
Ein wenig über mich selbst: Ich bin auch Anfängerentwickler, ich nehme am Kurs "Python-Entwickler" teil. Dieses Material wurde nicht als Ergebnis der Fernerkundung zusammengestellt, sondern in der Reihenfolge der Selbstentwicklung. Mein Code ist möglicherweise ziemlich naiv. Bitte hinterlassen Sie Ihre Kommentare in den Kommentaren. Wenn ich dich noch nicht erschreckt habe, bitte unter dem Schnitt :)
Wir werden ein praktisches Beispiel für die Normalisierung einer flachen Tabelle mit doppelten Daten auf den Zustand 3NF ( dritte Normalform ) analysieren .
Aus dieser Tabelle:
Datentabelle

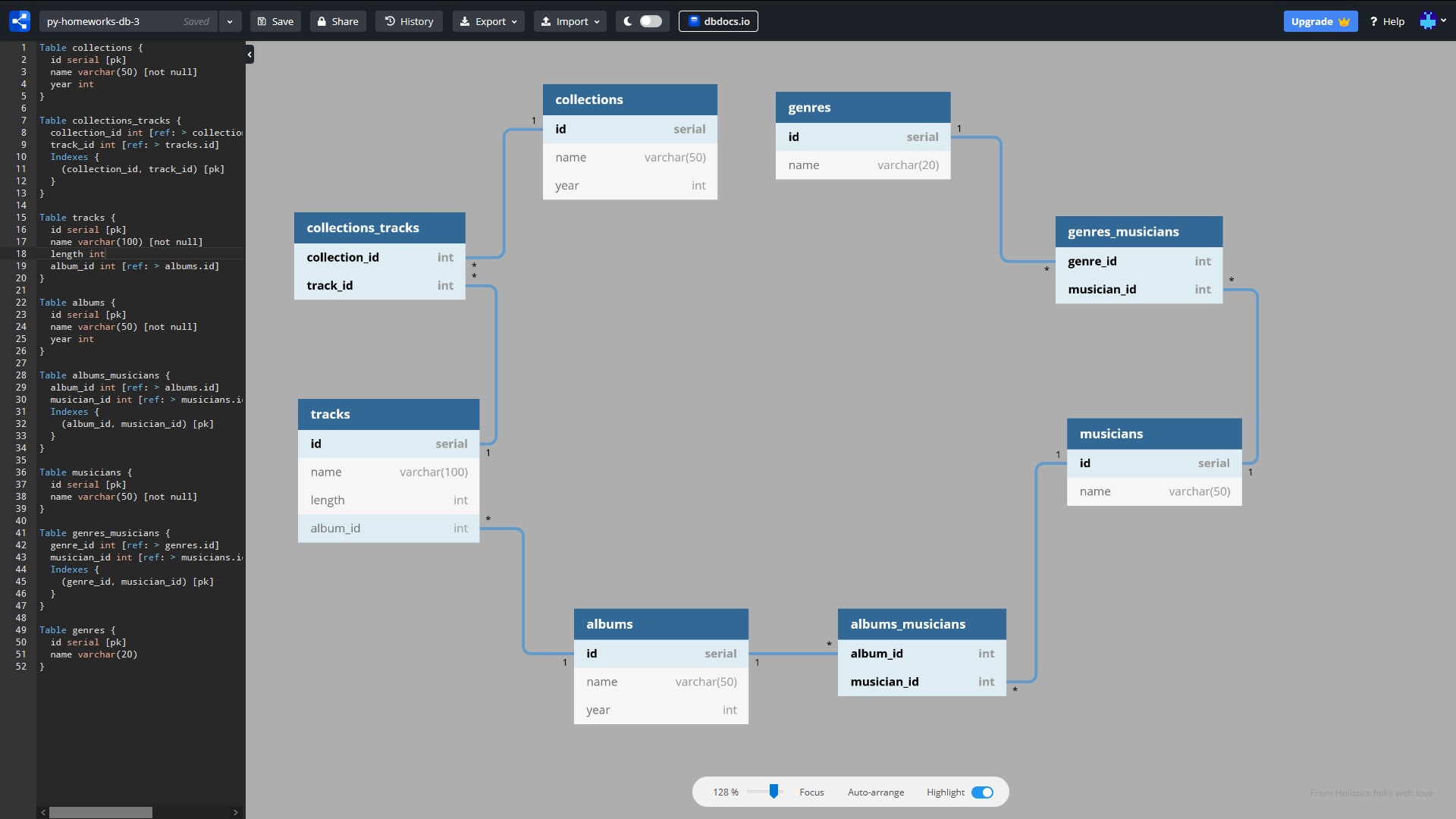
Lassen Sie uns eine solche Datenbank erstellen:
DB-Anschlussplan
Für Ungeduldige: Der ausführbare Code befindet sich in diesem Repository . Das interaktive Datenbankschema finden Sie hier . Ein Spickzettel zum Schreiben von ORM-Abfragen befindet sich am Ende des Artikels.
