Obsessive Melodie (englische Ohrwürmer) - ein bekanntes und manchmal irritierendes Phänomen. Sobald eines davon im Kopf steckt, kann es ziemlich schwierig sein, es loszuwerden. Untersuchungen haben gezeigt , dass die sogenannte Interaktion mit der Originalkomposition , ob sie nun angehört oder gesungen wird, dazu beiträgt, die aufdringliche Melodie zu vertreiben. Aber was ist, wenn Sie sich nicht an den Namen des Songs erinnern können, sondern nur die Melodie summen können?
Wenn vorhandene Methoden zum Vergleichen einer gesungenen Melodie mit ihrer ursprünglichen polyphonen Studioaufnahme verwendet werden, treten eine Reihe von Schwierigkeiten auf. Der Klang einer Live- oder Studioaufnahme mit Texten, Hintergrundgesang und Instrumenten kann sich stark von dem unterscheiden, was eine Person summt. Außerdem hat unsere Version aus Versehen oder aufgrund des Designs möglicherweise nicht genau die gleiche Tonhöhe, Tonart, Tonart oder den gleichen Rhythmus. Aus diesem Grund ordnen so viele aktuelle Ansätze für die Abfrage durch Brummsystem eine gesungene Melodie einer Datenbank mit bereits vorhandenen Melodien oder anderen gesungenen Versionen dieses Songs zu, anstatt sie direkt zu identifizieren. Diese Art von Ansatz basiert jedoch häufig auf einer begrenzten Datenbank, die manuell aktualisiert werden muss. Hum to Search
wurde im Oktober gestartetist ein neues, vollständig maschinell erlernbares Google-Suchsystem, mit dem eine Person ein Lied finden kann, indem sie es singt oder hetzt. Im Gegensatz zu bestehenden Methoden wird bei diesem Ansatz eine Einbettung aus dem Spektrogramm des Songs erstellt, wobei die Zwischendarstellung umgangen wird. Auf diese Weise kann das Modell unsere Melodie direkt mit der ursprünglichen (polyphonen) Aufnahme vergleichen, ohne dass für jede Spur eine andere Melodie oder MIDI-Version erforderlich ist. Es muss auch keine komplexe handgefertigte Logik verwendet werden, um die Melodie zu extrahieren. Dieser Ansatz vereinfacht die Datenbank für Hum to Search erheblich und ermöglicht es Ihnen, ständig Einbettungen von Originaltiteln aus der ganzen Welt, selbst der neuesten Veröffentlichungen, hinzuzufügen.
Wie es funktioniert
Viele vorhandene Musikerkennungssysteme wandeln es vor der Verarbeitung eines Audio-Samples in ein Spektrogramm um, um eine korrektere Übereinstimmung zu finden. Es gibt jedoch ein Problem beim Erkennen einer gesungenen Melodie - sie enthält oft relativ wenig Informationen, wie in diesem Beispiel des Songs "Bella Ciao" . Der Unterschied zwischen der gesungenen Version und demselben Segment gegenüber der entsprechenden Studioaufnahme kann mithilfe der folgenden Spektrogramme visualisiert werden :

Visualisierung des gesungenen Snippets und seiner Studioaufnahme
Angesichts des Bildes links muss das Modell das Audio, das mit dem Bild rechts übereinstimmt, in einer Sammlung von mehr als 50 Millionen ähnlichen Bildern finden (entsprechend Segmenten von Studioaufnahmen anderer Songs). Dazu muss das Modell lernen, sich auf die dominante Melodie zu konzentrieren und die Hintergrundstimmen, Instrumente und das Timbre der Stimme sowie Unterschiede aufgrund von Hintergrundgeräuschen oder Nachhall zu ignorieren. Um die dominante Melodie, mit der diese beiden Spektrogramme verglichen werden können, mit dem Auge zu bestimmen, können Sie in den Zeilen unten in den obigen Bildern nach Ähnlichkeiten suchen.
Frühere Versuche, die Erkennung von Musik zu implementieren, insbesondere das Klingen in Cafés oder Clubs, haben gezeigt, wie maschinelles Lernen auf dieses Problem angewendet werden kann. Now Playing , das 2017 für Pixel-Telefone veröffentlicht wurde, verwendet ein integriertes tiefes neuronales Netzwerk, um Songs zu erkennen, ohne dass eine Serververbindung erforderlich ist, während Sound Search , das später die Technologie entwickelte, die serverbasierte Erkennung verwendet, um schnell und genau über 100 Millionen Songs zu suchen. Wir mussten auch das, was wir in diesen Veröffentlichungen gelernt hatten, anwenden, um Musik aus einer ähnlich großen Bibliothek zu erkennen, aber bereits aus den gesungenen Passagen.
Maschinelles Lernen einrichten
Der erste Schritt in der Entwicklung von Hum to Search bestand darin, die in Now Playing und Sound Search verwendeten Musikerkennungsmodelle für die Aufnahme von Melodienaufnahmen zu ändern. Im Prinzip funktionieren viele Suchmaschinen wie diese (wie die Bilderkennung) auf ähnliche Weise. Während des Trainings empfängt das neuronale Netzwerk ein Paar (eine Melodie und eine Originalaufnahme) als Eingabe und erstellt deren Einbettungen, die später zur Anpassung an die gesungene Melodie verwendet werden.

