MegaFon hat die Möglichkeit gewählt, mit instabiler Kommunikation als einem seiner wichtigen Wachstumspunkte zu arbeiten. Es gibt Orte in Russland, an denen die Kommunikation vorübergehend unterbrochen wird oder für lange Zeit verloren geht. Und es ist notwendig, dass die Anwendung auch in diesem Fall fehlerfrei funktioniert.
Valentin sprach auf der Apps Live 2020-Konferenz der Entwickler mobiler Anwendungen darüber, wie diese Aufgabe in den letzten fünf Monaten ausgeführt wurde, wie die Architektur des Projekts ausgewählt und implementiert wurde, welche Technologien verwendet wurden, was sie erreichten und was für die Zukunft geplant war.

Eine Aufgabe
Das Unternehmen sagte - wir gehen offline, damit der Benutzer erfolgreich mit der Anwendung in einer instabilen Netzwerkverbindung interagieren kann. Als Entwicklungsteam mussten wir zuerst Offline garantieren - die Anwendung funktioniert auch mit einem instabilen oder völlig fehlenden Internet. Heute werde ich Ihnen erzählen, wo wir angefangen haben und welche ersten Schritte wir in diese Richtung unternommen haben.
Technologie-Stack
Neben der Standard-MVC-Architektur verwenden wir:
Swift + Objective-C
Der größte Teil des Codes (80% unseres Projekts) ist in Objective-C geschrieben. Und schon schreiben wir neuen Code in Swift.
Modulare Architektur
Wir unterteilen die globalen Codeblöcke logisch in Module, um eine schnellere Kompilierung, Projektstart und Entwicklung zu erreichen.
Submodule (Bibliotheken)
Wir verbinden alle zusätzlichen Bibliotheken über das Git-Submodul, um mehr Kontrolle über die verwendeten Bibliotheken zu erhalten. Wenn die Unterstützung für einen von ihnen plötzlich aufhört, können wir die Situation daher selbst korrigieren.
Kerndaten für die lokale Speicherung
Bei der Auswahl war das Hauptkriterium für uns die Ursprünglichkeit und Integration in iOS-Frameworks. Und diese Vorteile von Core Data waren entscheidend:
- Speichern Sie den Stapel und die Daten, die wir erhalten, automatisch.
- , ( , ..)
- ;
- ;
- ;
- ;
- UI (FRC);
- (NSPredicates).
UIManaged document
Das UI-Kit verfügt über eine integrierte Klasse namens UIManagedDocument, eine Unterklasse von UIDocument. Der Hauptunterschied besteht darin, dass bei der Initialisierung eines verwalteten Dokuments eine URL für den Speicherort des Dokuments im lokalen oder Remotespeicher angegeben wird. Das Dokumentobjekt erstellt dann sofort einen Kerndatenstapel, mit dem über das Objektmodell (.xcdatamodeld) aus dem Hauptanwendungspaket auf den dauerhaften Speicher des Dokuments zugegriffen werden kann. Es ist bequem und sinnvoll, obwohl wir bereits im 21. Jahrhundert leben:
- UIDocument speichert den aktuellen Status selbst automatisch mit einer bestimmten Frequenz. Für besonders kritische Abschnitte können wir das Speichern manuell auslösen.
- . - — , , - , — , , .
- UIDocument .
- Core data .
- iCloud . , .
- .
- Es wird das dokumentbasierte App-Paradigma verwendet, das das Datenmodell als Container zum Speichern dieser Daten darstellt. Wenn wir uns das klassische MVC-Modell in der Apple-Dokumentation ansehen, können wir sehen, dass Core-Daten genau erstellt wurden, um dieses Modell zu manipulieren und uns dabei zu helfen, mit Daten auf einer höheren Abstraktionsebene zu arbeiten. Auf Modellebene verbinden wir das UIManagedDocument mit dem gesamten erstellten Stack. Wir betrachten das Dokument selbst als einen Container, in dem Kerndaten und alle Daten aus dem Cache (von Bildschirmen, Benutzern) gespeichert werden. Außerdem können es Bilder, Videos, Texte sein - jede Information.