Lassen Sie uns zustimmen, dass wir im Text des Artikels das Wort "Tabelle" anstelle von "Beziehung" und das Wort "Feld" anstelle von "Attribut" verwenden. Durch Zuweisung müssen wir eine Tabelle mit Musikdateien in der Datenbank platzieren und gleichzeitig die Datenredundanz beseitigen. Die Originaltabelle (CSV-Format) enthält die folgenden Felder (Titel, Genre, Musiker, Album, Länge, Albumjahr, Sammlung, Sammlungsjahr). Die Verbindungen zwischen ihnen sind wie folgt:
- Jeder Musiker kann in mehreren Genres singen, und mehrere Musiker können in einem Genre auftreten (viele zu viele Beziehungen).
- Ein oder mehrere Musiker können an der Erstellung eines Albums teilnehmen (Viele-zu-Viele-Beziehung).
- Ein Titel gehört nur zu einem Album (eine zu viele Beziehung)
- Tracks können in mehreren Sammlungen enthalten sein (Viele-zu-Viele-Beziehung)
- Der Titel darf nicht in eine Sammlung aufgenommen werden.
Nehmen wir zur Vereinfachung an, Genre-Namen, Künstlernamen, Album-Namen und Sammlungsnamen werden nicht wiederholt. Titelnamen können wiederholt werden. Wir haben 8 Tabellen in der Datenbank entworfen:
- Genres (Genres)
- genres_musicians (Staging-Tabelle)
- Musiker (Musiker)
- Alben_Musiker (Zwischentabelle)
- Alben (Alben)
- Spuren
- collection_tracks (Staging-Tabelle)
- Sammlungen (Sammlungen)
* Dieses Schema ist ein Test, der von einem der DZ stammt. Es hat einige Nachteile - zum Beispiel gibt es keine Verbindung zwischen den Tracks und dem Musiker sowie dem Track mit dem Genre. Dies ist jedoch für das Lernen nicht unbedingt erforderlich, und wir werden diesen Nachteil auslassen.
Für den Test habe ich zwei Datenbanken auf den lokalen Postgres erstellt: "TestSQL" und "TestORM", Zugriff darauf: Login und Passworttest. Lassen Sie uns endlich etwas Code schreiben!
Erstellen Sie Verbindungen und Tabellen
Erstellen Sie Verbindungen zur Datenbank
* Der Code der Funktionen read_data und clear_db befindet sich im Repository .
DSN_SQL = 'postgresql://test:test@localhost:5432/TestSQL'
DSN_ORM = 'postgresql://test:test@localhost:5432/TestORM'
# CSV .
DATA = read_data('data/demo-data.csv')
print('Connecting to DB\'s...')
# , .
engine_orm = sa.create_engine(DSN_ORM)
Session_ORM = sessionmaker(bind=engine_orm)
session_orm = Session_ORM()
engine_sql = sa.create_engine(DSN_SQL)
Session_SQL = sessionmaker(bind=engine_sql)
session_sql = Session_SQL()
print('Clearing the bases...')
# . .
clear_db(sa, engine_sql)
clear_db(sa, engine_orm)
Wir erstellen Tabellen auf klassische Weise mit SQL
* read_query . .
print('\nPreparing data for SQL job...')
print('Creating empty tables...')
session_sql.execute(read_query('queries/create-tables.sql'))
session_sql.commit()
print('\nAdding musicians...')
query = read_query('queries/insert-musicians.sql')
res = session_sql.execute(query.format(','.join({f"('{x['musician']}')" for x in DATA})))
print(f'Inserted {res.rowcount} musicians.')
print('\nAdding genres...')
query = read_query('queries/insert-genres.sql')
res = session_sql.execute(query.format(','.join({f"('{x['genre']}')" for x in DATA})))
print(f'Inserted {res.rowcount} genres.')
print('\nLinking musicians with genres...')
