So kam es, dass ich 1998 in die Graduiertenschule der Russischen Staatlichen Landwirtschaftsakademie eintrat und AI / ML als Thema meiner wissenschaftlichen Arbeit auswählte. Dies waren die harten Zeiten der nächsten Eiszeit neuronaler Netze. Zu dieser Zeit veröffentlichte Yang Lecun seine berühmte Arbeit "Gradient-Based Learning Applied to Document Recognition" über die Prinzipien der Organisation von Faltungsnetzwerken, die meiner Meinung nach nur der Beginn eines neuen Tauwetters war. Es ist lustig, dass ich zu dieser Zeit an ähnlichen Elementen gearbeitet habe. Es ist wahr, dass sie sagen, dass die Idee, wenn es soweit ist, in der Luft liegt. Es ist jedoch nicht jedem gegeben, es zum Leben zu erwecken. Leider habe ich meine Arbeit bis zur Verteidigung nie beendet, aber ich wollte sie immer eines Tages beenden.
Quelle: Hitecher
Und jetzt, nach 20 Jahren, als ich anfing, als Lehrer an der Southern Federal University zu arbeiten und gleichzeitig im Zusatzprogramm "Samsung IT School" zu unterrichten, hatte ich eine zweite Chance. Samsung bot SFedU an, als erster den Trainingspfad "Samsung IT Academy" über künstliche Intelligenz für Junggesellen und Meister zu starten. Ich hatte einige Bedenken, dass es möglich sein würde, den gesamten Lehrplan vollständig umzusetzen, aber ich reagierte begeistert auf das Angebot, den Kurs zu lesen. Mir wurde klar, dass der Kreis geschlossen war und ich noch eine zweite Chance hatte, das zu tun, was ich einmal versagt hatte. Hierbei ist zu beachten, dass der Samsung AI / ML-Kurs einer der besten derzeit offenen Kurse in russischer Sprache ist, die kostenlos auf der Stepik-Plattform ( https://stepik.org/org/srr) verfügbar sind ). Im Falle eines Universitätsprogramms wurde jedoch zusätzlich zum theoretischen / praktischen Kurs der Projektteil hinzugefügt. Das heißt, der jährliche Lehrplan der "Samsung IT Academy" wurde als beherrscht angesehen, wenn zwei Module "Neuronale Netze und Computer Vision", "Neuronale Netze und Textverarbeitung" mit dem Erhalt der entsprechenden Stepik-Zertifikate sowie der Implementierung eines einzelnen Projekts studiert wurden. Der Kurs endete mit der Verteidigung von Studentenprojekten, zu denen Experten eingeladen wurden, inkl. Mitarbeiter des Moskauer Zentrums für Künstliche Intelligenz Samsung.
Und seit September 2019 haben wir einen Kurs am Institut für Hochtechnologien und Piezotechnik der SFedU begonnen. Natürlich kam eine ziemlich große Anzahl von Studenten zum HYIP und anschließend gab es einen ernsthaften Schulabbruch. Das Programm war nicht sehr kompliziert, aber umfangreich - Kenntnisse waren erforderlich:
- Lineare Algebra,
- Wahrscheinlichkeitstheorie,
- Differentialrechnung,
- die Programmiersprache Python.
Natürlich gehen alle erforderlichen Kenntnisse und Fähigkeiten nicht über den Lehrplan des 3. Studienjahres der Universität hinaus. Ich werde einige Beispiele nennen, von denen, die komplizierter sind:
- Finden Sie die Ableitung der Aktivierungsfunktion der hyperbolischen Tangente
 und drücken Sie das Ergebnis in Form von aus
.
und drücken Sie das Ergebnis in Form von aus
.
- Finden Sie die Ableitung der Sigmoid-Aktivierungsfunktion
 und drücken Sie das Ergebnis in Form des Sigmoid aus
...
und drücken Sie das Ergebnis in Form des Sigmoid aus
...
