Wir setzen das Thema Informationssicherheit fort und veröffentlichen die Übersetzung des Artikels von Coussement Bruno.
Hinzufügen von Rauschen zu vorhandenen Daten, Hinzufügen von Rauschen nur zu Datenmanipulationsergebnissen oder Generieren synthetischer Daten? Vertrauen wir unserer Intuition?

Unternehmen wachsen und ihre Vorschriften zur Cybersicherheit werden strenger, leitende Architekten nehmen Trends an ... All dies führt dazu, dass die Notwendigkeit (oder Verpflichtung), die mit Datenschutz und Informationslecks verbundenen Risiken zu verringern, nur für betroffene Personen zunimmt.
In diesem Fall werden häufig Methoden zur Anonymisierung oder Tokenisierung von Daten verwendet, die jedoch auch die Möglichkeit bieten, private Informationen offenzulegen (siehe diesen Artikel, um zu verstehen, warum dies geschieht).
Synthetische Daten generieren
Synthetische Daten haben einen grundlegenden Unterschied. Ziel ist es, einen Datengenerator zu erstellen, der dieselben globalen Statistiken wie die Originaldaten anzeigt. Die Unterscheidung des Originals vom Endergebnis sollte für ein Modell oder eine Person schwierig sein.
Lassen Sie uns das Obige veranschaulichen, indem Sie mithilfe des TGAN-Modells synthetische Daten für den Covertype-Datensatz generieren .

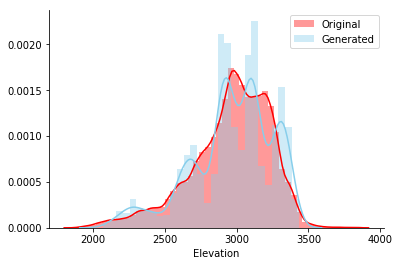
Nachdem ich das Modell in dieser Tabelle trainiert hatte, generierte ich 5000 Zeilen und zeichnete ein Histogramm der Elevation- Spalte des ursprünglichen und generierten Satzes. Es scheint, dass beide Linien visuell zusammenfallen.
Um die Beziehung zwischen Balkenpaaren zu testen, wird ein gepaartes Diagramm aller durchgehenden Balken angezeigt. Die Form, die die blaugrünen Punkte bilden (generiert), sollte visuell mit der Form der roten Punkte (Original) übereinstimmen. Und so geschah es, cool!

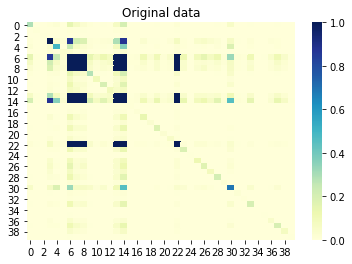
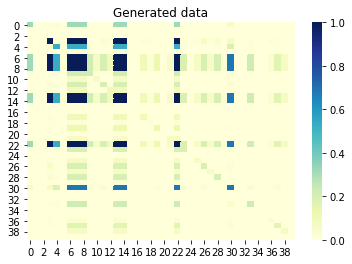
Wenn wir uns nun die gegenseitige Information (auch als vorzeichenlose Korrelation bezeichnet) zwischen Spalten ansehen, sollten die miteinander korrelierten Spalten auch in der generierten Menge korreliert werden. Umgekehrt sollten nicht korrelierte Spalten in der ursprünglichen Menge nicht in der generierten Menge korreliert werden. Ein Wert nahe 0 bedeutet keine Korrelation, und ein Wert nahe 1 bedeutet perfekte Korrelation. Großartig, das ist es!
