Ich habe lange Zeit keine Artikel geschrieben und ich denke, es ist Zeit, darüber zu schreiben, wie sich das Wissen in Datenwissenschaft, das während der Ausbildung der bekannten Spezialisierung von Yandex und MIPT "Maschinelles Lernen und Datenanalyse" gewonnen wurde, als nützlich erwiesen hat. Fairerweise sollte angemerkt werden, dass das Wissen nicht vollständig erworben wurde - die Spezialität ist noch nicht abgeschlossen :) Es ist jedoch bereits möglich, einfache reale Geschäftsprobleme zu lösen. Oder ist es notwendig? Diese Frage wird in nur wenigen Absätzen beantwortet.
Deshalb werde ich heute in diesem Artikel dem lieben Leser von meinen ersten Erfahrungen mit der Teilnahme an einem offenen Wettbewerb erzählen. Ich möchte sofort darauf hinweisen, dass mein Ziel des Wettbewerbs darin bestand, keine Preise zu erhalten. Der einzige Wunsch war, mich in der realen Welt zu versuchen :) Ja, außerdem kam es so vor, dass sich das Thema des Wettbewerbs praktisch nicht mit dem Material aus den bestandenen Kursen überschnitt. Dies fügte einige Komplikationen hinzu, aber damit wurde der Wettbewerb noch interessanter und wertvoller als die dort gewonnenen Erfahrungen.
Aus Tradition werde ich bestimmen, wer an dem Artikel interessiert sein könnte. Erstens, wenn Sie die ersten beiden Kurse der oben genannten Spezialisierung bereits abgeschlossen haben und sich an praktischen Problemen versuchen möchten, aber schüchtern und besorgt sind, dass es möglicherweise nicht funktioniert und Sie ausgelacht werden usw. Nach dem Lesen des Artikels hoffe ich, dass solche Befürchtungen zerstreut werden. Zweitens lösen Sie vielleicht ein ähnliches Problem und wissen überhaupt nicht, wo Sie eintreten sollen. Und hier ist eine fertige, unprätentiöse, wie echte Datasinterter sagen, eine Basis :)
Hier lohnt es sich, den Forschungsplan zu skizzieren, aber wir werden ein wenig abschweifen und versuchen, die Frage aus dem ersten Absatz zu beantworten - ob ein Anfänger im Datendruck bei solchen Wettbewerben versuchen muss. In diesem Punkt gehen die Meinungen auseinander. Persönlich ist meine Meinung notwendig! Lassen Sie mich erklären, warum. Es gibt viele Gründe, ich werde nicht alles auflisten, ich werde die wichtigsten angeben. Erstens tragen solche Wettbewerbe dazu bei, das theoretische Wissen in der Praxis zu festigen. Zweitens motiviert in meiner Praxis fast immer die Erfahrung, die unter kampfnahen Bedingungen gesammelt wurde, sehr stark zu weiteren Heldentaten. Drittens, und das ist das Wichtigste: Während des Wettbewerbs haben Sie die Möglichkeit, mit anderen Teilnehmern in speziellen Chats zu kommunizieren, Sie müssen nicht einmal kommunizieren, Sie können nur lesen, worüber die Leute schreiben, und dies a) führt oft zu interessanten Gedanken darüberwelche anderen Änderungen in der Studie vorgenommen werden müssen und b) Vertrauen in die Validierung ihrer eigenen Ideen gibt, insbesondere wenn sie im Chat zum Ausdruck gebracht werden. Diese Vorteile müssen mit einer gewissen Vorsicht angegangen werden, damit kein Gefühl der Allwissenheit entsteht ...
Nun ein wenig darüber, wie ich mich zur Teilnahme entschlossen habe. Ich habe wenige Tage vor dem Start von dem Wettbewerb erfahren. Der erste Gedanke lautet: "Nun, wenn ich vor einem Monat von dem Wettbewerb gewusst hätte, hätte ich mich vorbereitet, aber ich hätte einige zusätzliche Materialien studiert, die für die Durchführung der Forschung nützlich sein könnten, andernfalls könnte ich ohne Vorbereitung die Frist nicht einhalten ...", der zweite der Gedanke „eigentlich, was könnte nicht funktionieren, wenn das Ziel nicht ein Preis ist, sondern die Teilnahme, zumal die Teilnehmer in 95% der Fälle Russisch sprechen und es spezielle Chats zur Diskussion gibt, wird es eine Art Webinare von den Organisatoren geben. Am Ende wird es möglich sein, Live-Datenwissenschaftler aller Streifen und Größen zu sehen ... ". Wie Sie vermutet haben, hat der zweite Gedanke gewonnen, und er war nicht umsonst - nur ein paar Tage harte Arbeit, und ich habe eine wertvolle Erfahrung gemacht, wenn auch eine einfache.aber eine ziemliche Geschäftsaufgabe. Wenn Sie also auf dem Weg sind, die Höhen der Datenwissenschaft zu erobern und den bevorstehenden Wettbewerb zu sehen, ja in Ihrer Muttersprache, mit Unterstützung in Chats und Sie haben Freizeit - zögern Sie nicht lange - versuchen Sie und möge die Macht mit Ihnen kommen! Positiv ist zu vermerken, dass wir zum Aufgaben- und Forschungsplan übergehen.
Passende Namen
Wir werden uns nicht quälen und eine Beschreibung des Problems erstellen, aber wir werden den Originaltext von der Website des Veranstalters des Wettbewerbs geben.
Eine Aufgabe
Bei der Suche nach neuen Kunden muss SIBUR Informationen über Millionen neuer Unternehmen aus verschiedenen Quellen verarbeiten. Gleichzeitig können Firmennamen unterschiedliche Schreibweisen haben, Abkürzungen oder Fehler enthalten und mit Firmen verbunden sein, die SIBUR bereits bekannt sind.
Um Informationen über potenzielle Kunden effizienter verarbeiten zu können, muss SIBUR wissen, ob die beiden Namen verwandt sind (d. H. Zum selben Unternehmen oder zu verbundenen Unternehmen gehören).
In diesem Fall kann SIBUR bereits bekannte Informationen über das Unternehmen selbst oder über verbundene Unternehmen verwenden, um Anrufe an das Unternehmen nicht zu duplizieren oder keine Zeit mit irrelevanten Unternehmen oder Tochterunternehmen von Wettbewerbern zu verschwenden.
Das Trainingsbeispiel enthält Namenspaare aus verschiedenen Quellen (einschließlich benutzerdefinierter) und Markups.
Das Markup wurde teilweise von Hand, teilweise - algorithmisch erhalten. Darüber hinaus kann das Markup Fehler enthalten. Sie werden ein Binärmodell erstellen, das vorhersagt, ob zwei Namen zusammenhängen. Die in dieser Aufgabe verwendete Metrik ist F1.
In dieser Aufgabe können und müssen Sie offene Datenquellen verwenden, um den Datensatz anzureichern oder zusätzliche Informationen zu finden, die für die Identifizierung verbundener Unternehmen wichtig sind.
Zusätzliche Informationen zur Aufgabe
Decken Sie mich für weitere Informationen auf
, . , : , , Sibur Digital, , Sibur international GMBH , “ International GMBH” .
: , .
, , , .
(50%) (50%) .
. , , .
1 1 000 000 .
( ). , .
24:00 6 2020 # .
, , , .
, , - , .
.
, , .
10 .
API , , 2.
“” crowdsource . , :)
, .
legel entities, , .. , Industries .
. .
, . , “” .
, , , . , , .
, , .
open source , . — . .
, - – . , , - , , , .
: , .
, , , .
(50%) (50%) .
. , , .
1 1 000 000 .
( ). , .
24:00 6 2020 # .
, , , .
, , - , .
.
, , .
10 .
API , , 2.
, , , .. crowdsource
“” crowdsource . , :)
, .
legel entities, , .. , Industries .
. .
, . , “” .
, , , . , , .
, , .
open source
open source , . — . .
, - – . , , - , , , .
Daten
train.csv - Trainingsset
test.csv -
Testset sample_submission.csv - Beispiel einer Lösung im richtigen Format
Benennung von base.ipynb - Code
basis_submission.csv - Basislösung
Bitte beachten Sie, dass sich die Organisatoren des Wettbewerbs um die jüngere Generation gekümmert und eine Basislösung für das Problem veröffentlicht haben. Dies ergibt eine f1-Qualität von etwa 0,1. Dies ist das erste Mal, dass ich an Wettbewerben teilnehme und das erste Mal, dass ich das sehe :)
Nachdem wir uns mit der Aufgabe selbst und den Anforderungen für ihre Lösung vertraut gemacht haben, fahren wir mit dem Lösungsplan fort.
Problemlösungsplan
Technische Instrumente einrichten
Laden wir die Bibliotheken
. Schreiben wir Hilfsfunktionen
Datenvorverarbeitung
… -. !
50 & Drop it smart.
Berechnen wir den Levenshtein-Abstand.
Berechnen Sie den normalisierten Levenshtein-Abstand.
Visualisieren Sie die Merkmale.
Vergleichen Sie die Wörter im Text für jedes Paar und generieren Sie eine große Anzahl von Merkmalen.
Vergleichen Sie die Wörter aus dem Text mit Wörtern aus den Namen der Top 50 Holding-Marken in der Petrochemie- und Bauindustrie. Lassen Sie uns die zweite große Reihe von Funktionen erhalten. Zweiter CHIT Daten für die Einspeisung in das Modell vorbereiten
Modell einrichten und trainieren
Ergebnisse des Wettbewerbs
Informationsquellen
Nachdem wir uns mit dem Forschungsplan vertraut gemacht haben, fahren wir mit seiner Umsetzung fort.
