
Dieser Beitrag kann als Überarbeitung des Restaurierungsmaterials durch tiefes Lernen für meine Freunde oder Neulinge angesehen werden. Ich habe über 10 Beiträge geschrieben, die sich auf Ansätze zur Bildwiederherstellung mit Deep Learning beziehen. Jetzt ist die Zeit für einen schnellen Überblick über das, was die Leser dieser Artikel gelernt haben, sowie für eine kurze Einführung für Neulinge, die Spaß mit uns haben möchten.
Terminologie

Zahl: 1. Beispiel für ein beschädigtes Eingabebild (links) und Wiederherstellungsergebnis (rechts). Bild von der Github- Seite des Autors Die
in Abbildung 1 gezeigte beschädigte Eingabe identifiziert normalerweise: a) ungültige, fehlende Pixel oder Löcher als Pixel, die sich in zu füllenden Bereichen befinden; b) korrekte, verbleibende, echte Pixel, mit denen wir die fehlenden ausfüllen können. Beachten Sie, dass wir die richtigen Pixel nehmen und die entsprechenden zugehörigen Leerzeichen ausfüllen können.
Einführung
Der einfachste Weg, die fehlenden Teile auszufüllen, ist das Kopieren und Einfügen. Die Schlüsselidee besteht darin, zuerst nach den ähnlichsten Bildschnitten aus den verbleibenden Pixeln zu suchen oder sie in einem großen Datensatz mit Millionen von Bildern zu finden und dann die Schnitte direkt in die fehlenden Teile einzufügen. Der Suchalgorithmus kann jedoch zeitaufwändig sein und enthält manuell generierte Entfernungsmessmetriken. Die Verallgemeinerung des Algorithmus und seine Effizienz müssen noch verbessert werden.
Mit Deep-Learning-Ansätzen im Zeitalter von Big Data haben wir datengesteuerte Ansätze für Deep-Learning-Restaurationen. Mit diesen Ansätzen erzeugen wir Drop-Pixel mit guter Konsistenz und feinen Texturen. Werfen wir einen Blick auf 10 bekannte Deep-Learning-Ansätze zur Bildwiederherstellung. Ich bin sicher, Sie können die anderen Artikel verstehen, wenn Sie diese 10 verstehen. Lassen Sie uns anfangen.
Kontextcodierer (erster GAN-basierter Wiederherstellungsalgorithmus, 2016)

Zahl: 2. Netzwerkarchitektur des Kontextcodierers (CE).
Der Kontextcodierer (CE, 2016) [1] ist die erste Implementierung einer GAN-basierten Wiederherstellung. Diese Arbeit behandelt nützliche Grundkonzepte für Restaurierungsaufgaben. Das Konzept des "Kontexts" ist mit dem Verständnis des Bildes als solchem verbunden. Die Essenz der Encoder-Idee besteht darin, Schichten durch Kanäle vollständig zu verbinden (die mittlere Schicht des Netzwerks ist in Abbildung 2 dargestellt). Ähnlich wie bei einer vollständig verbundenen Standardebene besteht der Hauptpunkt darin, dass alle Elementpositionen auf der vorherigen Ebene zu jeder Elementposition auf der aktuellen Ebene beitragen. Das Netzwerk lernt also die Beziehung zwischen allen Anordnungen der Elemente und erhält eine tiefere semantische Darstellung des gesamten Bildes. CE wird als Basis betrachtet, mehr dazu in meinem Beitrag [ hier].
MSNPS ( )

