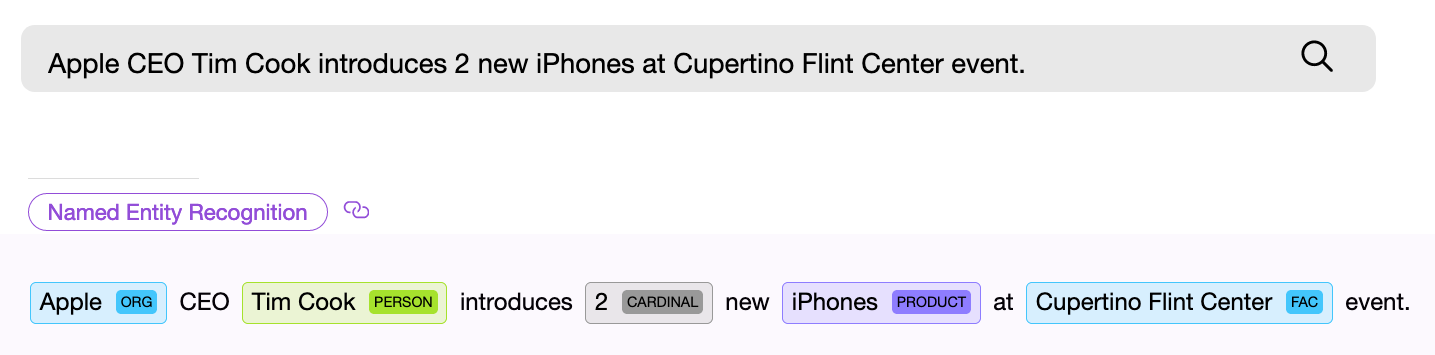
Die NER-Komponente (Named Entity Recognition), dh eine Softwarekomponente für die Suche nach benannten Entitäten, muss ein Objekt im Text finden und wenn möglich einige Informationen daraus abrufen. Beispiel - "Gib mir zweiundzwanzig Masken." Die numerische NER-Komponente findet die Phrase "zweiundzwanzig" im gegebenen Text und extrahiert aus diesen Wörtern den numerischen normalisierten Wert - " 22 ", jetzt kann dieser Wert verwendet werden.
NER-Komponenten können auf neuronalen Netzen basieren oder auf der Grundlage von Regeln und internen Modellen arbeiten. Generische NER-Komponenten verwenden häufig die zweite Methode.
Betrachten wir einige vorgefertigte Lösungen zum Auffinden von Standardentitäten im Text. In diesem Beitrag konzentrieren wir uns auf freie oder freie Bibliotheken mit Einschränkungen und sprechen darüber, was im Rahmen dieser Ausgabe im Apache NlpCraft- Projekt getan wurde . Die folgende Liste ist keine detaillierte und detaillierte Übersicht, von der es bereits eine ausreichende Anzahl im Netzwerk gibt, sondern eine kurze Beschreibung der Hauptmerkmale, Vor- und Nachteile der Verwendung dieser Bibliotheken.
NER-Komponentenanbieter
Apache OpenNlp
Apache OpenNlp bietet einen ziemlich standardmäßigen Satz von NER-Komponenten für die englische Sprache, die sich mit Datum, Uhrzeit , Geografie, Organisationen, numerischen Prozentsätzen und Personen befassen. Ein kleines Set ist auch für andere Sprachen (Spanisch, Niederländisch) erhältlich.
Lieferung:
Java-Bibliothek. Apache OpenNlp liefert keine Modelle mit dem Hauptprojekt aus. Sie können separat heruntergeladen werden.
Vorteile:
Apache-Lizenz. Modelle wurden in vielen Implementierungen getestet.
Minuspunkte:
Anscheinend wurden die Modelle aus einem bestimmten Grund aus dem Hauptprojekt entfernt. Man hat den Eindruck, dass die Arbeit an ihnen entweder eingestellt wird oder in einem bedrückend gemächlichen Tempo voranschreitet, da neue Modelle oder Änderungen an bestehenden seit geraumer Zeit nicht mehr gesehen wurden. Da Apache OpenNlp-Benutzer ihre eigenen Modelle erstellen und trainieren können, ist es möglich, dass diese Aufgabe tatsächlich vollständig ihnen überlassen bleibt.
