
Chatbots sind mittlerweile in verschiedenen Geschäftsbereichen weit verbreitet. Banken können sie beispielsweise verwenden, um die Arbeit ihres Contact Centers zu optimieren, beliebte Kundenfragen sofort zu beantworten und ihnen Referenzinformationen bereitzustellen. Für Kunden sind Chatbots auch ein praktisches Tool: Es ist viel einfacher, eine Frage im Chat zu schreiben, als auf eine Antwort zu warten, indem Sie ein Contact Center anrufen.
In anderen Bereichen haben Chatbots ebenfalls gut funktioniert: In der Medizin können sie einen Patienten interviewen, Symptome einem Spezialisten übermitteln und einen Termin mit einem Arzt vereinbaren, um eine Diagnose zu stellen. In Logistikunternehmen helfen Ihnen Chat-Bots dabei, den Liefertermin zu vereinbaren, die Adresse zu ändern und einen geeigneten Abholpunkt auszuwählen. In großen Online-Shops haben Chat-Bots teilweise die Verwaltung von Bestellungen übernommen, und im Bereich Carsharing-Dienste erledigen Chat-Bots bis zu 90% der Aufgaben des Betreibers. Chat-Bots sind jedoch noch nicht in der Lage, Beschwerden zu lösen. Negatives Feedback und kontroverse Situationen fallen immer noch auf die Schultern von Bedienern und Spezialisten.
Daher nutzen die meisten wachsenden Unternehmen Chatbots bereits aktiv, um mit Kunden zu arbeiten. Die Vorteile der Implementierung eines Chatbots variieren jedoch häufig: In einigen Unternehmen erreicht der Automatisierungsgrad 90%, in anderen Unternehmen nur 30-40%. Wovon hängt es ab? Wie gut ist diese Metrik für ein Unternehmen? Gibt es Möglichkeiten, den Grad der Chatbot-Automatisierung zu erhöhen? Dieser Artikel behandelt Fragen, die Ihnen helfen, dies zu verstehen.
Benchmarking
Heute hat fast jeder Geschäftsbereich ein eigenes Wettbewerbsumfeld. Viele Unternehmen verfolgen ähnliche Geschäftsansätze. Wenn konkurrierende Unternehmen Chat-Bots für ihre Aktivitäten verwenden, ist es daher ratsam, diese zu vergleichen. Benchmarking ist ein gutes Vergleichstool.
In unserem Fall umfasst das Chatbot-Benchmarking verdeckte Recherchen, um die Funktionalität der Chatbots der Wettbewerber mit der Funktionalität Ihres eigenen Chatbots zu vergleichen. Betrachten wir einen Fall am Beispiel eines Bank-Chat-Bots.
Angenommen, eine Bank hat einen Chatbot entwickelt, um den Betrieb des Contact Centers zu optimieren und die Wartungskosten zu senken. Um ein Benchmarking durchzuführen, müssen andere Banken analysiert und die funktionalsten Chatbots ihrer Konkurrenten identifiziert werden.
Es ist erforderlich, eine Liste von Fragen zur Überprüfung zu erstellen (mindestens 50 Fragen, die in mehrere Themen unterteilt sind):
- Fragen zu Bankdienstleistungen , zum Beispiel: "Wie hoch sind Ihre Einzahlungssätze?", "Wie kann ich eine Karte erneut ausstellen?" etc.
- Referenzinformationen , zum Beispiel: "Wie hoch ist der aktuelle Wechselkurs?", "Wie bekomme ich einen Krediturlaub?" etc.
- Kundenverständnisstufe. (Widerstand des Bots gegen Tippfehler, Fehler, Wahrnehmung umgangssprachlicher Sprache), zum Beispiel: "Ich lade die Karte auf, was mache ich?", "Lade das Handy auf" usw.
- Gespräch über abstrakte Themen , zum Beispiel: "Erzähl einen Witz", "Was tun während der Selbstisolation?" etc.
Hinweis: Diese Themen der Fragen dienen als Beispiel und können erweitert oder geändert werden.
Dies sind die Fragen, die Sie Ihrem Chatbot sowie den Chatbots Ihrer Konkurrenten stellen sollten. Nach dem Schreiben der Frage sind 3 Optionen für das Ergebnis möglich (je nach Ergebnis wird die entsprechende Punktzahl notiert):
- Der Bot hat die Frage des Kunden nicht erkannt (0 Punkte).
- Der Bot erkannte die Frage des Kunden, jedoch erst nach Klärung der Fragen (0,5 Punkte).
- Der Bot erkannte die Frage beim ersten Versuch (1 Punkt).
Wenn der Chatbot den Client an den Operator übertragen hat, gilt die Frage ebenfalls als nicht erkannt (0 Punkte).
