Einführung
Die Technologie des maschinellen Lernens hat sich im vergangenen Jahr in einem unglaublichen Tempo weiterentwickelt. Immer mehr Unternehmen tauschen ihre Best Practices aus und eröffnen so neue Möglichkeiten für die Schaffung intelligenter digitaler Assistenten.
Als Teil dieses Artikels möchte ich meine Erfahrungen bei der Implementierung eines Sprachassistenten teilen und Ihnen einige Ideen anbieten, um ihn noch intelligenter und nützlicher zu machen.

Was kann mein Sprachassistent tun?
| Fähigkeitsbeschreibung | Offline-Arbeit | Erforderliche Abhängigkeiten |
| Sprache erkennen und synthetisieren | Unterstützt | pip install PyAudio (Mikrofon verwenden)
pip install pyttsx3 (Sprachsynthese) Sie können eine oder beide für die Spracherkennung auswählen:
|
| pip install pyowm (OpenWeatherMap) | ||
| Google ( ) | pip install google | |
| YouTube | - | |
| Wikipedia c | pip install wikipedia-api | |
| pip install googletrans (Google Translate) | ||
| - | ||
| « » | - | |
| ( ) | - | |
| - | ||
| TODO ... | ||
1.
Beginnen wir mit dem Erlernen des Umgangs mit Spracheingaben. Wir brauchen ein Mikrofon und ein paar installierte Bibliotheken: PyAudio und SpeechRecognition.
Bereiten wir die grundlegenden Werkzeuge für die Spracherkennung vor:
import speech_recognition
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
voice_input = record_and_recognize_audio()
print(voice_input)
Erstellen wir nun eine Funktion zum Aufzeichnen und Erkennen von Sprache. Für die Online-Erkennung benötigen wir Google, da es eine hohe Erkennungsqualität in einer Vielzahl von Sprachen aufweist.
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
except speech_recognition.RequestError:
print("Check your Internet Connection, please")
return recognized_data
Was ist, wenn kein Internetzugang vorhanden ist? Sie können Lösungen für die Offline-Erkennung verwenden. Das Vosk- Projekt hat mir persönlich sehr gut gefallen .
Tatsächlich müssen Sie die Offline-Option nicht implementieren, wenn Sie keine benötigen. Ich wollte nur beide Methoden im Rahmen des Artikels zeigen, und Sie wählen bereits basierend auf Ihren Systemanforderungen (zum Beispiel ist Google zweifellos führend in der Anzahl der verfügbaren Erkennungssprachen).Nachdem wir eine Offline-Lösung implementiert und dem Projekt die erforderlichen Sprachmodelle hinzugefügt haben und kein Zugriff auf das Netzwerk besteht, wechseln wir automatisch zur Offline-Erkennung.
Beachten Sie, dass ich mich entschlossen habe, Audio vom Mikrofon in eine temporäre WAV-Datei aufzunehmen, die nach jeder Erkennung gelöscht wird, um nicht zweimal denselben Satz wiederholen zu müssen.
Der resultierende Code sieht also folgendermaßen aus:
Vollständiger Code für die Spracherkennung
from vosk import Model, KaldiRecognizer # - Vosk
import speech_recognition # (Speech-To-Text)
import wave # wav
import json # json- json-
import os #
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
with open("microphone-results.wav", "wb") as file:
file.write(audio.get_wav_data())
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
# offline- Vosk
except speech_recognition.RequestError:
print("Trying to use offline recognition...")
recognized_data = use_offline_recognition()
return recognized_data
def use_offline_recognition():
"""
-
:return:
"""
recognized_data = ""
try:
#
if not os.path.exists("models/vosk-model-small-ru-0.4"):
print("Please download the model from:\n"
"https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.")
exit(1)
# ( )
wave_audio_file = wave.open("microphone-results.wav", "rb")
model = Model("models/vosk-model-small-ru-0.4")
offline_recognizer = KaldiRecognizer(model, wave_audio_file.getframerate())
data = wave_audio_file.readframes(wave_audio_file.getnframes())
if len(data) > 0:
if offline_recognizer.AcceptWaveform(data):
recognized_data = offline_recognizer.Result()
# JSON-
# ( )
recognized_data = json.loads(recognized_data)
recognized_data = recognized_data["text"]
except:
print("Sorry, speech service is unavailable. Try again later")
return recognized_data
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
Möglicherweise fragen Sie: "Warum Offline-Funktionen unterstützen?"