- In der Grafik der Berechnungen in Abb. 1 zeigt eine komplexe Funktion
mit Parametern
... Der Einfachheit halber wurden Zwischenergebnisse hinzugefügt
... Es muss bestimmt werden, wie groß die Ableitung sein wird
nach Parameter

Um ehrlich zu sein, habe ich mich hastig mit Studenten befasst, insbesondere mit modernen Algorithmen für die Arbeit mit neuronalen Netzen. Zunächst wurde davon ausgegangen, dass die Schüler selbst Videovorträge des Samsung-Online-Kurses über Stepik studieren und im Klassenzimmer nur Workshops durchführen würden. Ich traf jedoch die Entscheidung, auch die Theorie zu lesen. Diese Entscheidung beruht auf der Tatsache, dass Sie mit dem Lehrer ein unverständliches Thema klären, die entstandenen Ideen diskutieren usw. können. Die Studierenden erhielten praktische Aufgaben in Form von Hausaufgaben. Der Ansatz erwies sich als richtig - im Klassenzimmer herrschte eine lebhafte Atmosphäre, und ich sah, dass die Schüler im Allgemeinen das Material recht erfolgreich beherrschten.
Einen Monat später wechselten wir reibungslos von einem Neuronenmodell zu den ersten einfachen vollständig verbundenen Architekturen, von der einfachen Regression zur Klassifizierung mehrerer Klassen, von der einfachen Gradientenberechnung zu den Algorithmen zur Optimierung des Gradientenabfalls SGD, ADAM usw. Wir haben die erste Hälfte des Kurses mit Faltungsnetzwerken und modernen tiefen Netzwerkarchitekturen abgeschlossen. Die letzte Aufgabe des ersten Computer Vision-Moduls bestand darin, am " Dirty vs Cleaned " -Wettbewerb auf Kaggle teilzunehmen und die Genauigkeitsschwelle von 80% zu überwinden.
Ein weiterer meiner Meinung nach wichtiger Faktor: Wir waren innerhalb der Universität nicht geschlossen. Die Streckenorganisatoren veranstalteten für uns Webinare und Meisterkurse mit eingeladenen Experten aus Samsung-Labors. Solche Ereignisse haben die Motivation der Studenten und meiner erhöht, um ehrlich zu sein :). Zum Beispiel gab es eine interessante Veranstaltung zur Berufsberatung - eine Online-Brücke zwischen den Klassenzimmern der SFedU, der Moskauer Staatsuniversität und Samsung, bei der Mitarbeiter des Moskauer KI-Zentrums Samsung über moderne Trends in der KI / ML-Entwicklung sprachen und Fragen der Schüler beantworteten.
Der zweite Teil des Kurses, der der Textverarbeitung gewidmet war, begann mit einer allgemeinen Theorie der Sprachanalyse. Anschließend wurden die Schüler in die Vektor- und TF-IDF-Textmodelle sowie in die Verteilungssemantik und word2vec eingeführt. Basierend auf den Ergebnissen wurden mehrere interessante Workshops abgehalten: Generieren von word2wec-Einbettungen, Generieren von Namen und Slogans. Dann gingen wir zu Theorie und Praxis über, Faltungsnetzwerke und wiederkehrende Netzwerke für die Textanalyse zu verwenden.
Im Moment habe ich einen Artikel im VAK-Journal veröffentlicht und begonnen, den nächsten vorzubereiten, wobei ich nach und nach Material für eine neue Dissertation sammelte. Meine Schüler saßen auch nicht still, sondern begannen an ihren ersten Projekten zu arbeiten. Die Studierenden wählten die Themen selbst aus und so wurden 7 Abschlussprojekte in verschiedenen Anwendungsbereichen neuronaler Netze durchgeführt:
- « » , .
- « » .
- « » .
- « » .
- « » .
- « » .
- « » , .