. 3. ( CE) (VGG-19).
(MSNPS, 2016) [3] kann als erweiterte Version von CE [1] angesehen werden. Die Autoren dieses Artikels verwendeten ein modifiziertes CE, um fehlende Teile in einem Bild vorherzusagen, und ein Texturnetzwerk, um die Vorhersage zu dekorieren und die Qualität der fehlenden Teile des gefüllten Modells zu verbessern. Die Idee des Texturnetzwerks stammt aus der Aufgabe, den Stil zu übertragen. Wir wollten die ähnlichsten vorhandenen Pixel zu den generierten Pixeln formatieren, um die Details der lokalen Textur zu verbessern. Ich würde sagen, dass diese Arbeit eine frühe Version einer zweistufigen Grob-Fein-Netzwerkstruktur ist. Das erste Inhaltsnetzwerk (d. H. Hier CE) ist für die Rekonstruktion / Vorhersage der fehlenden Teile verantwortlich, und das zweite Netzwerk (d. H. Das Texturnetzwerk) ist für die Verfeinerung der gefüllten Teile verantwortlich.
Zusätzlich zu dem typischen Pixelrekonstruktionsverlust (d. H. L1-Verlust) und dem Standard-Gegnerverlust spielt das in diesem Artikel vorgeschlagene Konzept des Texturverlusts eine wichtige Rolle bei späteren Arbeiten zur Bildwiederherstellung. Tatsächlich ist Texturverlust mit Wahrnehmungsverlust und Stilverlust verbunden, die bei vielen Bilderzeugungsaufgaben wie der Übertragung neuronaler Stile weit verbreitet sind. Um mehr über diesen Artikel zu erfahren, können Sie auf meinen vorherigen Beitrag [ hier ] verweisen .
GLCIC (Meilenstein in der Wiederherstellung des tiefen Lernens, 2017)
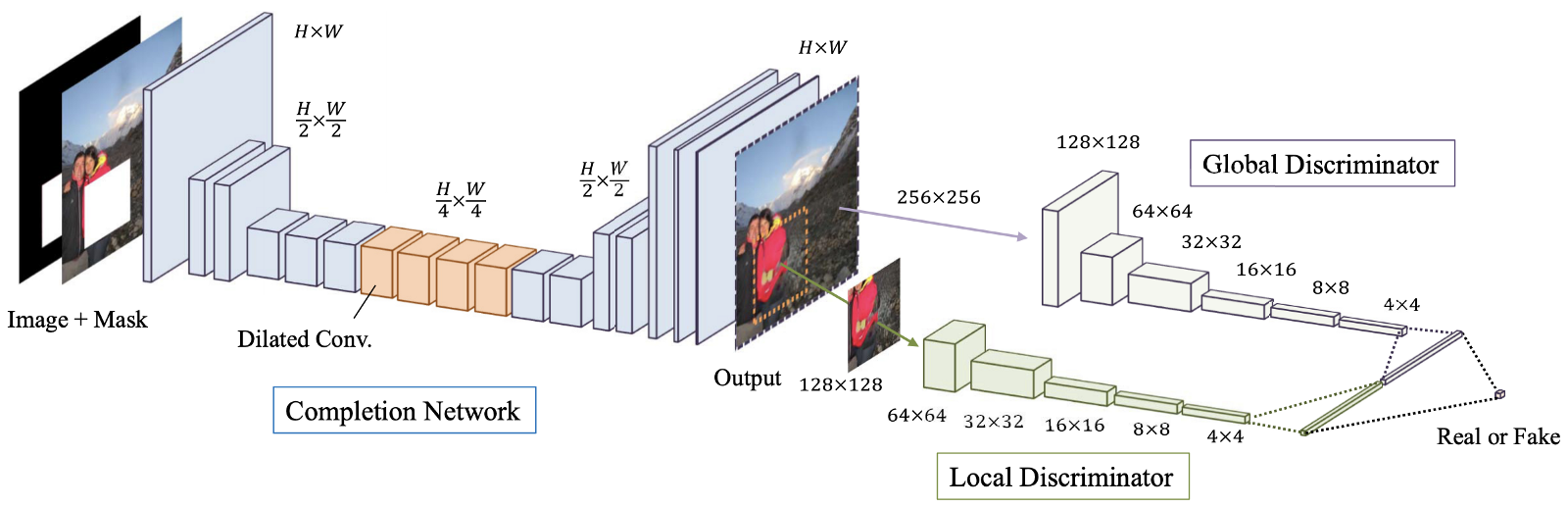
Zahl: 4. Eine Übersicht über das vorgeschlagene Modell, das aus einem Terminalnetzwerk („Generator“ -Netzwerk) sowie globalen und lokalen Diskriminatoren besteht.
Die global und lokal konsistente Bildvervollständigung (GLCIC, 2017) [4] ist ein Meilenstein bei der Wiederherstellung von Bildern mit tiefem Lernen, da sie ein vollständig gefaltetes erweitertes Faltungsnetzwerk für diesen Bereich definiert und tatsächlich eine typische Netzwerkarchitektur bei der Bildwiederherstellung darstellt. Mit erweiterten Faltungen kann das Netzwerk den Kontext eines Bildes ohne die Verwendung teurer, vollständig verbundener Schichten verstehen und daher Bilder unterschiedlicher Größe verarbeiten.
Neben dem vollständig gefalteten Netzwerk mit erweiterten Faltungen wurden auch zwei Diskriminatoren auf zwei Skalen zusammen mit dem Generatornetzwerk trainiert. Der globale Diskriminator betrachtet das gesamte Bild, während der lokale Diskriminator den gefüllten mittleren Bereich betrachtet. Sowohl mit globalen als auch mit lokalen Diskriminatoren weist das gefüllte Bild eine bessere globale und lokale Konsistenz auf. Beachten Sie, dass viele der neueren Artikel zur Bildwiederherstellung diesem Multiskalen-Diskriminator-Design folgen. Wenn Sie interessiert sind, lesen Sie bitte meinen vorherigen Beitrag [ hier ] für weitere Informationen.
GAN-Patch-basierte Wiederherstellung (GLCIC-Variante, 2018)

