- Forschungsartikel
- Pytorch : YOLOv4-CSP, YOLOv4-P5, YOLOv4-P6, YOLOv4-P7 ( Hauptrepository - Verwendung Ergebnisse zu reproduzieren)
YOLOv4-CSP
YOLOv4-tiny
YOLOv4-large
- Darknet : YOLOv4-winzig, YOLOv4-CSP, YOLOv4x-MISH
- YOLOv4-CSP-Struktur
Das skalierte YOLO v4 ist das genaueste neuronale Netzwerk ( 55,8% AP ) im Microsoft COCO-Datensatz aller bisher veröffentlichten neuronalen Netzwerke. Und es ist auch das beste in Bezug auf das Verhältnis von Geschwindigkeit zu Genauigkeit im gesamten Bereich von Genauigkeit und Geschwindigkeit von 15 FPS bis 1774 FPS . Im Moment ist es das neuronale Top1-Netzwerk für die Objekterkennung.
Skaliertes YOLO v4 übertrifft neuronale Netze in Bezug auf Genauigkeit:
- Google EfficientDet D7x / DetectoRS oder SpineNet-190 (selbst trainiert für zusätzliche Daten)
- Amazon Cascade-RCNN ResNest200
- Microsoft RepPoints v2
- Facebook RetinaNet SpineNet-190
Wir zeigen, dass die Ansätze von YOLO und Cross-Stage-Partial (CSP) Network sowohl hinsichtlich der absoluten Genauigkeit als auch des Verhältnisses von Genauigkeit zu Geschwindigkeit die besten sind.
Diagramm der Genauigkeit (vertikale Achse) und Latenz (horizontale Achse) auf der GPU Tesla V100 (Volta) mit Batch = 1 ohne Verwendung von TensorRT:
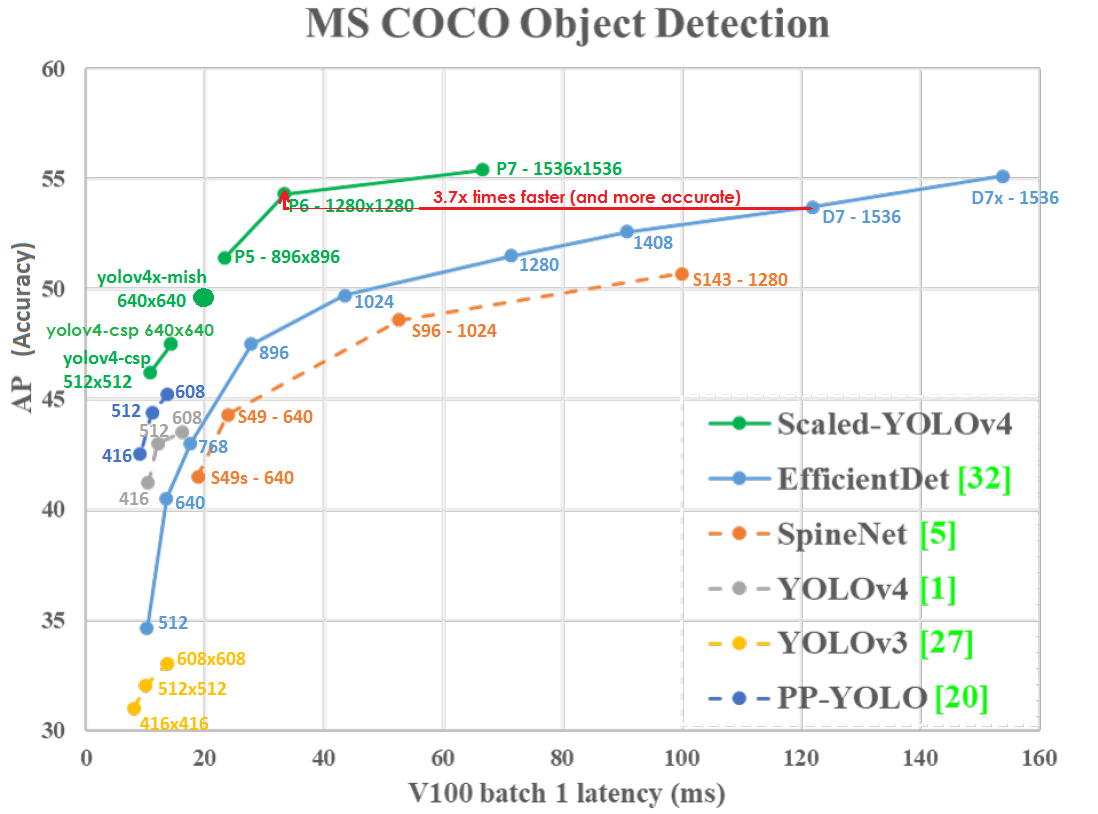
Selbst bei niedrigerer Netzwerkauflösung ist Scaled-YOLOv4-P6 (1280 x 1280) 30 FPS etwas genauer und 3,7-mal schneller als EfficientDetD7 (1536 x 1536) 8,2 FPS. Jene. YOLOv4 nutzt die Netzwerkauflösung besser.