Technische Instrumente einrichten
Laden von Bibliotheken
Eigentlich ist hier alles einfach, zuerst werden wir die fehlenden Bibliotheken installieren
Installieren Sie die Bibliothek, um die Liste der Länder zu ermitteln, und entfernen Sie sie dann aus dem Text
pip install pycountry
Installieren Sie eine Bibliothek zum Bestimmen des Levenshtein-Abstands zwischen Wörtern aus einem Text untereinander und mit Wörtern aus verschiedenen Listen
pip install strsimpy
Wir werden die Bibliothek installieren, mit deren Hilfe wir den russischen Text ins Lateinische übersetzen
pip install cyrtranslit
Bibliotheken aufrufen
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import pycountry
import re
from tqdm import tqdm
tqdm.pandas()
from strsimpy.levenshtein import Levenshtein
from strsimpy.normalized_levenshtein import NormalizedLevenshtein
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import seaborn as sns
sns.set()
sns.set_style("whitegrid")
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import StratifiedShuffleSplit
from scipy.sparse import csr_matrix
import lightgbm as lgb
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import roc_auc_score
from sklearn.metrics import classification_report, f1_score
# import googletrans
# from googletrans import Translator
import cyrtranslitSchreiben wir Hilfsfunktionen
Es wird als bewährte Methode angesehen, die Funktion in einer Zeile anzugeben, anstatt einen großen Code zu kopieren. Wir werden das fast immer tun.
Ich werde nicht behaupten, dass die Qualität des Codes in den Funktionen ausgezeichnet ist. An einigen Stellen sollte es auf jeden Fall optimiert werden, aber für eine schnelle Recherche reicht nur die Genauigkeit der Berechnungen aus.
Die erste Funktion konvertiert den Text also in Kleinbuchstaben
Der Code
# convert text to lowercase
def lower_str(data,column):
data[column] = data[column].str.lower()Die folgenden vier Funktionen helfen bei der Visualisierung des Raums der untersuchten Features und ihrer Fähigkeit, Objekte durch Zielbezeichnungen zu trennen - 0 oder 1.
Der Code
# statistic table for analyse float values (it needs to make histogramms and boxplots)
def data_statistics(data,analyse,title_print):
data0 = data[data['target']==0][analyse]
data1 = data[data['target']==1][analyse]
data_describe = pd.DataFrame()
data_describe['target_0'] = data0.describe()
data_describe['target_1'] = data1.describe()
data_describe = data_describe.T
if title_print == 'yes':
print ('\033[1m' + ' ',analyse,'\033[m')
elif title_print == 'no':
None
return data_describe
# histogramms for float values
def hist_fz(data,data_describe,analyse,size):
print ()
print ('\033[1m' + 'Information about',analyse,'\033[m')
print ()
data_0 = data[data['target'] == 0][analyse]
data_1 = data[data['target'] == 1][analyse]
min_data = data_describe['min'].min()
max_data = data_describe['max'].max()
data0_mean = data_describe.loc['target_0']['mean']
data0_median = data_describe.loc['target_0']['50%']
data0_min = data_describe.loc['target_0']['min']
data0_max = data_describe.loc['target_0']['max']
data0_count = data_describe.loc['target_0']['count']
data1_mean = data_describe.loc['target_1']['mean']
data1_median = data_describe.loc['target_1']['50%']
data1_min = data_describe.loc['target_1']['min']
data1_max = data_describe.loc['target_1']['max']
data1_count = data_describe.loc['target_1']['count']
print ('\033[4m' + 'Analyse'+ '\033[m','No duplicates')
figure(figsize=size)
sns.distplot(data_0,color='darkgreen',kde = False)
plt.scatter(data0_mean,0,s=200,marker='o',c='dimgray',label='Mean')
plt.scatter(data0_median,0,s=250,marker='|',c='black',label='Median')
plt.legend(scatterpoints=1,
loc='upper right',
ncol=3,
fontsize=16)
plt.xlim(min_data, max_data)
plt.show()
print ('Quantity:', data0_count,
' Min:', round(data0_min,2),
' Max:', round(data0_max,2),
' Mean:', round(data0_mean,2),
' Median:', round(data0_median,2))
print ()
print ('\033[4m' + 'Analyse'+ '\033[m','Duplicates')
figure(figsize=size)
sns.distplot(data_1,color='darkred',kde = False)
plt.scatter(data1_mean,0,s=200,marker='o',c='dimgray',label='Mean')
plt.scatter(data1_median,0,s=250,marker='|',c='black',label='Median')
plt.legend(scatterpoints=1,
loc='upper right',
ncol=3,
fontsize=16)
plt.xlim(min_data, max_data)
plt.show()
print ('Quantity:', data_1.count(),
' Min:', round(data1_min,2),
' Max:', round(data1_max,2),
' Mean:', round(data1_mean,2),
' Median:', round(data1_median,2))
# draw boxplot
def boxplot(data,analyse,size):
print ('\033[4m' + 'Analyse'+ '\033[m','All pairs')
data_0 = data[data['target'] == 0][analyse]
data_1 = data[data['target'] == 1][analyse]
figure(figsize=size)
sns.boxplot(x=analyse,y='target',data=data,orient='h',
showmeans=True,
meanprops={"marker":"o",
"markerfacecolor":"dimgray",
"markeredgecolor":"black",
"markersize":"14"},
palette=['palegreen', 'salmon'])
plt.ylabel('target', size=14)
plt.xlabel(analyse, size=14)
plt.show()
# draw graph for analyse two choosing features for predict traget label
def two_features(data,analyse1,analyse2,size):
fig = plt.subplots(figsize=size)
x0 = data[data['target']==0][analyse1]
y0 = data[data['target']==0][analyse2]
x1 = data[data['target']==1][analyse1]
y1 = data[data['target']==1][analyse2]
plt.scatter(x0,y0,c='green',marker='.')
plt.scatter(x1,y1,c='black',marker='+')
plt.xlabel(analyse1)
plt.ylabel(analyse2)
title = [analyse1,analyse2]
plt.title(title)
plt.show()Die fünfte Funktion dient zum Generieren einer Vermutungs- und Fehlertabelle des Algorithmus, besser bekannt als Konjugationstabelle.
Mit anderen Worten, nach der Bildung des Prognosevektors müssen wir die Prognose mit den Zielbezeichnungen vergleichen. Das Ergebnis eines solchen Vergleichs sollte eine Konjugationstabelle für jedes Unternehmenspaar aus der Trainingsstichprobe sein. In der Konjugationstabelle für jedes Paar wird das Ergebnis der Übereinstimmung der Vorhersage mit der Klasse aus der Trainingsstichprobe bestimmt. Die übereinstimmende Klassifizierung wird wie folgt akzeptiert: "Richtig positiv", "Falsch positiv", "Richtig negativ" oder "Falsch negativ". Diese Daten sind sehr wichtig, um die Funktionsweise des Algorithmus zu analysieren und Entscheidungen zur Verbesserung des Modell- und Merkmalsraums zu treffen.
Der Code
def contingency_table(X,features,probability_level,tridx,cvidx,model):
tr_predict_proba = model.predict_proba(X.iloc[tridx][features].values)
cv_predict_proba = model.predict_proba(X.iloc[cvidx][features].values)
tr_predict_target = (tr_predict_proba[:, 1] > probability_level).astype(np.int)
cv_predict_target = (cv_predict_proba[:, 1] > probability_level).astype(np.int)
X_tr = X.iloc[tridx]
X_cv = X.iloc[cvidx]
X_tr['predict_proba'] = tr_predict_proba[:,1]
X_cv['predict_proba'] = cv_predict_proba[:,1]
X_tr['predict_target'] = tr_predict_target
X_cv['predict_target'] = cv_predict_target
# make true positive column
data = pd.DataFrame(X_tr[X_tr['target']==1][X_tr['predict_target']==1]['pair_id'])
data['True_Positive'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==1][X_cv['predict_target']==1]['pair_id'])
data['True_Positive'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make false positive column
data = pd.DataFrame(X_tr[X_tr['target']==0][X_tr['predict_target']==1]['pair_id'])
data['False_Positive'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==0][X_cv['predict_target']==1]['pair_id'])
data['False_Positive'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make true negative column
data = pd.DataFrame(X_tr[X_tr['target']==0][X_tr['predict_target']==0]['pair_id'])
data['True_Negative'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==0][X_cv['predict_target']==0]['pair_id'])
data['True_Negative'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make false negative column
data = pd.DataFrame(X_tr[X_tr['target']==1][X_tr['predict_target']==0]['pair_id'])
data['False_Negative'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==1][X_cv['predict_target']==0]['pair_id'])
data['False_Negative'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
return X_tr,X_cvDie sechste Funktion dient zur Bildung der Konjugationsmatrix. Nicht zu verwechseln mit der Kupplungstabelle. Obwohl eins aus dem anderen folgt. Sie selbst werden alles weiter sehen
Der Code
def matrix_confusion(X):
list_matrix = ['True_Positive','False_Positive','True_Negative','False_Negative']
tr_pos = X[list_matrix].sum().loc['True_Positive']
f_pos = X[list_matrix].sum().loc['False_Positive']
tr_neg = X[list_matrix].sum().loc['True_Negative']
f_neg = X[list_matrix].sum().loc['False_Negative']
matrix_confusion = pd.DataFrame()
matrix_confusion['0_algorythm'] = np.array([tr_neg,f_neg]).T
matrix_confusion['1_algorythm'] = np.array([f_pos,tr_pos]).T
matrix_confusion = matrix_confusion.rename(index={0: '0_target', 1: '1_target'})
return matrix_confusionDie siebte Funktion dient zur Visualisierung des Berichts über die Funktionsweise des Algorithmus, der die Konjugationsmatrix, die Werte der Metrikgenauigkeit, Rückruf, f1 enthält
Der Code
def report_score(tr_matrix_confusion,
cv_matrix_confusion,
data,tridx,cvidx,
X_tr,X_cv):
# print some imporatant information
print ('\033[1m'+'Matrix confusion on train data'+'\033[m')
display(tr_matrix_confusion)
print ()
print(classification_report(data.iloc[tridx]["target"].values, X_tr['predict_target']))
print ('******************************************************')
print ()
print ()
print ('\033[1m'+'Matrix confusion on test(cv) data'+'\033[m')
display(cv_matrix_confusion)
print ()
print(classification_report(data.iloc[cvidx]["target"].values, X_cv['predict_target']))
print ('******************************************************')Mit der achten und neunten Funktion analysieren wir die Nützlichkeit von Merkmalen für das verwendete Modell von Light GBM im Hinblick auf den Wert des Koeffizienten 'Informationsgewinn' für jedes untersuchte Merkmal
Der Code
def table_gain_coef(model,features,start,stop):
data_gain = pd.DataFrame()
data_gain['Features'] = features
data_gain['Gain'] = model.booster_.feature_importance(importance_type='gain')
return data_gain.sort_values('Gain', ascending=False)[start:stop]
def gain_hist(df,size,start,stop):
fig, ax = plt.subplots(figsize=(size))
x = (df.sort_values('Gain', ascending=False)['Features'][start:stop])
y = (df.sort_values('Gain', ascending=False)['Gain'][start:stop])
plt.bar(x,y)
plt.xlabel('Features')
plt.ylabel('Gain')
plt.xticks(rotation=90)
plt.show()Die zehnte Funktion wird benötigt, um ein Array der Anzahl übereinstimmender Wörter für jedes Unternehmenspaar zu bilden.
