LightGBM erweitert den Gradienten-Boosting-Algorithmus um eine Art automatische Objektauswahl und konzentriert sich auf Beispiele für das Boosten mit großen Verläufen. Dies kann zu einer dramatischen Beschleunigung des Lernens und einer besseren Vorhersageleistung führen. Somit ist LightGBM zum De-facto-Algorithmus für maschinelle Lernwettbewerbe geworden, wenn mit Tabellendaten für Regressions- und Klassifizierungsvorhersagemodellierungsprobleme gearbeitet wird. In diesem Tutorial erfahren Sie, wie Sie Light Gradient Boosted-Maschinenensembles für die Klassifizierung und Regression entwerfen. Nach Abschluss dieses Tutorials wissen Sie:
- Die Light Gradient Boosted Machine (LightGBM) ist eine effiziente Open Source-Implementierung des stochastischen Gradient Boosting-Ensembles.
- Entwicklung von LightGBM-Ensembles zur Klassifizierung und Regression mithilfe der Scikit-Learn-API.
- LightGBM .

- LightBLM.
- Scikit-Learn API LightGBM.
— LightGBM .
— LightGBM . - LightGBM.
— .
— .
— .
— .
LightBLM
Gradient Boosting bezieht sich auf eine Klasse von Ensemble-Algorithmen für maschinelles Lernen, die für Klassifizierungsprobleme oder prädiktive Regressionsmodellierung verwendet werden können.
Ensembles werden aus Entscheidungsbaummodellen erstellt. Die Bäume werden einzeln zum Ensemble hinzugefügt und trainiert, um die Vorhersagefehler der vorherigen Modelle zu korrigieren. Dies ist eine Art Ensemble-Modell für maschinelles Lernen, das als Boosting bezeichnet wird.
Die Modelle werden unter Verwendung einer beliebigen differenzierbaren Verlustfunktion und eines Algorithmus zur Optimierung des Gradientenabfalls trainiert. Dies gibt der Methode den Namen "Gradientenverstärkung", da der Verlustgradient beim Training des Modells wie bei einem neuronalen Netzwerk minimiert wird. Weitere Informationen zum Gradientenverstärken finden Sie im Tutorial:"Eine sanfte Einführung in den ML-Gradienten-Boosting-Algorithmus . "
LightGBM ist eine Open-Source-Implementierung der Gradientenverstärkung, die effizient und möglicherweise sogar effizienter als andere Implementierungen ist.
Als solches ist LightGBM ein Open-Source-Projekt, eine Softwarebibliothek und ein Algorithmus für maschinelles Lernen. Das heißt, das Projekt ist der Extreme Gradient Boosting- oder XGBoost-Technik sehr ähnlich .
LightGBM wurde von Golin, K., et al. Weitere Informationen finden Sie unter 2017 Artikel mit dem Titel „LightGBM: Hoch effiziente Gradient Boosting Entscheidungsbaum . “ Die Implementierung führt zwei Schlüsselideen ein: GOSS und EFB.
Gradient One-Way Sampling (GOSS) ist eine Modifikation von Gradient Boosting, die sich auf die Tutorials konzentriert, die zu einem größeren Gradienten führen, was wiederum das Lernen beschleunigt und den Rechenaufwand der Methode verringert.
Mit GOSS schließen wir einen signifikanten Teil der Dateninstanzen mit kleinen Verläufen aus und verwenden nur den Rest der Dateninstanzen, um den Informationsgewinn abzuschätzen. Wir argumentieren, dass GOSS eine ziemlich genaue Schätzung des Informationsgewinns mit einer viel kleineren Datengröße erhalten kann, da Dateninstanzen mit großen Gradienten eine wichtigere Rolle bei der Berechnung des Informationsgewinns spielen.
Exclusive Feature Bundling (EFB) ist ein Ansatz zum Kombinieren spärlicher (meist null) sich gegenseitig ausschließender Features, z. B. kategoriale Eingabevariablen, die mit einer einheitlichen Codierung codiert sind. Somit handelt es sich um eine Art automatische Funktionsauswahl.
... wir verpacken sich gegenseitig ausschließende Features (dh sie nehmen selten gleichzeitig Werte ungleich Null an), um die Anzahl der Features zu reduzieren.
Zusammen können diese beiden Änderungen die Trainingszeit des Algorithmus um das 20-fache beschleunigen. Daher kann LightGBM als Gradient Boosted Decision Trees (GBDTs) mit GOSS und EFB betrachtet werden.