Skaliertes YOLO v4 liegt auf der Pareto-Optimalitätskurve - unabhängig davon, welches andere neuronale Netzwerk Sie verwenden, gibt es immer ein solches YOLOv4-Netzwerk, das entweder bei gleicher Geschwindigkeit genauer oder bei gleicher Genauigkeit schneller ist, d. H. YOLOv4 ist das Beste in Bezug auf Geschwindigkeit und Genauigkeit.
Skaliertes YOLOv4 ist genauer und schneller als neuronale Netze:
- Google EfficientDet D0-D7x
- Google SpineNet S49s - S143
- Baidu Paddel-Paddel PP YOLO
- Und viele andere
Skaliertes YOLO v4 ist eine Reihe von neuronalen Netzen, die aus dem verbesserten und skalierten YOLOv4-Netzwerk aufgebaut sind. Unser neuronales Netzwerk wurde von Grund auf trainiert, ohne zuvor trainierte Gewichte (Imagenet oder andere) zu verwenden.
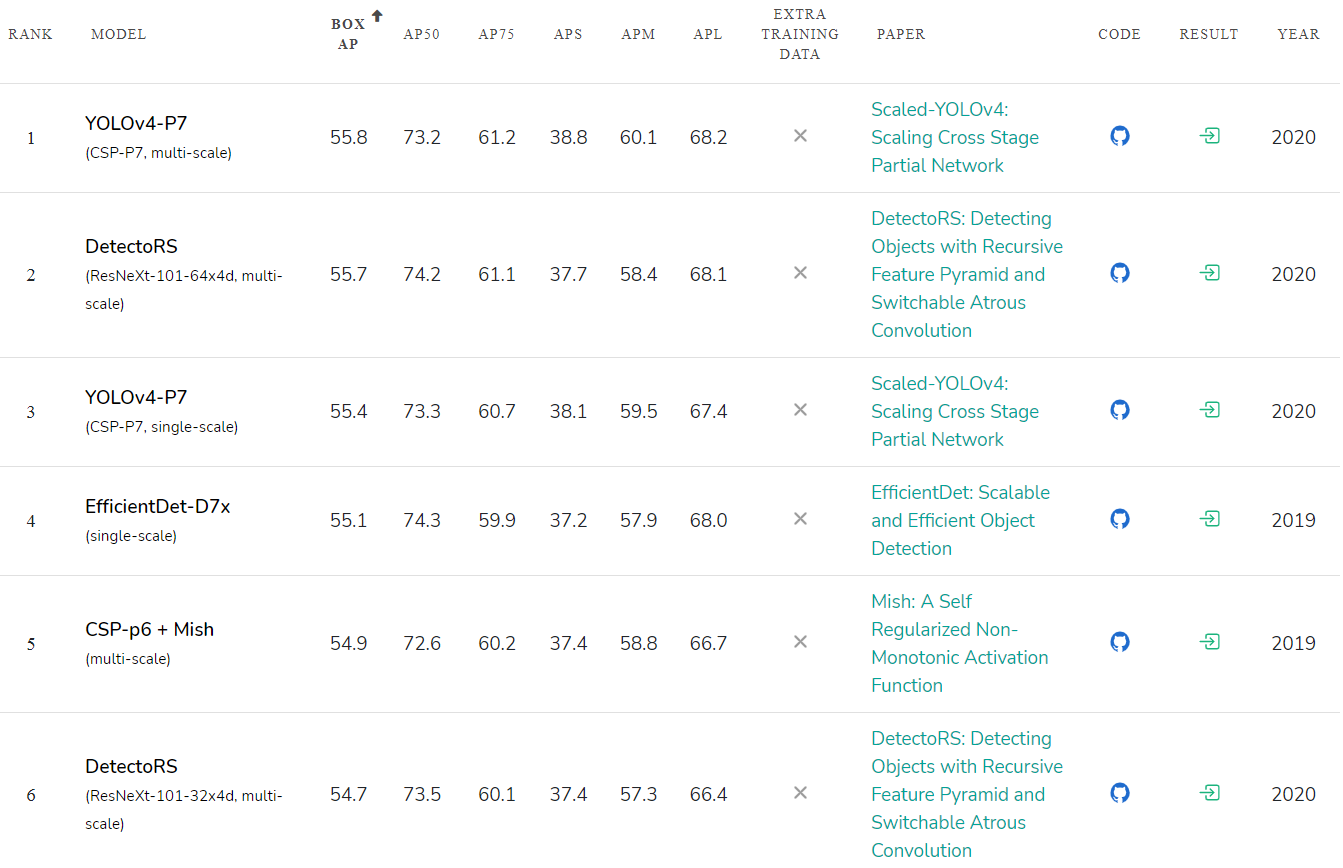
Genauigkeitsbewertung veröffentlichter neuronaler Netze: paperswithcode.com/sota/object-detection-on-coco :
Die Geschwindigkeit des YOLOv4-winzigen neuronalen Netzes erreicht 1774 FPS auf einer Gaming-GPU RTX 2080Ti mit TensorRT + tkDNN (Batch = 4, FP16): github. com / ceccocats / tkDNN