Stanford Nlp
Stanford NLP ist ein lebendiges, sich ständig weiterentwickelndes Produkt von ausgezeichneter Qualität und vielfältigen Möglichkeiten. Für die englische Sprache wurde Unterstützung für die Erkennung der folgenden Entitäten hinzugefügt: Person, Ort, Organisation, Sonstiges, Geld, Anzahl, Ordnungszahl, Prozent, Datum, Uhrzeit, Dauer, Satz. Darüber hinaus können Sie mit der integrierten Regex NER-Komponente Entitäten wie E-Mail, URL, Stadt, Bundesstaat oder Provinz, Land, Nationalität, Religion, (Berufs-) Titel, Ideologie, Straftat, Todesursache, Handle mit hoher Genauigkeit finden. Weitere Details zum Link . Eingeschränkte NER-Unterstützung für Deutsch, Spanisch und Chinesisch wird angekündigt. Die Qualität der Erkennung kann mithilfe der Online-Demo getestet werden .
Liefern:
Java-Bibliothek. Modelle können zusammen mit dem Projekt von Mavens heruntergeladen werden.
Ich habe nirgendwo eine Auflistung und detaillierte Beschreibung der NER-Komponenten für andere Sprachen als Englisch gefunden. Links 1 , 2 - Es werden Beispiele für den Prozess des Trainings Ihrer eigenen NER-Komponenten für verschiedene Sprachen gegeben. Einfach ausgedrückt, die Möglichkeit, andere Sprachen zu verwenden, wird angekündigt, aber Sie müssen basteln.
Vorteile:
Das Gefühl, mit dem Projekt als Ganzes und mit vorgefertigten Modellen zu arbeiten, ist am positivsten, das Projekt lebt und entwickelt sich, die Erkennungsqualität ist gut („gut“ ist ein bedingtes Konzept, es gibt Metriken, die die Qualität der Erkennung von NER-Komponenten charakterisieren, aber dieses Problem geht über den Rahmen des Artikels hinaus).
Minuspunkte:
Abgesehen von etwas Chaos mit den Dokumenten sind sie klein. Für wen es wichtig ist, achten Sie auf die Lizenz. Die GNU General Public License unterscheidet sich von Apache. Sie können beispielsweise Produkte, die unter Apache usw. lizenziert sind, nicht mit einem Produkt mit dieser Lizenz versehen.
Google Sprach-API
Die Google-Sprach-API für Englisch unterstützt die folgende Liste von Entitäten: Person, Ort, Organisation, Ereignis, Kunsthandwerk, Verbrauchergut, Sonstiges, Telefonnummer, Adresse, Datum, Nummer, Preis.
Plattform:
REST-API, SaaS. Über REST sind vorgefertigte Client-Bibliotheken verfügbar (Java, C #, Python, Go usw.).
Vorteile: Der
bekannte Internetgigant bietet eine große Auswahl an NER-Komponenten, Entwicklung und Qualität.
Nachteile:
Ab bestimmten Mengen wird die Nutzung bezahlt .
Spacy
Diese Bibliothek bietet eine der breitesten Gruppen von Entitäten, die für die Erkennung unterstützt werden. Eine Liste der unterstützten Entitäten finden Sie unter dem Link .
Plattform:
Python.
Leider erlaubt mir der Mangel an persönlicher Erfahrung in der industriellen Nutzung nicht, eine echte Beschreibung der Vor- und Nachteile dieser Bibliothek hinzuzufügen. Darüber hinaus hat eine detaillierte Übersicht über Python NLP - Lösungen bereits veröffentlicht auf habr.
In allen oben genannten Bibliotheken können Sie Ihre eigenen Modelle trainieren. Alle (außer Apache OpenNlp) ermöglichen das Extrahieren normalisierter Werte aus gefundenen Entitäten, dh das Abrufen der Nummer "173" aus der numerischen Entität "einhundertdreiundsiebzig" in der Abfrage.
Wie wir sehen können, gibt es viele Möglichkeiten, das Problem der Suche nach benannten Entitäten zu lösen. Die Richtung ihrer Entwicklung ist offensichtlich. Die Liste der unterstützten Sprachen und einer Reihe anerkannter Entitäten wird erweitert, wodurch die Qualität der Erkennung verbessert wird.