Wir betrachten unsere Anwendung, ihren Start, ihre Benutzerautorisierung und alle ihre Daten als eine Art großes Dokument (Datei), in dem der Verlauf unseres Benutzers gespeichert wird:

Prozess
Wie wir die Architektur entworfen haben
Unser Designprozess erfolgt in mehreren Phasen:
- Analyse der technischen Spezifikationen.
- Rendern eines UML-Diagramms. Wir verwenden hauptsächlich drei Arten von UML-Diagrammen: Klassendiagramm, Flussdiagramm, Sequenzdiagramm. Dies liegt in der direkten Verantwortung der leitenden Entwickler, aber auch Entwickler mit weniger Erfahrung können dies tun. Dies ist sogar willkommen, da Sie so gut in die Aufgabe eintauchen und all ihre Feinheiten lernen können. Dies hilft, Fehler in der technischen Aufgabe zu finden und alle Informationen zur Aufgabe zu strukturieren. Und wir versuchen, den plattformübergreifenden Charakter unserer Anwendung zu berücksichtigen. Wir arbeiten eng mit dem Android-Team zusammen, zeichnen dasselbe Diagramm auf zwei Plattformen und versuchen, die wichtigsten allgemein akzeptierten Entwurfsmuster der vierköpfigen Gruppe zu verwenden.
- Überprüfung der Architektur. In der Regel führt ein Kollege eines benachbarten Teams die Überprüfung und Bewertung durch.
- Implementierung und Test am Beispiel eines UI-Moduls.
- Skalierung. Wenn das Testen erfolgreich ist, skalieren wir die Architektur auf die gesamte Anwendung.
- Refactoring. Um zu überprüfen, ob wir etwas verpasst haben.
Jetzt, nach fünf Monaten der Entwicklung dieses Projekts, kann ich unseren gesamten Prozess in drei Schritten zeigen: Was ist passiert, wie hat es sich verändert und was ist daraus geworden?
Was war
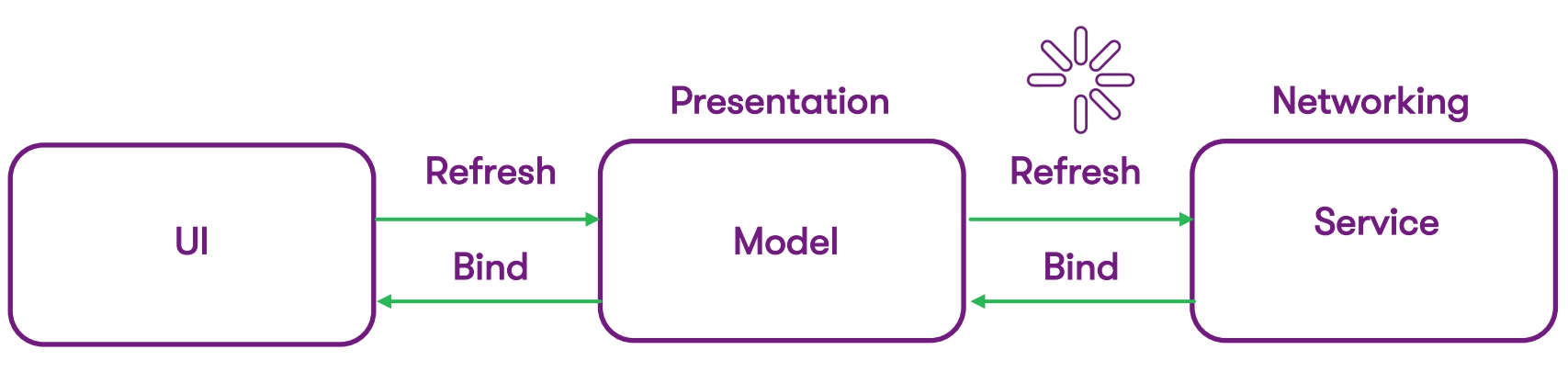
Unser Ausgangspunkt war die Standard-MVC-Architektur - dies sind miteinander verbundene Schichten:
- UI-Ebene, vollständig programmiert mit Ziel C;
- Präsentationsklasse (Modell);
- Die Service-Schicht, in der wir mit dem Netzwerk arbeiten.
