- Lass uns anfangen. Ich werde Sie über die bequeme Protokollierung und die Infrastruktur rund um die Protokollierung informieren, die Sie bereitstellen können, damit Sie bequem mit Ihrer Anwendung und ihrem Lebenszyklus leben können.

Was machen wir? Wir werden eine kleine Anwendung erstellen, unser Startup. Dann werden wir die grundlegende Anmeldung implementieren. Dies ist ein kleiner Teil des Berichts, den Python sofort bereitstellt. Und dann der größte Teil - wir werden die typischen Probleme analysieren, auf die wir beim Debuggen, Roll-out und Tools zu deren Lösung stoßen.
Kleiner Haftungsausschluss: Ich werde Wörter wie Stift und Gebietsschema verwenden. Lassen Sie mich erklären. "Handle" ist möglicherweise Yandex-Slang. Es bezeichnet Ihre API, http oder gRPC-API oder andere Buchstabenkombinationen vor der APU. "Gebietsschema" ist, wenn ich auf einem Laptop entwickle. Es scheint, dass ich über alle Wörter erzählt habe, die ich nicht kontrolliere.
Buchhandlungsanwendung
Lasst uns beginnen. Unser Startup ist der Bookstore. Das Hauptmerkmal dieser Anwendung wird der Verkauf von Büchern sein, das ist alles, was wir tun wollen. Dann etwas Füllung. Die Bewerbung wird in Flask geschrieben. Alle Codefragmente und Tools sind generisch und von Python abstrahiert, sodass sie in die meisten Ihrer Anwendungen integriert werden können. Aber in unserem Gespräch wird es Flask sein.
Charaktere: ich, der Entwickler, die Manager und mein geliebter Kollege Erast. Zufälle sind zufällig.
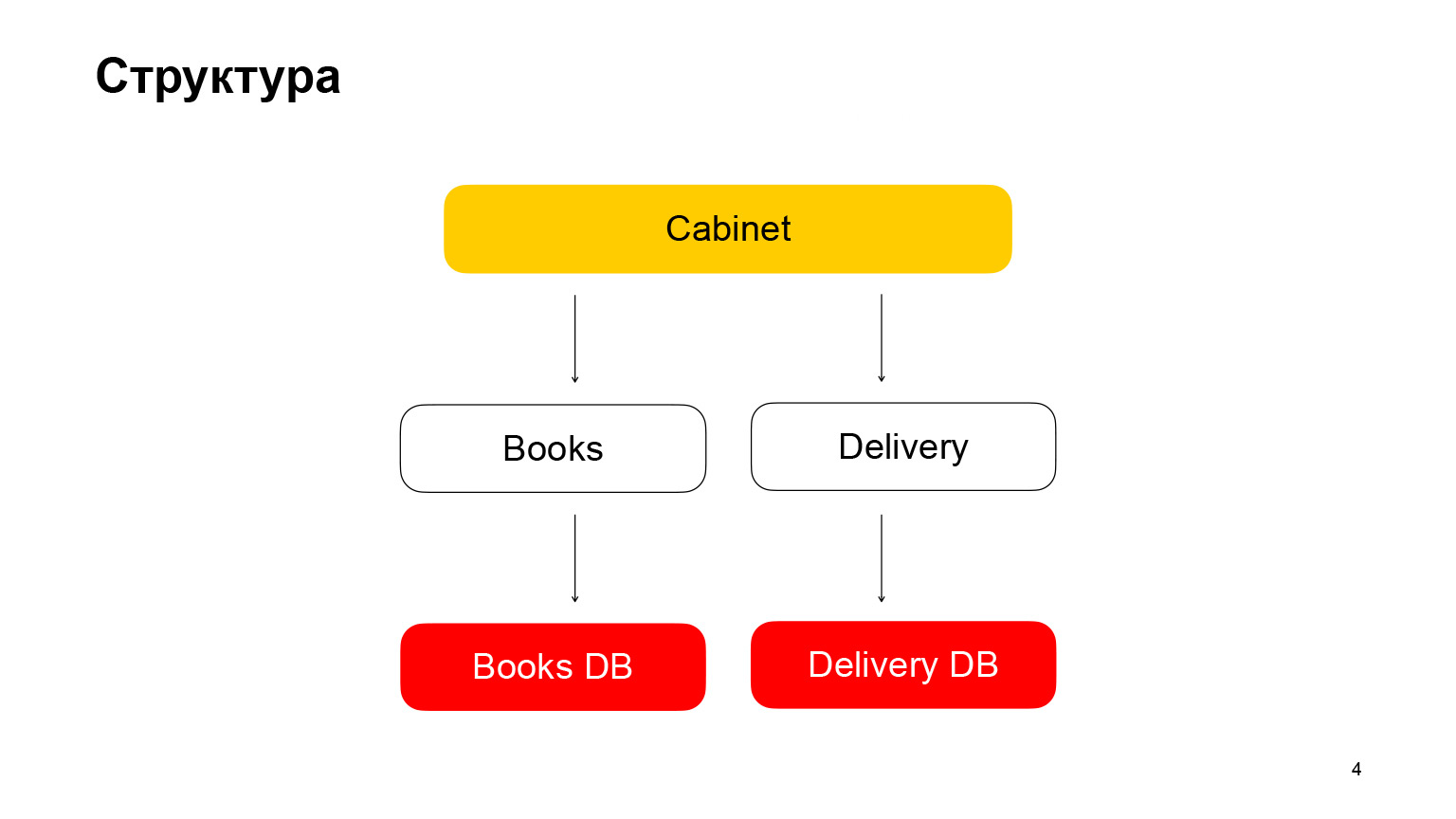
Lassen Sie uns ein wenig über die Struktur sprechen. Es ist eine Mikroservice-Architekturanwendung. Der erste Dienst ist Books, ein Buchspeicher mit Buchmetadaten. Es verwendet die PostgreSQL-Datenbank. Der zweite Microservice ist ein Liefer-Microservice, der Metadaten zu Benutzeraufträgen speichert. Cabinet ist das Backend für das Cabinet. Wir haben kein Frontend, es wird in unserem Bericht nicht benötigt. Das Kabinett fasst Anfragen, Daten aus dem Buchservice und dem Lieferservice zusammen.

Ich werde Ihnen schnell den Code für die Handles dieser Dienste, API-Bücher, zeigen. Dieses Handle erfasst Daten aus der Datenbank, serialisiert sie, wandelt sie in JSON um und gibt sie zurück.

Gehen wir weiter. Lieferservice. Der Griff ist genau der gleiche. Wir holen die Daten aus der Datenbank, serialisieren sie und senden sie.

Und der letzte Knopf ist der Schrankknopf. Es hat etwas anderen Code. Das Kabinettshandle fordert Daten vom Lieferservice und vom Buchservice an, aggregiert die Antworten und gibt dem Benutzer seine Bestellungen. Alles. Wir haben die Struktur der Anwendung schnell herausgefunden.
Grundlegende Protokollierung in der Anwendung
Lassen Sie uns nun über die grundlegende Protokollierung sprechen, die wir eingesägt haben. Beginnen wir mit der Terminologie.

Was gibt uns Python? Vier grundlegende Hauptentitäten:
- Logger, der Einstiegspunkt für die Anmeldung Ihres Codes. Sie werden eine Art Logger verwenden, logging.INFO schreiben und fertig. Ihr Code weiß nichts mehr darüber, wohin die Nachricht ging und was als nächstes damit passiert ist. Die Handler-Entität ist bereits dafür verantwortlich.
- Der Handler verarbeitet Ihre Nachricht und entscheidet, wohin sie gesendet werden soll: an die Standardausgabe, an eine Datei oder an die E-Mail eines anderen.
- Filter ist eine von zwei Hilfseinheiten. Entfernt Nachrichten aus dem Protokoll. Ein weiterer häufiger Anwendungsfall ist das Füllen von Daten. In Ihrem Beitrag müssen Sie beispielsweise ein Attribut hinzufügen. Filter kann auch hier helfen.
- Der Formatierer bringt Ihre Nachricht in die gewünschte Form.