Meiner Meinung nach ist es immer zu bedenken, dass der Benutzer möglicherweise vom Netzwerk abgeschnitten ist. In diesem Fall kann der Sprachassistent weiterhin nützlich sein, wenn Sie ihn als Konversationsbot verwenden oder eine Reihe einfacher Aufgaben lösen, z. B. etwas zählen, einen Film empfehlen, bei der Auswahl einer Küche helfen, ein Spiel spielen usw.
Schritt 2. Konfigurieren des Sprachassistenten
Da unser Sprachassistent ein Geschlecht, eine Sprachsprache und gemäß den Klassikern einen Namen haben kann, wählen wir für diese Daten eine separate Klasse aus, mit der wir in Zukunft arbeiten werden.
Um eine Stimme für unseren Assistenten festzulegen, verwenden wir die Offline-Sprachsynthesebibliothek pyttsx3. Abhängig von den Einstellungen des Betriebssystems werden automatisch die für die Synthese verfügbaren Stimmen auf unserem Computer gefunden (daher ist es möglich, dass Sie andere Stimmen zur Verfügung haben und andere Indizes benötigen).
Wir werden der Hauptfunktion auch die Initialisierung der Sprachsynthese und eine separate Funktion zum Spielen hinzufügen. Um sicherzustellen, dass alles funktioniert, überprüfen wir, ob der Benutzer uns begrüßt hat, und geben ihm eine Begrüßung vom Assistenten:
Vollständiger Code für das Voice Assistant Framework (Sprachsynthese und -erkennung)
from vosk import Model, KaldiRecognizer # - Vosk
import speech_recognition # (Speech-To-Text)
import pyttsx3 # (Text-To-Speech)
import wave # wav
import json # json- json-
import os #
class VoiceAssistant:
"""
, , ,
"""
name = ""
sex = ""
speech_language = ""
recognition_language = ""
def setup_assistant_voice():
"""
(
)
"""
voices = ttsEngine.getProperty("voices")
if assistant.speech_language == "en":
assistant.recognition_language = "en-US"
if assistant.sex == "female":
# Microsoft Zira Desktop - English (United States)
ttsEngine.setProperty("voice", voices[1].id)
else:
# Microsoft David Desktop - English (United States)
ttsEngine.setProperty("voice", voices[2].id)
else:
assistant.recognition_language = "ru-RU"
# Microsoft Irina Desktop - Russian
ttsEngine.setProperty("voice", voices[0].id)
def play_voice_assistant_speech(text_to_speech):
"""
( )
:param text_to_speech: ,
"""
ttsEngine.say(str(text_to_speech))
ttsEngine.runAndWait()
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
with open("microphone-results.wav", "wb") as file:
file.write(audio.get_wav_data())
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
# ( )
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
# offline- Vosk
except speech_recognition.RequestError:
print("Trying to use offline recognition...")
recognized_data = use_offline_recognition()
return recognized_data
def use_offline_recognition():
"""
-
:return:
"""
recognized_data = ""
try:
#
if not os.path.exists("models/vosk-model-small-ru-0.4"):
print("Please download the model from:\n"
"https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.")
exit(1)
# ( )
wave_audio_file = wave.open("microphone-results.wav", "rb")
model = Model("models/vosk-model-small-ru-0.4")
offline_recognizer = KaldiRecognizer(model, wave_audio_file.getframerate())
data = wave_audio_file.readframes(wave_audio_file.getnframes())
if len(data) > 0:
if offline_recognizer.AcceptWaveform(data):
recognized_data = offline_recognizer.Result()
# JSON-
# ( )
recognized_data = json.loads(recognized_data)
recognized_data = recognized_data["text"]
except:
print("Sorry, speech service is unavailable. Try again later")
return recognized_data
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
#
ttsEngine = pyttsx3.init()
#
assistant = VoiceAssistant()
assistant.name = "Alice"
assistant.sex = "female"
assistant.speech_language = "ru"
#
setup_assistant_voice()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
# ()
voice_input = voice_input.split(" ")
command = voice_input[0]
if command == "":
play_voice_assistant_speech("")
Tatsächlich würde ich hier gerne lernen, wie man einen Sprachsynthesizer selbst schreibt, aber mein Wissen hier wird nicht ausreichen. Wenn Sie gute Literatur, einen Kurs oder eine interessante dokumentierte Lösung vorschlagen können, die Ihnen hilft, dieses Thema gründlich zu verstehen, schreiben Sie bitte in die Kommentare.