Als nächstes wird die Anzahl der von jedem Chatbot erzielten Punkte zusammengefasst, wonach der Anteil der korrekt erkannten Fragen zu jedem Thema berechnet wird (niedrig - weniger als 40%, mittel - von 40 bis 80%, hoch - mehr als 80%) und die endgültige Bewertung zusammengestellt wird. Die Ergebnisse können in Form einer Tabelle dargestellt werden:
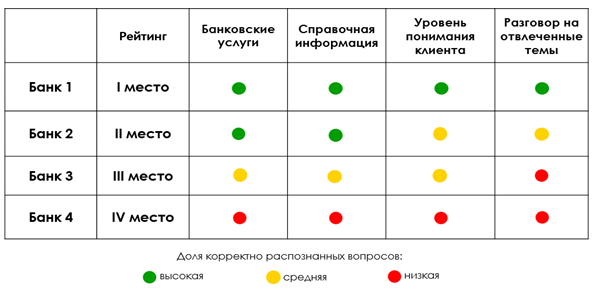
Angenommen, der Benchbot der Bank belegt laut Benchmarking-Ergebnissen den zweiten Platz. Welche Schlussfolgerungen können gezogen werden? Das Ergebnis ist nicht das beste, aber auch nicht das schlechteste. Anhand der Tabelle können wir sagen, dass es nicht die stärksten Seiten sind: Erstens müssen die Algorithmen verbessert werden, um die Fragen des Kunden richtig zu erkennen (der Chatbot versteht die Fragen des Kunden, die Fehler und Tippfehler enthalten, nicht immer) und unterstützt auch nicht immer den Dialog über abstrakte Themen ... Ein detaillierterer Unterschied ist im Vergleich zum Chatbot an erster Stelle zu sehen.
Der Chatbot, der den dritten Platz belegte, schnitt schlechter ab: Erstens erfordert er eine ernsthafte Überarbeitung der Wissensbasis über Bankdienstleistungen und Referenzinformationen, und zweitens ist er für den Dialog mit einem Kunden über abstrakte Themen schlecht ausgebildet. Es ist offensichtlich, dass der Automatisierungsgrad eines solchen Chatbots im Vergleich zu Wettbewerbern, die die Plätze I und II belegt haben, geringer ist.
Basierend auf den Ergebnissen des Benchmarking wurden die Stärken und Schwächen der Arbeit von Chat-Bots identifiziert und ein Vergleich der konkurrierenden Chat-Bots miteinander durchgeführt. Der nächste Schritt besteht darin, diese Problembereiche zu identifizieren. Wie kann dies erreicht werden? Betrachten wir einige Ansätze, die auf Datenanalyse basieren: AutoML, Process-Mining, DE-Ansatz.
AutoML
Derzeit ist künstliche Intelligenz bereits in viele Geschäftsbereiche eingedrungen und durchdringt diese auch weiterhin, was zwangsläufig zu einem erhöhten Bedarf an Kompetenzen im Bereich DataScience führt. Die Nachfrage nach solchen Spezialisten wächst jedoch schneller als ihr Qualifikationsniveau. Tatsache ist, dass die Entwicklung von Modellen für maschinelles Lernen viele Ressourcen erfordert und nicht nur viel Wissen von einem Spezialisten erfordert, sondern auch viel Zeit, um Modelle zu erstellen und zu vergleichen. Um den durch die Knappheit verursachten Druck zu verringern und die Zeit für die Entwicklung von Modellen zu verkürzen, haben viele Unternehmen begonnen, Algorithmen zu entwickeln, mit denen die Arbeit von DataScientists automatisiert werden kann. Solche Algorithmen werden AutoML genannt.
AutoML, auch als automatisiertes maschinelles Lernen bekannt, hilft dem DataScientist, die zeitaufwändigen und sich wiederholenden Aufgaben der Entwicklung von Modellen für maschinelles Lernen zu automatisieren und gleichzeitig deren Qualität beizubehalten. AutoML-Modelle können Ihnen zwar Zeit sparen, sie sind jedoch nur dann wirksam, wenn das von ihnen gelöste Problem dauerhaft ist und sich wiederholt. Unter diesen Bedingungen arbeiten AutoML-Modelle gut und zeigen akzeptable Ergebnisse.
Verwenden wir nun AutoML, um unser Problem zu lösen: Identifizieren Sie Problembereiche in der Arbeit von Chat-Bots. Wie oben erwähnt, ist ein Chatbot ein Roboter oder ein spezielles Programm. Sie weiß, wie man Schlüsselwörter aus einer Nachricht extrahiert und in ihrer Datenbank nach einer geeigneten Antwort sucht. Es ist eine Sache, nach der richtigen Antwort zu suchen, eine andere, einen logischen Dialog zu führen und die Kommunikation mit einer realen Person nachzuahmen. Dieser Vorgang hängt davon ab, wie gut der Chatbot geschrieben ist.
Stellen Sie sich eine Situation vor, in der ein Kunde eine Frage hat und ein Chatbot ihn seltsam, nicht logisch oder allgemein zu einem anderen Thema beantwortet. Infolgedessen ist der Kunde mit dieser Antwort nicht zufrieden und schreibt bestenfalls über sein Missverständnis der Antwort, schlimmstenfalls über negative Nachrichten an den Chatbot. Daher besteht die Aufgabe von AutoML darin, negative Dialoge aus der Gesamtzahl (basierend auf den entladenen Chatbot-Protokollen aus der Datenbank) zu identifizieren. Anschließend muss ermittelt werden, auf welche Szenarien sich diese Dialoge beziehen. Das erzielte Ergebnis wird die Grundlage für die Verfeinerung dieser Szenarien sein.
