
In nur 20 Jahren hat sich die Softwareentwicklung von Architekturmonolithen mit einer einzigen Datenbank und einem zentralen Status zu Microservices entwickelt, bei denen alles auf zahlreiche Container, Server, Rechenzentren und sogar Kontinente verteilt ist. Die Verteilung erleichtert die Skalierung, bringt jedoch auch völlig neue Herausforderungen mit sich, von denen viele zuvor mit Monolithen gelöst wurden.
Lassen Sie uns einen kurzen Überblick über die Geschichte der Netzwerkanwendungen geben, um herauszufinden, wie wir heute hierher gekommen sind. Lassen Sie uns dann über das in Temporal verwendete Stateful-Execution-Modell sprechen .und wie es das Problem serviceorientierter Architekturen (SOA) löst. Ich bin vielleicht voreingenommen, weil ich die Lebensmittelabteilung bei Temporal leite, aber ich glaube, dass dieser Ansatz die Zukunft ist.
Eine kurze Geschichtsstunde
 Vor zwanzig Jahren haben Entwickler fast immer monolithische Anwendungen erstellt. Es ist ein einfaches und konsistentes Modell, ähnlich wie Sie in Ihrer lokalen Umgebung programmieren. Monolithen sind naturgemäß von einer einzigen Datenbank abhängig, dh alle Zustände sind zentralisiert. Innerhalb einer einzelnen Transaktion kann ein Monolith jeden seiner Zustände ändern, dh es gibt ein binäres Ergebnis: ob es funktioniert hat oder nicht. Es gibt keinen Raum für Inkonsistenzen. Das Wunderbare am Monolithen ist, dass es aufgrund einer fehlgeschlagenen Transaktion keinen inkonsistenten Zustand gibt. Dies bedeutet, dass Entwickler keinen Code schreiben müssen, um den Status der verschiedenen Elemente zu erraten.
Vor zwanzig Jahren haben Entwickler fast immer monolithische Anwendungen erstellt. Es ist ein einfaches und konsistentes Modell, ähnlich wie Sie in Ihrer lokalen Umgebung programmieren. Monolithen sind naturgemäß von einer einzigen Datenbank abhängig, dh alle Zustände sind zentralisiert. Innerhalb einer einzelnen Transaktion kann ein Monolith jeden seiner Zustände ändern, dh es gibt ein binäres Ergebnis: ob es funktioniert hat oder nicht. Es gibt keinen Raum für Inkonsistenzen. Das Wunderbare am Monolithen ist, dass es aufgrund einer fehlgeschlagenen Transaktion keinen inkonsistenten Zustand gibt. Dies bedeutet, dass Entwickler keinen Code schreiben müssen, um den Status der verschiedenen Elemente zu erraten.
Monolithen machten lange Zeit Sinn. Es gab noch nicht viele verbundene Benutzer, daher waren die Anforderungen an die Software-Skalierung minimal. Selbst die größten Software-Giganten betrieben Systeme, die nach modernen Maßstäben dürftig waren. Nur eine Handvoll Unternehmen wie Amazon und Google verwendeten groß angelegte Lösungen, aber dies waren die Ausnahmen von der Regel.
Menschen als Software
In den letzten 20 Jahren sind die Softwareanforderungen stetig gestiegen. Heute sollten Anwendungen vom ersten Tag an auf dem Weltmarkt funktionieren. Unternehmen wie Twitter und Facebook haben Online rund um die Uhr zur Voraussetzung gemacht. Apps bieten nichts mehr, sie sind selbst zu einer Benutzererfahrung geworden. Jedes Unternehmen muss heute über Softwareprodukte verfügen. "Zuverlässigkeit" und "Verfügbarkeit" sind keine Eigenschaften mehr, sondern Anforderungen.
Leider begannen die Monolithen auseinanderzufallen, als "Skalierbarkeit" und "Verfügbarkeit" zu den Anforderungen hinzugefügt wurden. Entwickler und Unternehmen mussten Wege finden, um mit dem explosiven globalen Wachstum und den anspruchsvollen Benutzererwartungen Schritt zu halten. Ich musste nach alternativen Architekturen suchen, die die aufkommenden Probleme im Zusammenhang mit der Skalierung reduzieren.