Schritt 3. Befehlsverarbeitung
Nachdem wir "gelernt" haben, Sprache mithilfe einfach göttlicher Entwicklungen unserer Kollegen zu erkennen und zu synthetisieren, können wir beginnen, unser Rad für die Verarbeitung der Sprachbefehle des Benutzers neu zu erfinden: D
In meinem Fall verwende ich mehrsprachige Optionen zum Speichern von Befehlen, da ich nicht so viele habe Ereignisse, und ich bin mit der Genauigkeit der Definition eines bestimmten Befehls zufrieden. Für große Projekte empfehle ich jedoch, Konfigurationen nach Sprache aufzuteilen.
Ich kann zwei Möglichkeiten zum Speichern von Befehlen anbieten.
1 Weg
Sie können ein schönes JSON-ähnliches Objekt verwenden, um Absichten, Entwicklungsszenarien und Antworten bei fehlgeschlagenen Versuchen zu speichern (diese werden häufig für Chat-Bots verwendet). Es sieht ungefähr so aus:
config = {
"intents": {
"greeting": {
"examples": ["", "", " ",
"hello", "good morning"],
"responses": play_greetings
},
"farewell": {
"examples": ["", " ", "", " ",
"goodbye", "bye", "see you soon"],
"responses": play_farewell_and_quit
},
"google_search": {
"examples": [" ",
"search on google", "google", "find on google"],
"responses": search_for_term_on_google
},
},
"failure_phrases": play_failure_phrase
}
Diese Option eignet sich für diejenigen, die einen Assistenten darin schulen möchten, auf schwierige Sätze zu reagieren. Darüber hinaus können Sie hier den NLU-Ansatz anwenden und die Möglichkeit schaffen, die Absicht des Benutzers vorherzusagen, indem Sie sie mit denen vergleichen, die sich bereits in der Konfiguration befinden.
Wir werden diese Methode in Schritt 5 dieses Artikels ausführlich betrachten. In der Zwischenzeit werde ich Sie auf eine einfachere Option aufmerksam machen.
2-Wege
Sie können ein vereinfachtes Wörterbuch verwenden, das den Tupel vom Typ Hash als Schlüssel enthält (da Wörterbücher Hashes verwenden, um Elemente schnell zu speichern und abzurufen), und die Namen der Funktionen, die ausgeführt werden, werden in Form von Werten angegeben. Für kurze Befehle ist die folgende Option geeignet:
commands = {
("hello", "hi", "morning", ""): play_greetings,
("bye", "goodbye", "quit", "exit", "stop", ""): play_farewell_and_quit,
("search", "google", "find", ""): search_for_term_on_google,
("video", "youtube", "watch", ""): search_for_video_on_youtube,
("wikipedia", "definition", "about", "", ""): search_for_definition_on_wikipedia,
("translate", "interpretation", "translation", "", "", ""): get_translation,
("language", ""): change_language,
("weather", "forecast", "", ""): get_weather_forecast,
}
Um es zu verarbeiten, müssen wir den Code wie folgt hinzufügen:
def execute_command_with_name(command_name: str, *args: list):
"""
:param command_name:
:param args: ,
:return:
"""
for key in commands.keys():
if command_name in key:
commands[key](*args)
else:
pass # print("Command not found")
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