# assume that musician + genre has to be unique
genres_musicians = {x['musician'] + x['genre']: [x['musician'], x['genre']] for x in DATA}
query = read_query('queries/insert-genre-musician.sql')
# this query can't be run in batch, so execute one by one
res = 0
for key, value in genres_musicians.items():
res += session_sql.execute(query.format(value[1], value[0])).rowcount
print(f'Inserted {res} connections.')
print('\nAdding albums...')
# assume that albums has to be unique
albums = {x['album']: x['album_year'] for x in DATA}
query = read_query('queries/insert-albums.sql')
res = session_sql.execute(query.format(','.join({f"('{x}', '{y}')" for x, y in albums.items()})))
print(f'Inserted {res.rowcount} albums.')
print('\nLinking musicians with albums...')
# assume that musicians + album has to be unique
albums_musicians = {x['musician'] + x['album']: [x['musician'], x['album']] for x in DATA}
query = read_query('queries/insert-album-musician.sql')
# this query can't be run in batch, so execute one by one
res = 0
for key, values in albums_musicians.items():
res += session_sql.execute(query.format(values[1], values[0])).rowcount
print(f'Inserted {res} connections.')
print('\nAdding tracks...')
query = read_query('queries/insert-track.sql')
# this query can't be run in batch, so execute one by one
res = 0
for item in DATA:
res += session_sql.execute(query.format(item['track'], item['length'], item['album'])).rowcount
print(f'Inserted {res} tracks.')
print('\nAdding collections...')
query = read_query('queries/insert-collections.sql')
res = session_sql.execute(query.format(','.join({f"('{x['collection']}', {x['collection_year']})" for x in DATA if x['collection'] and x['collection_year']})))
print(f'Inserted {res.rowcount} collections.')
print('\nLinking collections with tracks...')
query = read_query('queries/insert-collection-track.sql')
# this query can't be run in batch, so execute one by one
res = 0
for item in DATA:
res += session_sql.execute(query.format(item['collection'], item['track'])).rowcount
print(f'Inserted {res} connections.')
session_sql.commit()
Tatsächlich erstellen wir Verzeichnisse in Paketen (Genres, Musiker, Alben, Sammlungen) und verknüpfen dann in einer Schleife den Rest der Daten und erstellen manuell Zwischentabellen. Führen Sie den Code aus und stellen Sie sicher, dass die Datenbank erstellt wurde. Die Hauptsache ist, nicht zu vergessen, commit () in der Sitzung aufzurufen.
Jetzt versuchen wir das Gleiche, verwenden aber den ORM-Ansatz. Um mit ORM arbeiten zu können, müssen wir Datenklassen beschreiben. Dazu erstellen wir 8 Klassen (eine für jede Tabelle).
Liste der DB-Klassen
.