Zahl: 5. Vorgeschlagene generative ResNet-Architektur und PGGAN-Diskriminator.
Die Patch-basierte Wiederherstellung mit GANs [5] kann als Variante von GLCIC [4] angesehen werden. Einfach ausgedrückt sind zwei fortschrittliche Konzepte, Restlernen [6] und PatchGAN [7], in das GLCIC integriert, um die Leistung weiter zu verbessern. Die Autoren dieses Artikels haben Restverknüpfung und erweiterte Faltung kombiniert, um einen erweiterten Restblock zu bilden. Der traditionelle GAN-Diskriminator wurde durch den PatchGAN-Diskriminator ersetzt, um bessere lokale Texturdetails und globale Konsistenz zu fördern.
Der Hauptunterschied zwischen dem herkömmlichen GAN-Diskriminator und dem PatchGAN-Diskriminator besteht darin, dass der traditionelle GAN-Diskriminator nur eine Vorhersagebezeichnung (0 bis 1) gibt, um den Realismus des Eingangssignals anzuzeigen, während der PatchGAN-Diskriminator eine Matrix von Tags (ebenfalls 0 bis 1) liefert ), um den Realismus jedes lokalen Bereichs des Eingangssignals anzuzeigen. Beachten Sie, dass jedes Matrixelement einen lokalen Bereich der Eingabedaten darstellt. Sie können sich auch einen Überblick über das verbleibende Lernen und PatchGAN verschaffen [indem Sie diesen Beitrag von mir besuchen ].
Shift-Net (Deep Learning kopieren und einfügen, 2018)