Alle Projekte wurden verteidigt, aber der Grad an Komplexität und Raffinesse war unterschiedlich, was sich zu Recht in den Schätzungen für die Projekte widerspiegelte. Basierend auf den Verteidigungsergebnissen wurden vier Projekte für den jährlichen Wettbewerb der Samsung IT Academy ausgewählt . Und ich kann stolz sagen, dass die Jury zwei unserer Projekte mit Top-Plätzen ausgezeichnet hat. Im Folgenden werde ich eine kurze Beschreibung dieser Projekte geben, basierend auf den Materialien meiner Schüler Grateful Alexander, Krikunov Stanislav und Pandov Vyacheslav, für die ich ihnen vielmals danke. Ich glaube, dass die von ihnen aufgezeigten Lösungen durchaus als ernsthafte Forschungsarbeit bewertet werden können.
I « » «IT Samsung».
« », ,
Das Projekt bestand darin, eine mobile Anwendung zu erstellen, die körperliche Aktivität im Training mithilfe von Mobiltelefonsensoren identifiziert und quantifiziert. Jetzt gibt es viele mobile Anwendungen, die die körperliche Aktivität einer Person erkennen können: Google Fit, Nike Training Club, MapMyFitness und andere. Diese Apps können jedoch bestimmte Arten von Übungen nicht erkennen und die Anzahl der Wiederholungen zählen.
Einer der Autoren des Projekts Grateful Alexander, mein Absolvent des Samsung IT School-Programms 2015, und ich freuten uns nicht ohne Stolz darüber, dass das Wissen über die mobile Entwicklung in der Schule so angewendet wurde.
Wie wird körperliche Aktivität erkannt? Beginnen wir damit, wie der Zeitpunkt der Übung bestimmt wird. Um den Beginn und das Ende der Übungen zu ermitteln, entschieden sich die Schüler für das Beschleunigungsmodul, das als Wurzel der Summe der Quadrate der Beschleunigungen entlang der Achsen berechnet wird. Es wurde ein bestimmter Schwellenwert gewählt, mit dem der aktuelle Beschleunigungswert verglichen wurde. Wenn der Schwellenwert überschritten wird (die Ableitung der Beschleunigung ist positiv), gehen wir davon aus, dass die Übung begonnen hat. Wenn die aktuelle Beschleunigung unter dem Schwellenwert liegt (die Ableitung der Beschleunigung ist negativ), gehen wir davon aus, dass die Übung beendet ist. Leider erlaubt dieser Ansatz keine Echtzeitverarbeitung. Eine mögliche Verbesserung ist die Verwendung eines Schiebefensters für die Daten mit der Berechnung des Ergebnisses bei jedem Schritt der Verschiebung.
Der Datensatz wurde von den Autoren selbst gesammelt. Bei der Durchführung von 7 verschiedenen Übungen wurden 3 Arten von Smartphones verwendet (Android-Versionen 4.4, 9.0, 10.0). Das Smartphone wurde mit einer speziellen Tasche an der Hand befestigt. Insgesamt 1800 Wiederholungen wurden von drei Freiwilligen durchgeführt. Während der Ausführung können aus irgendeinem Grund Fehler in der Technik auftreten, daher wurde ein Probenreinigungsverfahren durchgeführt. Hierzu wurden die Verteilungen der Kreuzkorrelationen für alle Arten von Übungen konstruiert. Dann wurde für jede Übung eine Korrelationsschwelle ausgewählt, unterhalb derer die Übung als ungeeignet angesehen und aus der Stichprobe ausgeschlossen wird.
Die gleiche Übung hat je nach Wiederholung eine unterschiedliche Ausführungszeit. Um dem entgegenzuwirken, wurde beschlossen, die Daten mit einer festen Anzahl von Proben zu interpolieren, unabhängig davon, wie viele von den Sensoren kamen. 50 erhalten - doppelte Abtastrate, wobei Zwischenpositionen als arithmetisches Mittel der benachbarten berechnet werden. 200 erhalten - alle 2 Zählungen verwerfen. In diesem Fall ist die Anzahl der Proben konstant. Ebenso für jedes Verhältnis der Eingangszahl von Abtastwerten zur gewünschten Ausgangszahl.