Wir nennen unsere neue GBDT-Implementierung GOSS und EFB LightGBM. Unsere Experimente mit mehreren öffentlich verfügbaren Datensätzen zeigen, dass LightGBM den Lernprozess eines herkömmlichen GBDT um mehr als das 20-fache beschleunigt und nahezu die gleiche Genauigkeit erreicht.
Scikit-Learn API für LightGBM
LightGBM kann als eigenständige Bibliothek installiert werden und das LightGBM-Modell kann mithilfe der Scikit-Learn-API entwickelt werden.
Der erste Schritt ist die Installation der LightGBM-Bibliothek. Auf den meisten Plattformen kann dies mit dem Pip-Paket-Manager durchgeführt werden. z.B:
sudo pip install lightgbmSie können die Installation und Version folgendermaßen überprüfen:
# check lightgbm version
import lightgbm
print(lightgbm.__version__)Das Skript zeigt die Version des installierten LightGBM an. Ihre Version sollte gleich oder höher sein. Wenn nicht, aktualisieren Sie LightGBM. Wenn Sie spezielle Anweisungen für Ihre Entwicklungsumgebung benötigen, lesen Sie das LightGBM-Installationshandbuch .
Die LightGBM-Bibliothek verfügt über eine eigene API, obwohl wir eine Methode über Scikit-Learn-Wrapper-Klassen verwenden: LGBMRegressor und LGBMClassifier . Auf diese Weise kann die gesamte Scikit-Learn-Bibliothek für maschinelles Lernen verwendet werden, um Daten vorzubereiten und Modelle auszuwerten.
Beide Modelle arbeiten auf dieselbe Weise und verwenden dieselben Argumente, um zu beeinflussen, wie Entscheidungsbäume erstellt und dem Ensemble hinzugefügt werden. Das Modell verwendet Zufälligkeit. Dies bedeutet, dass jedes Mal, wenn der Algorithmus mit denselben Daten ausgeführt wird, ein etwas anderes Modell erstellt wird.
Wenn Sie Algorithmen für maschinelles Lernen mit einem stochastischen Lernalgorithmus verwenden, wird empfohlen, diese zu bewerten, indem Sie ihre Leistung über mehrere Läufe oder Wiederholungen der Kreuzvalidierung mitteln. Bei der Anpassung des endgültigen Modells kann es wünschenswert sein, entweder die Anzahl der Bäume zu erhöhen, bis die Varianz des Modells mit wiederholten Schätzungen abnimmt, oder mehrere endgültige Modelle zu trainieren und ihre Vorhersagen zu mitteln. Lassen Sie uns einen Blick auf das Entwerfen eines LightGBM-Ensembles für Klassifizierung und Regression werfen.
LightGBM-Ensemble zur Klassifizierung
In diesem Abschnitt wird die Verwendung von LightGBM für eine Klassifizierungsaufgabe beschrieben. Erstens können wir die Funktion make_classification () verwenden , um ein synthetisches binäres Klassifizierungsproblem mit 1000 Beispielen und 20 Eingabefunktionen zu erstellen. Siehe das ganze Beispiel unten.
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# summarize the datasetDurch Ausführen des Beispiels wird ein Dataset erstellt und die Form der Eingabe- und Ausgabekomponenten zusammengefasst.
(1000, 20) (1000,)Wir können dann den LightGBM-Algorithmus für diesen Datensatz auswerten. Wir werden das Modell unter Verwendung einer wiederholten geschichteten k-fachen Kreuzvalidierung mit drei Wiederholungen und einem k von 10 bewerten. Wir werden den Mittelwert und die Standardabweichung der Modellgenauigkeit über alle Wiederholungen und Falten berichten.
# evaluate lightgbm algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = LGBMClassifier()
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))Das Ausführen des Beispiels zeigt die Genauigkeit des Mittelwerts und der Standardabweichung des Modells.
Hinweis : Ihre Ergebnisse können aufgrund der stochastischen Natur des Algorithmus oder des Schätzverfahrens oder aufgrund unterschiedlicher numerischer Genauigkeit abweichen. Probieren Sie das Beispiel mehrmals aus und vergleichen Sie das durchschnittliche Ergebnis.
In diesem Fall können wir sehen, dass das LightGBM-Ensemble mit Standard-Hyperparametern eine Klassifizierungsgenauigkeit von etwa 92,5% für diesen Testdatensatz erreicht.
Accuracy: 0.925 (0.031)Wir können auch das LightGBM-Modell als endgültiges Modell verwenden und Vorhersagen für die Klassifizierung treffen. Erstens passt das LightGBM-Ensemble alle verfügbaren Daten an, und zweitens können Sie die Funktion pred () aufrufen , um Vorhersagen für die neuen Daten zu treffen. Das folgende Beispiel zeigt dies in unserem binären Klassifizierungsdatensatz.
