CREATE TABLE task AS
SELECT
id
, (random() * 100)::integer person -- 100
, least(trunc(-ln(random()) / ln(2)), 10)::integer priority -- 2
FROM
generate_series(1, 1e5) id; -- 100K
CREATE INDEX ON task(person, priority);
Das Wort "ist" in SQL wird zu
EXISTS
- hier ist die einfachste Version und beginnen wir:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
);

Alle Planbilder sind anklickbar
Bisher sieht alles gut aus, aber ...
EXISTS + IN
... dann kamen sie zu uns und baten nicht nur
priority = 10
8 und 9 als "super" aufzunehmen :
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority IN (10, 9, 8)
);

Sie lesen 1,5-mal mehr und es hat sich auch auf die Ausführungszeit ausgewirkt.
ODER + EXISTIERT
Lassen Sie uns versuchen, unser Wissen zu nutzen, dass es
priority = 8
viel wahrscheinlicher ist, einen Rekord mit mehr als 10 zu erreichen:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
) OR
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
) OR
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
);

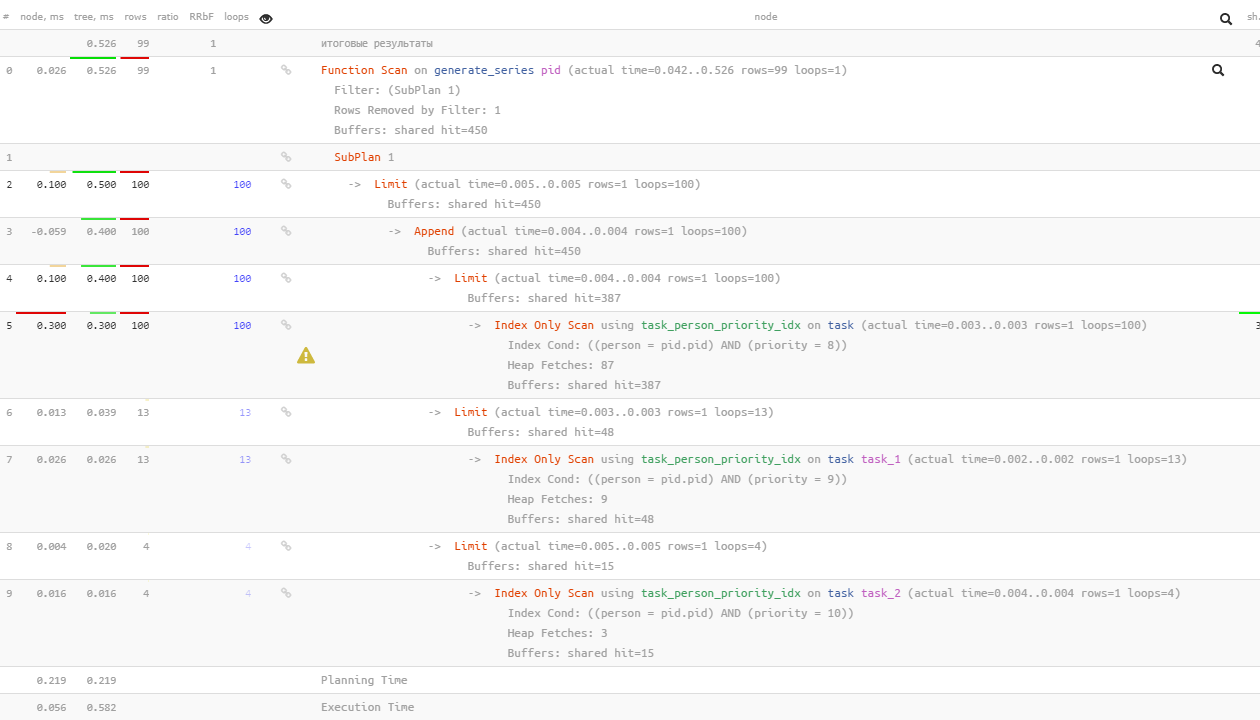
Beachten Sie, dass PostgreSQL 12 bereits intelligent genug ist, um nachfolgende
EXISTS
Abfragen nur für diejenigen durchzuführen, die von den vorherigen nach 100 Suchen nach Wert 8 "nicht gefunden" wurden - nur 13 für Wert 9 und nur 4 für 10.
FALL + EXISTIERT + ...
In früheren Versionen kann ein ähnliches Ergebnis erzielt werden, indem die folgenden Abfragen unter "CASE" ausgeblendet werden:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
CASE
WHEN
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
) THEN TRUE
ELSE
CASE
WHEN
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
) THEN TRUE
ELSE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
)
END
END;
EXISTS + UNION ALL + LIMIT
Das gleiche, aber Sie können etwas schneller werden, wenn Sie den "Hack" verwenden
UNION ALL + LIMIT
:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
LIMIT 1
)
UNION ALL
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
LIMIT 1
)
UNION ALL
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
LIMIT 1
)
LIMIT 1
);
Richtige Indizes sind der Schlüssel zum Zustand der Datenbank
Betrachten wir das Problem nun von einer ganz anderen Seite. Wenn wir sicher sind, dass die
task
Anzahl der Datensätze, die wir finden möchten, um ein Vielfaches geringer ist als der Rest , erstellen wir einen geeigneten Teilindex. Zur gleichen Zeit gehen wir direkt von der "Punkt" -Aufzählung
8, 9, 10
zu
>= 8
:
CREATE INDEX ON task(person) WHERE priority >= 8;
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority >= 8
);

Ich musste 2 mal schneller und 1,5 mal weniger lesen!
Aber wahrscheinlich, um alle geeigneten auf
task
einmal zu subtrahieren - wird es noch schneller sein?
SELECT DISTINCT
person
FROM
task
WHERE
priority >= 8;

Weit davon entfernt, immer und schon gar nicht in diesem Fall - denn statt 100 Lesungen der ersten verfügbaren Datensätze müssen wir mehr als 400 lesen!
Und um nicht zu erraten, welche der Abfrageoptionen effektiver ist, sondern um sie sicher zu kennen, verwenden Sie EXPLAIN.tensor.ru .