Base = declarative_base()
class Genre(Base):
__tablename__ = 'genres'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(20), unique=True)
# Musician genres_musicians
musicians = relationship("Musician", secondary='genres_musicians')
class Musician(Base):
__tablename__ = 'musicians'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50), unique=True)
# Genre genres_musicians
genres = relationship("Genre", secondary='genres_musicians')
# Album albums_musicians
albums = relationship("Album", secondary='albums_musicians')
class GenreMusician(Base):
__tablename__ = 'genres_musicians'
# ,
__table_args__ = (PrimaryKeyConstraint('genre_id', 'musician_id'),)
#
genre_id = sa.Column(sa.Integer, sa.ForeignKey('genres.id'))
musician_id = sa.Column(sa.Integer, sa.ForeignKey('musicians.id'))
class Album(Base):
__tablename__ = 'albums'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50), unique=True)
year = sa.Column(sa.Integer)
# Musician albums_musicians
musicians = relationship("Musician", secondary='albums_musicians')
class AlbumMusician(Base):
__tablename__ = 'albums_musicians'
# ,
__table_args__ = (PrimaryKeyConstraint('album_id', 'musician_id'),)
#
album_id = sa.Column(sa.Integer, sa.ForeignKey('albums.id'))
musician_id = sa.Column(sa.Integer, sa.ForeignKey('musicians.id'))
class Track(Base):
__tablename__ = 'tracks'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(100))
length = sa.Column(sa.Integer)
# album_id ,
album_id = sa.Column(sa.Integer, ForeignKey('albums.id'))
# Collection collections_tracks
collections = relationship("Collection", secondary='collections_tracks')
class Collection(Base):
__tablename__ = 'collections'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50))
year = sa.Column(sa.Integer)
# Track collections_tracks
tracks = relationship("Track", secondary='collections_tracks')
class CollectionTrack(Base):
__tablename__ = 'collections_tracks'
# ,
__table_args__ = (PrimaryKeyConstraint('collection_id', 'track_id'),)
#
collection_id = sa.Column(sa.Integer, sa.ForeignKey('collections.id'))
track_id = sa.Column(sa.Integer, sa.ForeignKey('tracks.id'))
Wir müssen nur eine Basisklasse Base für den deklarativen Stil der Beschreibung von Tabellen erstellen und von dieser erben. Die ganze Magie von Tabellenbeziehungen liegt in der korrekten Verwendung von Beziehung und ForeignKey. Der Code gibt an, in welchem Fall wir welche Beziehung erstellen. Die Hauptsache ist, nicht zu vergessen, die Beziehung auf beiden Seiten der Viele-zu-Viele-Beziehung zu registrieren.
Das direkte Erstellen von Tabellen mithilfe des ORM-Ansatzes erfolgt durch Aufrufen von:
Base.metadata.create_all(engine_orm)
Und hier kommt die Magie ins Spiel, buchstäblich werden alle Klassen , die durch Vererbung von Base im Code deklariert wurden, zu Tabellen. Ich habe nicht sofort gesehen, wie angegeben werden soll, welche Instanzen jetzt erstellt werden sollen und welche für die spätere Erstellung verschoben werden sollen (z. B. in einer anderen Datenbank). Sicher gibt es so einen Weg, aber in unserem Code werden alle Klassen, die von Base erben, sofort instanziiert. Denken Sie daran.
Das Füllen von Tabellen mit dem ORM-Ansatz sieht folgendermaßen aus:
Tabellen mit Daten über ORM füllen
print('\nPreparing data for ORM job...')
for item in DATA:
#
genre = session_orm.query(Genre).filter_by(name=item['genre']).scalar()
if not genre:
genre = Genre(name=item['genre'])
session_orm.add(genre)
#
musician = session_orm.query(Musician).filter_by(name=item['musician']).scalar()
if not musician:
musician = Musician(name=item['musician'])
musician.genres.append(genre)
session_orm.add(musician)
#
album = session_orm.query(Album).filter_by(name=item['album']).scalar()
if not album:
album = Album(name=item['album'], year=item['album_year'])
album.musicians.append(musician)
session_orm.add(album)
#
# ,
#
track = session_orm.query(Track).join(Album).filter(and_(Track.name == item['track'],
Album.name == item['album'])).scalar()
if not track:
track = Track(name=item['track'], length=item['length'])
track.album_id = album.id
session_orm.add(track)
# ,
if item['collection']:
collection = session_orm.query(Collection).filter_by(name=item['collection']).scalar()
if not collection:
collection = Collection(name=item['collection'], year=item['collection_year'])
collection.tracks.append(track)
session_orm.add(collection)
session_orm.commit()
Sie müssen jedes Nachschlagewerk (Genres, Musiker, Alben, Sammlungen) nach Stück ausfüllen. Bei SQL-Abfragen konnten Batchdaten hinzugefügt werden. Zwischentabellen müssen jedoch nicht explizit erstellt werden, dafür sind die internen Mechanismen von SQLAlchemy verantwortlich.
Datenbankabfragen
Bei der Zuweisung müssen 15 Abfragen sowohl mit SQL- als auch mit ORM-Techniken geschrieben werden. Hier ist eine Liste der Fragen, die in der Reihenfolge zunehmender Schwierigkeit gestellt werden:
- Titel und Erscheinungsjahr der 2018 veröffentlichten Alben;
- Titel und Dauer des längsten Titels;
- den Namen der Titel, deren Dauer mindestens 3,5 Minuten beträgt;
- Titel von Sammlungen, die im Zeitraum von 2018 bis einschließlich 2020 veröffentlicht wurden;
- Darsteller, deren Name aus 1 Wort besteht;
- der Name der Tracks, die das Wort "ich" enthalten.