# make predictions using lightgbm for classification
from sklearn.datasets import make_classification
from lightgbm import LGBMClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = LGBMClassifier()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.2929949,-4.21223056,-1.288332,-2.17849815,-0.64527665,2.58097719,0.28422388,-7.1827928,-1.91211104,2.73729512,0.81395695,3.96973717,-2.66939799,3.34692332,4.19791821,0.99990998,-0.30201875,-4.43170633,-2.82646737,0.44916808]
yhat = model.predict([row])
print('Predicted Class: %d' % yhat[0])Durch Ausführen des Beispiels wird ein LightGBM-Ensemble-Modell für das gesamte Dataset trainiert und anschließend eine neue Datenzeile vorhergesagt, als würde das Modell in einer Anwendung verwendet.
Predicted Class: 1Nachdem wir mit der Verwendung von LightGBM zur Klassifizierung vertraut sind, werfen wir einen Blick auf die Regressions-API.
LightGBM-Ensemble für Regression
In diesem Abschnitt werden wir uns mit der Verwendung von LightGBM für ein Regressionsproblem befassen. Erstens können wir die Funktion make_regression () verwenden
, um ein synthetisches Regressionsproblem mit 1000 Beispielen und 20 Eingabefunktionen zu erstellen. Siehe das ganze Beispiel unten.
# test regression dataset
from sklearn.datasets import make_regression
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# summarize the dataset
print(X.shape, y.shape)Durch Ausführen des Beispiels wird ein Dataset erstellt und die Eingabe- und Ausgabekomponenten zusammengefasst.
(1000, 20) (1000,)Zweitens können wir den LightGBM-Algorithmus für diesen Datensatz bewerten.
Wie im letzten Abschnitt werden wir das Modell durch wiederholte k-fache Kreuzvalidierung mit drei Wiederholungen und k gleich 10 bewerten. Wir werden den mittleren absoluten Fehler (MAE) des Modells über alle Wiederholungen und Kreuzvalidierungsgruppen hinweg melden. Die Scikit-Lernbibliothek macht die MAE negativ, so dass sie eher maximiert als minimiert wird. Dies bedeutet, dass große negative MAEs besser sind und das ideale Modell eine MAE von 0 hat. Ein vollständiges Beispiel ist unten gezeigt.
# evaluate lightgbm ensemble for regression
from numpy import mean
from numpy import std
from sklearn.datasets import make_regression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedKFold
from lightgbm import LGBMRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = LGBMRegressor()
# evaluate the model
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('MAE: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))Wenn Sie das Beispiel ausführen, werden der Mittelwert und die Standardabweichung des Modells angegeben.
Hinweis : Ihre Ergebnisse können aufgrund der stochastischen Natur des Algorithmus oder des Schätzverfahrens oder aufgrund von Unterschieden in der numerischen Genauigkeit variieren . Führen Sie das Beispiel mehrmals aus und vergleichen Sie den Durchschnitt. In diesem Fall sehen wir, dass das LightGBM-Ensemble mit Standard-Hyperparametern einen MAE von etwa 60 erreicht.
MAE: -60.004 (2.887)Wir können auch das LightGBM-Modell als endgültiges Modell verwenden und Vorhersagen für die Regression treffen. Zuerst wird das LightGBM-Ensemble auf alle verfügbaren Daten trainiert, dann kann Predict () aufgerufen werden , um neue Daten vorherzusagen. Das folgende Beispiel zeigt dies in unserem Regressionsdatensatz.
# gradient lightgbm for making predictions for regression
from sklearn.datasets import make_regression
from lightgbm import LGBMRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = LGBMRegressor()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.20543991,-0.97049844,-0.81403429,-0.23842689,-0.60704084,-0.48541492,0.53113006,2.01834338,-0.90745243,-1.85859731,-1.02334791,-0.6877744,0.60984819,-0.70630121,-1.29161497,1.32385441,1.42150747,1.26567231,2.56569098,-0.11154792]
yhat = model.predict([row])
print('Prediction: %d' % yhat[0]) Durch Ausführen des Beispiels wird das LightGBM-Ensemble-Modell für das gesamte Dataset trainiert und anschließend eine neue Datenzeile vorhergesagt, wie dies bei Verwendung des Modells in einer Anwendung der Fall wäre.