Zahl: 6. Shift-Net-Netzwerkarchitektur. Die Slip-Join-Ebene wird mit einer Auflösung von 32 x 32 hinzugefügt.
Shift-Net [8] nutzt sowohl moderne datengesteuerte CNNs als auch die traditionelle "Copy and Paste" -Methode zur tiefen Neupartitionierung von Elementen unter Verwendung der vorgeschlagenen Shift-Join-Schicht. In diesem Artikel gibt es zwei Hauptideen.
Erstens haben die Autoren einen Landmarkenverlust vorgeschlagen, der dazu führt, dass die dekodierten Elemente der fehlenden Teile (angesichts des verborgenen Teils des Bildes) nahe an den codierten Elementen der fehlenden Teile liegen (angesichts des guten Zustands des Bildes). Infolgedessen kann der Decodierungsprozess die fehlenden Teile mit ihrer vernünftigen Schätzung im Bild in gutem Zustand (dh der Quelle der Wahrheit für die fehlenden Teile) ausgleichen.
Zweitens ermöglicht die vorgeschlagene Join-Shift-Schicht dem Netzwerk, Informationen, die von seinen nächsten Nachbarn außerhalb fehlender Teile bereitgestellt werden, effizient auszuleihen, um sowohl die globale semantische Struktur als auch die lokalen Texturdetails der erzeugten Teile zu verfeinern. Einfach ausgedrückt, bieten wir relevante Links, um unsere Bewertung zu verfeinern. Ich denke, dass Leser, die an Bildwiederherstellung interessiert sind, es hilfreich finden werden, die in diesem Artikel vorgeschlagenen Ideen zu konsolidieren. Ich empfehle Ihnen dringend, den vorherigen Beitrag [ hier ] für Details zu lesen .
DeepFill v1 (Breakthrough Image Restoration, 2018)

Zahl: 7. Netzwerkarchitektur des vorgeschlagenen Frameworks.
Generative Wiederherstellung mit kontextbezogener Aufmerksamkeit (CA, 2018), auch DeepFill v1 oder CA genannt [9], kann als erweiterte Version oder Variante von Shift-Net [8] angesehen werden. Die Autoren entwickeln die Idee des Kopierens und Einfügens und bieten eine Ebene kontextbezogener Aufmerksamkeit, die differenzierbar und vollständig faltungsfähig ist.
Ähnlich wie bei der Join-Shift-Schicht in [8] können wir durch Anpassen der generierten Elemente innerhalb der fehlenden Pixel und der Eigenschaften außerhalb der fehlenden Pixel den Beitrag aller Elemente außerhalb der fehlenden Pixel zu jeder Stelle innerhalb der fehlenden Pixel ermitteln. Daher kann die Kombination aller Elemente außerhalb verwendet werden, um die erzeugten Elemente innerhalb der fehlenden Pixel zu verfeinern. Im Vergleich zur Join-Shear-Schicht, die nur nach den ähnlichsten Merkmalen sucht (d. H. Einer harten, nicht differenzierbaren Zuordnung), verwendet die CA-Schicht in diesem Artikel eine weiche, differenzierbare Zuordnung, bei der alle Merkmale ihre eigenen Gewichte haben, um ihren Beitrag zu angeben jeder Ort innerhalb fehlender Pixel. Um mehr über die kontextbezogene Aufmerksamkeit zu erfahren, lesen Sie bitte meinen vorherigen Beitrag [ hier] finden Sie dort spezifischere Beispiele.
GMCNN (Mehrspaltige CNNs zur Bildwiederherstellung, 2018)