Diese Funktion kann auch verwendet werden, um ein Array von NICHT übereinstimmenden Wörtern zu bilden.
Der Code
def compair_metrics(data):
duplicate_count = []
duplicate_sum = []
for i in range(len(data)):
count=len(data[i])
duplicate_count.append(count)
if count <= 0:
duplicate_sum.append(0)
elif count > 0:
temp_sum = 0
for j in range(len(data[i])):
temp_sum +=len(data[i][j])
duplicate_sum.append(temp_sum)
return duplicate_count,duplicate_sum Die elfte Funktion übersetzt den russischen Text in das lateinische Alphabet
Der Code
def transliterate(data):
text_transliterate = []
for i in range(data.shape[0]):
temp_list = list(data[i:i+1])
temp_str = ''.join(temp_list)
result = cyrtranslit.to_latin(temp_str,'ru')
text_transliterate.append(result)
.
, , , . , ,
<spoiler title="">
<source lang="python">def rename_agg_columns(id_client,data,rename):
columns = [id_client]
for lev_0 in data.columns.levels[0]:
if lev_0 != id_client:
for lev_1 in data.columns.levels[1][:-1]:
columns.append(rename % (lev_0, lev_1))
data.columns = columns
return datareturn text_transliterate Die
dreizehnten und vierzehnten Funktionen werden benötigt, um die Levenshtein-Entfernungstabelle und andere wichtige Indikatoren anzuzeigen und zu generieren.
Was für eine Tabelle ist das im Allgemeinen, welche Metriken sind darin enthalten und wie wird sie gebildet? Schauen wir uns Schritt für Schritt an, wie die Tabelle aufgebaut ist:
- Schritt 1. Definieren wir, welche Daten wir benötigen. Paar-ID, Textveredelung - Beide Spalten, Liste der Holding-Namen (Top 50 Petrochemie- und Bauunternehmen).
- Schritt 2. Messen Sie in Spalte 1 in jedem Paar aus jedem Wort den Levenshtein-Abstand zu jedem Wort aus der Liste der Namen sowie die Länge jedes Wortes und das Verhältnis von Abstand zu Länge.
- 3. , 0.4, id , .
- 4. , 0.4, .
- 5. , ID , — . id ( id ). .
- Schritt 6. Kleben Sie die resultierende Tabelle mit der Forschungstabelle.
Ein wichtiges Merkmal: Die
Berechnung dauert aufgrund des hastig geschriebenen Codes sehr lange
Der Code
def dist_name_to_top_list_view(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
words1 = []
words2 = []
top_words = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist1
df['levenstein_dist_w2_top_w'] = dist2
df['length_w1_top_w'] = len(word1)
df['length_w2_top_w'] = len(word2)
df['length_top_w'] = len(top_word)
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
display(data)
print ('Words:', word1,word2,top_word)
print ('Levenstein distance:',dist1,dist2)
print ('Length of word:',len(word1),len(word2),len(top_word))
print ('Ratio (distance/length word):',ratio1,ratio2)
def dist_name_to_top_list_make(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
dist_w1 = []
dist_w2 = []
length_w1 = []
length_w2 = []
length_top_w = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
dist_w1.append(dist1)
dist_w2.append(dist2)
length_w1.append(float(len(word1)))
length_w2.append(float(len(word2)))
length_top_w.append(float(len(top_word)))
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist_w1
df['levenstein_dist_w2_top_w'] = dist_w2
df['length_w1_top_w'] = length_w1
df['length_w2_top_w'] = length_w2
df['length_top_w'] = length_top_w
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
return dataDatenvorverarbeitung
Aus meiner kleinen Erfahrung heraus dauert die Datenvorverarbeitung im weiteren Sinne dieses Ausdrucks länger. Lass uns in Ordnung gehen.
Lade Daten
Hier ist alles sehr einfach. Laden wir die Daten und ersetzen den Namen der Spalte durch die Zielbezeichnung "is_duplicate" durch "target". Dies dient der Vereinfachung der Verwendung von Funktionen. Einige von ihnen wurden im Rahmen früherer Untersuchungen geschrieben und verwenden den Namen der Spalte mit der Zielbezeichnung als "Ziel".
Der Code
# DOWNLOAD DATA
text_train = pd.read_csv('train.csv')
text_test = pd.read_csv('test.csv')
# RENAME DATA
text_train = text_train.rename(columns={"is_duplicate": "target"})Schauen wir uns die Daten an
Die Daten wurden geladen. Mal sehen, wie viele Objekte insgesamt sind und wie ausgewogen sie sind.
Der Code
# ANALYSE BALANCE OF DATA
target_1 = text_train[text_train['target']==1]['target'].count()
target_0 = text_train[text_train['target']==0]['target'].count()
print ('There are', text_train.shape[0], 'objects')
print ('There are', target_1, 'objects with target 1')
print ('There are', target_0, 'objects with target 0')
print ('Balance is', round(100*target_1/target_0,2),'%')Tabelle №1 "Balance of Marks"

Es gibt viele Objekte - fast 500.000 und sie sind überhaupt nicht ausgeglichen. Das heißt, von fast 500.000 Objekten haben weniger als 4.000 insgesamt eine Zielbezeichnung von 1 (weniger als 1%).
Schauen wir uns die Tabelle selbst an. Schauen wir uns die ersten fünf Objekte mit der Bezeichnung 0 und die ersten fünf Objekte mit der Bezeichnung 1 an.
Der Code
display(text_train[text_train['target']==0].head(5))
display(text_train[text_train['target']==1].head(5))Tabelle Nr. 2 "Die ersten 5 Objekte der Klasse 0", Tabelle Nr. 3 "Die ersten 5 Objekte der Klasse 1"
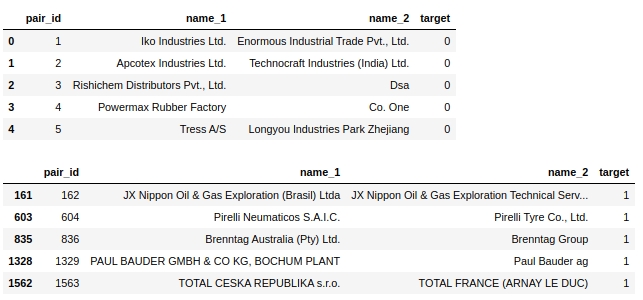
Einige einfache Schritte bieten sich sofort an: Bringen Sie den Text in ein Register, entfernen Sie alle Stoppwörter wie 'ltd', löschen Sie Länder und gleichzeitig die Namen der geografischen Objekte.
Tatsächlich kann so etwas in diesem Problem gelöst werden - Sie führen eine Vorverarbeitung durch, stellen sicher, dass es ordnungsgemäß funktioniert, führen das Modell aus, überprüfen die Qualität und analysieren selektiv die Objekte, bei denen das Modell falsch ist. So habe ich recherchiert. Aber im Artikel selbst wird die endgültige Lösung angegeben und die Qualität des Algorithmus nach jeder Vorverarbeitung wird nicht verstanden. Am Ende des Artikels werden wir eine endgültige Analyse durchführen. Andernfalls wäre der Artikel unbeschreiblich groß :)
Lassen Sie uns Kopien machen
Um ehrlich zu sein, ich weiß nicht, warum ich das mache, aber aus irgendeinem Grund mache ich es immer. Ich werde es auch dieses Mal tun
Der Code
baseline_train = text_train.copy()
baseline_test = text_test.copy()Konvertieren Sie alle Zeichen von Text in Kleinbuchstaben
Der Code
# convert text to lowercase
columns = ['name_1','name_2']
for column in columns:
lower_str(baseline_train,column)
for column in columns:
lower_str(baseline_test,column)Ländernamen entfernen
Es sei darauf hingewiesen, dass die Organisatoren des Wettbewerbs großartige Leute sind! Zusammen mit der Aufgabe gaben sie einen Laptop mit einer sehr einfachen Grundlinie, in der bereitgestellt wurde, einschließlich des folgenden Codes.
Der Code
# drop any names of countries
countries = [country.name.lower() for country in pycountry.countries]
for country in tqdm(countries):
baseline_train.replace(re.compile(country), "", inplace=True)
baseline_test.replace(re.compile(country), "", inplace=True)Zeichen und Sonderzeichen entfernen
Der Code
# drop punctuation marks
baseline_train.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_test.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_train.replace(re.compile(r"[^\w\s]"), "", inplace=True)
baseline_test.replace(re.compile(r"[^\w\s]"), "", inplace=True)Zahlen löschen
Das Entfernen der Zahlen aus dem Text direkt auf der Stirn im ersten Versuch beeinträchtigte die Qualität des Modells erheblich. Ich werde den Code hier geben, aber tatsächlich wurde er nicht verwendet.