- die Anzahl der Darsteller in jedem Genre;
- die Anzahl der Titel in den Alben 2019-2020;
- durchschnittliche Titellänge für jedes Album;
- alle Künstler, die 2020 keine Alben veröffentlicht haben;
- Titel von Sammlungen, in denen ein bestimmter Künstler vertreten ist;
- den Namen der Alben, in denen es Interpreten von mehr als einem Genre gibt;
- den Namen der Titel, die nicht in den Sammlungen enthalten sind;
- die Künstler, die den kürzesten Track geschrieben haben (theoretisch kann es mehrere solcher Tracks geben);
- Der Name der Alben mit der geringsten Anzahl von Titeln.
Wie Sie sehen können, implizieren die obigen Fragen sowohl die einfache Auswahl und Verkettung von Tabellen als auch die Verwendung von Aggregatfunktionen.
Im Folgenden finden Sie Lösungen für jede der 15 Abfragen in zwei Optionen (unter Verwendung von SQL und ORM). Im Code werden die Anforderungen paarweise angezeigt, um anzuzeigen, dass die Ergebnisse in der Konsolenausgabe identisch sind.
Anfragen und deren kurze Beschreibung
print('\n1. All albums from 2018:')
query = read_query('queries/select-album-by-year.sql').format(2018)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album).filter_by(year=2018):
print(item.name)
print('\n2. Longest track:')
query = read_query('queries/select-longest-track.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).order_by(Track.length.desc()).slice(0, 1):
print(f'{item.name}, {item.length}')
print('\n3. Tracks with length not less 3.5min:')
query = read_query('queries/select-tracks-over-length.sql').format(310)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).filter(310 <= Track.length).order_by(Track.length.desc()):
print(f'{item.name}, {item.length}')
print('\n4. Collections between 2018 and 2020 years (inclusive):')
query = read_query('queries/select-collections-by-year.sql').format(2018, 2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Collection).filter(2018 <= Collection.year,
Collection.year <= 2020):
print(item.name)
print('\n5. Musicians with name that contains not more 1 word:')
query = read_query('queries/select-musicians-by-name.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Musician).filter(Musician.name.notlike('%% %%')):
print(item.name)
print('\n6. Tracks that contains word "me" in name:')
query = read_query('queries/select-tracks-by-name.sql').format('me')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).filter(Track.name.like('%%me%%')):
print(item.name)
print('Ok, let\'s start serious work')
print('\n7. How many musicians plays in each genres:')
query = read_query('queries/count-musicians-by-genres.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Genre).join(Genre.musicians).order_by(func.count(Musician.id).desc()).group_by(
Genre.id):
print(f'{item.name}, {len(item.musicians)}')
print('\n8. How many tracks in all albums 2019-2020:')
query = read_query('queries/count-tracks-in-albums-by-year.sql').format(2019, 2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track, Album).join(Album).filter(2019 <= Album.year, Album.year <= 2020):
print(f'{item[0].name}, {item[1].year}')
print('\n9. Average track length in each album:')
query = read_query('queries/count-average-tracks-by-album.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album, func.avg(Track.length)).join(Track).order_by(func.avg(Track.length)).group_by(
Album.id):
print(f'{item[0].name}, {item[1]}')
print('\n10. All musicians that have no albums in 2020:')
query = read_query('queries/select-musicians-by-album-year.sql').format(2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery = session_orm.query(distinct(Musician.name)).join(Musician.albums).filter(Album.year == 2020)
for item in session_orm.query(distinct(Musician.name)).filter(~Musician.name.in_(subquery)).order_by(
Musician.name.asc()):
print(f'{item}')
print('\n11. All collections with musician Steve:')
query = read_query('queries/select-collection-by-musician.sql').format('Steve')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Collection).join(Collection.tracks).join(Album).join(Album.musicians).filter(