Microservices (also serviceorientierte Architekturen) waren die Antwort. Anfangs schienen sie eine großartige Lösung zu sein, da Sie damit Anwendungen in relativ eigenständige Module aufteilen konnten, die unabhängig voneinander skaliert werden können. Und da jeder Microservice seinen eigenen Status beibehielt, waren die Anwendungen nicht mehr auf die Kapazität einer einzelnen Maschine beschränkt! Die Entwickler konnten endlich Programme erstellen, die mit der wachsenden Anzahl von Verbindungen skaliert werden konnten. Microservices gaben Teams und Unternehmen aufgrund der Transparenz in der Verantwortung und der Trennung von Architekturen Flexibilität bei ihrer Arbeit.
Es gibt keinen freien Käse
Während Microservices die Skalierbarkeits- und Verfügbarkeitsprobleme gelöst haben, die das Softwarewachstum behindert haben, waren die Dinge nicht wolkenlos. Die Entwickler begannen zu erkennen, dass Microservices schwerwiegende Mängel aufweisen.
Monolithen haben normalerweise eine Datenbank und einen Anwendungsserver. Und da der Monolith nicht gespalten werden kann, gibt es nur zwei Möglichkeiten zur Skalierung:
- Vertikal : Aktualisieren der Hardware, um den Durchsatz oder die Kapazität zu erhöhen. Diese Skalierung kann effektiv sein, ist aber teuer. Und es wird das Problem sicherlich nicht für immer beheben, wenn Ihre Anwendung weiter wachsen muss. Und wenn Sie genug erweitern, wird es am Ende nicht genug Ausrüstung geben, um ein Upgrade durchzuführen.
- : , . , .
Microservices sind unterschiedlich, ihr Wert liegt in der Fähigkeit, viele "Typen" von Datenbanken, Warteschlangen und anderen Diensten zu haben, die unabhängig voneinander skaliert und verwaltet werden. Das erste Problem, das beim Wechsel zu Microservices auffiel, war jedoch genau die Tatsache, dass Sie sich jetzt um eine Reihe von Servern und Datenbanken aller Art kümmern müssen.
Lange Zeit war alles dem Zufall überlassen, Entwickler und Betreiber stiegen selbstständig aus. Infrastrukturmanagementprobleme, die von Microservices ausgehen, sind schwer zu lösen und beeinträchtigen bestenfalls die Anwendungszuverlässigkeit.
Das Angebot entsteht jedoch als Reaktion auf die Nachfrage. Je mehr Microservices verbreitet werden, desto mehr Entwickler sind motiviert, Infrastrukturprobleme zu lösen. Langsam aber sicher tauchten Tools auf, und Technologien wie Docker, Kubernetes und AWS Lambda füllten die Lücke. Sie machten die Bedienung der Microservice-Architektur sehr einfach. Anstatt ihren eigenen Code für die Orchestrierung mit Containern und Ressourcen zu schreiben, können sich Entwickler auf vorgefertigte Tools verlassen. Im Jahr 2020 haben wir endlich den Meilenstein erreicht, bei dem die Verfügbarkeit unserer Infrastruktur die Zuverlässigkeit unserer Anwendungen nicht mehr beeinträchtigt. Perfekt!

Natürlich leben wir noch nicht in der Utopie perfekt stabiler Software. Die Infrastruktur ist nicht länger die Quelle der Anwendungsunsicherheit, der Anwendungscode hat seinen Platz eingenommen.
Ein weiteres Problem mit Microservices
In Monolithen schreiben Entwickler Code, der den Status binär ändert: Entweder passiert etwas oder nicht. Bei Microservices wird der Status auf verschiedene Server verteilt. Um den Status einer Anwendung zu ändern, müssen mehrere Datenbanken gleichzeitig aktualisiert werden. Es besteht die Möglichkeit, dass eine Datenbank erfolgreich aktualisiert wird und andere abstürzen, sodass Sie einen inkonsistenten Zwischenstatus haben. Da jedoch Services die einzige Lösung für das Problem der horizontalen Skalierung waren, hatten die Entwickler keine andere Option.
