.
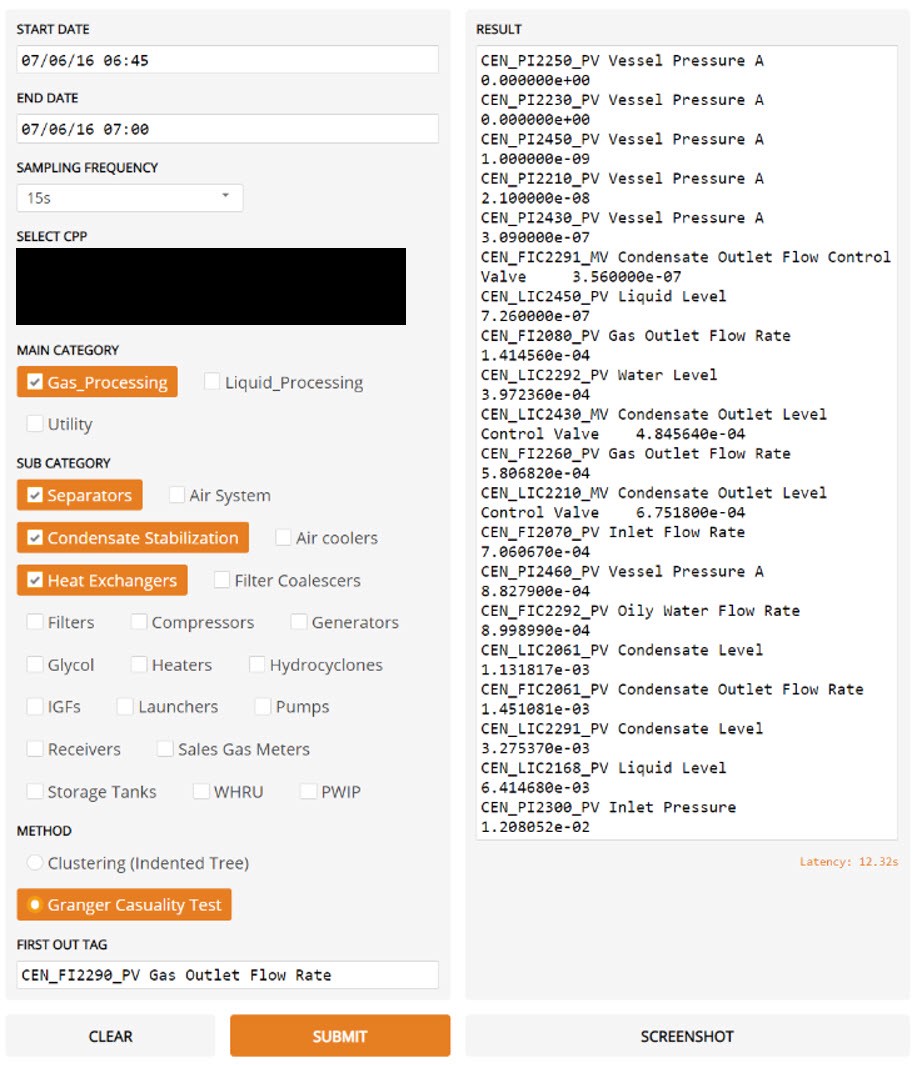
Um eine nützliche GUI für die Interaktion mit Benutzern zu erstellen, die keine Programmierkenntnisse haben, haben wir die Gradio- Bibliothek verwendet und im Prototyping-Stadium wunderschöne Grafiken erstellt.
Fazit
Nach dem, was ich bisher versucht habe, funktioniert hierarchisches Clustering gut mit dem Gasverarbeitungsteil, während der Granger-Kausaltest gut mit dem Flüssigkeitsverarbeitungsteil funktioniert. Ein Grund dafür ist, dass es bei einem flüssigen Prozess aufgrund der Natur einer inkompressiblen Flüssigkeit normalerweise eine Weile dauert, bis die Sensoren auf eine Änderung des Prozesses reagieren. Dies ist in der Gasphase nicht der Fall.
Auf diese Weise werden Data Science-Methoden angewendet, um reale Öl- und Gasprobleme zu lösen. Wenn Sie dies lernen und DS auf das Projekt anwenden möchten, an dem Sie gerade arbeiten, warten wir auf Sie.

Andere Berufe und Kurse
BERUF
KURSE
- Java-Entwicklerberuf
- Frontend-Entwicklerberuf
- Beruf Ethischer Hacker
- C ++ Entwicklerberuf
- Profession Unity Spieleentwickler
- Der Beruf des iOS-Entwicklers von Grund auf neu
- Der Beruf des Android-Entwicklers von Grund auf neu
- Beruf Webentwickler
KURSE
- Kurs für maschinelles Lernen
- Fortgeschrittenenkurs "Maschinelles Lernen Pro + Deep Learning"
- Python für Webentwicklungskurs
- JavaScript
- « Machine Learning Data Science»
- DevOps