Der Aktivitätsindikator befand sich an der Stelle des Diagramms, an der der Prozess des Datenempfangs von der Internetgeschwindigkeit abhängt. Der Benutzer möchte ein schnelles Ergebnis, muss jedoch einige Lader, Indikatoren und andere Signale betrachten. Dies waren unsere Wachstumspunkte in der Benutzererfahrung:
Übergangsphase
Während der Übergangszeit mussten wir das Caching für Bildschirme implementieren. Da die Anwendung jedoch groß ist und viel älteren Objective C-Code enthält, können wir nicht einfach alle Dienste und Modelle durch Einfügen von Swift-Code übernehmen und löschen. Wir müssen berücksichtigen, dass parallel zum Caching noch viele andere Produktaufgaben in der Entwicklung sind.
Wir haben einen schmerzlosen Weg gefunden, um so effizient wie möglich in den aktuellen Code zu integrieren, ohne irgendetwas zu beschädigen, und die erste Iteration so reibungslos wie möglich durchzuführen. Auf der linken Seite des vorherigen Diagramms haben wir alles, was mit Netzwerkanforderungen zu tun hat, vollständig entfernt. Der Dienst kommuniziert jetzt über die Schnittstelle mit der DataSourceFacade. Und jetzt ist dies die Fassade, mit der der Dienst arbeitet. Es erwartet von der DataSource die Daten, die es zuvor vom Netzwerk empfangen hat. In der DataSource selbst ist die Logik zum Extrahieren dieser Daten verborgen.
Auf der rechten Seite des Diagramms haben wir die Datenerfassung in Befehle unterteilt. Das Befehlsmuster zielt darauf ab, einige grundlegende Befehle auszuführen und das Ergebnis zu erhalten. Im Fall von iOS verwenden wir die Erben von NSOperation:
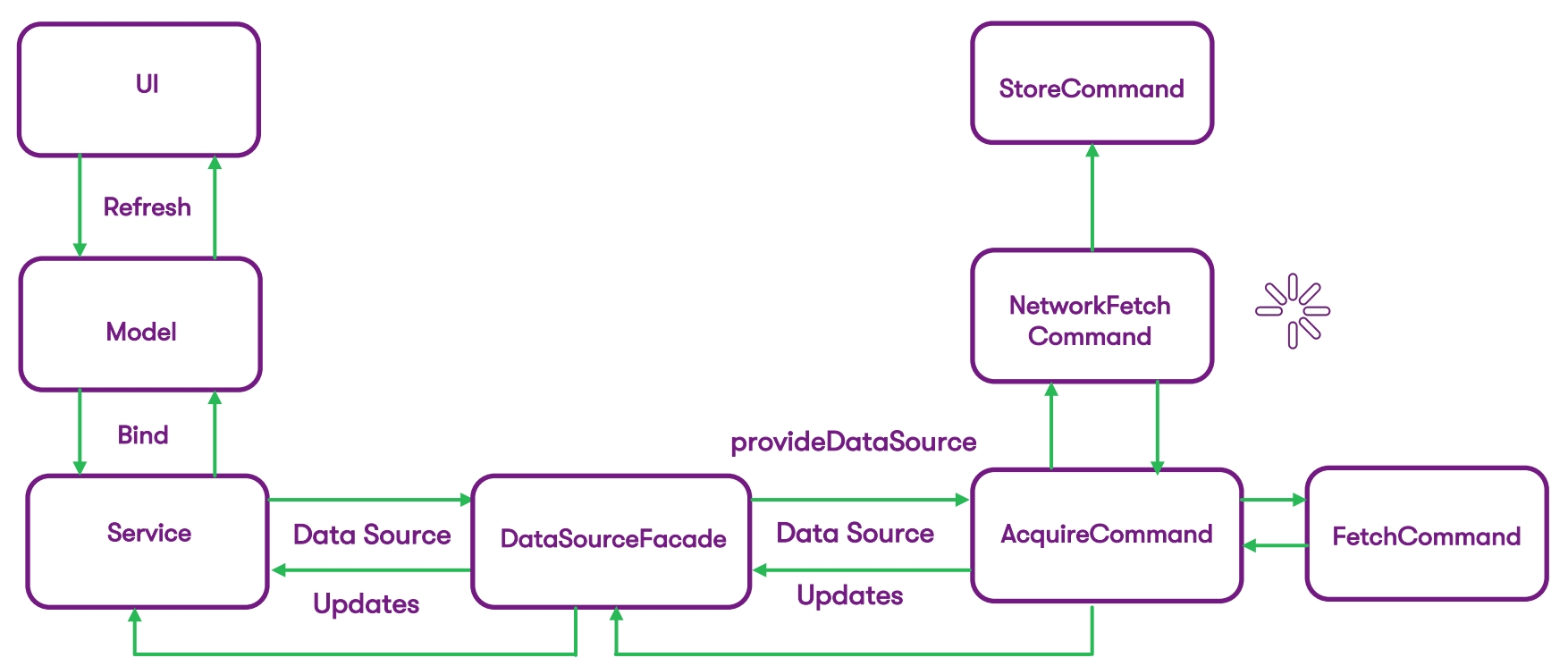