Nachfolgend finden Sie eine Zusammenfassung dessen, was das Apache NlpCraft-Projekt in diesen bereits hoch entwickelten Bereich gebracht hat.
Zusätzliche Funktionen von NlpCraft
- Eigene NER-Komponenten für neue Entitäten, verbesserte Lösungen für einige bestehende.
- Integration von NER-Komponenten aller oben genannten Bibliotheken im Rahmen der Produktnutzung.
- Unterstützung für „zusammengesetzte Entitäten“, mit denen Benutzer auf einfache Weise neue benutzerdefinierte Komponenten aus vorhandenen Komponenten erstellen können.
Nun zu all dem etwas detaillierter.
Proprietäre NER-Komponenten
Die nativen NER-Komponenten von Apache NlpCraft sind Komponenten zum Erkennen von Datumsangaben, Zahlen, Geografie, Koordinaten, Sortieren und Abgleichen verschiedener Entitäten. Einige von ihnen sind einzigartig, andere sind nur eine verbesserte Implementierung bestehender Lösungen (Erkennungsgenauigkeit wurde erhöht, zusätzliche Wertfelder wurden hinzugefügt usw.).
Integration bestehender Lösungen
Alle oben genannten Lösungen sind für die Verwendung mit Apache NlpCraft integriert.
Bei der Arbeit mit einem Projekt muss der Benutzer nur das erforderliche Modul anschließen und in der Konfiguration angeben, welche NER-Komponenten bei der Suche nach Entitäten eines bestimmten Modells verwendet werden sollen.
Unten finden Sie ein Beispiel für eine Konfiguration, bei der beim Durchsuchen des Textes vier verschiedene NER-Komponenten von zwei Anbietern verwendet werden:
"enabledBuiltInTokens": [
"nlpcraft:num",
"nlpcraft:coordinate",
"google:organization",
"google:phone_number"
]
Weitere Informationen zur Verwendung von Apache NlpCraft finden Sie hier . Für die Verwendung der Google Language API ist ein gültiges Google-Entwicklerkonto erforderlich.
Unterstützung für zusammengesetzte Entitäten
Die Unterstützung für zusammengesetzte Entitäten ist die interessanteste der oben genannten Funktionen. Lassen Sie uns etwas näher darauf eingehen.
Eine zusammengesetzte Entität ist eine Entität, die auf der Grundlage einer anderen definiert wurde. Schauen wir uns ein Beispiel an. Angenommen, Sie entwickeln ein absichtsbasiertes NLP-Steuerungssystem (siehe Alexa , Google Dialogflow , Alice , Apache Nlpraft usw.), und Ihr Modell funktioniert mit der Geografie, jedoch nur für die USA. Sie können jede geografische Suchkomponente wie " nlpcraft: city " verwenden.
Wenn die Absicht ausgelöst wird, müssen Sie in der entsprechenden Funktion (Rückruf) den Wert des Felds " Land " überprüfen”, Und wenn es die erforderlichen Bedingungen nicht erfüllt, beenden Sie die Funktion, um eine falsche Auslösung zu verhindern. Als nächstes sollten Sie zum Abgleich zurückkehren und versuchen, eine andere, geeignetere Funktion auszuwählen.
Was ist falsch an diesem Ansatz:
- Sie erschweren die Arbeit mit aufgerufenen Funktionen erheblich, indem Sie die Steuerung von diesen auf den Haupt-Worker-Thread und zurück übertragen. Darüber hinaus ist zu berücksichtigen, dass nicht alle Dialogsysteme über eine solche Steuerungsübertragungsfunktion verfügen.
- Sie verwischen die Übereinstimmungslogik zwischen der Absicht und dem ausführbaren Methodencode.
Ok ... Sie können Ihre eigene NER-Komponente von Grund auf neu erstellen, um amerikanische Städte zu finden, aber diese Aufgabe ist nicht in fünf Minuten gelöst.