Ein grundlegendes Problem mit dem über Dienste verteilten Status besteht darin, dass jeder Anruf bei einem externen Dienst ein zufälliges Ergebnis in Bezug auf die Verfügbarkeit hat. Natürlich können Entwickler das Problem in ihrem Code ignorieren und jeden Aufruf einer externen Abhängigkeit als immer erfolgreich betrachten. Aber dann kann eine gewisse Abhängigkeit die Anwendung ohne Vorwarnung herunterfahren. Daher mussten Entwickler ihren Code aus der Zeit der Monolithen anpassen, um während der Transaktionen Überprüfungen auf Betriebsstörungen durchzuführen. Im Folgenden wird gezeigt, wie der zuletzt aufgezeichnete Status kontinuierlich aus dem dedizierten myDB-Speicher abgerufen wird, um Rennbedingungen zu vermeiden. Leider hilft auch diese Implementierung nicht weiter. Wenn sich der Status des Kontos ändert, ohne myDB zu aktualisieren, kann es zu Inkonsistenzen kommen.
public void transferWithoutTemporal(
String fromId,
String toId,
String referenceId,
double amount,
) {
boolean withdrawDonePreviously = myDB.getWithdrawState(referenceId);
if (!withdrawDonePreviously) {
account.withdraw(fromAccountId, referenceId, amount);
myDB.setWithdrawn(referenceId);
}
boolean depositDonePreviously = myDB.getDepositState(referenceId);
if (!depositDonePreviously) {
account.deposit(toAccountId, referenceId, amount);
myDB.setDeposited(referenceId);
}
}
Leider ist es unmöglich, Code ohne Fehler zu schreiben. Und je komplexer der Code ist, desto wahrscheinlicher treten Fehler auf. Wie zu erwarten ist, ist der Code, der mit der "Middleware" funktioniert, nicht nur komplex, sondern auch kompliziert. Zumindest eine gewisse Zuverlässigkeit ist besser als keine Zuverlässigkeit, daher mussten die Entwickler solchen anfangs fehlerhaften Code schreiben, um die Benutzererfahrung aufrechtzuerhalten. Es kostet uns Zeit und Mühe und die Arbeitgeber viel Geld. Microservices lassen sich zwar wunderbar skalieren, kosten jedoch Spaß, Produktivität und Anwendungszuverlässigkeit für Entwickler.
Millionen von Entwicklern verbringen jeden Tag Zeit damit, eines der am meisten neu erfundenen Räder neu zu erfinden - die Zuverlässigkeit der Kesselplatte. Moderne Ansätze für die Arbeit mit Microservices spiegeln einfach nicht die Anforderungen an die Zuverlässigkeit und Skalierbarkeit moderner Anwendungen wider.