Jeder Befehl, den Sie hier sehen, ist eine Operation, die eine logische Einheit der erwarteten Aktion enthält. Hierbei werden Daten aus einer Datenbank (oder einem Netzwerk) abgerufen und in Kerndaten gespeichert. Der Hauptzweck von AcquireCommand besteht beispielsweise nicht nur darin, die Datenquelle an die Fassade zurückzugeben, sondern es uns auch zu ermöglichen, Code so zu gestalten, dass Daten über die Fassade empfangen werden. Das heißt, die Interaktion mit Operationen verläuft über diese Fassade.
Die Hauptaufgabe der Operationen besteht darin, DataSource-Daten an DataSourceFacade zu übergeben. Natürlich bauen wir die Logik so auf, dass die Daten dem Benutzer so schnell wie möglich angezeigt werden. Normalerweise haben wir innerhalb der DataSourceFacade eine Betriebswarteschlange, in der wir unsere NSOperations starten. Abhängig von den konfigurierten Bedingungen können wir entscheiden, wann Daten aus dem Cache angezeigt und wann aus dem Netzwerk empfangen werden sollen. Bei der ersten Anforderung einer Datenquelle in der Fassade gehen wir zur Core-Datendatenbank, rufen die Daten von dort über FetchCommand ab (falls vorhanden) und geben sie sofort an den Benutzer zurück.
Gleichzeitig starten wir eine parallele Anforderung für Daten über das Netzwerk. Wenn diese Anforderung ausgeführt wird, wird das Ergebnis in die Datenbank eingegeben, dort gespeichert und anschließend erhalten wir eine Aktualisierung unserer DataSource. Dieses Update ist bereits in der Benutzeroberfläche enthalten. Auf diese Weise minimieren wir die Wartezeit für Daten, und der Benutzer, der sie sofort empfängt, bemerkt den Unterschied nicht. Die aktualisierten Daten werden empfangen, sobald die Datenbank eine Antwort vom Netzwerk erhält.
Wie ist es geworden?