Musician.name == 'Steve').order_by(Collection.name):
print(f'{item.name}')
print('\n12. Albums with musicians that play in more than 1 genre:')
query = read_query('queries/select-albums-by-genres.sql').format(1)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album).join(Album.musicians).join(Musician.genres).having(func.count(distinct(
Genre.name)) > 1).group_by(Album.id).order_by(Album.name):
print(f'{item.name}')
print('\n13. Tracks that not included in any collections:')
query = read_query('queries/select-absence-tracks-in-collections.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
# Important! Despite the warning, following expression does not work: "Collection.id is None"
for item in session_orm.query(Track).outerjoin(Track.collections).filter(Collection.id == None):
print(f'{item.name}')
print('\n14. Musicians with shortest track length:')
query = read_query('queries/select-musicians-min-track-length.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery = session_orm.query(func.min(Track.length))
for item in session_orm.query(Musician, Track.length).join(Musician.albums).join(Track).group_by(
Musician.id, Track.length).having(Track.length == subquery).order_by(Musician.name):
print(f'{item[0].name}, {item[1]}')
print('\n15. Albums with minimum number of tracks:')
query = read_query('queries/select-albums-with-minimum-tracks.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery1 = session_orm.query(func.count(Track.id)).group_by(Track.album_id).order_by(func.count(Track.id)).limit(1)
subquery2 = session_orm.query(Track.album_id).group_by(Track.album_id).having(func.count(Track.id) == subquery1)
for item in session_orm.query(Album).join(Track).filter(Track.album_id.in_(subquery2)).order_by(Album.name):
print(f'{item.name}')
Für diejenigen, die nicht in das Lesen des Codes eintauchen möchten, werde ich versuchen zu zeigen, wie "rohes" SQL und seine Alternative im ORM-Ausdruck aussehen, lass uns gehen!
Spickzettel zum Abgleichen von SQL-Abfragen und ORM-Ausdrücken
1. Titel und Erscheinungsjahr der Alben 2018:
SQL
select name
from albums
where year=2018
ORM
session_orm.query(Album).filter_by(year=2018)
2. Titel und Dauer des längsten Titels:
SQL
select name, length
from tracks
order by length DESC
limit 1
ORM
session_orm.query(Track).order_by(Track.length.desc()).slice(0, 1)
3. der Name der Titel, deren Dauer mindestens 3,5 Minuten beträgt:
SQL
select name, length
from tracks
where length >= 310
order by length DESC
ORM
session_orm.query(Track).filter(310 <= Track.length).order_by(Track.length.desc())
4. die Namen der im Zeitraum von 2018 bis einschließlich 2020 veröffentlichten Sammlungen:
SQL
select name
from collections
where (year >= 2018) and (year <= 2020)
ORM
session_orm.query(Collection).filter(2018 <= Collection.year, Collection.year <= 2020)
* Beachten Sie, dass im Folgenden die Filterung mit filter und nicht mit filter_by angegeben wird.
5.Ausführer, deren Name aus 1 Wort besteht:
SQL
select name
from musicians
where not name like '%% %%'
ORM
session_orm.query(Musician).filter(Musician.name.notlike('%% %%'))
6. Name der Tracks, die das Wort "me" enthalten:
SQL
select name
from tracks
where name like '%%me%%'
ORM
session_orm.query(Track).filter(Track.name.like('%%me%%'))
7. Anzahl der Darsteller in jedem Genre:
SQL
select g.name, count(m.name)
from genres as g
left join genres_musicians as gm on g.id = gm.genre_id
left join musicians as m on gm.musician_id = m.id
group by g.name
order by count(m.id) DESC
ORM
session_orm.query(Genre).join(Genre.musicians).order_by(func.count(Musician.id).desc()).group_by(Genre.id)
8.Anzahl der in den Alben enthaltenen Titel 2019-2020:
SQL
select t.name, a.year
from albums as a
left join tracks as t on t.album_id = a.id
where (a.year >= 2019) and (a.year <= 2020)
ORM
session_orm.query(Track, Album).join(Album).filter(2019 <= Album.year, Album.year <= 2020)
9. Durchschnittliche Titellänge für jedes Album:
SQL
select a.name, AVG(t.length)
from albums as a
left join tracks as t on t.album_id = a.id
group by a.name