Hier haben wir die Terminologie fertiggestellt. Wir werden nicht mehr direkt in Python mit Basisklassen protokollieren. Hier ist ein Beispiel für die Konfiguration unserer Anwendung, die für alle drei Dienste bereitgestellt wird. Für uns gibt es zwei wichtige Hauptblöcke: Formatierer und Handler. Für Formatierer gibt es ein Beispiel, das Sie hier sehen können, eine Vorlage für die Anzeige der Nachricht.
In den Handlern sehen Sie die Protokollierung. StreamHandler wird verwendet. Das heißt, wir speichern alle unsere Protokolle in der Standardausgabe. Das war's, wir sind fertig damit.
Problem 1. Protokolle sind verstreut
Weiter zu den Problemen. Zunächst das erste Problem: Die Protokolle sind verstreut.
Ein bisschen Kontext. Wir haben unsere Bewerbung geschrieben, die Süßigkeiten sind schon fertig. Wir können damit Geld verdienen. Wir rollen es in die Produktion aus. Natürlich gibt es mehr als einen Server. Nach unseren vorsichtigen Schätzungen benötigt unsere komplexeste Anwendung etwa drei oder vier Autos usw. für jeden Service.
Nun die Frage. Der Manager kommt zu uns gerannt und fragt: "Es ist dort kaputt, Hilfe!" Du läufst. Alles ist für Sie protokolliert, es ist großartig. Sie gehen zur ersten Schreibmaschine, schauen Sie - es gibt nichts für Ihre Anfrage. Geh zum zweiten Auto - nichts. Usw. Das ist schlecht, es muss irgendwie gelöst werden.

Lassen Sie uns das gewünschte Ergebnis formalisieren. Ich möchte, dass sich die Protokolle an einem Ort befinden. Dies ist eine einfache Anforderung. Ein bisschen cooler ist, dass ich die Protokolle durchsuchen möchte. Das heißt, ja, es liegt an einer Stelle und ich kann rippen, aber es wäre cool, wenn es einige Werkzeuge gäbe, coole Funktionen neben einem einfachen Grap.
Und ich will nicht schreiben. Dies ist Erast, der gerne Code schreibt. Ich spreche nicht darüber, ich habe sofort ein Produkt gemacht. Das heißt, Sie möchten weniger zusätzlichen Code, kommen mit ein oder zwei Dateien, Zeilen aus und das wars.

Die Lösung, die verwendet werden kann, ist Elasticsearch. Versuchen wir es zu erhöhen. Was sind die Vorteile von Elasticsearch? Dies ist eine Protokollsuchoberfläche. Es gibt eine sofort einsatzbereite Schnittstelle. Dies ist keine Konsole für Sie, sondern der einzige Speicherplatz. Das heißt, wir haben die Hauptanforderung erfüllt. Wir müssen nicht zu Servern gehen.
In unserem Fall handelt es sich um eine recht einfache Integration. Mit der jüngsten Version verfügt Elasticsearch über einen neuen Agenten, der für die meisten Integrationen verantwortlich ist. Sie haben dort selbst in die Integration gesägt. Sehr cool. Ich habe vorhin einen Vortrag geschrieben und Filebeat verwendet, genauso einfach. Es ist einfach für Protokolle.
Ein bisschen über Elasticsearch. Ich möchte keine Werbung schalten, aber es gibt viele zusätzliche Funktionen. Das Coole ist beispielsweise die sofort einsatzbereite Volltext-Protokollsuche. Klingt sehr cool. Diese Vorteile reichen uns vorerst aus. Wir befestigen es.
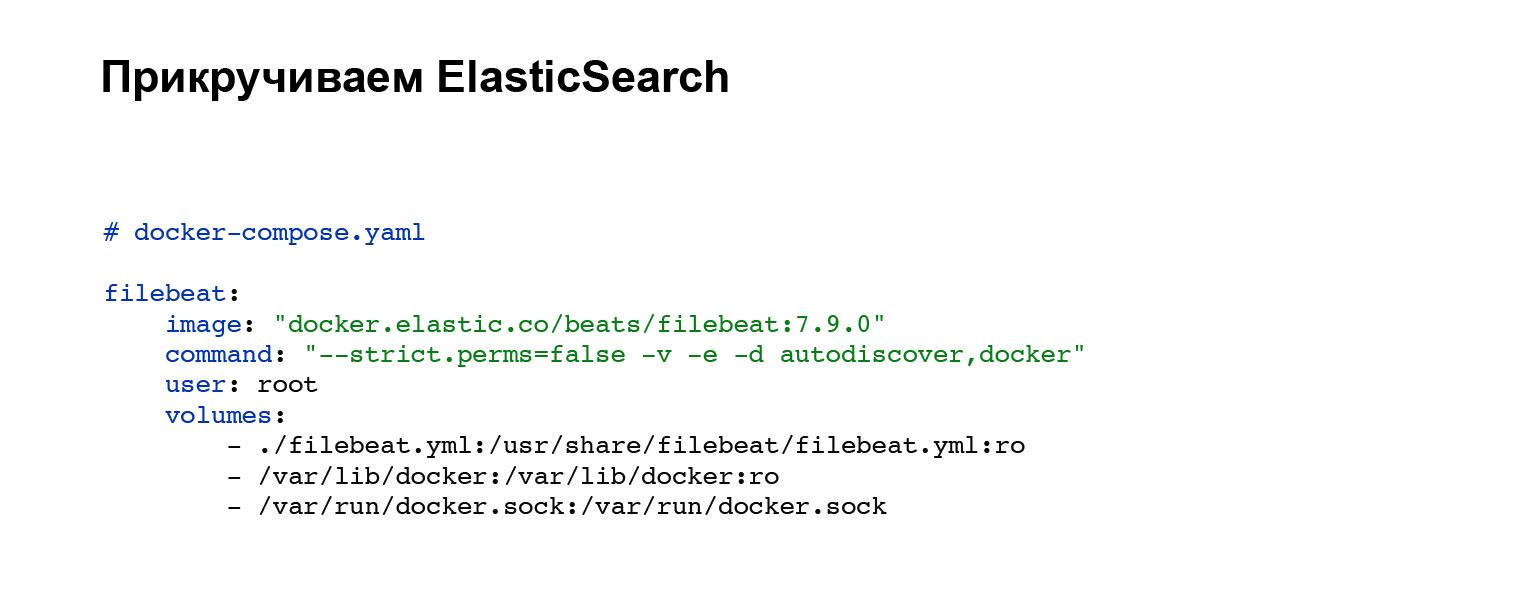
Zunächst müssen wir einen Agenten bereitstellen, der unsere Protokolle an Elasticsearch sendet. Sie registrieren ein Konto bei Elasticsearch und fügen es dann Ihrem Docker-Compose hinzu. Wenn Sie kein Docker-Compose haben, können Sie mit Handles oder auf Ihrem System erhöhen. In unserem Fall wird der folgende Codeblock hinzugefügt, die Integration in Docker-Compose. Alles, der Dienst ist konfiguriert. Und Sie können die Konfigurationsdatei filebeat.yml im Volume-Block sehen.