Wir gehen zu einem so lakonischeren Schema (und wir werden am Ende kommen):
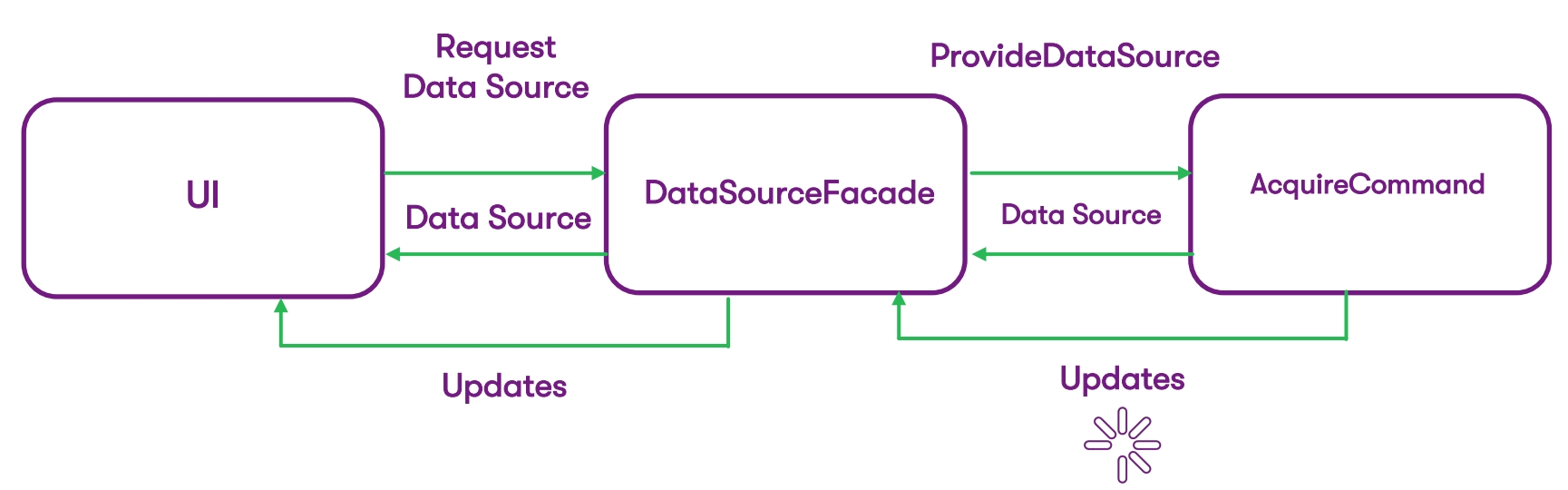
Nun haben wir davon:
- UI-Ebene,
- die Fassade, durch die wir unsere DataSource bereitstellen,
- Der Befehl, der diese DataSource zusammen mit Aktualisierungen zurückgibt.
Was ist eine DataSource und warum reden wir so viel darüber?
DataSource ist ein Objekt, das Daten für die Präsentationsschicht bereitstellt und einem vordefinierten Protokoll folgt. Das Protokoll sollte an unsere Benutzeroberfläche angepasst werden und Daten für unsere Benutzeroberfläche bereitstellen (dies spielt für einen bestimmten Bildschirm oder eine Gruppe von Bildschirmen keine Rolle).
Eine DataSource hat normalerweise zwei Hauptaufgaben:
- Bereitstellen von Daten zur Anzeige in der UI-Ebene;
- Benachrichtigen der Layer-Benutzeroberfläche über Datenänderungen und Senden der erforderlichen Änderungen an den Bildschirm, wenn wir ein Update erhalten.
Wir verwenden hier verschiedene Varianten von DataSource, da wir viel Objective C-Legacy-Code haben - das heißt, wir können unsere Swift DataSource nicht einfach überall anbringen. Wir verwenden auch noch nicht überall Sammlungen, aber in Zukunft werden wir den Code speziell für die Verwendung von CollectionView-Bildschirmen neu schreiben.
Ein Beispiel für eine unserer DataSource:

Dies ist eine DataSource für eine Sammlung (sie wird CollectionDataSource genannt), und dies ist aus Sicht der Benutzeroberfläche eine recht einfache Klasse. Es wird eine Sammlung benötigt, die von einem fetchedResultsController und einem CellDequeueBlock konfiguriert wurde. Wobei CellDequeueBlock ein Typalias ist, in dem wir die Strategie zum Erstellen von Zellen beschreiben.