Für das neuronale Netz wurde beschlossen, Daten im Frequenzbereich anzuwenden. Da das Körpergewicht einer Person ziemlich groß ist, kann man erwarten, dass die charakteristischen Signalfrequenzen bei den meisten Standardübungen im Niederfrequenzbereich des Spektrums liegen. In diesem Fall können hohe Frequenzen entweder als Jitter während der Ausführung oder als Rauschen der Sensoren betrachtet werden. Was bedeutet das? Dies bedeutet, dass wir das Spektrum des Signals mit der FFT ermitteln und nur 10-20% der Daten für die Analyse verwenden können. Warum so wenig? Da 1) das Spektrum symmetrisch ist, können Sie sofort die Hälfte der Komponenten abschneiden. 2) Grundinformationen - nur 20-40% des informativen Teils des Spektrums. Diese Annahmen beschreiben langsame Kraftübungen besonders gut.
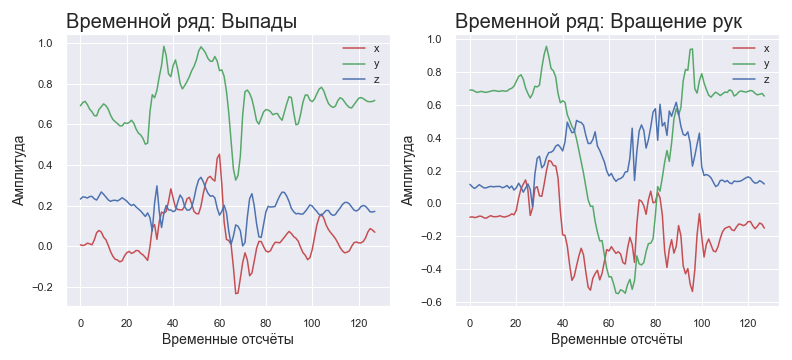
Normalisierte Zeitreihen für verschiedene Übungen
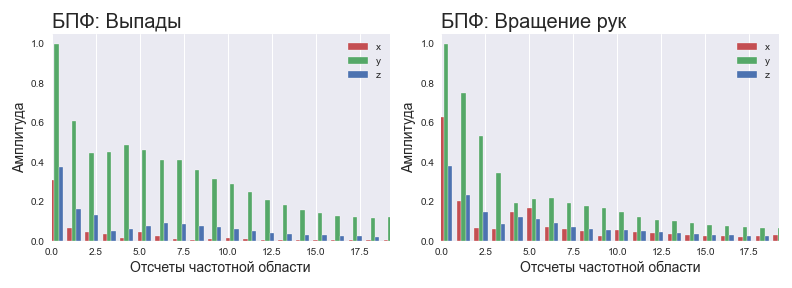
Normalisiertes Spektrum für verschiedene Übungen
Vor der Verarbeitung durch das neuronale Netzwerk wird das Datenspektrum auf den Maximalwert zwischen den drei Achsen normiert, um alle Übungsproben in den Amplitudenbereich 0-1 anzupassen. In diesem Fall bleiben die Proportionen zwischen den Achsen erhalten.
Das neuronale Netzwerk übernimmt die Aufgabe, Übungen zu klassifizieren. Dies bedeutet, dass es einen Wahrscheinlichkeitsvektor aller Übungen aus der Liste ausgibt, mit der es trainiert wurde. Der Index des maximalen Elements in diesem Vektor ist die Nummer der abgeschlossenen Übung. Wenn das Vertrauen in die durchgeführte Übung weniger als 85% beträgt, wird davon ausgegangen, dass keine der Übungen durchgeführt wurde. Das Netzwerk besteht aus 3 Schichten: 4 Faltungsschichten, 3 vollständig verbundene, die Anzahl der Ausgangsneuronen entspricht der Anzahl der Übungen, die wir erkennen möchten. In der Architektur werden zum Einsparen von Rechenressourcen nur Faltungen mit einer Kerngröße von 3 x 3 verwendet. Die relativ einfache Architektur des Netzwerks wird durch die begrenzten Rechenressourcen von Smartphones gerechtfertigt. In unserer Aufgabe ist eine Erkennung mit einer minimalen Verzögerung erforderlich.