Hier ist ein Beispiel für filebeat.yml. Hier haben wir eine automatische Suche nach den Protokollen von Docker-Containern eingerichtet, die sich in der Nähe drehen. Die Auswahl dieser Protokolle wurde angepasst. Je nach Bedingung können Sie Etiketten festlegen und an Ihre Container hängen. Abhängig davon werden Ihre Protokolle nur von bestimmten Containern gesendet. Der Block Prozessoren: add_docker_metadata ist einfach. Wir fügen den Protokollen ein wenig mehr Informationen zu Ihren Protokollen im Docker-Kontext hinzu. Optional, aber cool.
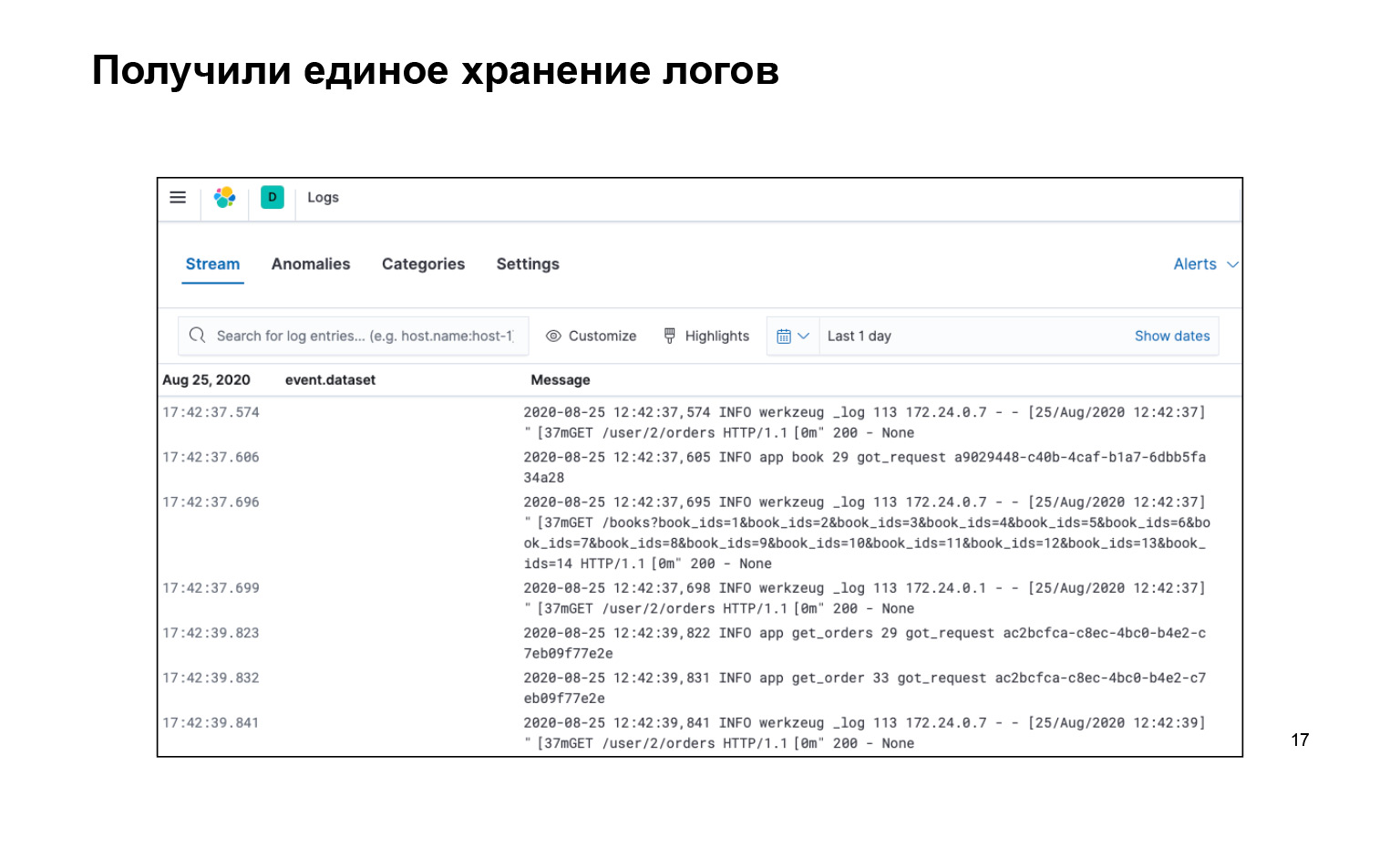
Was haben wir bekommen? Das ist alles was wir geschrieben haben, der ganze Code, sehr cool. Gleichzeitig haben wir alle Protokolle an einem Ort und es gibt eine Schnittstelle. Wir können unsere Protokolle durchsuchen, hier ist die Suchleiste. Sie werden geliefert. Und Sie können es sogar live einschalten, sodass der Stream zu unseren Protokollen in der Benutzeroberfläche fliegt, und wir haben es gesehen.

Hier hätte ich selbst gefragt: warum, wie man etwas anschnallt? Was ist eine Protokollsuche, was kann dort gemacht werden?
Ja, bei diesem Ansatz gibt es sofort einen kleinen Gag, wenn wir über Textprotokolle verfügen: Wir können eine Anforderung anhand des Textes festlegen, z. B. Nachricht: Benutzer. Dadurch werden alle Protokolle gedruckt, die die Teilzeichenfolge des Benutzers enthalten. Sie können Sternchen verwenden, die meisten anderen Unix-Platzhalter. Aber es scheint, dass dies nicht genug ist. Ich möchte es schwieriger machen, damit Sie sich in Nginx früher aufwärmen können, so wie wir können.

Lassen Sie uns ein wenig von Elasticsearch zurücktreten und versuchen, dies nicht mit Elasticsearch, sondern mit einem anderen Ansatz zu tun. Betrachten wir strukturelle Protokolle. In diesem Fall ist jeder Ihrer Protokolleinträge nicht nur eine Textzeile, sondern ein serialisiertes Objekt mit Attributen, die jedes System eines Drittanbieters serialisieren kann, um ein fertiges Objekt zu erhalten.
Was sind die Vorteile davon? Es ist ein einheitliches Datenformat. Ja, Objekte können unterschiedliche Attribute haben, aber jedes externe System kann JSON lesen und eine Art Objekt abrufen.
Eine Art Tippen. Dies vereinfacht die Integration mit anderen Systemen: Deserialisierer müssen nicht geschrieben werden. Und nur Deserialisierer sind ein weiterer Punkt. Sie müssen keine prosaischen Texte in die Anwendung schreiben. Beispiel: "Benutzer kam mit so und so einem ID-Spezialisten, mit so und so einer Bestellung." Und das alles muss jedes Mal geschrieben werden.
Es hat mich gestört. Ich möchte schreiben: "Eine Anfrage ist eingetroffen." Weiter: "So und so, so und so, so und so", sehr einfach, sehr IT-artig.

Lass uns weitermachen. Lassen Sie uns zustimmen: Wir werden uns im JSON-Format anmelden, dies ist ein einfaches Format. Elasticsearch wird sofort unterstützt, Filebeat, den wir serialisieren und zu archivieren versuchen. Es ist nicht sehr schwierig. Zunächst fügen Sie die Einstellungsdatei aus der Pythonjsonlogger-Bibliothek zum JSONFormatter-Formatierungsblock hinzu, in dem die Konfiguration gespeichert wird. Dies kann ein anderer Ort in Ihrem System sein. Und dann übergeben Sie im Formatattribut, welche Attribute Sie Ihrem Objekt hinzufügen möchten.
Der folgende Block ist ein Konfigurationsblock, der zu filebeat.yml hinzugefügt wird. Hier gibt es sofort eine Filebeat-Schnittstelle zum Parsen von JSON-Protokollen. Sehr cool. Das ist alles. Sie müssen dafür nichts anderes schreiben. Und jetzt sehen Ihre Protokolle wie Objekte aus.
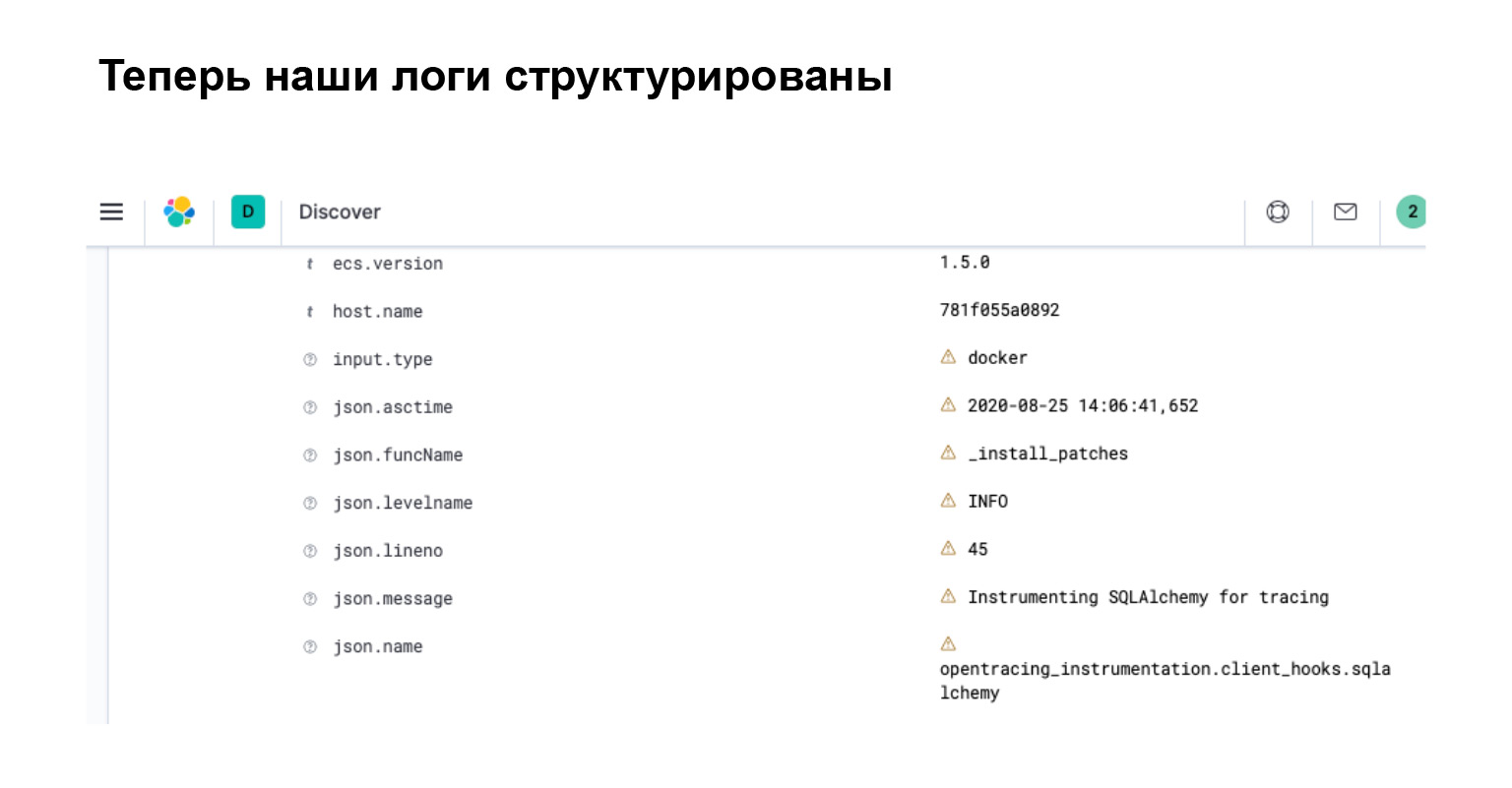
Was haben wir in Elasticsearch bekommen? In der Benutzeroberfläche können Sie sofort erkennen, dass Ihr Protokoll zu einem Objekt mit separaten Attributen geworden ist, mit denen Sie suchen, Filter erstellen und komplexe Abfragen durchführen können.