Markieren wir zunächst die Dialoge des Clients mit dem Chatbot. In jedem Dialog hinterlassen wir nur Nachrichten von Kunden. Wenn in der Nachricht des Kunden ein Negativ in Richtung des Chatbots vorhanden ist oder seine Antworten nicht verstanden werden, setzen Sie flag = 1, in anderen Fällen = 0:

Markieren von Nachrichten von Clients
Als Nächstes deklarieren wir das AutoML-Modell, trainieren es mit den markierten Daten und speichern es (alle erforderlichen Modellparameter werden ebenfalls übergeben, aber im folgenden Beispiel nicht gezeigt).
automl = saa.AutoML
res_df, feat_imp = automl.train('test.csv', 'test_preds.csv', 'classification', cache_dir = 'tmp_dir', use_ids = False)
automl.save('prec')Wir laden das resultierende Modell und machen dann eine Vorhersage der Zielvariablen für die Testdatei:
automl = saa.AutoML
automl.load('text_model.pkl')
preds_df, score, res_df = automl.predict('test.csv', 'test_preds.csv', cache_dir = 'tmp_dir')
preds_df.to_csv('preds.csv', sep=',', index=False)Als nächstes bewerten wir das resultierende Modell:
test_df = pd.read_csv('test.csv')
threshold = 0.5
am_test = preds_df['prediction'].copy()
am_test.loc[am_test>=threshold] = 1
am_test.loc[am_test<threshold] = 0
clear_output()
print_result(test_df[target_col], am_test.apply(int))Die resultierende

Fehlermatrix : Bei der Erstellung des Modells haben wir versucht, den Fehler der ersten Art zu minimieren (indem wir einem schlechten einen guten Dialog zuweisen). Daher haben wir für den erhaltenen Klassifikator beim f1-Maß von 0,66 angehalten. Mit Hilfe des trainierten Modells konnten 65.000 "schlechte" Sitzungen identifiziert werden, was es wiederum ermöglichte, 7 nicht ausreichend effektive Szenarien zu identifizieren.
Process Mining
Um problematische Szenarien zu identifizieren, können wir auch Tools verwenden, die auf Process Mining basieren - dem allgemeinen Namen für eine Reihe von Methoden und Ansätzen zur Analyse und Verbesserung von Prozessen in Informationssystemen oder Geschäftsprozessen, die auf der Untersuchung von Ereignisprotokollen basieren.
Mit dieser Methode konnten wir 7 Szenarien identifizieren, die an langwierigen und ineffektiven Dialogen beteiligt sind:
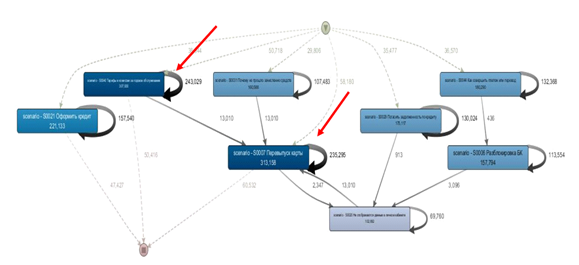
18% der Dialoge enthalten mehr als 4 Nachrichten vom Chatbot.
Jedes Element in der obigen Grafik ist ein Szenario. Wie Sie der Abbildung entnehmen können, werden die Skripte in einer Schleife ausgeführt, und die fettgedruckten Schleifenpfeile zeigen einen ziemlich langen Dialog zwischen dem Client und dem Chatbot an.
Um schlechte Szenarien zu finden, haben wir einen separaten Datensatz erstellt und darauf basierend ein Diagramm erstellt. Zu diesem Zweck wurden nur die Dialoge übrig gelassen, in denen kein Zugriff auf den Operator besteht. Anschließend wurden Dialoge mit ungelösten Problemen herausgefiltert. Als Ergebnis haben wir 5 Revisionsszenarien identifiziert, in denen der Chatbot die Frage des Kunden nicht löst.
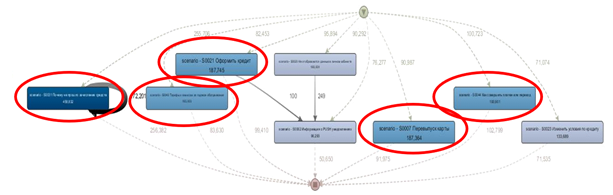
Identifizierte Szenarien machen etwa 15% aller Dialoge aus
DE-Ansatz (Data Engineering)
Ein einfacher analytischer Ansatz wurde auch verwendet, um nach Problemszenarien zu suchen: Dialoge wurden identifiziert, die Feedback-Bewertung, in der (von Kundenseite) zwischen 1 und 7 Punkten lag, und dann wurden die häufigsten Szenarien in dieser Stichprobe ausgewählt.
Mithilfe der auf AutoML, Process Mining und DE basierenden Ansätze haben wir beispielsweise im Chatbot des Unternehmens Problembereiche identifiziert, die verbessert werden müssen.
Jetzt wird der Chatbot besser!