
Betrachten Sie also einen gerichteten gewichteten Graphen. Lassen Sie den Graphen n Eckpunkte haben. Jedes Eckpunktpaar entspricht einem gewissen Gewicht (Übergangswahrscheinlichkeit).

Es ist zu beachten, dass typische Webgraphen eine homogene diskrete Markov-Kette sind, für die die Unzersetzbarkeitsbedingung und die Aperiodizitätsbedingung erfüllt sind.
Schreiben wir die Kolmogorov-Chapman-Gleichung:
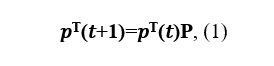
wobei P die Übergangsmatrix ist.
Angenommen, es gibt eine Grenze. Der
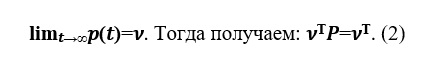
Vektor v wird als stationäre Wahrscheinlichkeitsverteilung bezeichnet.
Aus Beziehung (2) wurde vorgeschlagen, nach dem Ranking-Vektor von Webseiten im Brin-Page-Modell zu suchen.
Da v die Grenze ist, kann

die stationäre Verteilung nach der Methode der einfachen Iterationen (MPI) berechnet werden.
Um von einer Webseite zur nächsten zu gelangen, muss der Benutzer mit einer gewissen Wahrscheinlichkeit auswählen, zu welchem Link er wechseln möchte. Wenn das Dokument mehrere ausgehende Links enthält, wird davon ausgegangen, dass der Benutzer mit der gleichen Wahrscheinlichkeit auf jeden von ihnen klickt. Und schließlich gibt es noch den Teleportationskoeffizienten, der uns zeigt, dass der Benutzer mit einiger Wahrscheinlichkeit vom aktuellen Dokument auf eine andere Seite wechseln kann, die nicht unbedingt direkt mit der Seite zusammenhängt, auf der wir uns gerade befinden. Lassen Sie den Benutzer mit der Wahrscheinlichkeit δ teleportieren, dann nimmt Gleichung (1) die Form an.

Für 0 <δ <1 hat die Gleichung garantiert eine eindeutige Lösung. In der Praxis wird normalerweise eine Gleichung mit δ = 0,15 verwendet, um den PageRank zu berechnen.
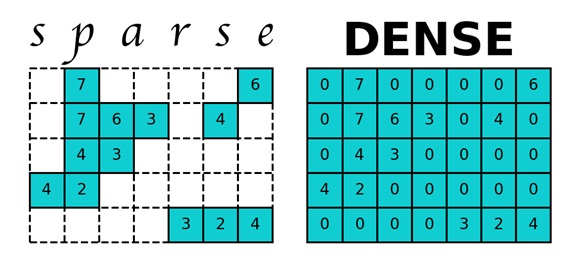
Betrachten Sie ein Google-Webdiagramm von einem Site-Link. Dieses Webdiagramm enthält 875713 Eckpunkte. Dies bedeutet, dass Sie für eine zweidimensionale Matrix P 714 GB Speicher zuweisen müssen. Der Arbeitsspeicher moderner Computer ist um eine Größenordnung geringer, sodass der Computer anfängt, Festplattenspeicher zu verwenden, dessen Zugriff die Arbeit des PageRank-Berechnungsprogramms erheblich verlangsamt. Die Matrix P ist jedoch eine spärliche Matrix - eine Matrix mit überwiegend null Elementen. Um mit Sparse-Matrizen in Python zu arbeiten, wird das Sparse-Modul aus der Scipy-Bibliothek verwendet, wodurch die Matrix P viel weniger Speicherplatz beansprucht.
Wenden wir diesen Algorithmus auf diese Daten an. Knoten sind Webseiten und gerichtete Kanten sind Hyperlinks zwischen ihnen.
Importieren wir zunächst die benötigten Bibliotheken:
import cvxpy as cp
import numpy as np
import pandas as pd
import time
import numpy.linalg as ln
from scipy.sparse import csr_matrix
Fahren wir nun mit der Implementierung selbst fort:
#
data = pd.read_csv("web-Google.txt", names = ['i','j'], sep="\t", header=None)
NODES = 916428
EDGES = 5105039
#
NEW = csr_matrix((np.ones(len(data['i'])),(data['i'],data['j'])),shape=(NODES,NODES))
b = NEW.sum(axis=1)
NEW = NEW.transpose()
#
p0 = np.ones((NODES,1))/NODES
eps = 10**-5
delta = 0.15
ERROR = True
k = 0
#
while (ERROR == True):
with np.errstate(divide='ignore'):
z = p0 / b
p1 = (1-delta) * NEW.dot(csr_matrix(z)) + delta * np.ones((NODES,1))/NODES
if (ln.norm(p1-p0) < eps):
ERROR = False
k = k + 1
# PageRank
p0 = p1
In den Diagrammen können wir sehen, wie der Vektor p zu einem stationären Zustand v kommt :