YOLOv4-tiny kann in Echtzeit mit einer Latenz von 39 FPS / 25 ms auf JetsonNano (416 x 416, fp16, batch = 1) ausgeführt werden. tkDNN / TensorRT:

Skaliertes YOLOv4 nutzt die Ressourcen paralleler Computer wie GPUs und NPUs wesentlich effizienter. Zum Beispiel hat GPU V100 (Volta) eine Leistung: 14 TFLops - 112 TFLops-TC images.nvidia.com/content/technologies/volta/pdf/tesla-volta-v100-datasheet-letter-fnl-web.pdf
Wenn wir testen beide Modelle auf GPU V100 mit Batch = 1 , mit den Parametern --hparams = Mixed_Precision = True und ohne --tensorrt = FP32 , dann:
- YOLOv4-CSP (640 x 640) - 47,5% AP - 70 FPS - 120 BFlops (60 FMA)
Basierend auf BFlops sollte es 933 FPS = (112.000 / 120) sein, aber in Wirklichkeit erhalten wir 70 FPS, d. H. verwendete 7,5% GPU = (70/933) - EfficientDetD3 (896x896) – 47.5% AP – 36 FPS – 50 BFlops (25 FMA)
BFlops, 2240 FPS = (112 000 / 50), 36 FPS, .. 1.6% GPU = (36 / 2240)
Jene. Die Effizienz von Rechenoperationen auf Geräten mit massivem Parallel-Computing wie GPUs, die in YOLOv4-CSP (7.5 / 1.6) verwendet werden, ist 4,7-mal besser als die Effizienz von Operationen, die in EfficientDetD3 verwendet werden.