Beschreibung der neuronalen Netzwerkarchitektur
Die Trainingsstrategie für neuronale Netze besteht darin, nach Epochen unter Verwendung einer Chargennormalisierung der Trainingsdaten zu trainieren, bis die Verlustfunktion auf der Trainingsprobe ihren Minimalwert erreicht.
Ergebnisse: Bei mehr oder weniger hoher Trainingsleistung liegt das Netzwerkvertrauen bei 95-99%. Auf dem Validierungssatz betrug die Genauigkeit 99,8%.
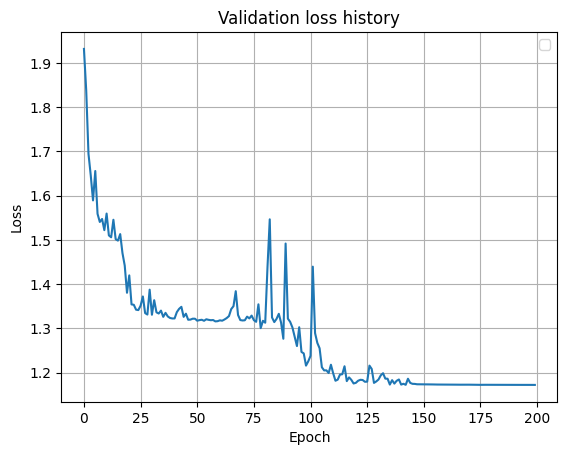
Fehler während des Trainings auf einem Validierungssatz

Fehlermatrix für ein neuronales
Netzwerk Das neuronale Netzwerk wurde in eine mobile Anwendung eingebaut und zeigte ähnliche Ergebnisse wie beim Training.
Die Studie testete auch andere Modelle des maschinellen Lernens, die heute zur Lösung von Klassifizierungsproblemen verwendet werden: logistische Regression, zufällige Wälder, XG Boost. Für diese Architekturen wurden Tikhonov-Regularisierung (L2), Kreuzvalidierung und Rastersuche verwendet, um die optimalen Parameter zu finden. Infolgedessen waren die Genauigkeitsindikatoren wie folgt:
- Logistische Regression: 99,4%
- Zufällige Wälder: 99,1%
- XG-Boost: 97,5%
Das während der Ausbildung an der Samsung IT Academy gewonnene Wissen half den Autoren des Projekts, den Horizont ihrer Interessen zu erweitern, und leistete einen unschätzbaren Beitrag beim Eintritt in das Masterstudium am Skolkovo-Institut für Wissenschaft und Technologie. Momentan forschen meine Studenten dort auf dem Gebiet des maschinellen Lernens für Kommunikationssysteme.
Code auf GitHub
II « » «IT Samsung».
« »,
Die Arbeit des Modells ist auf dieser Folie gut beschrieben:

Alles beginnt mit einem Foto. In der vorgestellten Implementierung stammt es von einem Telegramm-Bot. Dlib frontal_face_detector findet damit alle Gesichter im Bild. Dann werden 68 wichtige 2D-Punkte jeder Fläche mithilfe von Dlib shape_predictor_68_face_landmarks erkannt. Jeder Satz wird wie folgt normalisiert: zentriert (Subtrahieren des Durchschnitts von X und Y) und skaliert (dividiert durch das absolute Maximum von X und Y). Jede Koordinate des normalisierten Punktes gehört zum Intervall [-1, +1].