Fassen wir zusammen. Jetzt haben unsere Protokolle eine Struktur. Sie sind einfach zu bedienen und können zum Schreiben intelligenter Abfragen verwendet werden. Elasticsearch ist sich dieser Struktur bewusst, da alle diese Attribute analysiert wurden. In Kibana, einer Schnittstelle für Elasticsearch, können Sie solche Protokolle mithilfe einer von Elasticsearch bereitgestellten speziellen Abfragesprache filtern.
Und es ist einfacher als Paddeln. Grep hat eine ziemlich komplizierte und coole Sprache. Es gibt viel zu schreiben. In Kibana können viele Dinge einfacher gemacht werden. Damit aussortiert.
Problem 2. Bremsen
Das nächste Problem sind die Bremsen. In der Microservice-Architektur gibt es immer und überall Bremsen.

Hier ist ein kleiner Kontext, ich erzähle Ihnen eine Geschichte. Der Manager, die Hauptfigur unseres Projekts, kommt zu mir gerannt und sagt: „Hey, das Büro wird langsamer! Danya, rette, hilf! "
Wir wissen noch nichts, wir klettern in unsere Protokolle in Elasticsearch. Aber lassen Sie mich Ihnen sagen, was tatsächlich passiert ist.

Erast hat eine Funktion hinzugefügt. In Büchern zeigen wir jetzt nicht die ID des Autors, sondern seinen Namen direkt in der Benutzeroberfläche an. Sehr cool. Er hat es mit dem folgenden Code gemacht. Ein kleines Stück Code, nichts kompliziertes. Was könnte schiefgehen?
Mit einem geschulten Auge können Sie sagen, dass Sie dies mit SQLAlchemy und auch mit einem anderen ORM nicht tun können. Sie müssen einen Pre-Cache oder etwas anderes ausführen, damit Sie nicht mit einer kleinen Unterabfrage in einer Schleife zur Datenbank wechseln. Ein unangenehmes Problem. Es scheint, dass ein solcher Fehler überhaupt nicht erlaubt sein sollte.
Lass mich dir sagen. Ich hatte Erfahrung: Wir haben mit Django gearbeitet und in unserem Projekt einen benutzerdefinierten Pre-Cache implementiert. Viele Jahre lang lief alles gut. Irgendwann haben Erast und ich beschlossen: Lasst uns mit der Zeit gehen und Django aktualisieren. Natürlich weiß Django nichts über unseren benutzerdefinierten Cache und die Benutzeroberfläche hat sich geändert. Prikash fiel lautlos ab. Dies wurde nicht in Tests gefangen. Das gleiche Problem, es war nur schwieriger zu fangen.
Was ist das Problem? Wie kann ich Ihnen bei der Lösung des Problems helfen?

Lassen Sie uns Ihnen sagen, was ich getan habe, bevor ich das Problem der Bremsenfindung gelöst habe.
Das erste, was ich mache, ist, zu Elasticsearch zu gehen. Wir haben es bereits. Es hilft, es besteht keine Notwendigkeit, um die Server herumzulaufen. Ich gehe zu den Protokollen und suche nach den Schrankprotokollen. Ich finde lange Fragen. Ich spiele es auf einem Laptop und sehe, dass es nicht das Büro ist, das sich zurückhält. Verlangsamt Bücher.
Ich stoße auf die Bücherprotokolle, finde problematische Fragen - tatsächlich haben wir sie bereits. Ich reproduziere Bücher auf die gleiche Weise auf einem Laptop. Sehr komplizierter Code - ich verstehe nichts. Ich fange an zu debuggen. Timings sind ziemlich schwer zu fangen. Warum? Es ist ziemlich schwierig, dies intern in SQLAlchemy zu definieren. Ich schreibe benutzerdefinierte Zeitlogger, lokalisiere und behebe das Problem.
Es tat mir weh. Schwierig, unangenehm. Ich weinte. Ich möchte, dass dieser Prozess, ein Problem zu finden, schneller und bequemer ist.
Lassen Sie uns unsere Probleme formalisieren. Es ist schwierig, die Protokolle nach Verlangsamungen zu durchsuchen, da unser Protokoll ein Protokoll nicht verwandter Ereignisse ist. Wir müssen benutzerdefinierte Timer schreiben, die uns zeigen, wie viele Codeblöcke ausgeführt wurden. Darüber hinaus ist nicht klar, wie die Timings externer Systeme protokolliert werden sollen: z. B. ORM oder Anforderungsbibliotheken. Wir müssen unsere Timer in oder mit einer Art Wrapper einbetten, aber wir werden nicht herausfinden, warum es im Inneren langsamer wird. Kompliziert.