Prediction: 52Nachdem wir mit der Verwendung der Scikit-Learn-API zum Bewerten und Anwenden von LightGBM-Ensembles vertraut sind, werfen wir einen Blick auf das Einrichten des Modells.
LightGBM-Hyperparameter
In diesem Abschnitt werden einige der für das LightGBM-Ensemble wichtigen Hyperparameter und ihre Auswirkungen auf die Modellleistung genauer betrachtet. LightGBM hat viele Hyperparameter zu betrachten. Hier sehen wir uns die Anzahl der Bäume und ihre Tiefe, die Lernrate und die Art des Boosts an. Allgemeine Tipps zum Optimieren von LightGBM-Hyperparametern finden Sie in der Dokumentation: Optimieren von LightGBM-Parametern .
Untersuchen der Anzahl der Bäume
Ein wichtiger Hyperparameter für den LightGBM-Ensemble-Algorithmus ist die Anzahl der im Ensemble verwendeten Entscheidungsbäume. Denken Sie daran, dass dem Modell nacheinander Entscheidungsbäume hinzugefügt werden, um die Vorhersagen früherer Bäume zu korrigieren und zu verbessern. Die Regel funktioniert oft: Mehr Bäume sind besser. Die Anzahl der Bäume kann mit dem Argument n_estimators angegeben werden, das standardmäßig 100 ist. Im folgenden Beispiel wird die Auswirkung der Anzahl der Bäume von 10 bis 5000 untersucht.
# explore lightgbm number of trees effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
trees = [10, 50, 100, 500, 1000, 5000]
for n in trees:
models[str(n)] = LGBMClassifier(n_estimators=n)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()Wenn Sie das Beispiel zuerst ausführen, wird die durchschnittliche Genauigkeit für jede Anzahl von Entscheidungsbäumen angezeigt.
Hinweis : Ihre Ergebnisse können aufgrund der stochastischen Natur des Algorithmus oder des Schätzverfahrens oder aufgrund unterschiedlicher numerischer Genauigkeit abweichen. Führen Sie das Beispiel mehrmals aus und vergleichen Sie den Durchschnitt.
Hier sehen wir, dass sich die Leistung für diesen Datensatz auf etwa 500 Bäume verbessert, wonach er sich zu glätten scheint.
>10 0.857 (0.033)
>50 0.916 (0.032)
>100 0.925 (0.031)
>500 0.938 (0.026)
>1000 0.938 (0.028)
>5000 0.937 (0.028)Ein Box- und Whisker-Diagramm wird erstellt, um die Genauigkeitsbewertungen für jede konfigurierte Anzahl von Bäumen zu verteilen. Es gibt einen allgemeinen Trend zu einer Steigerung der Leistung des Modells und der Größe des Ensembles.