Beachten Sie auch, dass wir bis zu diesem Punkt die Transformation direkt für die Spalten durchgeführt haben, die uns gegeben wurden. Lassen Sie uns nun für jede Vorverarbeitung neue Spalten erstellen. Es wird mehr Spalten geben, aber wenn irgendwann in einem Stadium der Vorverarbeitung ein Fehler auftritt, ist es in Ordnung, dass Sie nicht alles von Anfang an tun müssen, da wir Spalten aus jeder Phase der Vorverarbeitung haben.
Code, der die Qualität verdirbt. Sie müssen empfindlicher sein
# # first: make dictionary of frequency every word
# list_words = baseline_train['name_1'].to_string(index=False).split() +\
# baseline_train['name_2'].to_string(index=False).split()
# freq_words = {}
# for w in list_words:
# freq_words[w] = freq_words.get(w, 0) + 1
# # second: make data frame of frequency words
# df_freq = pd.DataFrame.from_dict(freq_words,orient='index').reset_index()
# df_freq.columns = ['word','frequency']
# df_freq_agg = df_freq.groupby(['word']).agg([sum]).reset_index()
# df_freq_agg = rename_agg_columns(id_client='word',data=df_freq_agg,rename='%s_%s')
# df_freq_agg = df_freq_agg.sort_values(by=['frequency_sum'], ascending=False)
# # third: make drop list of digits
# string = df_freq_agg['word'].to_string(index=False)
# digits = [int(digit) for digit in string.split() if digit.isdigit()]
# digits = set(digits)
# digits = list(digits)
# # drop the digits
# baseline_train['name_1_no_digits'] =\
# baseline_train['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_train['name_2_no_digits'] =\
# baseline_train['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_1_no_digits'] =\
# baseline_test['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_2_no_digits'] =\
# baseline_test['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))Löschen wir ... die erste Stoppwortliste. Manuell!
Nun wird vorgeschlagen, Stoppwörter in Firmennamen zu definieren und aus der Wortliste zu entfernen.
Wir haben die Liste basierend auf der manuellen Überprüfung des Trainingsmusters zusammengestellt. Logischerweise sollte eine solche Liste automatisch mit den folgenden Ansätzen erstellt werden:
- Verwenden Sie zunächst die 10 häufigsten Wörter (20,50,100).
- zweitens, um Standard-Stoppwortbibliotheken in verschiedenen Sprachen zu verwenden. Zum Beispiel Bezeichnungen von Organisations- und Rechtsformen von Organisationen in verschiedenen Sprachen (LLC, PJSC, CJSC, Ltd., Gmbh, Inc. usw.)
- drittens ist es sinnvoll, eine Liste von Ortsnamen in verschiedenen Sprachen zusammenzustellen
Wir werden auf die erste Option zurückkommen, um automatisch eine Liste der am häufigsten vorkommenden Wörter zu erstellen. Im Moment beschäftigen wir uns jedoch mit der manuellen Vorverarbeitung.
Der Code
# drop some stop-words
drop_list = ["ltd.", "co.", "inc.", "b.v.", "s.c.r.l.", "gmbh", "pvt.",
'retail','usa','asia','ceska republika','limited','tradig','llc','group',
'international','plc','retail','tire','mills','chemical','korea','brasil',
'holding','vietnam','tyre','venezuela','polska','americas','industrial','taiwan',
'europe','america','north','czech republic','retailers','retails',
'mexicana','corporation','corp','ltd','co','toronto','nederland','shanghai','gmb','pacific',
'industries','industrias',
'inc', 'ltda', '', '', '', '', '', '', '', '', 'ceska republika', 'ltda',
'sibur', 'enterprises', 'electronics', 'products', 'distribution', 'logistics', 'development',
'technologies', 'pvt', 'technologies', 'comercio', 'industria', 'trading', 'internacionais',
'bank', 'sports',
'express','east', 'west', 'south', 'north', 'factory', 'transportes', 'trade', 'banco',
'management', 'engineering', 'investments', 'enterprise', 'city', 'national', 'express', 'tech',
'auto', 'transporte', 'technology', 'and', 'central', 'american',
'logistica','global','exportacao', 'ceska republika', 'vancouver', 'deutschland',
'sro','rus','chemicals','private','distributors','tyres','industry','services','italia','beijing',
'','company','the','und']
baseline_train['name_1_non_stop_words'] =\
baseline_train['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_train['name_2_non_stop_words'] =\
baseline_train['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_1_non_stop_words'] =\
baseline_test['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_2_non_stop_words'] =\
baseline_test['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))Lassen Sie uns selektiv überprüfen, ob unsere Stoppwörter tatsächlich aus dem Text entfernt wurden.
Der Code
baseline_train[baseline_train.name_1_non_stop_words.str.contains("factory")].head(3)Tabelle 4 "Selektive Überprüfung des Codes zum Entfernen von Stoppwörtern"

Alles scheint zu funktionieren. Alle Stoppwörter, die durch ein Leerzeichen getrennt sind, wurden entfernt. Was wir wollten. Weitermachen.
Lassen Sie uns den russischen Text in das lateinische Alphabet übersetzen
Ich benutze dafür meine selbstgeschriebene Funktion und meine cyrtranslit-Bibliothek. Es scheint zu funktionieren. Manuell überprüft.
Der Code
# transliteration to latin
baseline_train['name_1_transliterated'] = transliterate(baseline_train['name_1_non_stop_words'])
baseline_train['name_2_transliterated'] = transliterate(baseline_train['name_2_non_stop_words'])
baseline_test['name_1_transliterated'] = transliterate(baseline_test['name_1_non_stop_words'])
baseline_test['name_2_transliterated'] = transliterate(baseline_test['name_2_non_stop_words'])Schauen wir uns ein Paar mit der ID 353150 an. In der zweiten Spalte ("name_2") befindet sich das Wort "Michelin". Nach der Vorverarbeitung ist das Wort bereits wie folgt geschrieben "mishlen" (siehe Spalte "name_2_transliterated"). Nicht ganz richtig, aber deutlich besser.
Der Code
pair_id = 353150
baseline_train[baseline_train['pair_id']==353150]Tabelle Nummer 5 "Selektive Überprüfung des Codes für die Transliteration"

Beginnen wir mit der automatischen Liste der 50 am häufigsten vorkommenden Wörter und lassen Sie es intelligent fallen. Erster CHIT
Ein etwas kniffliger Titel. Werfen wir einen Blick darauf, was wir hier machen werden.
Zuerst kombinieren wir den Text aus der ersten und zweiten Spalte zu einem Array und zählen für jedes eindeutige Wort, wie oft es vorkommt.
Zweitens wählen wir die Top 50 dieser Wörter aus. Und es scheint, dass Sie sie löschen können, aber nein. Diese Wörter können die Namen von Betrieben enthalten ('total', 'knauf', 'shell', ...), aber dies sind sehr wichtige Informationen und können nicht verloren gehen, da wir sie weiter verwenden werden. Deshalb werden wir einen betrügerischen (verbotenen) Trick machen. Zunächst werden wir auf der Grundlage einer sorgfältigen, selektiven Untersuchung der Ausbildungsstichprobe eine Liste der Namen häufig anzutreffender Betriebe zusammenstellen. Die Liste wird nicht vollständig sein, sonst wäre es überhaupt nicht fair :) Obwohl wir keinen Preis verfolgen, warum nicht. Dann werden wir das Array der 50 häufigsten Wörter mit der Liste der Bestandsnamen vergleichen und Wörter aus der Liste entfernen, die mit den Namen der Bestände übereinstimmen.
Die zweite Stoppwortliste ist jetzt vollständig. Sie können Wörter aus dem Text entfernen.
Aber vorher möchte ich eine kleine Bemerkung zur Betrugsliste der Holding-Namen einfügen. Die Tatsache, dass wir eine Liste der Namen von Betrieben zusammengestellt haben, die auf Beobachtungen basiert, hat unser Leben viel einfacher gemacht. Tatsächlich hätten wir eine solche Liste aber auch anders zusammenstellen können. Sie können beispielsweise die Ratings der größten Unternehmen der Petrochemie-, Bau-, Automobil- und anderen Industriezweige kombinieren, kombinieren und die Namen der Beteiligungen von dort übernehmen. Für die Zwecke unserer Forschung werden wir uns jedoch auf einen einfachen Ansatz beschränken. Dieser Ansatz ist im Wettbewerb verboten! Darüber hinaus werden die Organisatoren des Wettbewerbs, die Arbeit der Kandidaten für die Preisplätze auf verbotene Techniken überprüft. Seien Sie aufmerksam!
Der Code
list_top_companies = ['arlanxeo', 'basf', 'bayer', 'bdp', 'bosch', 'brenntag', 'contitech',
'daewoo', 'dow', 'dupont', 'evonik', 'exxon', 'exxonmobil', 'freudenberg',
'goodyear', 'goter', 'henkel', 'hp', 'hyundai', 'isover', 'itochu', 'kia', 'knauf',
'kraton', 'kumho', 'lusocopla', 'michelin', 'paul bauder', 'pirelli', 'ravago',
'rehau', 'reliance', 'sabic', 'sanyo', 'shell', 'sherwinwilliams', 'sojitz',
'soprema', 'steico', 'strabag', 'sumitomo', 'synthomer', 'synthos',
'total', 'trelleborg', 'trinseo', 'yokohama']
# drop top 50 common words (NAME 1 & NAME 2) exept names of top companies
# first: make dictionary of frequency every word
list_words = baseline_train['name_1_transliterated'].to_string(index=False).split() +\
baseline_train['name_2_transliterated'].to_string(index=False).split()
freq_words = {}
for w in list_words:
freq_words[w] = freq_words.get(w, 0) + 1
# # second: make data frame
df_freq = pd.DataFrame.from_dict(freq_words,orient='index').reset_index()
df_freq.columns = ['word','frequency']
df_freq_agg = df_freq.groupby(['word']).agg([sum]).reset_index()
df_freq_agg = rename_agg_columns(id_client='word',data=df_freq_agg,rename='%s_%s')
df_freq_agg = df_freq_agg.sort_values(by=['frequency_sum'], ascending=False)
drop_list = list(set(df_freq_agg[0:50]['word'].to_string(index=False).split()) - set(list_top_companies))
# # check list of top 50 common words
# print (drop_list)
# drop the top 50 words
baseline_train['name_1_finish'] =\
baseline_train['name_1_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_train['name_2_finish'] =\
baseline_train['name_2_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_1_finish'] =\
baseline_test['name_1_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_2_finish'] =\
baseline_test['name_2_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
Hier sind wir mit der Datenvorverarbeitung fertig. Beginnen wir mit der Generierung neuer Features und deren visueller Bewertung auf die Fähigkeit, Objekte durch 0 oder 1 zu trennen.