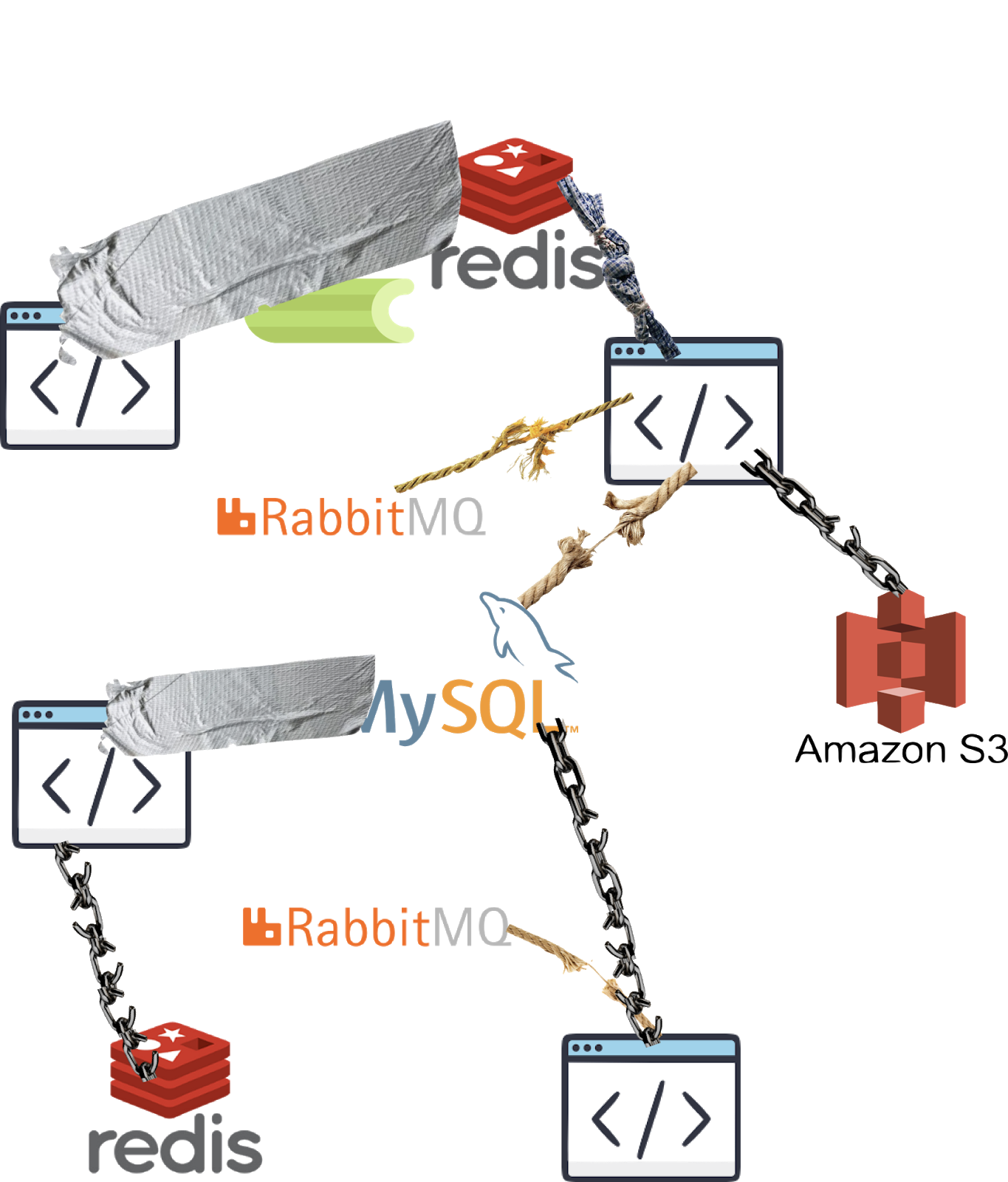
Zeitlich
Jetzt sind wir zu unserer Lösung gekommen. Es wird von Stack Overflow nicht unterstützt, und wir behaupten nicht, perfekt zu sein. Wir möchten nur unsere Ideen teilen und Ihre Meinung hören. Gibt es einen besseren Ort, um Feedback zur Verbesserung Ihres Codes zu erhalten als den Stack?
Bis heute gab es keine Lösung, mit der Sie Microservices verwenden können, ohne die oben beschriebenen Probleme zu lösen. Sie können Absturzzustände testen und emulieren, Code unter Berücksichtigung von Abstürzen schreiben, aber diese Probleme treten weiterhin auf. Wir glauben, dass Temporal sie löst. Es ist eine Open-Source-Umgebung (MIT No-Nonsense) für die Microservice-Orchestrierung.
Temporal besteht aus zwei Hauptkomponenten: einem Stateful-Backend, das in der Datenbank Ihrer Wahl ausgeführt wird, und einem Client-Framework in einer der unterstützten Sprachen. Anwendungen werden mithilfe eines Client-Frameworks und regulären Legacy-Codes erstellt, der Statusänderungen im Backend während der Ausführung automatisch speichert. Sie können dieselben Abhängigkeiten, Bibliotheken und Erstellungsketten verwenden wie beim Erstellen einer anderen Anwendung. Um ehrlich zu sein, ist das Backend stark verteilt, es ist also nicht wie J2EE 2.0. Tatsächlich ermöglicht die Verteilung des Backends eine nahezu unendliche horizontale Skalierung. Temporal verleiht der Anwendungsschicht Konsistenz, Einfachheit und Zuverlässigkeit, ebenso wie die Docker-Infrastruktur, Kubernetes und die serverlose Architektur.