Einrichten eines neuronalen Netzwerktrainings
Um sicherzustellen, dass das, was wir singen, erkannt wird, müssen die Einbettungen von Audiopaaren mit derselben Melodie nebeneinander angeordnet werden, auch wenn sie unterschiedliche Instrumentalbegleitungen und Gesangsstimmen haben. Audiopaare mit unterschiedlichen Melodien müssen weit voneinander entfernt sein. Während des Trainings empfängt das Netzwerk solche Audiopaare, bis es lernt, wie Einbettungen mit dieser Eigenschaft erstellt werden.
Letztendlich wird das trainierte Modell in der Lage sein, Einbettungen für unsere Melodien zu generieren, ähnlich den Einbettungen von Master-Aufnahmen von Songs. In diesem Fall müssen Sie nur die Datenbank nach ähnlichen Einbettungen durchsuchen, die auf der Grundlage von Audioaufnahmen populärer Musik berechnet wurden.
Trainingsdaten
Da für das Training des Modells Paare von Liedern (aufgenommen und gesungen) erforderlich waren, bestand die erste Herausforderung darin, genügend Daten zu erhalten. Unser ursprünglicher Datensatz bestand hauptsächlich aus gesungenen Schnipsel (nur sehr wenige enthielten nur ein Summen eines Motivs ohne Worte). Um das Modell zuverlässiger zu machen, haben wir während des Trainings diese Fragmente vergrößert: Wir haben Tonhöhe und Tempo in zufälliger Reihenfolge geändert. Das resultierende Modell funktionierte gut genug für Beispiele, bei denen das Lied eher gesungen als gesummt oder gepfiffen wurde.
Um die Leistung des Modells bei wortlosen Melodien zu verbessern, haben wir aus den vorhandenen Audiodaten zusätzliche Trainingsdaten mit künstlichem „Brummen“ generiert. Dafür verwendeten wir SPICE , ein Pitch-Extraktionsmodell, das von unserem erweiterten Team im Rahmen eines Projekts entwickelt wurdeFreddieMeter . SPICE extrahiert die Tonhöhenwerte aus einem bestimmten Audio, die wir dann verwenden, um eine Melodie zu erzeugen, die aus diskreten Audiotönen besteht. Die allererste Version dieses Systems hat die ursprüngliche Passage hier in diese verwandelt .
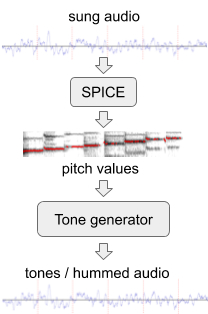
Generieren von "Brummen" aus einem gesungenen Audiofragment.
Später haben wir den Ansatz verbessert, indem wir einen einfachen Tongenerator durch ein neuronales Netzwerk ersetzt haben, das einen Klang erzeugt, der einem echten Brummen eines Motivs ohne Worte ähnelt. Zum Beispiel kann das obige Snippet in ein solches "Summen" oder Pfeifen umgewandelt werden .
Im letzten Schritt haben wir die Trainingsdaten durch Mischen und Anpassen von Audio-Snippets verglichen. Als wir zum Beispiel auf ähnliche Fragmente von zwei verschiedenen Interpreten stießen, haben wir sie an unseren vorläufigen Modellen ausgerichtet und dem Modell daher ein zusätzliches Paar Audiofragmente derselben Melodie zur Verfügung gestellt.
Das Modell verbessern
Beim Training des Hum to Search-Modells haben wir mit dem Triplettverlust begonnen , der sich bei verschiedenen Klassifizierungsaufgaben wie der Klassifizierung von Bildern und aufgenommener Musik als hervorragend erwiesen hat . Wenn ein Audiopaar angegeben wird, das mit derselben Melodie übereinstimmt (die R- und P-Punkte im unten gezeigten Einbettungsraum), ignoriert die Triplettverlustfunktion bestimmte Teile der Trainingsdaten, die von der anderen Melodie abgeleitet wurden. Dies hilft, das Lernverhalten zu verbessern, wenn das Modell eine andere Melodie findet, die zu einfach und bereits weit von R und P entfernt ist (siehe Punkt E). Und auch, wenn es für die aktuelle Phase des Modelltrainings zu komplex ist und sich als zu nahe an R herausstellt (siehe Punkt H).

Beispiele für Audiosegmente, die als Punkte im Raum gerendert werden
Wir haben festgestellt, dass wir die Genauigkeit des Modells verbessern können, indem wir zusätzliche Trainingsdaten (Punkte H und E) berücksichtigen, indem wir das allgemeine Konzept des Modellvertrauens in einer Reihe von Beispielen formulieren: Wie sicher ist das Modell, dass alle Daten, mit denen sie gearbeitet hat kann man richtig klassifizieren? Oder ist sie auf Beispiele gestoßen, die nicht ihrem gegenwärtigen Verständnis entsprechen? Auf dieser Grundlage haben wir eine Verlustfunktion hinzugefügt, die das Modellvertrauen in allen Bereichen des Einbettungsraums näher an 100% bringt, was zu einer verbesserten Speicherqualität und Genauigkeit unseres Modells führt .
Die oben genannten Änderungen, insbesondere die Kombination von Erweiterungs- und Trainingsdaten, ermöglichten es dem in der Google-Suche verwendeten neuronalen Netzwerkmodell, gesungene Melodien zu erkennen. Das aktuelle System erreicht ein hohes Maß an Genauigkeit, basierend auf einer Datenbank von über einer halben Million Songs, die wir ständig aktualisieren. Diese Sammlung von Tracks bietet Raum für Wachstum, und es wird noch mehr Musik aus der ganzen Welt geben.
Um diese Funktion zu testen, öffnen Sie die neueste Version der Google App, klicken Sie auf das Mikrofonsymbol und sagen Sie "What's this song" oder klicken Sie auf "Find a song". Jetzt können Sie eine Melodie summen oder pfeifen! Wir hoffen, dass Hum to Search Ihnen hilft, obsessive Melodien loszuwerden oder einfach einen Titel zu finden und anzuhören, ohne seinen Namen einzugeben.