Normalerweise werden neuronale Netze auf der CPU nur in Forschungsaufgaben ausgeführt, um das Debuggen zu vereinfachen, und die BFlops-Eigenschaft ist derzeit nur von akademischem Interesse. Bei realen Aufgaben sind echte Geschwindigkeit und Genauigkeit wichtig, nicht die Leistung auf dem Papier. Die tatsächliche Geschwindigkeit von YOLOv4-P6 ist 3,7-mal schneller als die von EfficientDetD7 auf der GPU V100. Daher werden Geräte mit massiver Parallelität GPU / NPU / TPU / DSP fast immer mit viel optimalerem Einsatz verwendet: Geschwindigkeit, Preis und Wärmeableitung:
- Eingebettete GPU (Jetson Nano / Nx)
- Mobile-GPU / NPU / DSP (Bionic-NPU / Snapdragon-DSP / Mediatek-APU / Kirin-NPU / Exynos-GPU / ...)
- TPU-Edge (Google Coral / Intel Myriad / Mobileye EyeQ5 / Tesla-Motoren TPU 144 TOPS-8bit)
- Cloud-GPU (nVidia A100 / V100 / TitanV)
- Cloud-NPU (Google-TPU, Huawei Ascend, Intel Habana, Qualcomm AI 100, ...)
Auch bei der Verwendung neuronaler Netze im Web - in diesem Fall wird die GPU normalerweise über die Bibliotheken WebGL, WebAssembly und WebGPU verwendet - kann die Größe des Modells von Bedeutung sein: github.com/tensorflow/tfjs#about-this-repo
Verwenden von Geräten und Algorithmen mit schwachen Werten Parallelität ist eine Sackgasse der Entwicklung, weil Es ist unmöglich, die Lithographiegröße kleiner als die Größe eines Siliziumatoms zu reduzieren, um die Prozessorfrequenz zu erhöhen:
- Die derzeit beste Größe für die Herstellung von Halbleiterbauelementen beträgt 5 Nanometer.
- Die Kristallgittergröße von Silizium beträgt 0,5 Nanometer.
- Der Atomradius von Silizium beträgt 0,1 Nanometer.
Die Lösung sind Computer mit massiver Parallelität: auf einem Einkristall oder auf mehreren Kristallen, die durch einen Interposer verbunden sind. Daher ist es äußerst wichtig, neuronale Netze zu erstellen, die effektiv massiv parallele Rechenmaschinen wie GPUs und NPUs effektiv nutzen.
Verbesserungen in skaliertem YOLOv4 gegenüber YOLOv4:
- Skaliertes YOLOv4 verwendete optimale Netzwerkskalierungstechniken, um YOLOv4-CSP -> P5 -> P6 -> P7-Netzwerke zu erhalten
- Verbesserte Netzwerkarchitektur: Backbone-optimiert und Neck (PAN) verwendet CSP-Verbindungen (Cross-Stage-Partial) und Mish-Aktivierung
- Exponential Moving Average (EMA) wird während des Trainings verwendet - dies ist ein Sonderfall von SWA: pytorch.org/blog/pytorch-1.6-now-includes-stochastic-weight-averaging
- Für jede Auflösung des Netzwerks wird ein separates neuronales Netzwerk trainiert (in YOLOv4 wurde nur ein neuronales Netzwerk für alle Auflösungen trainiert).
- Verbesserte Normalisierer in [Yolo] -Schichten
- Die Aktivierungen für Breite und Höhe wurden geändert, um ein schnelleres Netzwerktraining zu ermöglichen
- Verwenden Sie den Parameter [net] letter_box = 1 (behält das Seitenverhältnis des Eingabebilds bei) für hochauflösende Netzwerke (für alle außer yolov4-tiny.cfg).