Feature-Generierung und -Analyse
Berechnen wir den Levenshtein-Abstand
Verwenden wir die strsimpy-Bibliothek und berechnen in jedem Paar (nach der gesamten Vorverarbeitung) den Levenshtein-Abstand vom Firmennamen aus der ersten Spalte zum Firmennamen in der zweiten Spalte.
Der Code
# create feature with LEVENSTAIN DISTANCE
levenshtein = Levenshtein()
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
baseline_train["levenstein"] = baseline_train.progress_apply(
lambda r: levenshtein.distance(r[column_1], r[column_2]), axis=1)
baseline_test["levenstein"] = baseline_test.progress_apply(
lambda r: levenshtein.distance(r[column_1], r[column_2]), axis=1)Berechnen wir den normalisierten Levenshtein-Abstand
Alles ist das gleiche wie oben, nur werden wir den normalisierten Abstand zählen.
Spoiler Header
# create feature with NORMALIZATION LEVENSTAIN DISTANCE
normalized_levenshtein = NormalizedLevenshtein()
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
baseline_train["norm_levenstein"] = baseline_train.progress_apply(
lambda r: normalized_levenshtein.distance(r[column_1], r[column_2]),axis=1)
baseline_test["norm_levenstein"] = baseline_test.progress_apply(
lambda r: normalized_levenshtein.distance(r[column_1], r[column_2]),axis=1)Wir haben gezählt und jetzt visualisieren wir
Funktionen visualisieren
Schauen wir uns die Verteilung des Merkmals 'Levenstein' an.
Der Code
data = baseline_train
analyse = 'levenstein'
size = (12,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)Grafik 1 "Histogramm und Box mit einem Schnurrbart zur Beurteilung der Bedeutung eines Merkmals"
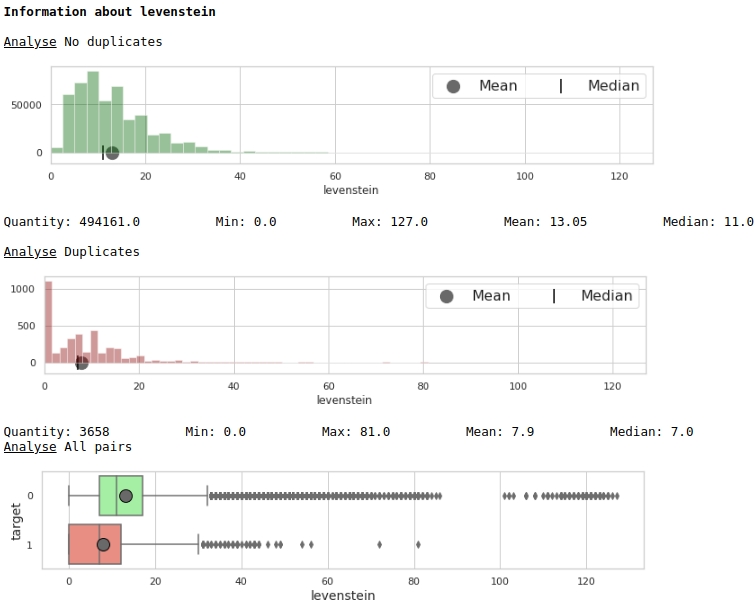
Auf den ersten Blick kann eine Metrik Daten markieren. Natürlich nicht sehr gut, aber es kann verwendet werden.
Schauen wir uns die Verteilung des Merkmals 'norm_levenstein' an.
Spoiler Header
data = baseline_train
analyse = 'norm_levenstein'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)Grafik №2 "Histogramm und Box mit Schnurrbart zur Beurteilung der Bedeutung des Zeichens"

Bereits besser. Schauen wir uns nun an, wie die beiden kombinierten Features den Raum in die Objekte 0 und 1 unterteilen.
Der Code
data = baseline_train
analyse1 = 'levenstein'
analyse2 = 'norm_levenstein'
size = (14,6)
two_features(data,analyse1,analyse2,size)Grafik Nr. 3 "Streudiagramm" Es wird ein
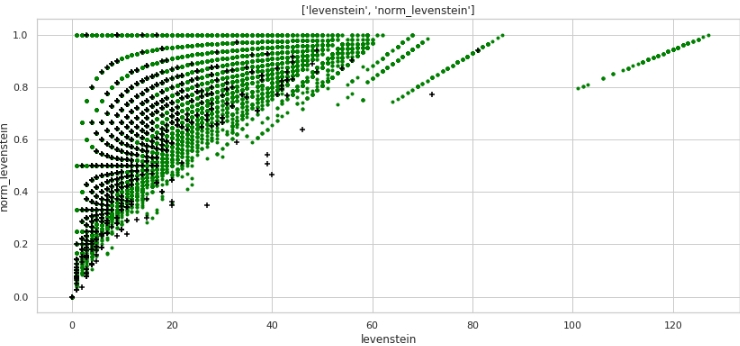
sehr gutes Markup erhalten. Es ist also nicht umsonst, dass wir die Daten so oft vorverarbeitet haben :)
Jeder versteht, dass horizontal - die Werte der Metrik "levenstein" und vertikal - die Werte der Metrik "norm_levenstein" und die grünen und schwarzen Punkte Objekte 0 und 1 sind. Fahren wir fort.
Vergleichen wir die Wörter im Text für jedes Paar und generieren eine Vielzahl von Funktionen
Nachfolgend werden wir die Wörter in Firmennamen vergleichen. Lassen Sie uns die folgenden Funktionen erstellen:
- Eine Liste von Wörtern, die in den Spalten 1 und 2 jedes Paares dupliziert werden
- eine Liste von Wörtern, die NICHT dupliziert werden
Basierend auf diesen Wortlisten erstellen wir die Funktionen, die wir in das trainierte Modell einspeisen:
- Anzahl doppelter Wörter
- Anzahl NICHT duplizierter Wörter
- Summe der Zeichen, doppelte Wörter
- Summe der Zeichen, KEINE doppelten Wörter
- durchschnittliche Länge doppelter Wörter
- durchschnittliche Länge von NICHT duplizierten Wörtern
- das Verhältnis der Anzahl der Duplikate zur Anzahl der NICHT-Duplikate
Der Code hier ist wahrscheinlich nicht sehr freundlich, da er wieder in Eile geschrieben wurde. Aber es funktioniert, aber es wird für eine schnelle Forschung gehen.
Der Code
# make some information about duplicates and differences for TRAIN
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
duplicates = []
difference = []
for i in range(baseline_train.shape[0]):
list1 = list(baseline_train[i:i+1][column_1])
str1 = ''.join(list1).split()
list2 = list(baseline_train[i:i+1][column_2])
str2 = ''.join(list2).split()
duplicates.append(list(set(str1) & set(str2)))
difference.append(list(set(str1).symmetric_difference(set(str2))))
# continue make information about duplicates
duplicate_count,duplicate_sum = compair_metrics(duplicates)
dif_count,dif_sum = compair_metrics(difference)
# create features have information about duplicates and differences for TRAIN
baseline_train['duplicate'] = duplicates
baseline_train['difference'] = difference
baseline_train['duplicate_count'] = duplicate_count
baseline_train['duplicate_sum'] = duplicate_sum
baseline_train['duplicate_mean'] = baseline_train['duplicate_sum'] / baseline_train['duplicate_count']
baseline_train['duplicate_mean'] = baseline_train['duplicate_mean'].fillna(0)
baseline_train['dif_count'] = dif_count
baseline_train['dif_sum'] = dif_sum
baseline_train['dif_mean'] = baseline_train['dif_sum'] / baseline_train['dif_count']
baseline_train['dif_mean'] = baseline_train['dif_mean'].fillna(0)
baseline_train['ratio_duplicate/dif_count'] = baseline_train['duplicate_count'] / baseline_train['dif_count']
# make some information about duplicates and differences for TEST
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
duplicates = []
difference = []
for i in range(baseline_test.shape[0]):
list1 = list(baseline_test[i:i+1][column_1])
str1 = ''.join(list1).split()
list2 = list(baseline_test[i:i+1][column_2])
str2 = ''.join(list2).split()
duplicates.append(list(set(str1) & set(str2)))
difference.append(list(set(str1).symmetric_difference(set(str2))))
# continue make information about duplicates
duplicate_count,duplicate_sum = compair_metrics(duplicates)
dif_count,dif_sum = compair_metrics(difference)
# create features have information about duplicates and differences for TEST
baseline_test['duplicate'] = duplicates
baseline_test['difference'] = difference
baseline_test['duplicate_count'] = duplicate_count
baseline_test['duplicate_sum'] = duplicate_sum
baseline_test['duplicate_mean'] = baseline_test['duplicate_sum'] / baseline_test['duplicate_count']
baseline_test['duplicate_mean'] = baseline_test['duplicate_mean'].fillna(0)
baseline_test['dif_count'] = dif_count
baseline_test['dif_sum'] = dif_sum
baseline_test['dif_mean'] = baseline_test['dif_sum'] / baseline_test['dif_count']
baseline_test['dif_mean'] = baseline_test['dif_mean'].fillna(0)
baseline_test['ratio_duplicate/dif_count'] = baseline_test['duplicate_count'] / baseline_test['dif_count']
Wir visualisieren einige der Zeichen.