Eine gute Lösung, die ich gefunden habe, ist Jaeger. Dies ist eine Implementierung des Opentracing-Protokolls. Implementieren wir also die Ablaufverfolgung.
Was gibt Jaeger? Es ist eine benutzerfreundliche Oberfläche mit Suchanfragen. Sie können lange Abfragen filtern oder nach Tags ausführen. Eine visuelle Darstellung des Anforderungsflusses, ein sehr schönes Bild, werde ich etwas später zeigen.
Timings werden sofort abgemeldet. Sie müssen nichts mit ihnen machen. Wenn Sie überprüfen müssen, wie viel von einem benutzerdefinierten Block ausgeführt wird, können Sie ihn in von Jaeger bereitgestellte Timer einschließen. Sehr bequem.
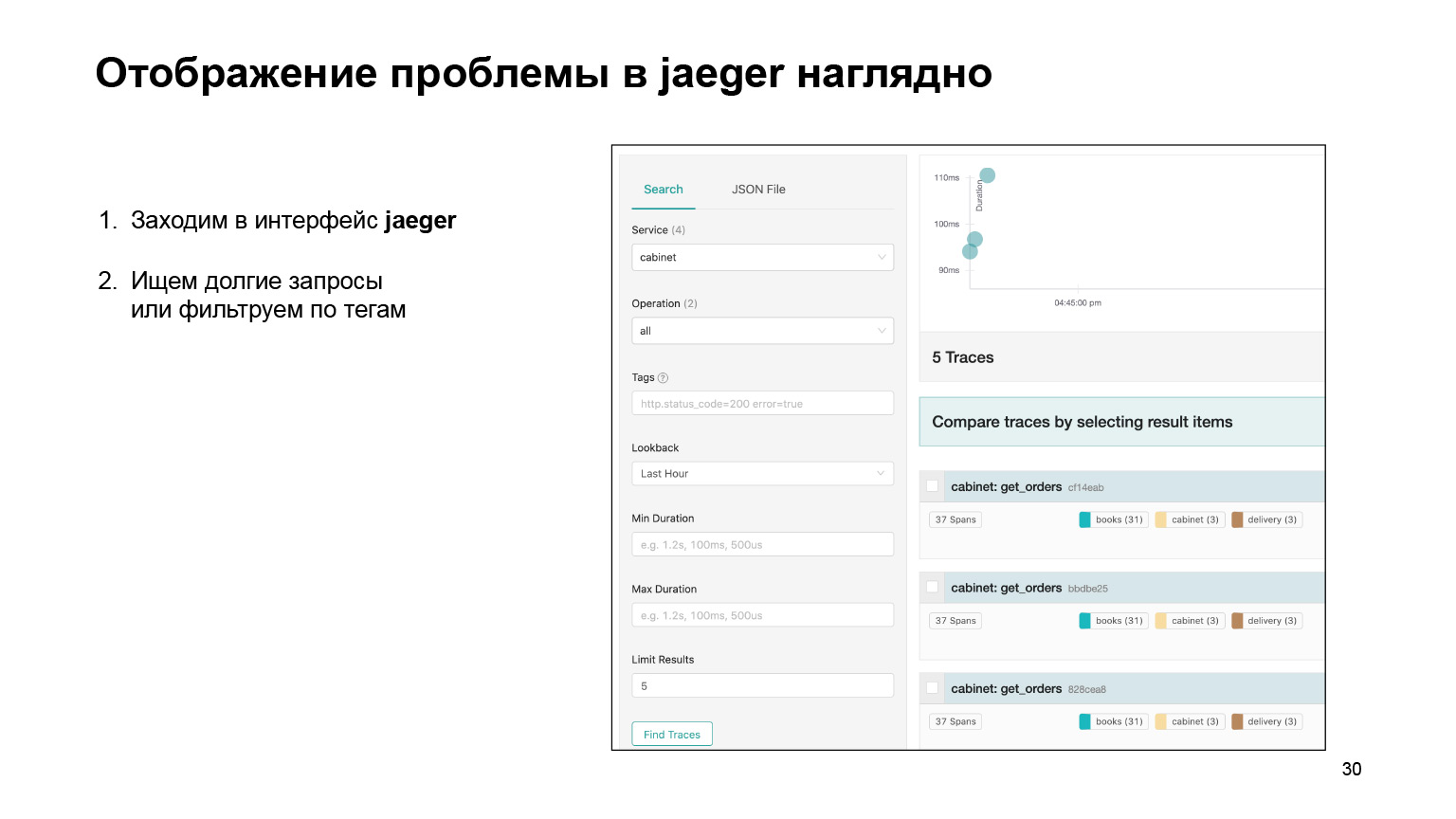
Mal sehen, wie es möglich war, das Problem in der Schnittstelle zu finden und dort zu lokalisieren. Wir gehen in die Jaeger-Oberfläche. So sehen unsere Anfragen aus. Wir können nach Anfragen für ein Konto oder einen anderen Dienst suchen. Wir filtern sofort lange Anfragen. Wir interessieren uns für die langen, sie sind ziemlich schwer aus den Protokollen zu finden. Wir bekommen ihre Liste.
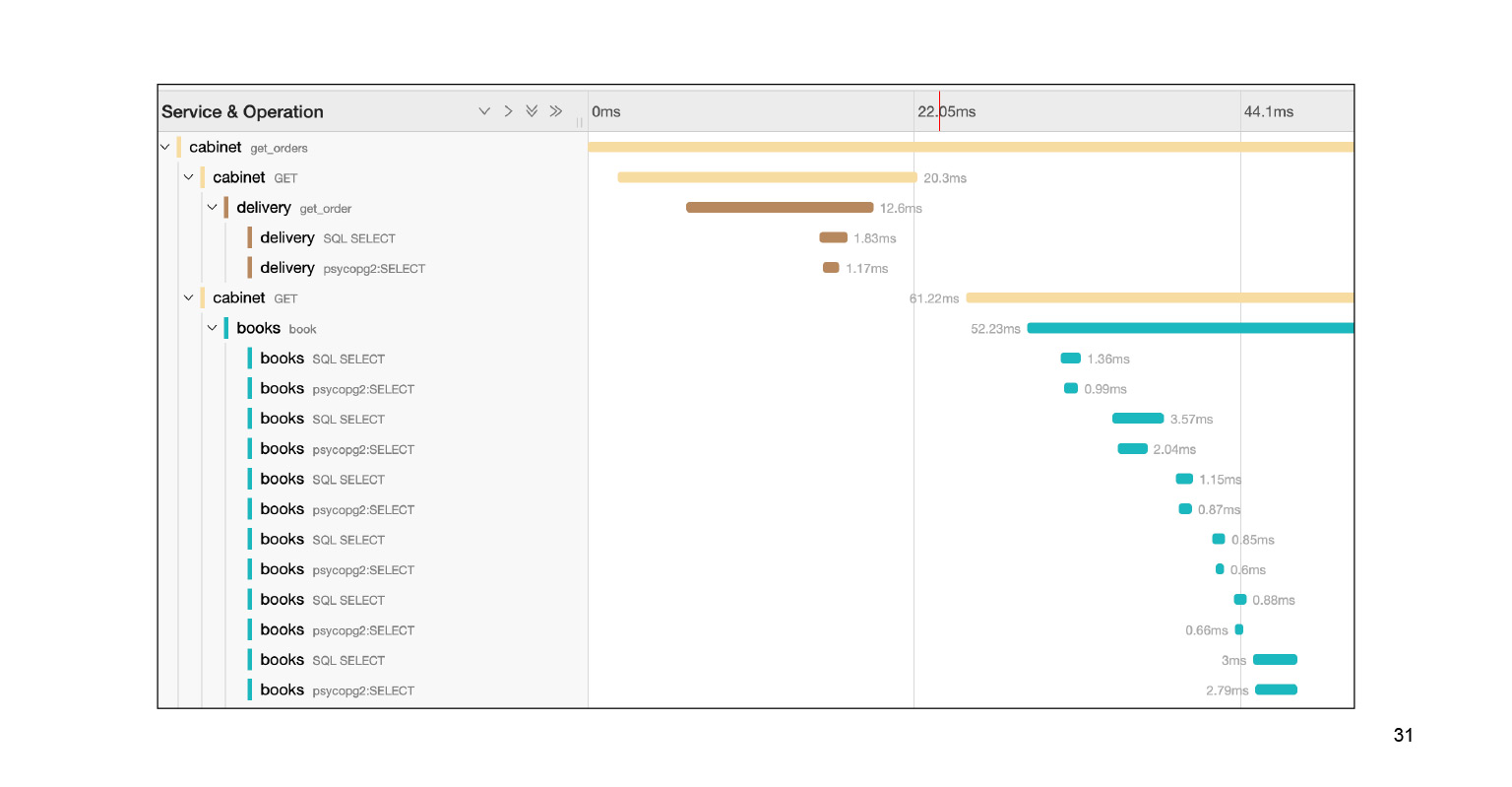
Wir fallen in diese Abfrage und sehen eine große Anzahl von SQL-Unterabfragen. Wir können deutlich sehen, wie sie rechtzeitig ausgeführt wurden, welcher Codeblock für was verantwortlich war. Sehr cool. Darüber hinaus ist dies im Zusammenhang mit unserem Problem nicht das gesamte Protokoll. Es gibt ein weiteres großes Fußtuch, zwei oder drei Rutschen nach unten. Wir haben das Problem in Jaeger ziemlich schnell lokalisiert. Was kann uns der von Jaeger bereitgestellte Kontext nach der Lösung des Problems helfen?
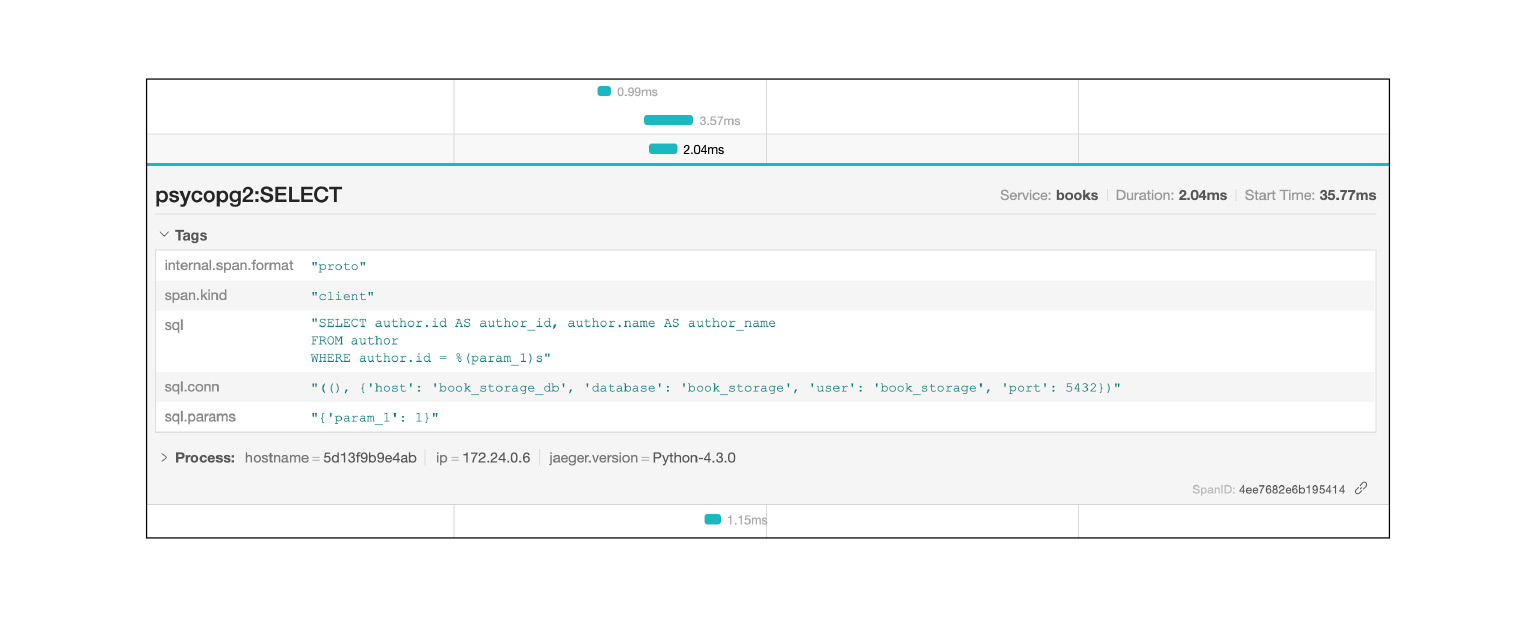
Jaeger protokolliert beispielsweise SQL-Abfragen: Sie können sehen, welche Abfragen wiederholt werden. Sehr schnell und cool.
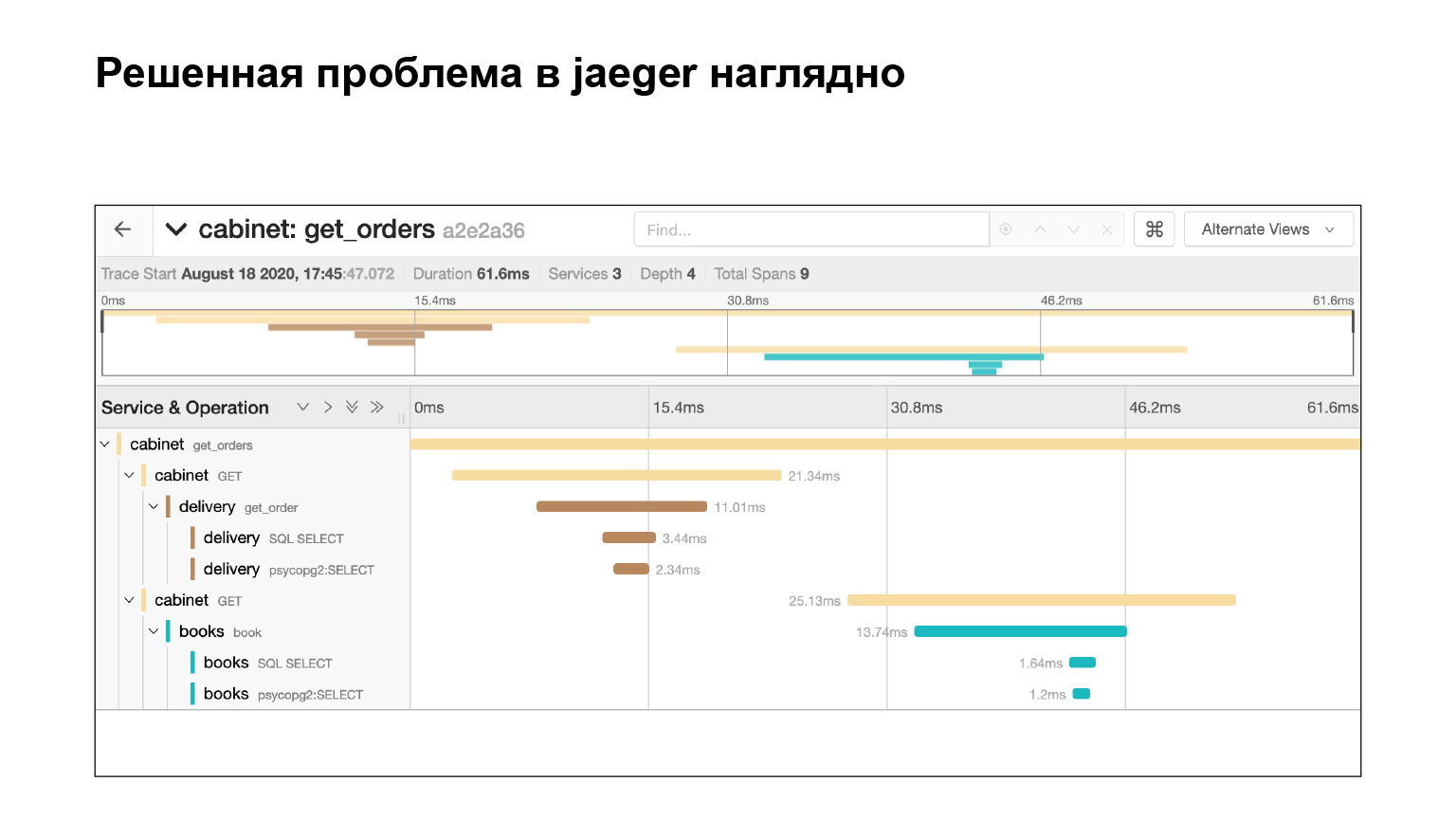
Wir haben das Problem gelöst und sehen sofort in Jaeger, dass alles in Ordnung ist. Wir überprüfen mit derselben Abfrage, dass wir jetzt keine Unterabfragen haben. Warum? Angenommen, wir überprüfen dieselbe Anforderung und ermitteln das Timing. Sehen Sie in Elasticsearch nach, wie lange die Anforderung ausgeführt wurde. Dann werden wir die Zeit sehen. Dies garantiert jedoch nicht, dass keine Unterabfragen vorhanden waren. Und hier sehen wir es, cool.