Zahl: 8. Die Architektur des vorgeschlagenen Netzwerks.
Generative Multicolumn Convolutional Neural Networks (GMCNN, 2018) [10] erweitern die Bedeutung ausreichender Empfangsfelder für die Bildwiederherstellung und bieten neue Verlustfunktionen, um die lokalen Texturdetails des generierten Inhalts weiter zu verbessern. Wie in Abbildung 9 dargestellt, gibt es drei Zweige / Spalten, und jeder Zweig verwendet drei verschiedene Filtergrößen. Die Verwendung mehrerer Empfangsfelder (Filtergrößen) beruht auf der Tatsache, dass die Größe des Empfangsfelds für die Aufgabe der Bildwiederherstellung wichtig ist. Da es keine lokalen benachbarten Pixel gibt, ist es notwendig, Informationen von räumlich entfernten Orten auszuleihen, um die lokalen fehlenden Pixel auszufüllen.
Für die vorgeschlagenen Verlustfunktionen besteht die Hauptidee hinter dem Verlust des impliziten diversifizierten Markov-Zufallsfelds (ID-MRF) darin, die generierten Element-Patches so zu steuern, dass ihre nächsten Nachbarn außerhalb der übersprungenen Bereiche als Referenzen gefunden werden, und diese nächsten Nachbarn sollten dies tun ausreichend diversifiziert sein, damit mehr lokale Texturdetails modelliert werden können. Tatsächlich ist dieser Verlust eine verbesserte Version des in MSNPS verwendeten Texturverlusts [3]. Ich empfehle Ihnen dringend, meinen Beitrag [ hier ] zu lesen, um eine detaillierte Erklärung dieses Verlusts zu erhalten.
PartialConv (verschiebt die Grenzen der Wiederherstellung durch tiefes Lernen für unregelmäßige Hohlräume, 2018)

. 9. , .
(PartialConv oder PConv) [11] erweitert die Grenzen des tiefen Lernens bei der Bildwiederherstellung, indem es eine Möglichkeit bietet, latente Bilder mit mehreren unregelmäßigen Löchern zu verarbeiten. Offensichtlich ist die Hauptidee dieses Artikels das teilweise Falten. Bei Verwendung von PConv hängen die Faltungsergebnisse nur von den zulässigen Pixeln ab, sodass wir die Kontrolle über die im Netzwerk übertragenen Informationen haben. Es ist die erste Bildwiederherstellungsarbeit, die unregelmäßige Hohlräume behebt. Beachten Sie, dass frühere Wiederherstellungsmodelle auf korrekte beschädigte Bilder trainiert wurden, sodass diese Modelle nicht für Wiederherstellungsbilder mit falschen Hohlräumen geeignet sind.
Ich habe ein einfaches Beispiel angegeben, um klar zu erklären, wie in meinem vorherigen Beitrag teilweise gefaltet wird [ hier ]. Besuchen Sie den Link für Details. Ich hoffe, dass es Ihnen gefällt.
EdgeConnect - Umrisse zuerst, dann Farben, 2019

Zahl: 10. Netzwerkarchitektur EdgeConnect. Wie Sie sehen können, gibt es zwei Generatoren und zwei Diskriminatoren.
EdgeConnect[12]: Generative Bildwiederherstellung mit Adversarial Edge Learning (EdgeConnect) [12] bietet eine interessante Möglichkeit, das Problem der Bildwiederherstellung zu lösen. Die Hauptidee dieses Artikels besteht darin, die Wiederherstellungsaufgabe in zwei vereinfachte Schritte zu unterteilen, nämlich das Vorhersagen der Kanten und das Vervollständigen des Bildes basierend auf der vorhergesagten Kantenabbildung. Die Kanten in den fehlenden Bereichen werden zuerst vorhergesagt, und dann wird das Bild gemäß der Kantenvorhersage vervollständigt. Die meisten in diesem Artikel verwendeten Methoden wurden in meinen vorherigen Beiträgen behandelt. Ein guter Blick darauf, wie verschiedene Techniken zusammen verwendet werden können, um einen neuen Ansatz für die Wiederherstellung von Bildern mit tiefem Lernen zu entwickeln. Vielleicht entwickeln Sie Ihr eigenes Restaurierungsmodell. Bitte beachten Sie meinen vorherigen Beitrag [ hier ], um mehr über diesen Artikel zu erfahren.
DeepFill v2 (Ein praktischer Ansatz zur generativen Bildwiederherstellung, 2019)