Gegenseitige Information zwischen Spalten Originalsatz:
Gegenseitige Information zwischen Spalten erzeugte Menge:
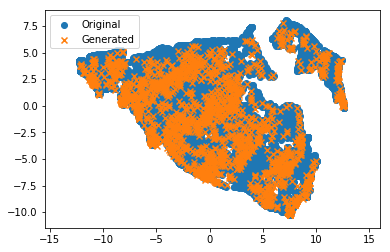
Als letzten Test wollte ich die UMAP-Methode (Nonlinear Dimensionality Reduction ) für die ursprüngliche Menge trainieren und die Ursprungspunkte in den 2D-Raum projizieren. Ich gebe das generierte Set in denselben Projektor ein. Die orangefarbenen Kreuze (generiert) sollten sich in den blauen Punktwolken des Originaldatensatzes befinden. So ist das! Ausgezeichnet!
OK, das Experimentieren mit Daten macht Spaß!
Für schwerwiegendere Fälle gibt es zwei Hauptansätze:
- : , . , . .
Es lohnt sich, auf Initiativen wie Synthetic Data Vault , Gretel.AI , Mostly.ai , MDClone , Hazy zu achten .
Bereits heute können Sie einen Proof-of-Concept mit synthetischen Daten erstellen, um eines der folgenden häufigen Probleme von IT-Organisationen zu lösen:
- Keine Nutzlast in der Entwicklungsumgebung
Angenommen, Sie arbeiten an einem Datenprodukt (es kann alles sein), bei dem sich die Daten, an denen Sie interessiert sind, in einer Produktionsumgebung mit einer sehr strengen Zugriffsrichtlinie befinden. Leider haben Sie nur ohne interessante Daten Zugriff auf die Entwicklungsumgebung.
- Gott-Modus - Zugriffsrechte für Ingenieure und Datenwissenschaftler
Angenommen, Sie sind Datenwissenschaftler und plötzlich hat ein Informationssicherheitsbeauftragter Ihre dringend benötigten Berechtigungen für den Zugriff auf Produktionsdaten eingeschränkt. Wie können Sie in einem so schwierigen und begrenzten Umfeld weiterhin gute Arbeit leisten?
- Übermittlung vertraulicher Daten an einen nicht vertrauenswürdigen externen Partner
Sie sind Teil von Unternehmen X. Organisation Y möchte sein neuestes cooles Datenprodukt vorstellen (es kann alles sein).
Sie bitten Sie, Daten zu extrahieren, um Ihnen das Produkt zu zeigen.
Was haben synthetische Daten mit differenziertem Datenschutz zu tun?
Die Haupteigenschaft der Erzeugung synthetischer Daten besteht darin, dass unabhängig von der Nachbearbeitung oder dem Hinzufügen von Informationen von Drittanbietern niemand jemals wissen kann, ob ein Objekt im ursprünglichen Satz enthalten ist, und auch nicht in der Lage ist, die Eigenschaften dieses Objekts abzurufen. Diese Eigenschaft ist Teil eines umfassenderen Konzepts namens "Differential Privacy" (DP).
Globale und lokale unterschiedliche Privatsphäre
DP ist in 2 Typen unterteilt.
Oft ist nur das Ergebnis einer bestimmten Aufgabe von Interesse (z. B. Schulung eines Modells auf der Grundlage nicht offengelegter Daten von Patienten aus verschiedenen Krankenhäusern, Berechnung der durchschnittlichen Anzahl von Personen, die jemals eine Straftat begangen haben usw.). Dann sollte auf die globale unterschiedliche Privatsphäre geachtet werden.
In diesem Fall sieht ein nicht vertrauenswürdiger Benutzer niemals vertrauliche Daten. Stattdessen teilt er einem vertrauenswürdigen Kurator (mit globalen differenzierten Datenschutzmechanismen) mit, der Zugriff auf vertrauliche Daten hat, welche Vorgänge auszuführen sind.
Nur das Ergebnis wird dem nicht vertrauenswürdigen Benutzer gemeldet. Ich empfehle Pysyftund OpenDP, wenn Sie weitere Informationen zu ähnlichen Tools benötigen.