Lassen Sie uns Jaeger implementieren. Es wird nicht viel Code benötigt. Sie fügen Abhängigkeiten für Opentracing für Flask hinzu. Nun zu dem Code, den wir machen.
Der erste Codeblock ist das Jaeger-Client-Setup.
Dann richten wir die Integration mit Flask, Django oder einem anderen Framework mit Integration ein.
install_all_patches ist die allerletzte und interessanteste Codezeile. Wir patchen die meisten externen Integrationen durch Interaktion mit MySQL, Postgres, Anforderungsbibliothek. Wir patchen all dies und deshalb sehen wir in der Jaeger-Oberfläche sofort alle Abfragen mit SQL und welche der Dienste, zu denen unser erforderlicher Dienst gegangen ist. Sehr cool. Und du musstest nicht viel schreiben. Wir haben gerade install_all_patches geschrieben. Magie!
Was haben wir bekommen? Jetzt müssen Sie keine Ereignisse mehr aus Protokollen sammeln. Wie gesagt, Protokolle sind unterschiedliche Ereignisse. In Jaeger ist dies ein großes Ereignis, dessen Struktur Sie sehen. Mit Jaeger können Sie Engpässe in Ihrer Anwendung erkennen. Sie suchen nur nach langen Abfragen und können analysieren, was falsch läuft.
Problem 3. Fehler
Das letzte Problem sind Fehler. Ja, ich bin gerissen. Ich werde Ihnen nicht helfen, Fehler in der Anwendung zu beseitigen, aber ich werde Ihnen sagen, was Sie als nächstes tun können.