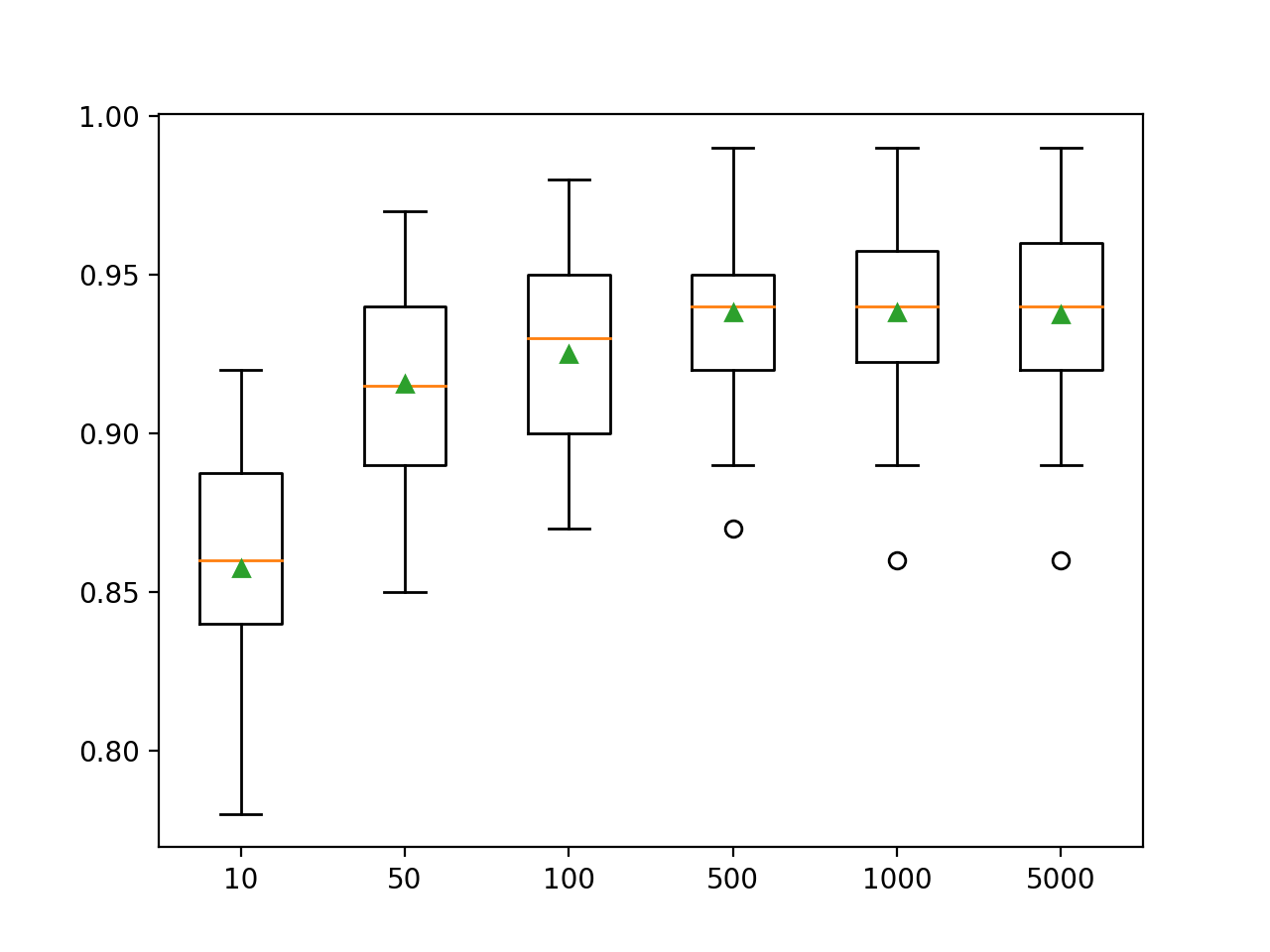
Untersuchen der Tiefe eines Baumes
Das Ändern der Tiefe jedes dem Ensemble hinzugefügten Baums ist ein weiterer wichtiger Hyperparameter für die Gradientenverstärkung. Die Tiefe des Baums bestimmt, wie sehr sich jeder Baum auf den Trainingsdatensatz spezialisiert hat: wie allgemein oder trainiert er sein kann. Bäume, die nicht zu flach und allgemein (z. B. AdaBoost ) und nicht zu tief und spezialisiert (z. B. Bootstrap-Aggregation ) sein sollten, werden bevorzugt .
Gradient Boosting funktioniert normalerweise gut bei Bäumen mit mäßiger Tiefe, die Training und Allgemeinheit in Einklang bringen. Die Tiefe des Baums wird durch das Argument max_depth gesteuertund der Standardwert ist ein undefinierter Wert, da der Standardmechanismus zum Verwalten der Komplexität von Bäumen darin besteht, eine endliche Anzahl von Knoten zu verwenden.
Es gibt zwei Möglichkeiten, die Komplexität eines Baums zu steuern: über die maximale Baumtiefe und die maximale Anzahl von Endknoten (Blättern) des Baums. Wir untersuchen hier die Anzahl der Blätter, daher müssen wir die Anzahl erhöhen, um tiefere Bäume zu unterstützen, indem wir das Argument num_leaves angeben . Im Folgenden untersuchen wir Baumtiefen von 1 bis 10 und deren Auswirkungen auf die Modellleistung.
# explore lightgbm tree depth effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
for i in range(1,11):
models[str(i)] = LGBMClassifier(max_depth=i, num_leaves=2**i)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()Wenn Sie das Beispiel zuerst ausführen, wird die durchschnittliche Genauigkeit für jede angepasste Baumtiefe angezeigt.
Hinweis : Ihre Ergebnisse können aufgrund der stochastischen Natur des Algorithmus oder des Schätzverfahrens oder aufgrund unterschiedlicher numerischer Genauigkeit abweichen. Führen Sie das Beispiel mehrmals aus und vergleichen Sie das durchschnittliche Ergebnis.
Hier können wir sehen, dass sich die Leistung mit zunehmender Baumtiefe verbessert, möglicherweise bis zu 10 Stufen. Es wäre interessant, noch tiefere Bäume zu erkunden.