# ()
voice_input = voice_input.split(" ")
command = voice_input[0]
command_options = [str(input_part) for input_part in voice_input[1:len(voice_input)]]
execute_command_with_name(command, command_options)
Zusätzliche Argumente werden nach dem Befehlswort an die Funktion übergeben. Wenn Sie also den Ausdruck " Videos sind süße Katzen " sagen , ruft der Befehl " Video " die Funktion search_for_video_on_youtube () mit dem Argument " süße Katzen " auf und gibt das folgende Ergebnis aus:
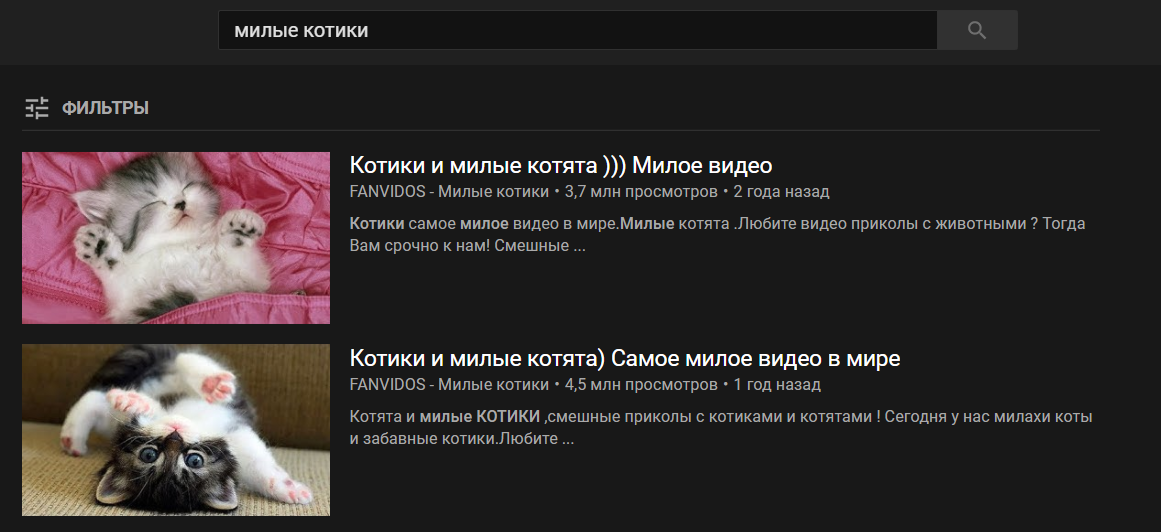
Ein Beispiel für eine solche Funktion mit der Verarbeitung eingehender Argumente:
def search_for_video_on_youtube(*args: tuple):
"""
YouTube
:param args:
"""
if not args[0]: return
search_term = " ".join(args[0])
url = "https://www.youtube.com/results?search_query=" + search_term
webbrowser.get().open(url)
#
# , JSON-
play_voice_assistant_speech("Here is what I found for " + search_term + "on youtube")
Das ist es! Die Hauptfunktionalität des Bots ist bereit. Dann können Sie es auf verschiedene Arten endlos verbessern. Meine Implementierung mit detaillierten Kommentaren ist auf meinem GitHub verfügbar .
Im Folgenden werden einige Verbesserungen vorgestellt, um unseren Assistenten noch intelligenter zu machen.
Schritt 4. Mehrsprachigkeit hinzufügen
Um unserem Assistenten das Arbeiten mit mehreren Sprachmodellen beizubringen, ist es am bequemsten, eine kleine JSON-Datei mit einer einfachen Struktur zu organisieren:
{
"Can you check if your microphone is on, please?": {
"ru": ", , ",
"en": "Can you check if your microphone is on, please?"
},
"What did you say again?": {
"ru": ", ",
"en": "What did you say again?"
},
}
In meinem Fall verwende ich das Umschalten zwischen Russisch und Englisch, da mir hierfür Modelle zur Spracherkennung und Sprache zur Sprachsynthese zur Verfügung stehen. Die Sprache wird abhängig von der Sprache der Sprache des Sprachassistenten selbst ausgewählt.
Um die Übersetzung zu erhalten, können wir eine separate Klasse mit einer Methode erstellen, die uns eine Zeichenfolge mit der Übersetzung zurückgibt:
class Translation:
"""
"""
with open("translations.json", "r", encoding="UTF-8") as file:
translations = json.load(file)
def get(self, text: str):
"""
( )
:param text: ,
:return:
"""
if text in self.translations:
return self.translations[text][assistant.speech_language]
else:
#
#
print(colored("Not translated phrase: {}".format(text), "red"))
return text
In der Hauptfunktion deklarieren wir unseren Übersetzer vor der Schleife wie folgt: translator = Translation ()
Wenn wir nun die Rede des Assistenten abspielen, können wir die Übersetzung wie folgt erhalten:
play_voice_assistant_speech(translator.get(
"Here is what I found for {} on Wikipedia").format(search_term))
Wie Sie dem obigen Beispiel entnehmen können, funktioniert dies auch für Zeilen, für die zusätzliche Argumente eingefügt werden müssen. Auf diese Weise können Sie die "Standard" -Phrasen für Ihre Assistenten übersetzen.
