Gegenwärtig ist einer der Trends bei der Untersuchung grafischer neuronaler Netze die Analyse der Funktionsweise solcher Architekturen, der Vergleich mit nuklearen Methoden, die Bewertung der Komplexität und die Verallgemeinerungsfähigkeit. All dies hilft, die Schwächen bestehender Modelle zu verstehen und schafft Raum für neue.
Die Arbeit zielt darauf ab, zwei Probleme zu untersuchen, die mit graphischen neuronalen Netzen verbunden sind. Zunächst geben die Autoren Beispiele für Diagramme, die sich in ihrer Struktur unterscheiden, jedoch sowohl für einfache als auch für leistungsfähigere GNNs nicht zu unterscheiden sind . Zweitens haben sie den Generalisierungsfehler für graphneurale Netze genauer als die VC-Grenzen begrenzt.
Einführung
Graphneurale Netze sind Modelle, die direkt mit Graphen arbeiten. Mit ihnen können Sie Informationen über die Struktur berücksichtigen. Ein typisches GNN enthält eine kleine Anzahl von Schichten, die nacheinander angewendet werden, wobei die Scheitelpunktdarstellungen bei jeder Iteration aktualisiert werden. Beispiele für gängige Architekturen: GCN , GraphSAGE , GAT , GIN .
Der Prozess der Aktualisierung von Vertex-Einbettungen für jede GNN-Architektur kann durch zwei Formeln zusammengefasst werden:

wo AGG üblicherweise eine Funktion invariant Permutationen ist ( Summe , Mittelwert , max etc.), COMBINE ist eine Funktion, kombiniert die Darstellung eines Scheitels und seine Nachbarn.

Fortgeschrittenere Architekturen können zusätzliche Informationen wie Kantenmerkmale, Kantenwinkel usw. berücksichtigen.
Der Artikel berücksichtigt die GNN-Klasse für das Diagrammklassifizierungsproblem. Diese Modelle sind wie folgt aufgebaut:
Erstens sind Eckpunkte Einbettungen unter Verwendung von L Schritten von Graphfaltungen
(, sum, mean, max)
GNN:
(LU-GNN). GCN, GraphSAGE, GAT, GIN
CPNGNN, , 1 d, d - ( port numbering)
DimeNet, 3D-,
LU-GNN
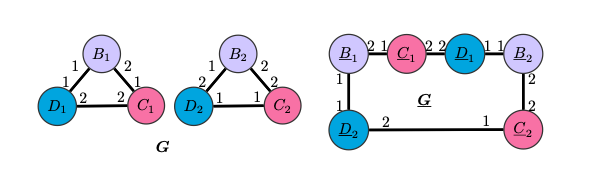
G G LU-GNN, , , readout-, . CPNGNN G G, .
CPNGNN

, “” , CPNGNN .
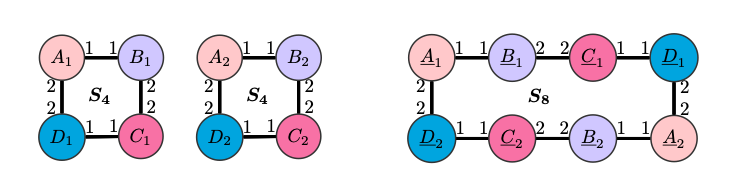
S8 S4 , , ( ), , , CPNGNN readout-, , . , .
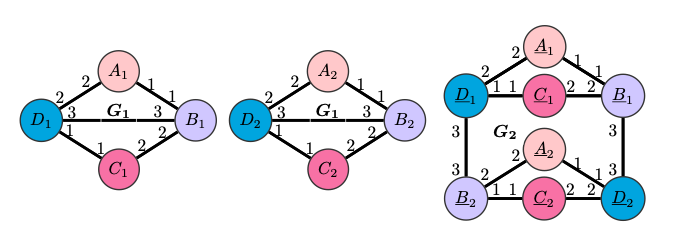
CPNGNN G2 G1. , DimeNet , , , , 
 .
.
DimeNet

DimeNet G4 , G3, . , . , G4 G3 S4 S8, , , DimeNet S4 S8 .
GNN
. , , .
GNN, :
DimeNet
message-



 , c - i- v, t - .
, c - i- v, t - .
:

readout-
.
: LU-GNN,

 - ,
- ,  - v, ,
- v, ,  . ,
. , 
 ,
,  .
.  GNN.
GNN.
. 
 .
.
 - GNN
- GNN  ,
,  - ,
- ,  .
.
,  ,
, - :
![Verlust _ {\ gamma} \ left (a \ right) = \ mathbb {I} \ left [a> 0 \ right] + (1 + \ frac {a} {\ gamma}) \ mathbb {I} \ left [a \ in \ left [\ gamma, 0 \ right] \ right].](https://habrastorage.org/getpro/habr/upload_files/10f/f87/63c/10ff8763ced82f8bcc4a3f1514442cd6.svg)
GNN 
 :
:

, , , , GNN . , (GNN, ), , , .
, :
,
( )

 - “ ”:
- “ ”:  , r - , d - , m - , L - ,
, r - , d - , m - , L - ,  - ,
- ,

( ), . , , , , , , .
Beweise und detailliertere Informationen finden Sie im Originalartikel oder in einem Bericht eines der Autoren.