Scaled-YOLOv4-Architektur für neuronale Netze (Beispiele für drei Netze: P5, P6, P7): Die

CSP-Verbindung ist sehr effizient, einfach und kann auf alle neuronalen Netze angewendet werden. Das Endergebnis ist das
- Die Hälfte des Ausgangssignals verläuft entlang des Hauptpfads (Erzeugung mehr semantischer Informationen mit einem großen Empfangsfeld).
- und die andere Hälfte des Signals folgt einem Umweg (wobei mehr räumliche Informationen mit einem kleinen Empfangsfeld erhalten bleiben)
Das einfachste Beispiel für eine CSP-Verbindung (links ein reguläres Netzwerk, rechts ein CSP-Netzwerk):

Ein Beispiel für eine CSP-Verbindung in YOLOv4-CSP / P5 / P6 / P7
(links ein reguläres Netzwerk, rechts ein CSP-Netzwerk):

In YOLOv4-tiny gibt es 2 CSP-Verbindungen :

YOLOv4 wird in verschiedenen Bereichen und Aufgaben verwendet:
- Taiwanesische Regierung: Verkehrskontrolle www.taiwannews.com.tw/en/news/3957400 und youtu.be/IiU6wFmfVnk
- Amazon: Anti-Covid19-Distanzassistent github.com/amzn/distance-assistant und Amazon Neurochip / Amazon EC2 Inf1-Instanzen: aws.amazon.com/ru/blogs/machine-learning/improving-performance-for-deep-learning- basierte Objekterkennung mit einem aws-Neuron-kompilierten yolov4-Modell-auf-aws-Inferenz
- BMW Innovation Lab: github.com/BMW-InnovationLab
Und bei vielen anderen Aufgaben….
Es gibt Implementierungen in verschiedenen Frameworks:
- Pytorch : github.com/WongKinYiu/ScaledYOLOv4
- Darknet : github.com/AlexeyAB/darknet
- TensorFlow : github.com/hunglc007/tensorflow-yolov4-tflite
- o Pip Installation von yolov4 pypi.org/project/yolov4
- OpenCV: docs.opencv.org/master/da/d9d/tutorial_dnn_yolo.html
- OpenVINO: github.com/TNTWEN/OpenVINO-YOLOV4
- ONNX: developer.nvidia.com/blog/announcing-onnx-runtime-for-jetson
- TensorRT ONNX Scaled-YOLOv4: github.com/linghu8812/tensorrt_inference/tree/master/ScaledYOLOv4
- TensorRT + tkDNN: github.com/ceccocats/tkDNN
- TensorRT + Deepstream: github.com/NVIDIA-AI-IOT/yolov4_deepstream
- Another Pytorch implementations:
- o github.com/WongKinYiu/PyTorch_YOLOv4
- o github.com/Tianxiaomo/pytorch-YOLOv4
- o github.com/VCasecnikovs/Yet-Another-YOLOv4-Pytorch
- Die Struktur des Netzwerks kann mit dem Dienstprogramm Netron - Visualizer für neuronale Netze angezeigt werden: github.com/lutzroeder/netron
So kompilieren und führen Sie Cloud Object Detection kostenlos aus :
- colab: colab.research.google.com/drive/12QusaaRj_lUwCGDvQNfICpa7kA7_a2dE
- Video: www.youtube.com/watch?v=mKAEGSxwOAY
So kompilieren und führen Sie Training in the Cloud kostenlos aus :
- colab: colab.research.google.com/drive/1_GdoqCJWXsChrOiY8sZMr_zbr_fH-0Fg?usp=sharing
- Video: youtu.be/mmj3nxGT2YQ
Der YOLOv4-Ansatz kann auch für andere Aufgaben verwendet werden, z. B. beim Erkennen von 3D-Objekten:
- Code - Complex-YOLOv4 (5-DOF): github.com/maudzung/Complex-YOLOv4-Pytorch
- Code - YOLO3D-YOLOv4 (7-DOF): github.com/maudzung/YOLO3D-YOLOv4-PyTorch