Kontext. Sie können sagen: „Danya, wir protokollieren Fehler, wir haben Warnungen für fünfhundert, wir haben sie konfiguriert. Was willst du? Wir haben uns angemeldet, wir haben uns angemeldet und wir werden uns anmelden und debuggen.
Sie kennen die Wichtigkeit des Fehlers nicht aus den Protokollen. Was ist wichtig? Hier haben Sie einen coolen Fehler und den Fehler beim Herstellen einer Verbindung zur Datenbank. Die Basis floppte gerade. Ich möchte sofort sehen, dass dieser Fehler nicht so wichtig ist, und wenn keine Zeit ist, ignorieren Sie ihn, aber beheben Sie den wichtigeren.
Die Fehlerrate ist ein Kontext, der uns beim Debuggen helfen kann. Wie verfolge ich Fehler? Fahren wir fort, wir hatten vor einem Monat einen Fehler und jetzt erscheint er wieder. Ich möchte sofort eine Lösung finden und korrigieren oder ihr Erscheinungsbild mit einer der Versionen vergleichen.
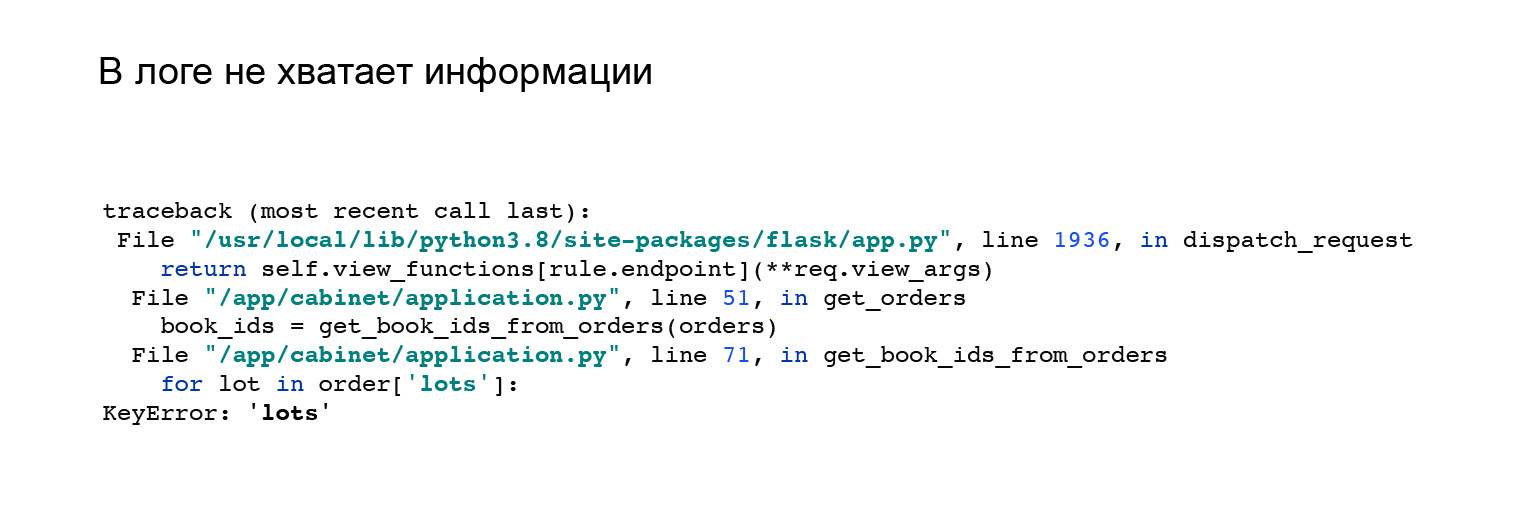
Hier ist ein gutes Beispiel. Als ich die Integration mit Jaeger sah, habe ich meine API ein wenig geändert. Ich habe das Format der Anwendungsantwort geändert. Ich habe diesen Fehler bekommen. Aber es ist nicht klar, warum ich keinen Schlüssel habe, viele im Bestellobjekt, und es gibt nichts, was mir helfen würde. Sehen Sie sich den Fehler hier an, reproduzieren Sie ihn und fangen Sie ihn selbst ab.