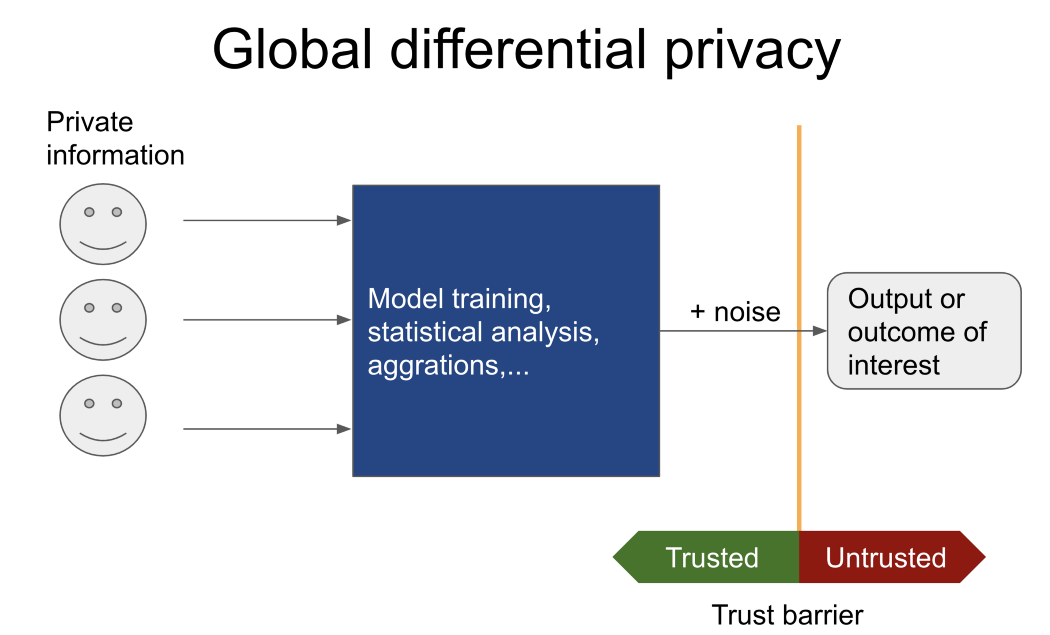
Wenn dagegen Daten an eine nicht vertrauenswürdige Partei übertragen werden sollen, spielen die Grundsätze der lokalen unterschiedlichen Vertraulichkeit eine Rolle. Traditionell wird dies erreicht, indem jeder Zeile in einer Tabelle oder Datenbank Rauschen hinzugefügt wird. Die Menge des hinzugefügten Rauschens hängt ab von:
- das erforderliche Maß an Vertraulichkeit (das berühmte Epsilon in der DP-Literatur),
- die Größe des Datensatzes (ein größerer Datensatz erfordert weniger Rauschen, um das gleiche Maß an Vertraulichkeit zu erreichen),
- Spaltendatentyp (quantitativ, kategorial, ordinal).

Theoretisch liefert der globale DP-Mechanismus (Hinzufügen von Rauschen zum Ergebnis) bei gleicher Vertraulichkeit genauere Ergebnisse als der lokale Mechanismus (Leitungspegelrauschen).
Daher können synthetische Datenerzeugungsmethoden als eine Form lokaler DP betrachtet werden.
Für weitere Informationen zu diesen Themen empfehle ich Ihnen, die folgenden Quellen zu konsultieren:
- www.udacity.com/course/secure-and-private-ai--ud185
- medium.com/@arbidha1412/local-and-global-differential-privacy-249aaa3571
- www.openmined.org
Empfehlung
Schauen wir uns nun ein genaueres Beispiel an. Sie möchten eine Tabelle mit persönlichen Informationen für eine nicht vertrauenswürdige Partei freigeben.
Im Moment können Sie entweder vorhandenen Datenleitungen Rauschen hinzufügen (lokaler DP), ein robustes System einrichten und verwenden (globaler DP) oder synthetische Daten basierend auf dem Original generieren.