Zahl: 11. Übersicht über die Netzwerkarchitektur des Modells zur kostenlosen Wiederherstellung.
Freiformrestauration mit Gated Convolution(DeepFill v2 oder GConv, 2019) [13]. Dies ist möglicherweise der praktischste Bildwiederherstellungsalgorithmus, der direkt in Ihren Anwendungen verwendet werden kann. Es kann als erweiterte Version von DeepFill v1 [9], Partial Convolution [11] und EdgeConnect [12] betrachtet werden. Die Hauptidee der Arbeit ist Gated Convolution, eine trainierbare Version der partiellen Faltung. Durch Hinzufügen einer zusätzlichen Standardfaltungsschicht, gefolgt von einer Sigmoidfunktion, ist es möglich, die Gültigkeit jeder Pixel- / Objektposition zu kennen, und daher ist auch eine zusätzliche benutzerdefinierte Skizzeneingabe zulässig. Zusätzlich zu Gated Convolution wird SN-PatchGAN verwendet, um das Training des GAN-Modells weiter zu stabilisieren. Erfahren Sie mehr über den Unterschied zwischen Partial Convolution und Gated Convolution und wieWie sich zusätzliche Benutzerskizzeneingaben auf die Wiederherstellungsergebnisse auswirken können, lesen Sie bitte meinen letzten Beitrag [ hier ].
Fazit
Ich hoffe, Sie haben jetzt ein grundlegendes Verständnis der Bildwiederherstellung. Ich glaube, dass die meisten gängigen Techniken zur Wiederherstellung von Bildern mit tiefem Lernen in meinen vorherigen Beiträgen behandelt wurden. Wenn Sie ein alter Freund von mir sind, sind Sie jetzt in der Lage, andere Restaurierungsarbeiten mithilfe von Deep Learning zu verstehen. Wenn Sie ein Anfänger sind, würde ich Sie gerne begrüßen. Ich hoffe, Sie finden diesen Beitrag hilfreich. In der Tat gibt Ihnen dieser Beitrag die Möglichkeit, sich uns anzuschließen und gemeinsam zu lernen.
Meiner Meinung nach ist es immer noch schwierig, Bilder mit komplexen Szenenstrukturen und einer großen Anzahl fehlender Pixel wiederherzustellen (z. B. wenn 50% der Pixel fehlen). Eine weitere Herausforderung ist natürlich die Wiederherstellung hochauflösender Bilder. All diese Aufgaben können als extrem bezeichnet werden. Ich denke, dass ein Ansatz, der auf den neuesten Fortschritten bei der Restaurierung basiert, einige dieser Probleme lösen kann.
Links zu Artikeln
[1] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A. Efros, “
Context Encoders: Feature Learning by Inpainting,”
Proc. International Conference on Computer Vision and Pattern Recognition (
CVPR), 2016.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “ Generative Adversarial Nets,” in Advances in Neural Information Processing Systems ( NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “ High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition ( CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “ Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “ Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “ Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition ( CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “ Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition ( CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “ Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision ( ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “ Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition ( CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “ Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “ Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision ( ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “ EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision ( ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “ Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision ( ICCV), 2019.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “ Generative Adversarial Nets,” in Advances in Neural Information Processing Systems ( NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “ High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition ( CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “ Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “ Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “ Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition ( CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “ Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition ( CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “ Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision ( ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “ Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition ( CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “ Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “ Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision ( ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “ EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision ( ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “ Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision ( ICCV), 2019.

- Fortgeschrittenenkurs "Maschinelles Lernen Pro + Deep Learning"
- Kurs für maschinelles Lernen
- Data Science Berufsausbildung
- Data Analyst-Schulung
- Python für Webentwicklungskurs
Weitere Kurse
empfohlene Artikel
- Wie viel Data Scientist verdient: Ein Überblick über Gehälter und Jobs im Jahr 2020
- Wie viel Data Analyst verdient: Ein Überblick über Gehälter und Jobs im Jahr 2020
- So werden Sie Data Scientist ohne Online-Kurse
- 450
- Machine Learning 5 9
- Machine Learning Computer Vision
- Machine Learning Computer Vision