>1 0.833 (0.028)
>2 0.870 (0.033)
>3 0.899 (0.032)
>4 0.912 (0.026)
>5 0.925 (0.031)
>6 0.924 (0.029)
>7 0.922 (0.027)
>8 0.926 (0.027)
>9 0.925 (0.028)
>10 0.928 (0.029)Ein Rechteck- und Whisker-Diagramm wird generiert, um die Genauigkeitsbewertungen für jede konfigurierte Baumtiefe zu verteilen. Es besteht eine allgemeine Tendenz, dass die Modellleistung mit einer Baumtiefe von bis zu fünf Ebenen zunimmt, wonach die Leistung ziemlich flach bleibt.
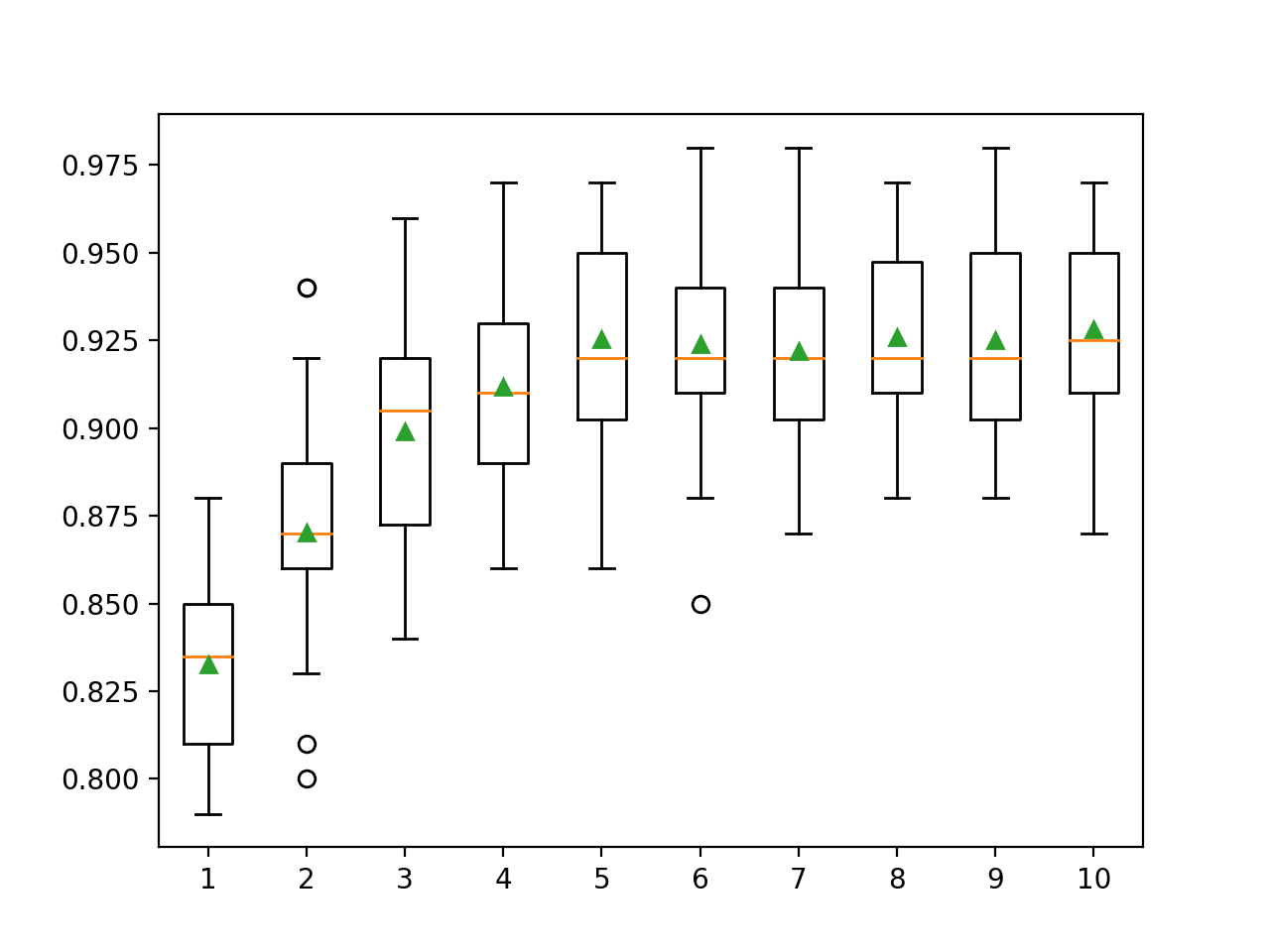
Lernratenforschung
Die Lernrate steuert den Grad, in dem jedes Modell zur Vorhersage des Ensembles beiträgt. Niedrigere Geschwindigkeiten erfordern möglicherweise mehr Entscheidungsbäume im Ensemble. Die Lernrate kann mit dem Argument learning_rate gesteuert werden. Standardmäßig beträgt sie 0,1. Im Folgenden wird die Lernrate untersucht und die Auswirkung von Werten von 0,0001 bis 1,0 verglichen.