Lass es uns anders versuchen. Sie können die Absicht erschweren (in diesen Systemen, wo dies möglich ist) und nach Städten suchen, die zusätzlich nach Ländern gefiltert sind. Aber auch hier bieten nicht alle Systeme die Möglichkeit einer komplexen Filterung nach Feldern von Elementen. Außerdem erschweren Sie die Absichten, die so klar und einfach wie möglich sein sollten, insbesondere wenn viele davon im Projekt vorhanden sind.
Apache NlpCraft bietet einen Mechanismus zum Definieren nativer NER-Komponenten basierend auf vorhandenen. Unten finden Sie ein Konfigurationsbeispiel (die vollständige DSL-Syntax finden Sie hier , ein Beispiel zum Erstellen von Elementen finden Sie hier ):
"elements": [
{
"id": "custom:city:usa",
"description": "Wrapper for USA cities",
"synonyms": [
"^^id == 'nlpcraft:city' && lowercase(~city:country) == 'usa')^^"
]
}
]
In diesem Beispiel beschreiben wir eine neu benannte Entität "American City" - " custom: city: usa ", basierend auf dem vorhandenen " nlpcraft: city ", gefiltert nach einem bestimmten Kriterium.
Jetzt können Sie Absichten basierend auf dem erstellten neuen Element erstellen, und Städte außerhalb der USA, die im Text vorkommen, führen nicht dazu, dass Ihre Absichten unerwünscht ausgelöst werden.
Ein anderes Beispiel:
"macros": [
{
"name": "<AIRPORT>",
"macro": "{airport|aerodrome|airdrome|air station}"
}
],
"elements": [
{
"id": "custom:airport:usa",
"description": "Wrapper for USA airports",
"synonyms": [
"<AIRPORT> {of|for|*} ^^id == 'nlpcraft:city' &&
lowercase(~city:country) == 'usa')^^"
]
}
]
In diesem Beispiel haben wir eine benannte Entität "Stadtflughafen in den USA" definiert - " Brauch: Flughafen: USA ". Bei der Definition dieses Elements haben wir nicht nur die Städte nach ihrer staatlichen Zugehörigkeit gefiltert, sondern auch eine zusätzliche Regel festgelegt, nach der dem Namen der Stadt ein Synonym vorangestellt werden soll, das den Begriff „Flughafen“ definiert. (Lesen Sie mehr über Synonyme von Elementen über die Erstellung von Makros - hier ).
Zusammengesetzte Elemente können mit jedem Verschachtelungsgrad definiert werden, dh Sie können bei Bedarf neue Elemente basierend auf dem neu erstellten „ custom: Airport: USA “ entwerfen . Beachten Sie auch, dass alle normalisierten Werte der übergeordneten Entitäten, in diesem Fall das Basiselement „ nlpcraft: citySind auch im Element " custom: Airport: USA " verfügbar und können im Funktionskörper der ausgelösten Absicht verwendet werden.
Natürlich können „Bausteine“ nicht nur für alle unterstützten Standardkomponenten von OpenNlp, Stanford, Google, Spacy und NlpCraft definiert werden, sondern auch für benutzerdefinierte NER-Komponenten, um deren Funktionen zu erweitern und vorhandene Softwareentwicklungen wiederzuverwenden.
Bitte beachten Sie, dass Sie tatsächlich nicht für jede neue Aufgabe neue Komponenten erstellen, sondern diese einfach konfigurieren oder ihre Funktionalität in Ihre eigenen Elemente "mischen".
Mit „zusammengesetzten Entitäten“ kann ein Entwickler also:
- Vereinfachen Sie die Logik zum Erstellen von Absichten erheblich, indem Sie sie teilweise auf wiederverwendbare Bausteine übertragen.
- Erhalten Sie NER-Komponenten mit neuem Verhalten mithilfe von Konfigurationsänderungen ohne Modelltraining oder Codierung.
- Verwenden Sie fertige Lösungen mit der erwarteten Qualität wieder, wobei Sie sich auf vorhandene Tests oder Metriken stützen.
Fazit
Ich hoffe, dass ein kurzer Überblick über die Vor- und Nachteile vorhandener NER-Komponenten für die Leser hilfreich sein wird und das Verständnis, wie Apache NlpCraft ihre Funktionen erheblich erweitern und vorhandene Lösungen für neue Aufgaben anpassen kann, die Entwicklung Ihrer Projekte beschleunigen wird.