Schritt 5. Ein wenig maschinelles Lernen
Kehren wir nun zum JSON-Objekt zum Speichern von Mehrwortbefehlen zurück, das für die meisten Chatbots typisch ist, das ich in Absatz 3 erwähnt habe. Es ist für diejenigen geeignet, die keine strengen Befehle verwenden möchten und planen, ihr Verständnis der Benutzerabsicht mithilfe von NLU zu erweitern -Methoden.
Grob gesagt werden in diesem Fall die Sätze " Guten Tag ", " Guten Abend " und " Guten Morgen " als gleichwertig angesehen. Der Assistent wird verstehen, dass der Benutzer in allen drei Fällen die Absicht hatte, seinen Sprachassistenten zu begrüßen.
Mit dieser Methode können Sie auch einen Konversationsbot für Chats oder einen Konversationsmodus für Ihren Sprachassistenten erstellen (für Fälle, in denen Sie einen Gesprächspartner benötigen).
Um eine solche Möglichkeit zu implementieren, müssen wir einige Funktionen hinzufügen:
def prepare_corpus():
"""
"""
corpus = []
target_vector = []
for intent_name, intent_data in config["intents"].items():
for example in intent_data["examples"]:
corpus.append(example)
target_vector.append(intent_name)
training_vector = vectorizer.fit_transform(corpus)
classifier_probability.fit(training_vector, target_vector)
classifier.fit(training_vector, target_vector)
def get_intent(request):
"""
:param request:
:return:
"""
best_intent = classifier.predict(vectorizer.transform([request]))[0]
index_of_best_intent = list(classifier_probability.classes_).index(best_intent)
probabilities = classifier_probability.predict_proba(vectorizer.transform([request]))[0]
best_intent_probability = probabilities[index_of_best_intent]
#
if best_intent_probability > 0.57:
return best_intent
Ändern Sie außerdem die Hauptfunktion geringfügig, indem Sie die Initialisierung von Variablen hinzufügen, um das Modell vorzubereiten, und die Schleife auf die Version ändern, die der neuen Konfiguration entspricht:
#
# ( )
vectorizer = TfidfVectorizer(analyzer="char", ngram_range=(2, 3))
classifier_probability = LogisticRegression()
classifier = LinearSVC()
prepare_corpus()
while True:
#
#
voice_input = record_and_recognize_audio()
if os.path.exists("microphone-results.wav"):
os.remove("microphone-results.wav")
print(colored(voice_input, "blue"))
# ()
if voice_input:
voice_input_parts = voice_input.split(" ")
# -
#
if len(voice_input_parts) == 1:
intent = get_intent(voice_input)
if intent:
config["intents"][intent]["responses"]()
else:
config["failure_phrases"]()
# -
# ,
#
if len(voice_input_parts) > 1:
for guess in range(len(voice_input_parts)):
intent = get_intent((" ".join(voice_input_parts[0:guess])).strip())
if intent:
command_options = [voice_input_parts[guess:len(voice_input_parts)]]
config["intents"][intent]["responses"](*command_options)
break
if not intent and guess == len(voice_input_parts)-1:
config["failure_phrases"]()
Diese Methode ist jedoch schwieriger zu kontrollieren: Sie erfordert eine ständige Überprüfung, ob diese oder jene Phrase vom System als Teil einer bestimmten Absicht immer noch korrekt identifiziert wird. Daher sollte diese Methode mit Vorsicht angewendet werden (oder mit dem Modell selbst experimentieren).
Fazit
Damit ist mein kleines Tutorial abgeschlossen.
Ich würde mich freuen, wenn Sie mir in den Kommentaren Open-Source-Lösungen mitteilen, von denen Sie wissen, dass sie in diesem Projekt implementiert werden können, sowie Ihre Ideen, welche anderen Online- und Offline-Funktionen implementiert werden können.
Die dokumentierten Quellen meines Sprachassistenten in zwei Versionen finden Sie hier .
PS: Die Lösung funktioniert unter Windows, Linux und MacOS mit geringfügigen Unterschieden bei der Installation von PyAudio- und Google-Bibliotheken.