# explore lightgbm learning rate effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
rates = [0.0001, 0.001, 0.01, 0.1, 1.0]
for r in rates:
key = '%.4f' % r
models[key] = LGBMClassifier(learning_rate=r)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()Wenn Sie das Beispiel zuerst ausführen, wird die durchschnittliche Genauigkeit für jede konfigurierte Lernrate angezeigt.
Hinweis : Ihre Ergebnisse können aufgrund der stochastischen Natur des Algorithmus oder des Schätzverfahrens oder aufgrund von Unterschieden in der numerischen Genauigkeit variieren . Führen Sie das Beispiel mehrmals aus und vergleichen Sie das durchschnittliche Ergebnis.
Hier sehen wir, dass eine höhere Lernrate zu einer besseren Leistung dieses Datensatzes führt. Wir gehen davon aus, dass das Hinzufügen weiterer Bäume zum Ensemble für eine niedrigere Lernrate die Leistung weiter verbessern wird.
>0.0001 0.800 (0.038)
>0.0010 0.811 (0.035)
>0.0100 0.859 (0.035)
>0.1000 0.925 (0.031)
>1.0000 0.928 (0.025)Ein Schnurrbartfeld wird erstellt, um die Genauigkeitswerte für jede konfigurierte Lernrate zu verteilen. Es besteht eine allgemeine Tendenz, dass die Modellleistung mit einer Erhöhung der Lernrate auf 1,0 zunimmt.

Förderung der Typforschung
Die Besonderheit von LightGBM besteht darin, dass es eine Reihe von Boosting-Algorithmen unterstützt, die als Boost-Typen bezeichnet werden. Der Boosting-Typ wird mit dem Argument boosting_type angegeben und verwendet eine Zeichenfolge, um den Typ zu bestimmen. Mögliche Werte:
- 'gbdt' : Gradient Boosted Decision Tree (GDBT);
- 'Dart' : Das Konzept des Aussetzers wird in MART eingegeben, wir erhalten DART;
- 'goss' : Gradient One-Way-Fetch (GOSS).
Die Standardeinstellung ist GDBT, der klassische Algorithmus zur Erhöhung des Gradienten.
DART wird in einem Artikel aus dem Jahr 2015 mit dem Titel " DART: Aussetzer treffen auf mehrere additive Regressionsbäume " beschrieben und fügt, wie der Name schon sagt, das Konzept des Ausfalls vom tiefen Lernen zum MART-Algorithmus ( Multiple Additive Regression Trees ) hinzu, einem Vorläufer für Entscheidungsbäume mit Gradientenverstärkung.
Dieser Algorithmus ist unter vielen Namen bekannt, einschließlich Gradient TreeBoost, Boosted Trees und Multiple Additive Regression Trees and Trees (MART). Wir verwenden den letzteren Namen, um auf den Algorithmus zu verweisen.
GOSS wird mit Arbeiten zu LightGBM und der lightbgm-Bibliothek vorgestellt. Dieser Ansatz zielt darauf ab, nur diejenigen Instanzen zu verwenden, die zu einem großen Fehlergradienten führen, um das Modell zu aktualisieren und die verbleibenden Instanzen zu entfernen.
... Wir schließen einen erheblichen Teil der Dateninstanzen mit kleinen Verläufen aus und verwenden nur den Rest, um die Zunahme der Informationen abzuschätzen.
Im Folgenden wird LightGBM anhand eines synthetischen Klassifizierungsdatensatzes mit drei wichtigen Boosting-Methoden trainiert.
# explore lightgbm boosting type effect on performance
from numpy import arange
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
types = ['gbdt', 'dart', 'goss']
for t in types:
models[t] = LGBMClassifier(boosting_type=t)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()Wenn Sie das Beispiel zuerst ausführen, wird die durchschnittliche Genauigkeit für jeden konfigurierten Boost-Typ angezeigt.
Hinweis : Ihre Ergebnisse können aufgrund der stochastischen Natur des Algorithmus oder des Schätzverfahrens oder aufgrund unterschiedlicher numerischer Genauigkeit abweichen. Führen Sie das Beispiel mehrmals aus und vergleichen Sie das durchschnittliche Ergebnis.