order by AVG(t.length)
ORM
session_orm.query(Album, func.avg(Track.length)).join(Track).order_by(func.avg(Track.length)).group_by(Album.id)
10. Alle Künstler, die 2020 keine Alben veröffentlicht haben:
SQL
select distinct m.name
from musicians as m
where m.name not in (
select distinct m.name
from musicians as m
left join albums_musicians as am on m.id = am.musician_id
left join albums as a on a.id = am.album_id
where a.year = 2020
)
order by m.name
ORM
subquery = session_orm.query(distinct(Musician.name)).join(Musician.albums).filter(Album.year == 2020)
session_orm.query(distinct(Musician.name)).filter(~Musician.name.in_(subquery)).order_by(Musician.name.asc())
11. die Namen der Zusammenstellungen, in denen ein bestimmter Künstler (Steve) anwesend ist:
SQL
select distinct c.name
from collections as c
left join collections_tracks as ct on c.id = ct.collection_id
left join tracks as t on t.id = ct.track_id
left join albums as a on a.id = t.album_id
left join albums_musicians as am on am.album_id = a.id
left join musicians as m on m.id = am.musician_id
where m.name like '%%Steve%%'
order by c.name
ORM
session_orm.query(Collection).join(Collection.tracks).join(Album).join(Album.musicians).filter(Musician.name == 'Steve').order_by(Collection.name)
12. der Name der Alben, in denen es Künstler aus mehr als einem Genre gibt:
SQL
select a.name
from albums as a
left join albums_musicians as am on a.id = am.album_id
left join musicians as m on m.id = am.musician_id
left join genres_musicians as gm on m.id = gm.musician_id
left join genres as g on g.id = gm.genre_id
group by a.name
having count(distinct g.name) > 1
order by a.name
ORM
session_orm.query(Album).join(Album.musicians).join(Musician.genres).having(func.count(distinct(Genre.name)) > 1).group_by(Album.id).order_by(Album.name)
13. Name der Spuren, die nicht in Sammlungen enthalten sind:
SQL
select t.name
from tracks as t
left join collections_tracks as ct on t.id = ct.track_id
where ct.track_id is null
ORM
session_orm.query(Track).outerjoin(Track.collections).filter(Collection.id == None)
* Beachten Sie, dass trotz der Warnung in PyCharm die Filterbedingung auf diese Weise zusammengestellt werden muss. Wenn Sie sie wie von der IDE vorgeschlagen schreiben ("Collection.id is None"), funktioniert sie nicht.
14. Künstler, die den kürzesten Track geschrieben haben (theoretisch könnte es mehrere solcher Tracks geben):
SQL
select m.name, t.length
from tracks as t
left join albums as a on a.id = t.album_id
left join albums_musicians as am on am.album_id = a.id
left join musicians as m on m.id = am.musician_id
group by m.name, t.length
having t.length = (select min(length) from tracks)
order by m.name
ORM
subquery = session_orm.query(func.min(Track.length)) session_orm.query(Musician, Track.length).join(Musician.albums).join(Track).group_by(Musician.id, Track.length).having(Track.length == subquery).order_by(Musician.name)
15. der Name der Alben mit der geringsten Anzahl von Titeln:
SQL
select distinct a.name
from albums as a
left join tracks as t on t.album_id = a.id
where t.album_id in (
select album_id
from tracks
group by album_id
having count(id) = (
select count(id)
from tracks
group by album_id
order by count
limit 1
)
)
order by a.name
ORM
subquery1 = session_orm.query(func.count(Track.id)).group_by(Track.album_id).order_by(func.count(Track.id)).limit(1)
subquery2 = session_orm.query(Track.album_id).group_by(Track.album_id).having(func.count(Track.id) == subquery1)
session_orm.query(Album).join(Track).filter(Track.album_id.in_(subquery2)).order_by(Album.name)
Wie Sie sehen können, implizieren die obigen Fragen sowohl einfache Auswahl- und Verknüpfungstabellen als auch die Verwendung von Aggregatfunktionen und Unterabfragen. All dies kann mit SQLAlchemy sowohl im SQL- als auch im ORM-Modus durchgeführt werden. Die Vielzahl von Operatoren und Methoden ermöglicht es Ihnen, eine Abfrage beliebiger Komplexität auszuführen.
Ich hoffe, dass dieses Material Anfängern hilft, schnell und effizient mit dem Schreiben von Anfragen zu beginnen.