Das heißt, wir haben die DataSource erstellt und der Auflistung zugewiesen, indem wir performFetch auf dem fetchedResultsController aufgerufen haben. Anschließend wird die gesamte Magie der Interaktion unserer DataSource-Klasse fetchedResultsController und der Fähigkeit des Delegaten zugewiesen, Aktualisierungen aus der Datenbank zu erhalten:

FetchedResultsController ist das Herzstück unserer DataSource. In der Apple-Dokumentation finden Sie viele Informationen zur Arbeit damit. In der Regel erhalten wir mit seiner Hilfe alle Daten - sowohl neue Daten als auch Daten, die aktualisiert oder gelöscht wurden. Gleichzeitig fordern wir Daten vom Netzwerk an. Sobald die Daten empfangen und in der Datenbank gespeichert wurden, erhielten wir ein Update von der DataSource, und das Update kam über die Benutzeroberfläche zu uns. Das heißt, mit einer Anfrage erhalten wir Daten und zeigen sie an verschiedenen Orten an - cool, praktisch, nativ!
Und wo immer es möglich ist, vorgefertigte DataSource mit Tabellen oder Sammlungen zu verwenden, tun wir dies:

An Orten, an denen viele Bildschirme und Tabellen und Sammlungen nicht verwendet werden (und die Objective C-Programmierung verwendet wird), bewerten wir, welche Daten wir benötigen Für den Bildschirm und durch das Protokoll beschreiben wir unsere DataSource. Danach schreiben wir die Fassade - in der Regel ist dies auch ein öffentliches Objective C-Protokoll, über das wir unsere DataSource anfordern. Und dann ist der Eingang zum Swift-Code bereits im Gange.
Sobald wir bereit sind, den Bildschirm vollständig auf die Swift-Implementierung zu übertragen, reicht es aus, den Objective C-Wrapper zu entfernen - und dank der benutzerdefinierten DataSource können wir direkt mit dem Swift-Protokoll arbeiten.
Wir verwenden derzeit drei Hauptvarianten von DataSources:
- TableViewDatasource + Zellenstrategie (Strategie zum Erstellen von Zellen);
- CollectionViewDatasource + Zellenstrategie (Option mit Sammlungen);
- CustomDataSource ist eine benutzerdefinierte Option. Wir benutzen es jetzt am meisten.
Ergebnisse
Nach allen Schritten zum Entwerfen, Implementieren und Interagieren mit Legacy-Code erhielt das Unternehmen die folgenden Verbesserungen:
- Die Geschwindigkeit der Datenübermittlung an den Benutzer hat sich aufgrund des Cachings erheblich erhöht. Dies ist wahrscheinlich ein offensichtliches und logisches Ergebnis.
- Wir sind dem ersten Offline-Paradigma jetzt einen Schritt näher gekommen.
- Die Prozesse einer plattformübergreifenden Überprüfung der Architektur wurden in den iOS- und Android-Teams eingerichtet. Alle an diesem Projekt beteiligten Entwickler verfügen über Informationen und können problemlos Erfahrungen zwischen den Teams austauschen.
- . , , legacy , .
- , — . , , , , , .
Der Bonus für uns war, dass wir verstanden haben, wie interessant und unterhaltsam das Arbeiten mit Architektur und Diagrammen sein kann (und dies vereinfacht die Entwicklung). Ja, wir haben viel Zeit damit verbracht, unsere architektonischen Ansätze zu zeichnen und auszurichten, aber bei der Implementierung haben wir sehr schnell über alle Bildschirme skaliert.
Unser Weg zu Offline geht zunächst weiter - wir müssen nicht nur zwischenspeichern, um offline zu sein, sondern der Benutzer kann auch ohne Netzwerkverbindung arbeiten und nach dem Erscheinen des Internets eine weitere Synchronisierung mit dem Server durchführen.
Links
- Dokumentbasierte Programmieranleitung . Dies ist ein ziemlich altes Dokument, und Apple empfiehlt, es nicht mehr zu verwenden. Aber ich würde empfehlen, zumindest nach zusätzlicher Entwicklung zu suchen. Dort gibt es viele nützliche Informationen.
- Document-based WWDC:
- DataSources
Apps Live 2020 .
— Android iOS, . , , .