Temporal bietet eine Reihe hochzuverlässiger Mechanismen für die Orchestrierung von Microservices. Das Wichtigste ist jedoch die Erhaltung des Staates. Diese Funktion verwendet die Ereignisausgabe , um alle statusbehafteten Änderungen automatisch an einer laufenden Anwendung zu speichern. Das heißt, wenn der Computer, auf dem Temporal ausgeführt wird, abstürzt, springt der Code automatisch zu einem anderen Computer, als wäre nichts passiert. Dies gilt sogar für lokale Variablen, Ausführungsthreads und andere anwendungsspezifische Zustände.
Lassen Sie mich Ihnen eine Analogie geben. Als Entwickler verlassen Sie sich heute wahrscheinlich auf die SVN-Versionierung (das ist OG Git), um die Änderungen zu verfolgen, die Sie an Ihrem Code vornehmen. SVN speichert nur neue Dateien und verknüpft sie dann mit vorhandenen Dateien, um Doppelarbeit zu vermeiden. Temporal ist so etwas wie SVN (grobe Analogie) für den Status der laufenden Anwendungen. Wenn Ihr Code den Status der Anwendung ändert, speichert Temporal diese Änderung (nicht das Ergebnis) automatisch ohne Fehler. Das heißt, Temporal stellt die abgestürzte Anwendung nicht nur wieder her, sondern rollt sie auch zurück, gabelt sie und macht noch viel mehr. Entwickler müssen also keine Anwendungen mehr mit der Erwartung erstellen, dass der Server abstürzen könnte.
Es ist so, als würde man nach jedem eingegebenen Zeichen vom manuellen Speichern von Dokumenten (Strg + S) zum automatischen Speichern von Clouds in Google Text & Tabellen wechseln. Nicht in dem Sinne, dass Sie nichts mehr manuell speichern, sondern nur, dass diesem Dokument kein Computer mehr zugeordnet ist. Statefulness bedeutet, dass Entwickler viel weniger langweiligen Boilerplate-Code schreiben können, der aufgrund von Microservices geschrieben werden musste. Darüber hinaus benötigen Sie keine spezielle Infrastruktur mehr - separate Warteschlangen, Caches und Datenbanken. Dies erleichtert die Wartung und das Hinzufügen neuer Funktionen. Es macht es auch viel einfacher, Neulinge auf den neuesten Stand zu bringen, da sie den verwirrenden und spezifischen Statusverwaltungscode nicht verstehen müssen.