Vorhandenen Datenleitungen sollte Rauschen hinzugefügt werden, wenn
- Sie wissen nicht, welche Operation an den Daten nach der Veröffentlichung ausgeführt wird.
- Sie müssen regelmäßig eine Aktualisierung der Originaldaten freigeben (= diesen Workflow als Teil eines stabilen Batch-Prozesses verwenden).
- Sie und die Dateneigentümer vertrauen darauf, dass die Person / das Team / die Organisation den Originaldaten Rauschen hinzufügt.
Hier empfehle ich, mit den OpenDP- Tools zu beginnen .
Der bekannteste Fall von differenzierter Privatsphäre ist die US-Volkszählung (siehe databricks.com/session_na20/ Using-apache-spark-and- differential-privacy- for-protecting- the-privacy-of-the- 2020- census- respondents ).
Diese Daten werden alle drei Jahre neu berechnet und aktualisiert. Es handelt sich hauptsächlich um numerische Daten, die auf mehreren Ebenen (Landkreis, Bundesstaat, nationale Ebene) aggregiert und veröffentlicht werden.
Installieren und verwenden Sie ein vertrauenswürdiges System, wenn
- Das von Ihnen angegebene System unterstützt die Aufgaben und Vorgänge, die darauf ausgeführt werden.
- Basisdaten werden an verschiedenen Orten gespeichert und können nicht verlassen werden (z. B. in verschiedenen Krankenhäusern).
- Sie und die Dateneigentümer vertrauen tatsächlich dem aktuellen System und der Person / dem Team / der Organisation, die es einrichtet.
Als Benutzer sensibler Daten erhalten Sie genauere Ergebnisse als beim ersten Ansatz.
Viele Frameworks verfügen derzeit nicht über alle erforderlichen Funktionen, um dieses Biest auf sichere, skalierbare und überprüfbare Weise bereitzustellen. Hier ist noch viel Ingenieurarbeit erforderlich.
Mit zunehmender Akzeptanz kann DP jedoch eine gute Alternative für große Organisationen und Unternehmen sein.
Ich empfehle hier mit OpenMined zu beginnen .
Es ist möglich, synthetische Daten zu generieren, wenn
- (<1 , <100 ),
- ad-hoc ( ),
- / / , .
Wie bei dem oben beschriebenen kleinen Experiment sind die Ergebnisse vielversprechend. Es erfordert auch keine hervorragenden Kenntnisse der DP-Systeme. Sie können heute beginnen, wenn Sie müssen, es über Nacht trainieren lassen und sozusagen das gemeinsame synthetische Set für morgen früh vorbereiten.
Der größte Nachteil ist, dass die Schulung und Wartung dieser komplexen Modelle teuer werden kann, wenn die Datenmenge zunimmt. Jeder Tisch erfordert auch ein eigenes vollständiges Training des Modells (tragbares Training funktioniert hier nicht). Selbst mit einem erheblichen Rechenbudget können Sie nicht auf Hunderte von Tabellen skalieren.
Ansonsten hast du kein Glück.
Fazit
Da Datenschutz heute wichtiger denn je ist, verfügen wir über hervorragende Methoden zum Generieren synthetischer Daten oder zum Hinzufügen von Rauschen zu vorhandenen Daten. Sie alle haben jedoch immer noch ihre Grenzen. Abgesehen von einigen Nischenfällen wurde noch kein skalierbares und flexibles Tool für Unternehmen entwickelt, mit dem Daten mit persönlichen Informationen an nicht vertrauenswürdige Parteien übertragen werden können.
Dateneigentümer müssen weiterhin etablierten Methoden oder Systemen vertrauen, was viel Vertrauen von ihnen erfordert. Das ist das größte Problem!
Wenn Sie es in der Zwischenzeit ausprobieren möchten (Proof of Concept, testen Sie es einfach), öffnen Sie einen der obigen Links.