Der Code
data = baseline_train
analyse = 'dif_sum'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)Grafik Nr. 4 "Histogramm und eine Box mit einem Schnurrbart zur Beurteilung der Bedeutung des Zeichens"
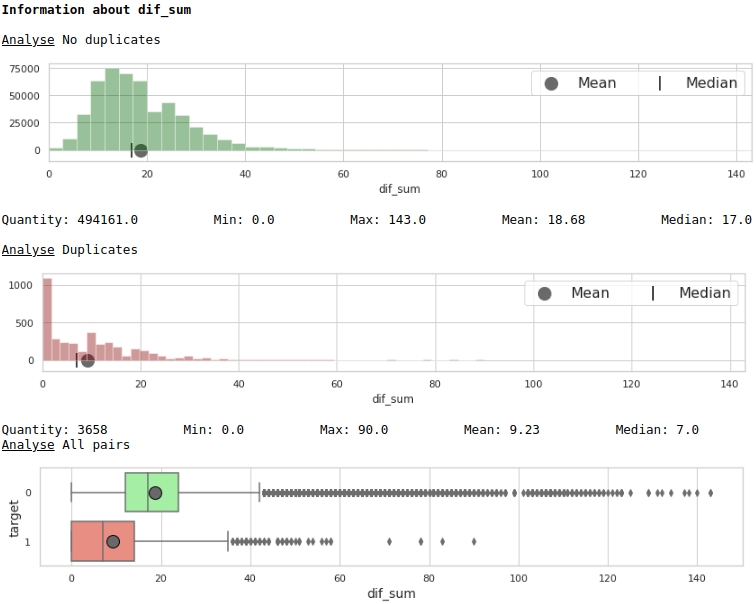
Der Code
data = baseline_train
analyse1 = 'duplicate_mean'
analyse2 = 'dif_mean'
size = (14,6)
two_features(data,analyse1,analyse2,size)Grafik №5 "Streudiagramm"
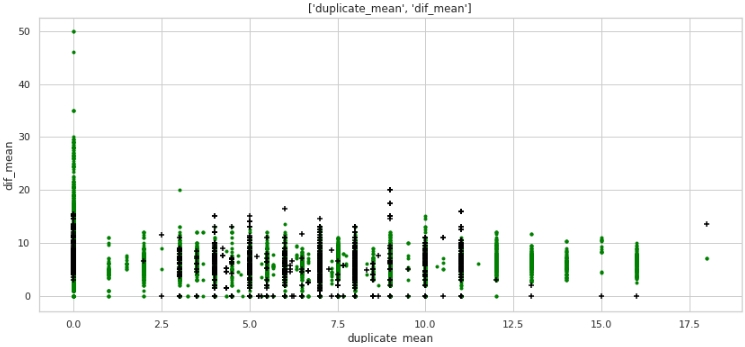
Was nein, aber das Markup. Beachten Sie, dass viele Unternehmen mit einer Zielbezeichnung von 1 keine Duplikate im Text haben und auch viele Unternehmen mit Duplikaten in ihren Namen, durchschnittlich mehr als 12 Wörtern, zu Unternehmen mit einer Zielbezeichnung von 0 gehören.
Schauen wir uns die tabellarischen Daten an und bereiten Sie eine Abfrage vor Im ersten Fall: Der Name der Unternehmen enthält keine Duplikate, aber die Unternehmen sind gleich.
Der Code
baseline_train[
baseline_train['duplicate_mean']==0][
baseline_train['target']==1].drop(
['duplicate', 'difference',
'name_1_non_stop_words',
'name_2_non_stop_words', 'name_1_transliterated',
'name_2_transliterated'],axis=1)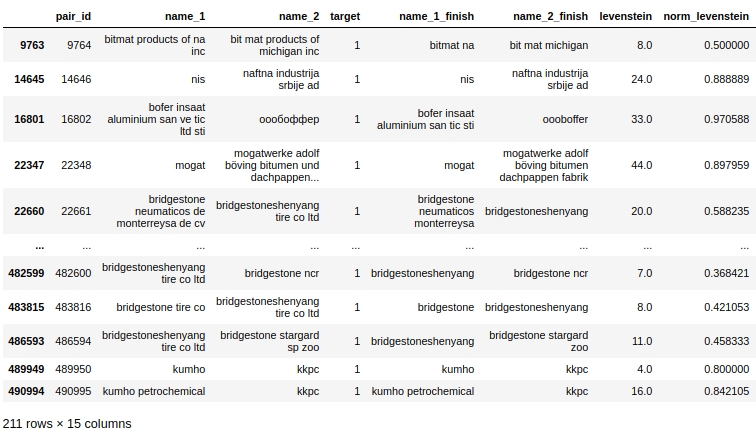
Offensichtlich liegt ein Systemfehler in unserer Verarbeitung vor. Wir haben nicht berücksichtigt, dass Wörter nicht nur fehlerhaft geschrieben werden können, sondern auch einfach zusammen oder im Gegenteil getrennt, wenn dies nicht erforderlich ist. Zum Beispiel Paar # 9764. In der ersten Spalte 'Bitmatte' in der zweiten 'Bitmatte' und jetzt ist dies kein Doppel, aber das Unternehmen ist das gleiche. Oder ein anderes Beispiel, Paar # 482600 'Bridgestoneshenyang' und 'Bridgestone'.
Was könnte getan werden. Das erste, was mir einfiel, war, nicht direkt auf der Stirn zu vergleichen, sondern die Levenshtein-Metrik zu verwenden. Aber auch hier erwartet uns ein Hinterhalt: Der Abstand zwischen 'Bridgestoneshenyang' und 'Bridgestone' wird nicht gering sein. Vielleicht hilft die Lemmatisierung, aber auch hier ist nicht sofort klar, wie die Namen von Unternehmen lemmatisiert werden können. Oder Sie können den Tamimoto-Koeffizienten verwenden, aber lassen Sie diesen Moment für erfahrene Kameraden und fahren Sie fort.
Vergleichen wir Wörter aus dem Text mit Wörtern aus den Namen der Top 50 Holding-Marken in der Petrochemie, im Baugewerbe und in anderen Branchen. Lassen Sie uns die zweite große Reihe von Funktionen erhalten. Zweiter CHIT
Tatsächlich gibt es zwei Verstöße gegen die Regeln für die Teilnahme am Wettbewerb:
- -, , «duplicate_name_company»
- -, . , .
Beide Techniken sind nach den Wettbewerbsregeln verboten. Sie können das Verbot umgehen. Dazu müssen Sie eine Liste mit Namen erstellen, die nicht manuell auf der Grundlage einer selektiven Ansicht des Trainingsbeispiels, sondern automatisch - aus externen Quellen - erstellt wird. Aber erstens wird sich die Liste der Bestände als umfangreich herausstellen und der Vergleich der in der Arbeit vorgeschlagenen Wörter wird sehr, sehr viel Zeit in Anspruch nehmen, und zweitens muss diese Liste noch zusammengestellt werden :) Aus Gründen der Einfachheit der Recherche werden wir daher prüfen, um wie viel sich die Qualität des Modells verbessern wird diese Zeichen. Mit Blick auf die Zukunft wächst die Qualität einfach unglaublich!
Bei der ersten Methode scheint alles klar zu sein, aber der zweite Ansatz erfordert Erklärungen.
Bestimmen wir also den Levenshtein-Abstand von jedem Wort in jeder Zeile der ersten Spalte mit dem Firmennamen zu jedem Wort aus der Liste der besten petrochemischen Unternehmen (und nicht nur).
Wenn das Verhältnis der Levenshtein-Entfernung zur Wortlänge kleiner oder gleich 0,4 ist, bestimmen wir das Verhältnis der Levenshtein-Entfernung zum ausgewählten Wort aus der Liste der Top-Unternehmen zu jedem Wort aus der zweiten Spalte - dem Namen der zweiten Firma.
Wenn der zweite Koeffizient (das Verhältnis von Abstand zu Wortlänge aus der Liste der Top-Unternehmen) kleiner oder gleich 0,4 ist, legen wir die folgenden Werte in der Tabelle fest:
- Levenshtein Abstand von einem Wort aus der Liste der Nr. 1 Unternehmen zu einem Wort in der Liste der Top-Unternehmen
- Levenshtein Abstand von einem Wort aus der Liste der Nr. 2 Unternehmen zu einem Wort in der Liste der Top-Unternehmen
- Länge eines Wortes aus Liste 1
- Länge eines Wortes aus Liste 2
- Wortlänge aus der Liste der Top-Unternehmen
- das Verhältnis der Länge eines Wortes aus der Liste Nr. 1 zur Entfernung
- das Verhältnis der Länge eines Wortes aus Liste Nr. 2 zur Entfernung
Es kann mehr als eine Übereinstimmung in einer Zeile geben. Wählen wir das Minimum aus (Aggregationsfunktion).
Ich möchte noch einmal Ihre Aufmerksamkeit auf die Tatsache lenken, dass die vorgeschlagene Methode zum Generieren von Features sehr ressourcenintensiv ist und im Falle des Abrufs einer Liste von einer externen Quelle eine Änderung des Codes zum Kompilieren von Metriken erforderlich ist.