Die Zustandserhaltung wird in Form von "persistenten Zeitgebern" implementiert. Dies ist ein ausfallsicherer Mechanismus, der mit einem Befehl verwendet werden kann
Workflow.sleep. Es funktioniert genauso wie sleep. Allerdings Workflow.sleepkann es sicher für längere Zeit eingeschläfert werden. Viele temporäre Benutzer haben seit Wochen oder sogar Jahren geschlafen. Dies wird erreicht, indem lang laufende Timer im Temporal Store gespeichert werden und der Code zum Aufwecken verfolgt wird. Auch wenn der Server abstürzt (oder Sie ihn gerade ausgeschaltet haben), wird der Code nach Ablauf des Timers an den verfügbaren Computer gesendet. Schlafprozesse verbrauchen keine Ressourcen, Sie können Millionen davon mit vernachlässigbarem Overhead haben. Es mag zu abstrakt klingen, daher hier ein Beispiel für einen funktionierenden zeitlichen Code:
public class SubscriptionWorkflowImpl implements SubscriptionWorkflow {
private final SubscriptionActivities activities =
Workflow.newActivityStub(SubscriptionActivities.class);
public void execute(String customerId) {
activities.onboardToFreeTrial(customerId);
try {
Workflow.sleep(Duration.ofDays(180));
activities.upgradeFromTrialToPaid(customerId);
while (true) {
Workflow.sleep(Duration.ofDays(30));
activities.chargeMonthlyFee(customerId);
}
} catch (CancellationException e) {
activities.processSubscriptionCancellation(customerId);
}
}
}
Zusätzlich zum dauerhaften Status bietet Temporal eine Reihe von Mechanismen zum Erstellen robuster Anwendungen. Aktivitätsfunktionen werden aus Workflows aufgerufen, aber der in der Aktivität ausgeführte Code ist nicht statusbehaftet. Obwohl sie ihren Status nicht speichern, enthalten Aktivitäten automatische Wiederholungsversuche, Zeitüberschreitungen und Herzschläge. Aktivitäten sind sehr nützlich, um Code zu kapseln, der möglicherweise fehlschlägt. Angenommen, Ihre App verwendet eine Banking-API, die häufig nicht verfügbar ist. Für ältere Software müssen Sie den gesamten Code, der diese API aufruft, mit try / catch-Anweisungen, Wiederholungslogik und Zeitüberschreitungen umschließen. Wenn Sie jedoch die Banking-API von einer Aktivität aus aufrufen, werden alle diese Funktionen sofort bereitgestellt: Wenn der Aufruf fehlschlägt, wird die Aktivität automatisch wiederholt. Es ist alles großartigAber manchmal besitzen Sie selbst einen unzuverlässigen Dienst und möchten ihn vor DDoS schützen. Daher unterstützen Aktivitätsaufrufe auch Zeitüberschreitungen, die durch lange Zeitgeber gesichert werden. Das heißt, die Pausen zwischen Wiederholungen von Aktivitäten können Stunden, Tage oder Wochen erreichen. Dies ist besonders nützlich für Code, der erfolgreich ausgeführt werden muss, aber Sie sind sich nicht sicher, wie schnell dies geschehen muss.
Dieses Video erklärt das zeitliche Programmiermodell in zwei Minuten:
Eine weitere Stärke von Temporal ist die Beobachtbarkeit der laufenden Anwendung. Die Beobachtungs-API bietet eine SQL-ähnliche Schnittstelle zum Abfragen von Metadaten aus einem beliebigen Workflow (ausführbar oder nicht). Sie können auch direkt innerhalb des Prozesses Ihre eigenen Metadatenwerte definieren und aktualisieren. Die Beobachtungs-API ist für temporäre Operatoren und Entwickler sehr nützlich, insbesondere beim Debuggen während der Entwicklung. Die Überwachung unterstützt sogar Stapelaktionen für Abfrageergebnisse. Sie können beispielsweise ein Kill-Signal an alle Worker-Prozesse senden, die einer Anforderung mit einer Erstellungszeit> gestern entsprechen. Temporal unterstützt eine synchrone Abruffunktion, mit der Sie die Werte lokaler Variablen aus laufenden Instanzen abrufen können. Es ist, als hätte ein Debugger aus Ihrer IDE mit Produktionsanwendungen gearbeitet. Auf diese Weise können Sie beispielsweise den Wert ermitteln
greeting in einer laufenden Instanz:
public static class GreetingWorkflowImpl implements GreetingWorkflow {
private String greeting;
@Override
public void createGreeting(String name) {
greeting = "Hello " + name + "!";
Workflow.sleep(Duration.ofSeconds(2));
greeting = "Bye " + name + "!";
}
@Override
public String queryGreeting() {
return greeting;
}
}
Fazit
Microservices sind großartig und kosten Produktivität und Zuverlässigkeit, die Entwickler und Unternehmen zahlen. Temporal wurde entwickelt, um dieses Problem zu lösen, indem eine Umgebung bereitgestellt wird, in der Microservices für Entwickler bezahlt werden. Out-of-the-Box-Status, automatische Fehler und Watchdogs sind nur einige der Funktionen, die Temporal für die intelligente Entwicklung von Microservices bietet.