Mit dem PageRank-Vektor können Sie auch den Wahlsieger bestimmen. Eine kleine Untergruppe der Wikipedia-Mitwirkenden sind Administratoren, die Benutzer sind, die Zugriff auf zusätzliche technische Funktionen haben, um die Wartung zu unterstützen. Damit ein Benutzer Administrator werden kann, wird eine Administratoranfrage gestellt, und die Wikipedia-Community entscheidet durch öffentliche Kommentare oder Abstimmungen, wer in die Administratorposition befördert werden soll.
Das PageRank-Problem kann auch auf ein Minimierungsproblem reduziert und mithilfe der Frank-Wolfe-Methode mit bedingtem Gradienten gelöst werden, die Folgendes umfasst: Wählen Sie einen der Scheitelpunkte des Simplex aus und legen Sie einen Ausgangspunkt an diesem Scheitelpunkt fest. Implementierung dieser Methode auf Daten - der Link ist unten dargestellt:
#
data = pd.read_csv("grad.txt", names = ['i','j'], sep="\t", header=None)
NODES = 6301
EDGES = 20777
#
NEW = csr_matrix((np.ones(len(data['i'])),(data['i'],data['j'])),shape=(NODES,NODES))
b = NEW.sum(axis=1)
NEW = NEW.transpose()
e = np.ones(NODES)
with np.errstate(divide='ignore'):
z = e / b
NEW = NEW.dot(csr_matrix(z))
#
eps = 0.05
k=0
a_0 = 1
y = np.zeros((NODES,1))
p0 = np.ones((NODES,1))/NODES
#
p0[0] = 0.1
y[np.argmin(df(p0))] = 1
p1 = (1-2/(1+k))*p0 + 2/(1+k)*y
#
while ((ln.norm(p1-p0) > eps)):
y = np.zeros((NODES,1))
k = k + 1
p0 = p1
y[np.argmin(df(p0))] = 1
p1 = (1-2/(1+k))*p0 + 2/(1+k)*y

Für den effektiven Betrieb einer realen Suchmaschine ist die Geschwindigkeit der Berechnung des PageRank-Vektors wichtiger als die Genauigkeit seiner Berechnung. Mit MPI können Sie die Genauigkeit nicht aus Gründen der Rechengeschwindigkeit opfern. Der Monte-Carlo-Algorithmus hilft in gewissem Maße, dieses Problem zu lösen. Wir starten einen virtuellen Benutzer, der durch die Seiten der Websites wandert. Durch das Sammeln von Statistiken über ihre Besuche auf den Seiten der Website erhalten wir nach ziemlich langer Zeit für jede Seite, wie oft der Benutzer sie besucht hat. Durch Normalisieren dieses Vektors erhalten wir den gewünschten PageRank-Vektor. Lassen Sie uns zeigen, wie dieser Algorithmus mit bereits verwendeten Daten funktioniert .
#
def get_edges(m, i):
if (i == NODES):
return random.randint(0, NODES)
else:
if (len(m.indices[m.indptr[i] : m.indptr[i+1]]) != 0):
return np.random.choice(m.indices[m.indptr[i] : m.indptr[i+1]])
else:
return NODES
#
data = pd.read_csv("web-Google.txt", names = ['i','j'], sep="\t", header=None)
NODES = 916428
EDGES = 5105039
NEW = csr_matrix((np.ones(len(data['i'])),(data['i'],data['j'])),shape=(NODES,NODES))
#c , total –
for total in range(1000000,2000000,100000):
#
k = random.randint(0, NODES)
# PageRank
ans = np.zeros(NODES+1)
margin2 = np.zeros(NODES)
ans_prev = np.zeros(NODES)
for t in range(total):
j = get_edges(NEW, k)
ans[j] = ans[j]+1
k = j
#
ans = np.delete(ans, len(ans)-1)
ans = ans/sum(ans)
for number in range(len(ans)):
margin2[number] = ans[number] - ans_prev[number]
ans_prev = ans
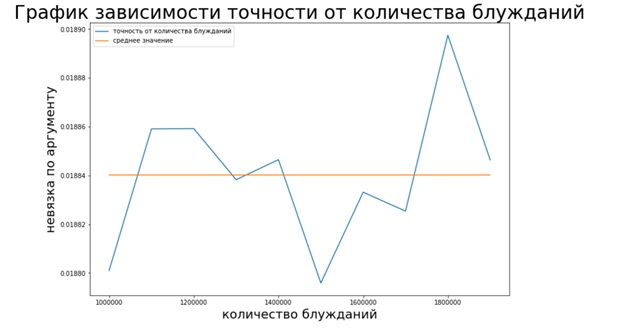
Wie aus der Grafik ersichtlich ist, ist die Monte-Carlo-Methode im Gegensatz zu den beiden vorherigen Methoden nicht stabil (es gibt keine Konvergenz), sie hilft jedoch, den Page Rank-Vektor zu schätzen, ohne viel Zeit zu benötigen.
Schlussfolgerung: Daher haben wir die Hauptalgorithmen zur Bestimmung des PageRank von Webgraphen betrachtet. Bevor Sie mit dem Entwerfen einer Website beginnen, sollten Sie sicherstellen, dass der PageRank nicht verschwendet wird, indem Sie die folgenden Punkte beachten:
- Interne Links zeigen, wie sich die „Link-Leistung“ auf Ihrer Website ansammelt. Konzentrieren Sie sich daher auf die wichtigen Informationen auf der Startseite der Website, da die „Startseite“ der Website den stärksten PageRank aufweist.
- Verwaiste Seiten, die nicht von anderen Seiten Ihrer Site verlinkt sind. Versuchen Sie, solche Seiten zu vermeiden.
- Es ist erwähnenswert, externe Links zu erwähnen, wenn diese für Ihren Website-Besucher nützlich sind.
- Unterbrochene eingehende Links verringern das Gesamtgewicht der Seite, sodass Sie sie regelmäßig überwachen und gegebenenfalls „reparieren“ müssen.
Dies bedeutet jedoch nicht, dass Sie von PageRank besessen sein sollten. Beachten Sie jedoch, dass Sie die Site für PageRank optimieren, indem Sie beim Erstellen der Site auf die Struktur der Site sowie auf die Funktionen interner und externer Links achten.