Der Code
# create information about duplicate name of petrochemical companies from top list
list_top_companies = list_top_companies
dp_train = []
for i in list(baseline_train['duplicate']):
dp_train.append(''.join(list(set(i) & set(list_top_companies))))
dp_test = []
for i in list(baseline_test['duplicate']):
dp_test.append(''.join(list(set(i) & set(list_top_companies))))
baseline_train['duplicate_name_company'] = dp_train
baseline_test['duplicate_name_company'] = dp_test
# replace name duplicate to number
baseline_train['duplicate_name_company'] =\
baseline_train['duplicate_name_company'].replace('',0,regex=True)
baseline_train.loc[baseline_train['duplicate_name_company'] != 0, 'duplicate_name_company'] = 1
baseline_test['duplicate_name_company'] =\
baseline_test['duplicate_name_company'].replace('',0,regex=True)
baseline_test.loc[baseline_test['duplicate_name_company'] != 0, 'duplicate_name_company'] = 1
# create some important feature about similar words in the data and names of top companies for TRAIN
# (levenstein distance, length of word, ratio distance to length)
baseline_train = dist_name_to_top_list_make(baseline_train,
'name_1_finish','name_2_finish',list_top_companies)
# create some important feature about similar words in the data and names of top companies for TEST
# (levenstein distance, length of word, ratio distance to length)
baseline_test = dist_name_to_top_list_make(baseline_test,
'name_1_finish','name_2_finish',list_top_companies)
Lassen Sie uns die Nützlichkeit von Funktionen anhand des Prismas von Diagrammen betrachten
Der Code
data = baseline_train
analyse = 'levenstein_dist_w1_top_w_min'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)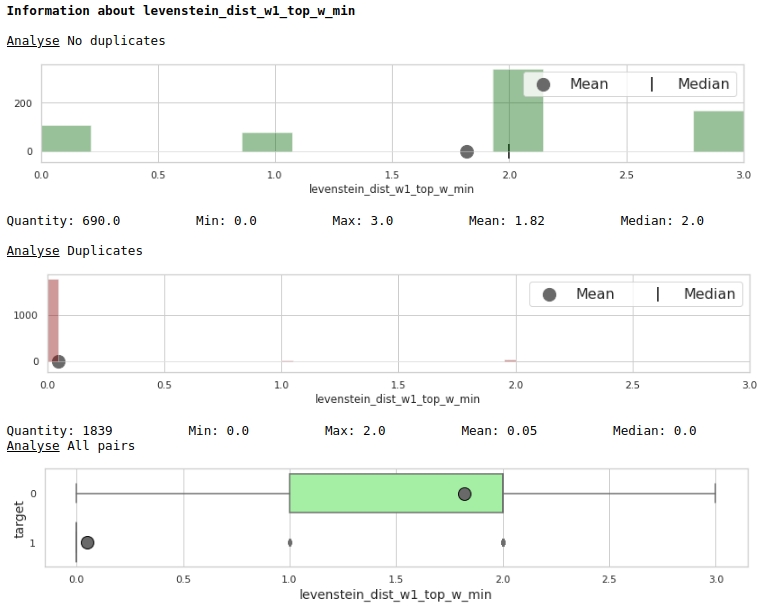
Sehr gut.
Vorbereiten der Daten für die Übermittlung an das Modell
Wir haben eine große Tabelle und benötigen nicht alle Daten für die Analyse. Schauen wir uns die Namen der Tabellenspalten an.
Der Code
baseline_train.columns
Wählen wir die Spalten aus, die wir analysieren möchten.
Lassen Sie uns den Keim für die Reproduzierbarkeit des Ergebnisses festlegen.
Der Code
# fix some parameters
features = ['levenstein','norm_levenstein',
'duplicate_count','duplicate_sum','duplicate_mean',
'dif_count','dif_sum','dif_mean','ratio_duplicate/dif_count',
'duplicate_name_company',
'levenstein_dist_w1_top_w_min', 'levenstein_dist_w2_top_w_min',
'length_w1_top_w_min', 'length_w2_top_w_min', 'length_top_w_min',
'ratio_dist_w1_to_top_w_min', 'ratio_dist_w2_to_top_w_min'
]
seed = 42Bevor Sie das Modell endgültig auf alle verfügbaren Daten trainieren und die Lösung zur Überprüfung senden, ist es sinnvoll, das Modell zu testen. Dazu teilen wir den Trainingssatz in bedingtes Training und bedingten Test auf. Wir werden die Qualität daran messen und wenn es uns passt, werden wir die Lösung an die Konkurrenz senden.
Der Code
# provides train/test indices to split data in train/test sets
split = StratifiedShuffleSplit(n_splits=1, train_size=0.8, random_state=seed)
tridx, cvidx = list(split.split(baseline_train[features],
baseline_train["target"]))[0]
print ('Split baseline data train',baseline_train.shape[0])
print (' - new train data:',tridx.shape[0])
print (' - new test data:',cvidx.shape[0])Modell einrichten und trainieren
Wir werden den Entscheidungsbaum aus der Light GBM-Bibliothek als Modell verwenden.
Es macht keinen Sinn, die Parameter zu stark aufzuziehen. Wir schauen uns den Code an.
Der Code
# learning Light GBM Classificier
seed = 50
params = {'n_estimators': 1,
'objective': 'binary',
'max_depth': 40,
'min_child_samples': 5,
'learning_rate': 1,
# 'reg_lambda': 0.75,
# 'subsample': 0.75,
# 'colsample_bytree': 0.4,
# 'min_split_gain': 0.02,
# 'min_child_weight': 40,
'random_state': seed}
model = lgb.LGBMClassifier(**params)
model.fit(baseline_train.iloc[tridx][features].values,
baseline_train.iloc[tridx]["target"].values)Das Modell wurde abgestimmt und trainiert. Schauen wir uns nun die Ergebnisse an.
Der Code
# make predict proba and predict target
probability_level = 0.99
X = baseline_train
tridx = tridx
cvidx = cvidx
model = model
X_tr, X_cv = contingency_table(X,features,probability_level,tridx,cvidx,model)
train_matrix_confusion = matrix_confusion(X_tr)
cv_matrix_confusion = matrix_confusion(X_cv)
report_score(train_matrix_confusion,
cv_matrix_confusion,
baseline_train,
tridx,cvidx,
X_tr,X_cv)
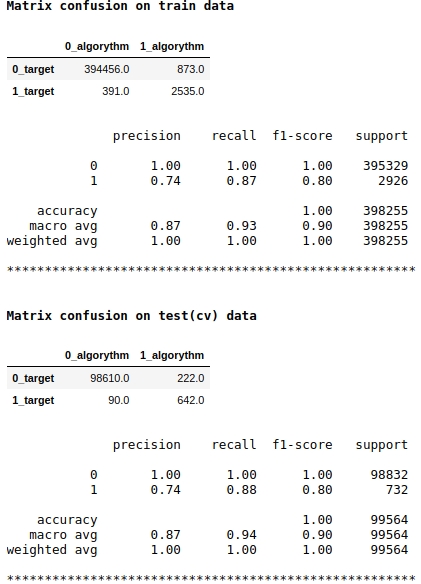
Beachten Sie, dass wir die f1-Qualitätsmetrik als Modellbewertung verwenden. Dies bedeutet, dass es sinnvoll ist, die Wahrscheinlichkeit der Zuordnung eines Objekts zur Klasse 1 oder 0 zu regeln. Wir haben die Stufe 0,99 gewählt. Wenn die Wahrscheinlichkeit gleich oder höher als 0,99 ist, wird das Objekt der Klasse 1 unter 0,99 - der Klasse 0 zugeordnet. Dies ist ein wichtiger Punkt - Sie können die Geschwindigkeit erheblich verbessern so ein kniffliger einfacher Trick.
Die Qualität scheint nicht schlecht zu sein. Bei einer bedingten Testprobe machte der Algorithmus Fehler bei der Definition von 222 Objekten der Klasse 0 und bei 90 Objekten der Klasse 0 machte er einen Fehler und ordnete sie der Klasse 1 zu (siehe Matrixverwirrung bei Testdaten (cv)).
Mal sehen, welche Zeichen am wichtigsten waren und welche nicht.
Der Code
start = 0
stop = 50
size = (12,6)
tg = table_gain_coef(model,features,start,stop)
gain_hist(tg,size,start,stop)
display(tg)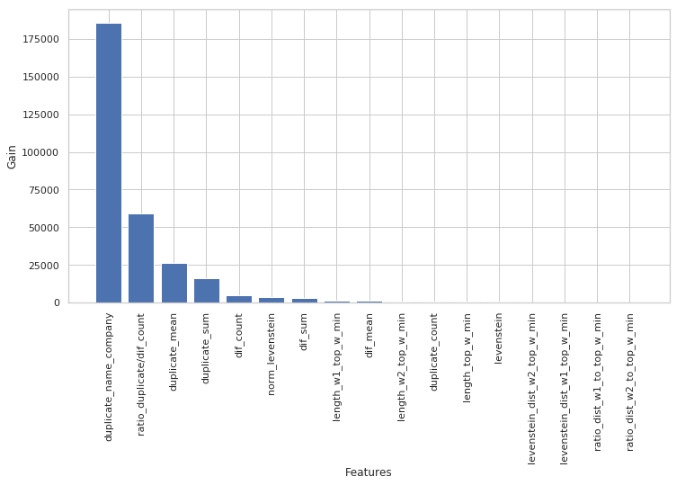
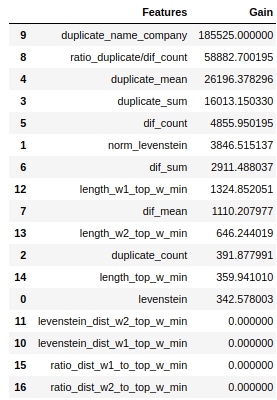
Beachten Sie, dass wir den Parameter 'Gain' und nicht den Parameter 'Split' verwendet haben, um die Signifikanz der Features zu bewerten. Dies ist wichtig, da in einer sehr vereinfachten Version der erste Parameter den Beitrag des Merkmals zur Abnahme der Entropie bedeutet und der zweite angibt, wie oft das Merkmal zum Markieren des Raums verwendet wurde.