Wir können sehen, dass die Standard-Boost-Methode besser abschneidet als die beiden anderen bewerteten Methoden.
>gbdt 0.925 (0.031)
>dart 0.912 (0.028)
>goss 0.918 (0.027)Ein Box-and-Whisker-Diagramm wird erstellt, um die Genauigkeitsschätzungen für jede konfigurierte Amplifikationsmethode zu verteilen und einen direkten Vergleich der Methoden zu ermöglichen.
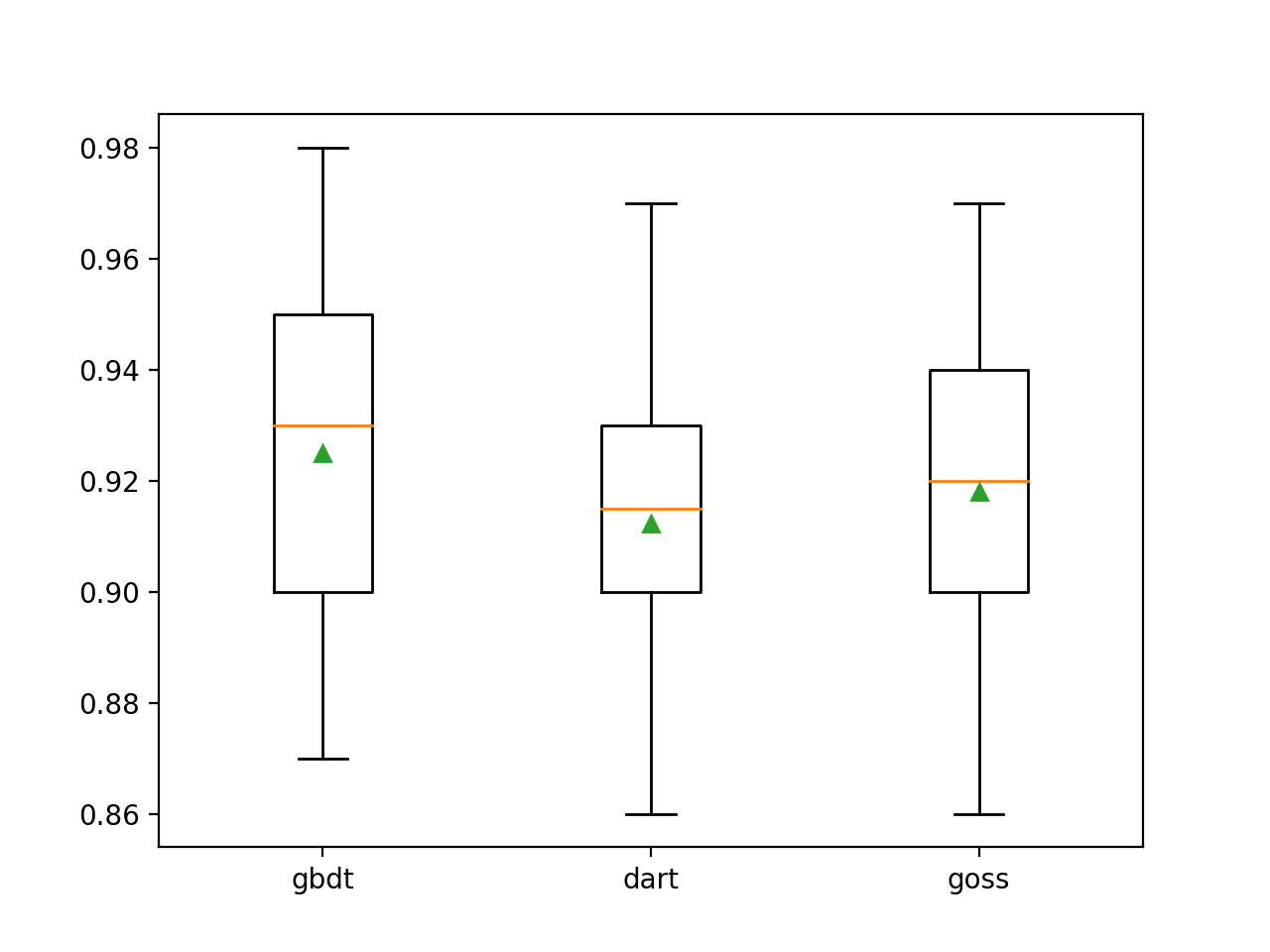

- Kurs für maschinelles Lernen
- Data Science Berufsausbildung
- Data Analyst-Schulung
- Python für Webentwicklungskurs
Weitere Kurse