Dann kommt das neuronale Netzwerk ins Spiel, das die Tiefe jedes Schlüsselpunkts des Gesichts - der Z-Koordinate - unter Verwendung der normalisierten Koordinaten (X, Y) vorhersagt. Dieses Modell wurde auf dem AFLW2000-Datensatz trainiert.
Ferner sind diese Punkte miteinander verbunden und bilden eine Netzmaske. Es kann auch als Gesichtsbiometrie bezeichnet werden. Die Länge der Segmente einer solchen Maske wird als eine der Möglichkeiten zur Definition von Emotionen verwendet. Die Idee ist, dass jedes Liniensegment seinen eigenen Platz im Liniensegmentvektor hat und einige davon abhängig von der Emotion. Und jede Emotion hat theoretisch eine begrenzte Anzahl solcher Vektoren. Diese Hypothese wurde im Verlauf von Experimenten bestätigt. Um ein solches Modell zu trainieren, wurden die folgenden Datensätze verwendet: Cohn-Kanade +, JAFFE, RAF-DB.
Parallel dazu lernt ein anderes Netzwerk, Emotionen anhand des Bildes selbst zu klassifizieren. Gesichtsbilder werden aus den mit Dlib gefundenen Rechtecken ausgeschnitten. In einkanaliges Schwarzweiß konvertiert und auf 48x48 komprimiert. Um dieses Modell zu trainieren, wurden dieselben Datensätze wie für das Biometrie-Modell verwendet. Es wurde jedoch zusätzlich der Datensatz FER2013 verwendet.
Zusammenfassend wird das dritte neuronale Netzwerk in Betrieb genommen, dessen Architektur die beiden vorherigen eingefrorenen und vorab trainierten Netzwerke mit einer trainierten Schicht kombiniert. Diese Netzwerke überschreiben auch die letzten vollständig verbundenen Schichten. Anstelle des erwarteten "Wahrscheinlichkeitsvektors", mit dem die Zielklasse bestimmt werden kann, werden jetzt mehr "Merkmale auf niedriger Ebene" zurückgegeben. Die vereinheitlichende Schicht wird darauf trainiert, diese Informationen in die Zielklasse zu interpretieren.
Unter den "ähnlichen Lösungen" sind die folgenden: EmoPy, DLP-CNN (RAF-DB), FER2013, EmotioNet. Es ist jedoch schwierig, Vergleiche anzustellen Sie wurden auf verschiedenen Daten trainiert.
Code auf GitHub
Fazit
Abschließend möchte ich sagen, dass sich der Pilotkurs bewährt hat. In diesem akademischen Jahr 2020/21 wird das Programm bereits an 23 Universitäten unterrichtet, die Partner der Samsung IT Academy in Russland und Kasachstan sind. Die vollständige Liste finden Sie hier... In diesem Jahr studiert bereits eine Gruppe von Meistern und Junggesellen bei uns (es gibt sogar einen ganzen Doktortitel in der Gruppe!). Und bis jetzt nagt der Granit der Wissenschaft in der Masse erfolgreich. Ideen für ein einzelnes Projekt müssen noch gefunden werden, aber die Studenten sind voller Optimismus. Natürlich wird sich der Wettbewerb im nächsten Wettbewerb einzelner Projekte verzehnfachen, aber wir hoffen, weiterhin gute Noten für die Leistungen unserer Studenten zu erhalten. Und vor allem bin ich sicher, dass die gewonnenen Kenntnisse und Erfahrungen unseren Absolventen bei ihrer Weiterentwicklung im Bereich IT eine große Hilfe sein werden.
2020 Rostow am Don. SFedU, IT-Akademie Samsung.

Dmitry Yatsenko
Dozent am Institut für Informations- und Messtechnik der Fakultät für Hochtechnologien der Southern Federal University,
Dozent an der Samsung IT School,
Dozent für den AI IT Track an der Samsung Academy.