Lassen Sie uns Wachposten implementieren. Dies ist ein Bug-Tracker, der uns hilft, ähnliche Probleme zu lösen und den Kontext des Fehlers zu finden. Nehmen Sie die Standardbibliothek, die von den Sentry-Entwicklern verwaltet wird. In vier Codezeilen fügen wir es unserer Anwendung hinzu. Alles.
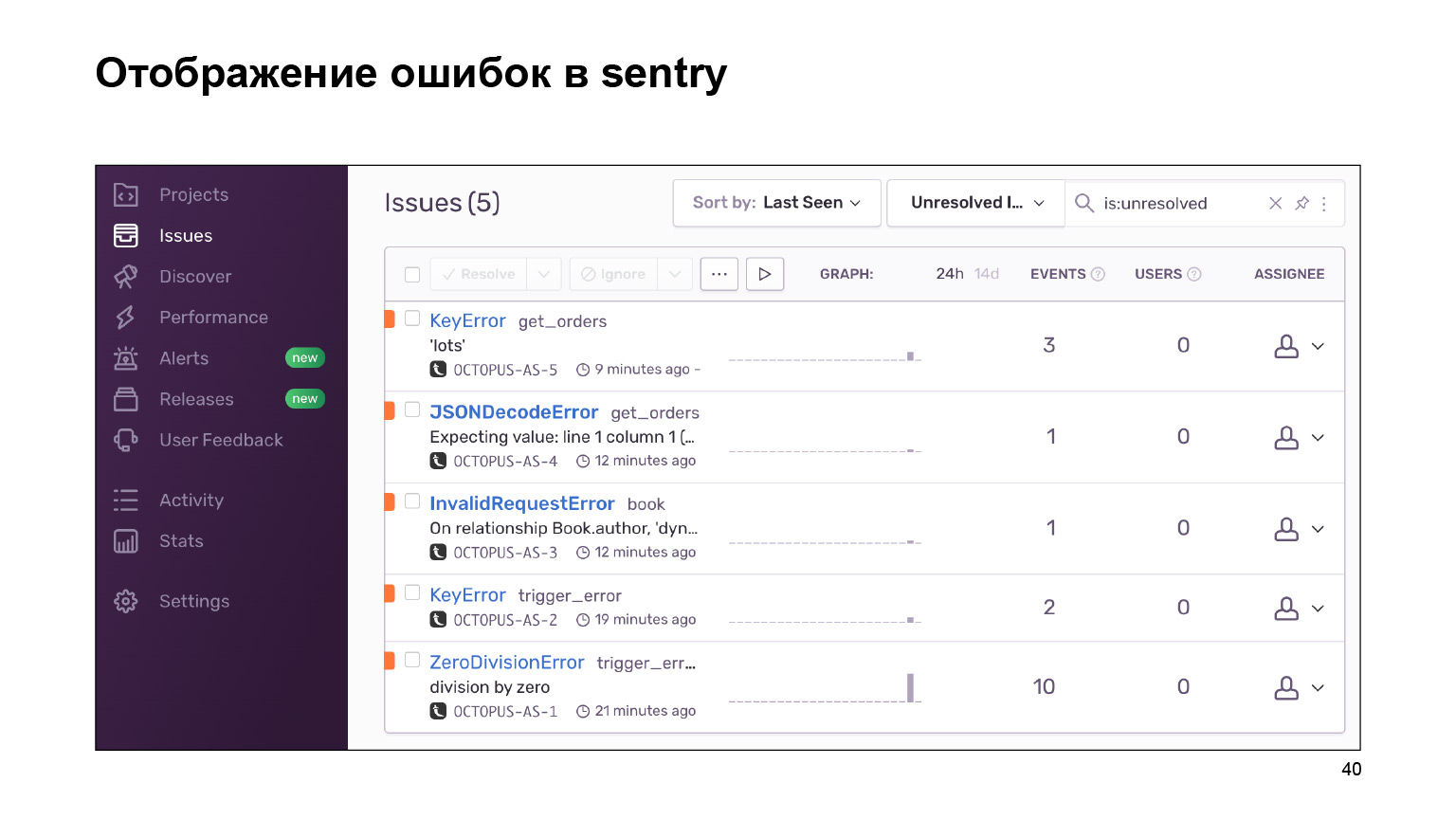
Was haben wir auf dem Weg nach draußen bekommen? Hier ist ein Dashboard mit Fehlern, die nach Projekt gruppiert werden können und denen Sie folgen können. Eine riesige Anzahl von Fehlerprotokollen ist in identische, ähnliche Protokolle gruppiert. Statistiken werden über sie bereitgestellt. Und Sie können diese Fehler auch über die Benutzeroberfläche beheben.
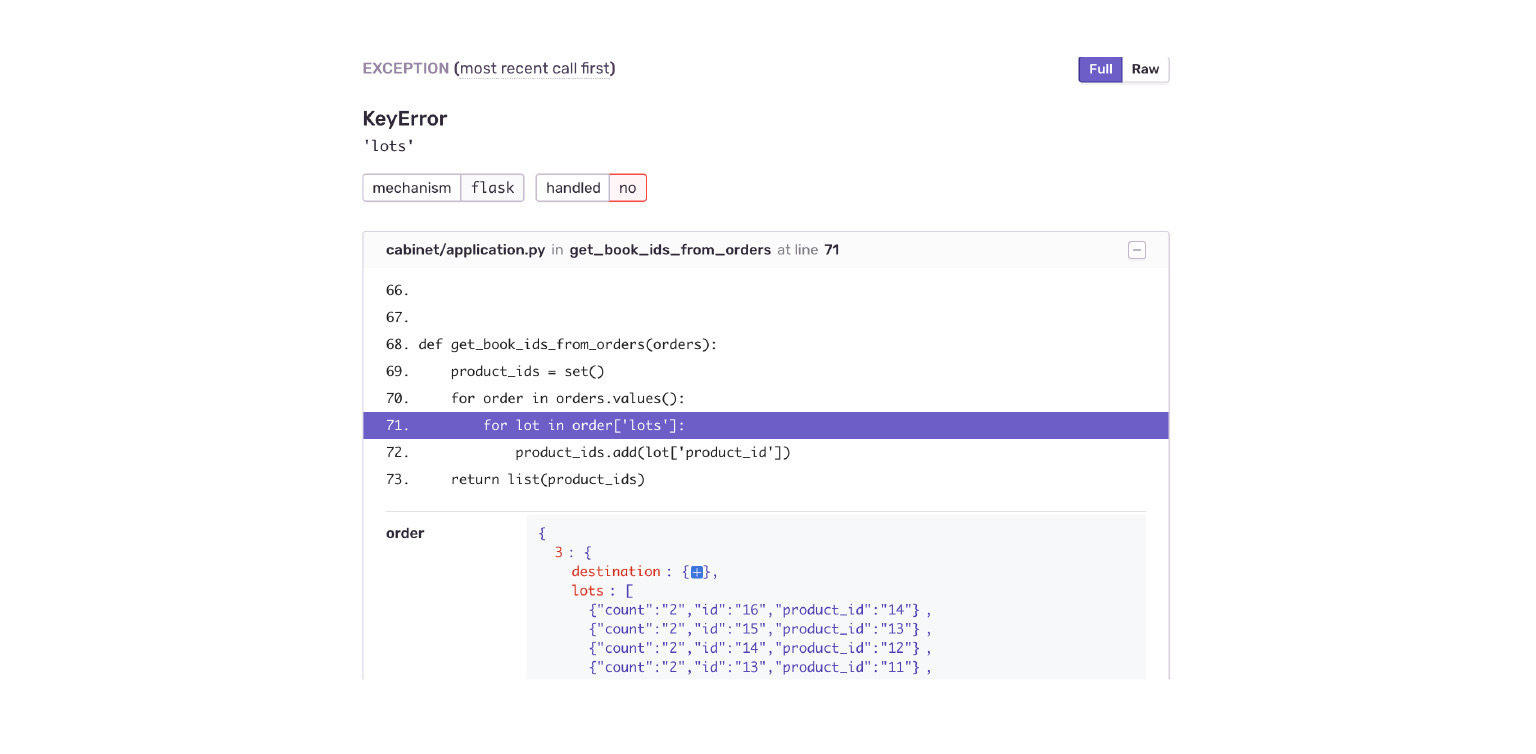
Schauen wir uns unser Beispiel an. In einen KeyError fallen. Wir sehen sofort den Kontext des Fehlers, was im Bestellobjekt war, was nicht da war. Ich sehe sofort aus Versehen, dass die Lieferanwendung mir eine neue Datenstruktur gegeben hat. Der Schrank ist dafür einfach nicht bereit.

Was gibt der Wachposten außer dem, was ich aufgelistet habe? Lassen Sie uns formalisieren.
Dies ist der Fehlerspeicher, in dem Sie nach ihnen suchen können. Hierfür gibt es praktische Werkzeuge. Es gibt eine Gruppierung von Fehlern - nach Projekten, nach Ähnlichkeit. Sentry bietet Integrationen mit verschiedenen Trackern. Das heißt, Sie können Ihre Fehler überwachen und mit ihnen arbeiten. Sie können die Aufgabe einfach zu Ihrem Kontext hinzufügen und fertig. Dies hilft bei der Entwicklung.
Fehlerstatistik. Auch hier ist es einfach, es mit der Einführung einer Veröffentlichung zu vergleichen. Sentry wird Ihnen dabei helfen. Ähnliche Ereignisse, die neben dem Fehler aufgetreten sind, können Ihnen auch helfen, herauszufinden und zu verstehen, was dazu geführt hat.

Fassen wir zusammen. Wir haben eine Anwendung geschrieben, die einfach ist, aber die Anforderungen erfüllt. Es hilft Ihnen, es in seinem Lebenszyklus zu entwickeln und zu erhalten. Was haben wir getan? Wir haben Protokolle in einem Repository gesammelt. Dies gab uns die Möglichkeit, sie nicht an verschiedenen Orten zu suchen. Außerdem haben wir jetzt eine Suche nach Protokollen und Funktionen von Drittanbietern, unseren Tools.
Integrierte Rückverfolgung. Jetzt können wir den Datenfluss in unserer Anwendung visuell überwachen.
Und wir haben ein praktisches Tool zum Umgang mit Fehlern hinzugefügt. Sie werden in unserer Bewerbung enthalten sein, egal wie sehr wir es versuchen. Aber wir werden sie schneller und besser beheben.
Was können Sie noch hinzufügen? Die Anwendung selbst ist fertig, es gibt einen Link, Sie können sehen, wie es gemacht wird. Alle Integrationen werden dort angehoben. Zum Beispiel Integration mit Elasticsearch oder Tracing. Komm rein und schau.
Eine andere coole Sache, für die ich keine Zeit hatte, ist request_id. Fast nichts anderes als trace_id, das in Traces verwendet wird. Wir sind jedoch für request_id verantwortlich, dies ist die wichtigste Funktion. Der Manager kann sofort mit request_id zu uns kommen, wir müssen ihn nicht suchen. Wir werden sofort damit beginnen, unser Problem zu lösen. Sehr cool.
Und vergessen Sie nicht, dass die von uns implementierten Tools Overhead sind. Dies sind Probleme, die für jede Anwendung behoben werden müssen. Sie können nicht alle unsere Integrationen gedankenlos implementieren, Ihr Leben einfacher machen und dann darüber nachdenken, was Sie mit einer hemmenden Anwendung tun sollen.
Hör zu. Wenn es dich nicht betrifft, cool. Sie haben nur die Pluspunkte und lösen die Probleme mit den Bremsen nicht. Vergiss das nicht. Ich danke Ihnen allen fürs Zuhören.