Auf den ersten Blick erwies sich das Feature "levenstein_dist_w1_top_w_min", das wir schon sehr lange machen, als überhaupt nicht informativ - sein Beitrag ist 0. Dies ist jedoch nur auf den ersten Blick der Fall. Die Bedeutung wird mit dem Attribut "duplicate_name_company" fast vollständig dupliziert. Wenn Sie "duplicate_name_company" löschen und "levenstein_dist_w1_top_w_min" belassen, ersetzt das zweite Feature das erste und die Qualität ändert sich nicht. Überprüft!
Im Allgemeinen ist ein solches Zeichen eine praktische Sache, insbesondere wenn Sie Hunderte von Funktionen und ein Modell mit einer Reihe von Schnickschnack und 5000 Iterationen haben. Sie können Funktionen in Stapeln entfernen und beobachten, wie die Qualität durch diese nicht gerissene Aktion wächst. In unserem Fall hat das Entfernen von Features keinen Einfluss auf die Qualität.
Werfen wir einen Blick auf den Mate-Tisch. Schauen wir uns zunächst die Objekte "False Positive" an, dh diejenigen, die unser Algorithmus als gleich bestimmt und der Klasse 1 zugeordnet hat, die aber tatsächlich zur Klasse 0 gehören.
Der Code
X_cv[X_cv['False_Positive']==1][0:50].drop(['name_1_non_stop_words',
'name_2_non_stop_words', 'name_1_transliterated',
'name_2_transliterated', 'duplicate', 'difference',
'levenstein',
'levenstein_dist_w1_top_w_min', 'levenstein_dist_w2_top_w_min',
'length_w1_top_w_min', 'length_w2_top_w_min', 'length_top_w_min',
'ratio_dist_w1_to_top_w_min', 'ratio_dist_w2_to_top_w_min',
'True_Positive','True_Negative','False_Negative'],axis=1)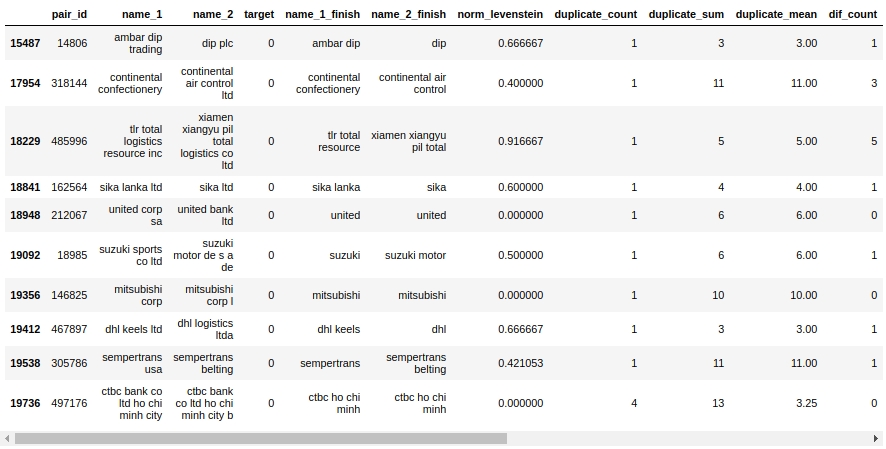
Ja. Hier bestimmt eine Person nicht sofort 0 oder 1. Beispiel: Paar # 146825 "Mitsubishi Corp" und "Mitsubishi Corp I". Die Augen sagen, dass es dasselbe ist, aber die Stichprobe sagt, dass es sich um verschiedene Unternehmen handelt. Wen soll man glauben?
Sagen wir einfach, Sie könnten sich sofort herausdrücken - wir haben uns herausgedrückt. Wir werden den Rest der Arbeit erfahrenen Kameraden überlassen :) Laden
wir die Daten auf die Website des Veranstalters hoch und finden Sie heraus, wie die Qualität der Arbeit bewertet wird.
Ergebnisse des Wettbewerbs
Der Code
model = lgb.LGBMClassifier(**params)
model.fit(baseline_train[features].values,
baseline_train["target"].values)
sample_sub = pd.read_csv('sample_submission.csv', index_col="pair_id")
sample_sub['is_duplicate'] = (model.predict_proba(
baseline_test[features].values)[:, 1] > probability_level).astype(np.int)
sample_sub.to_csv('baseline_submission.csv')
Also unsere Geschwindigkeit unter Berücksichtigung der verbotenen Methode: 0,5999
Ohne sie lag die Qualität irgendwo zwischen 0,3 und 0,4. Wir müssen das Modell neu starten, um die Genauigkeit zu gewährleisten, aber ich bin etwas zu faul :) Fassen
wir die gesammelten Erfahrungen besser zusammen.
Erstens haben wir, wie Sie sehen können, einen ziemlich reproduzierbaren Code und eine ziemlich angemessene Dateistruktur. Aufgrund meiner geringen Erfahrung habe ich einmal viele Unebenheiten gefüllt, gerade weil ich die Arbeit in Eile erledigt habe, nur um mehr oder weniger angenehme Geschwindigkeit zu erreichen. Infolgedessen stellte sich heraus, dass die Datei bereits nach einer Woche unheimlich war, sie zu öffnen - nichts ist so klar. Daher lautet meine Botschaft, den Code sofort zu schreiben und die Datei lesbar zu machen, damit Sie in einem Jahr zu den Daten zurückkehren, zuerst die Struktur betrachten, verstehen, welche Schritte unternommen wurden, und dann jeden Schritt leicht zerlegen können. Wenn Sie ein Anfänger sind, wird die Datei beim ersten Versuch natürlich nicht schön sein, der Code wird kaputt gehen, es wird Krücken geben, aber wenn Sie den Code während des Forschungsprozesses regelmäßig neu schreiben,Wenn Sie dann 5-7 Mal umschreiben, werden Sie selbst überrascht sein, wie sauberer der Code ist, und vielleicht sogar Fehler finden und die Geschwindigkeit verbessern. Vergessen Sie nicht die Funktionen, es macht die Datei sehr einfach zu lesen.
Zweitens überprüfen Sie nach jeder Verarbeitung der Daten, ob alles wie geplant verlaufen ist. Dazu müssen Sie in der Lage sein, Tabellen in Pandas zu filtern. Es gibt viel Filterung in dieser Arbeit, benutze sie für die Gesundheit :)
Drittens bilden immer, geradezu immer, bei Klassifizierungsaufgaben sowohl eine Tabelle als auch eine Konjugationsmatrix. Aus der Tabelle können Sie leicht herausfinden, bei welchen Objekten der Algorithmus falsch ist. Versuchen Sie zunächst, die Fehler zu bemerken, die als Systemfehler bezeichnet werden. Die Behebung erfordert weniger Arbeit und führt zu mehr Ergebnissen. Sobald Sie die Systemfehler behoben haben, gehen Sie zu Sonderfällen. Anhand der Fehlermatrix sehen Sie, wo der Algorithmus mehr Fehler macht: in Klasse 0 oder 1. Von hier aus werden Sie Fehler ausgraben. Zum Beispiel habe ich festgestellt, dass mein Baum die Klassen 1 gut definiert, aber viele Fehler in der Klasse 0 macht, dh der Baum "sagt" oft, dass dieses Objekt der Klasse 1 angehört, obwohl es tatsächlich 0 ist. Ich nahm an, dass dies der Fall sein könnte verbunden mit der Wahrscheinlichkeit, ein Objekt als 0 oder 1 zu klassifizieren. Meine Stufe wurde auf 0,9 festgelegt.Eine Erhöhung der Wahrscheinlichkeit, ein Objekt der Klasse 1 zuzuordnen, auf 0,99 machte die Auswahl von Objekten der Klasse 1 schwieriger und voila - unsere Geschwindigkeit hat erheblich zugenommen.
Ich werde noch einmal darauf hinweisen, dass der Zweck der Teilnahme am Wettbewerb nicht darin bestand, einen Preis zu gewinnen, sondern Erfahrungen zu sammeln. In Anbetracht dessen, dass ich vor Beginn des Wettbewerbs keine Ahnung hatte, wie ich mit Texten im maschinellen Lernen arbeiten soll, und am Ende in wenigen Tagen ein einfaches, aber immer noch funktionierendes Modell bekam, können wir sagen, dass das Ziel erreicht wurde. Für jeden Samurai-Neuling in der Welt der Datenwissenschaft ist es meiner Meinung nach wichtig, Erfahrung zu sammeln, nicht einen Preis, oder vielmehr, Erfahrung ist der Preis. Hab also keine Angst, an Wettbewerben teilzunehmen, mach mit, jeder ist ein Biber!
Zum Zeitpunkt der Veröffentlichung des Artikels ist der Wettbewerb noch nicht beendet. Basierend auf den Ergebnissen des Abschlusses des Wettbewerbs werde ich in den Kommentaren zum Artikel über die maximale faire Geschwindigkeit, über die Ansätze und Merkmale schreiben, die die Qualität des Modells verbessern.
Und Sie sind ein lieber Leser, wenn Sie Ideen haben, wie Sie die Geschwindigkeit jetzt erhöhen können, schreiben Sie in die Kommentare. Mach eine gute Tat :)
Informationsquellen, Hilfsmaterialien
- "Github mit Daten und Jupyter Notebook"
- "Wettbewerbsplattform SIBUR CHALLENGE 2020"
- "Seite des Veranstalters des Wettbewerbs SIBUR CHALLENGE 2020"
- "Guter Artikel über Habré" Grundlagen der Verarbeitung natürlicher Sprache für Text ""
- "Ein weiterer guter Artikel über Habré" Fuzzy-String-Vergleich: Verstehe mich, wenn du kannst ""
- "Veröffentlichung aus dem APNI-Magazin"
- "Ein Artikel über den Tanimoto-Koeffizienten" String-Ähnlichkeit "wird hier nicht verwendet"