Was war der Zweck dieser Studie? Ich wollte wissen:
- In welchen Anwendungen wird Python verwendet?
- Welche Kenntnisse sind erforderlich: Datenbanken, Bibliotheken, Frameworks
- Wie viele Spezialisten in jedem Bereich sind gefragt?
- Welche Gehälter werden angeboten?

Lade Daten
Jobs heruntergeladen von der Website hh.ru unter Verwendung der API: dev.hh.ru . Auf die Anfrage "Python" wurden 1994 offene Stellen (Region Moskau) hochgeladen , die im Verhältnis 80% und 20% in Schulungs- und Testsuiten unterteilt waren . Die Größe des Trainingssatzes beträgt 1595 , die Größe des Testsatzes beträgt 399 . Der Testsatz wird nur in den Abschnitten Top / Antitop-Fähigkeiten und Jobklassifizierung verwendet.
Zeichen
Entsprechend dem Text der hochgeladenen Stellen wurden zwei Gruppen der häufigsten n-Gramm Wörter gebildet :
- 2 Gramm in Kyrillisch und Latein
- 1 Gramm in Latein
In IT-Stellenangeboten werden Schlüsselkompetenzen und -technologien normalerweise auf Englisch geschrieben, sodass die zweite Gruppe nur lateinische Wörter enthielt.
Nach der Auswahl von n Gramm enthielt die erste Gruppe 81 2 Gramm und die zweite 98 1 Gramm:
| Nein. | n | n-Gramm | Gewicht | Stellenangebote |
| 1 | 2 | in Python | acht | 258 |
| 2 | 2 | ci cd | acht | 230 |
| 3 | 2 | Verständnis der Prinzipien | acht | 221 |
| 4 | 2 | Kenntnis von SQL | acht | 178 |
| fünf | 2 | Entwicklung und | neun | 174 |
| ... | ... | ... | ... | ... |
| 82 | 1 | sql | fünf | 490 |
| 83 | 1 | Linux | 6 | 462 |
| 84 | 1 | postgresql | fünf | 362 |
| 85 | 1 | Docker | 7 | 358 |
| 86 | 1 | Java | neun | 297 |
| ... | ... | ... | ... | ... |
Es wurde beschlossen, offene Stellen nach folgenden Kriterien in der Reihenfolge ihrer Priorität in Cluster aufzuteilen:
| Eine Priorität | Kriterium | Gewicht |
| 1 | Feld (angewandte Richtung), Position,
n-Gramm- Erfahrung : "Maschinelles Lernen", "Linux-Administration", "exzellentes Wissen" |
7-9 |
| 2 | Werkzeuge, Technologien, Software.
n-Gramm: "sql", "linux os", "pytest" |
4-6 |
| 3 | Andere
n-Gramm- Fähigkeiten : "technische Ausbildung", "Englisch", "interessante Aufgaben" |
1-3 |
Die Bestimmung, zu welcher Gruppe von Kriterien das n-Gramm gehört und welches Gewicht ihm zugewiesen werden soll, erfolgte auf einer intuitiven Ebene. Hier einige Beispiele:
- Auf den ersten Blick kann "Docker" der zweiten Kriteriengruppe mit einem Gewicht von 4 bis 6 zugeordnet werden. Die Erwähnung von "Docker" in der Vakanz bedeutet jedoch höchstwahrscheinlich, dass die Vakanz für die Position des "DevOps-Ingenieurs" bestimmt ist. Daher fiel "Docker" in die erste Gruppe und erhielt ein Gewicht von 7.
- «Java» , .. «Java» Java- « Python». «-». , , , «Java» 9.
n- — .
Für Berechnungen wurde jede Leerstelle in einen Vektor mit einer Dimension von 179 (der Anzahl ausgewählter Merkmale) von ganzen Zahlen von 0 bis 9 transformiert, wobei 0 bedeutet, dass das i-te n-Gramm in der Leerstelle fehlt, und die Zahlen von 1 bis 9 das Vorhandensein des i-ten n bedeuten - Gramm und sein Gewicht. Weiterhin wird im Text ein Punkt als eine durch einen solchen Vektor dargestellte Leerstelle verstanden.
Beispiel:
Angenommen, eine Liste von n-Gramm enthält nur drei Werte:
Nein. n n-Gramm Gewicht Stellenangebote 1 2 in Python acht 258 2 2 Verständnis der Prinzipien acht 221 3 1 sql fünf 490
Dann für eine Stelle mit Text.
Bedarf:
- Über 3 Jahre Erfahrung in der Python- Entwicklung .
- Gute SQL- Kenntnisse
der Vektor ist [8, 0, 5].
Metriken
Um mit Daten arbeiten zu können, müssen Sie diese verstehen. In unserem Fall würde ich gerne sehen, ob es Punktcluster gibt, die wir als Cluster betrachten werden. Dazu habe ich den t-SNE- Algorithmus verwendet , um alle Vektoren in den 2D-Raum zu übersetzen.
Das Wesentliche der Methode besteht darin, die Dimension der Daten zu reduzieren und gleichzeitig die Proportionen der Abstände zwischen den Punkten der Menge maximal beizubehalten. Es ist ziemlich schwierig zu verstehen, wie t-SNE anhand der Formeln funktioniert. Aber ich mochte ein Beispiel, das irgendwo im Internet zu finden ist: Nehmen wir an, wir haben Bälle im dreidimensionalen Raum. Wir verbinden jeden Ball mit allen anderen Bällen durch unsichtbare Federn, die sich in keiner Weise schneiden und sich beim Überqueren nicht gegenseitig stören. Die Federn wirken in zwei Richtungen, d.h. Sie widerstehen sowohl der Entfernung als auch der Annäherung der Kugeln aneinander. Das System ist in einem stabilen Zustand, die Kugeln sind stationär. Wenn wir eine der Kugeln nehmen und zurückziehen und dann loslassen, kehrt sie aufgrund der Kraft der Federn in ihren ursprünglichen Zustand zurück. Als nächstes nehmen wir zwei große Teller und drücken die Kugeln zu einer dünnen Schicht zusammen.ohne die Kugeln zu stören, um sich in der Ebene zwischen den beiden Platten zu bewegen. Die Kräfte der Federn beginnen zu wirken, die Kugeln bewegen sich und hören schließlich auf, wenn die Kräfte aller Federn ausgeglichen werden. Die Federn wirken so, dass die Kugeln, die nahe beieinander waren, relativ nahe und flach bleiben. Auch bei entfernten Bällen werden diese voneinander entfernt. Mit Hilfe von Federn und Platten haben wir den dreidimensionalen Raum in einen zweidimensionalen Raum umgewandelt, wobei der Abstand zwischen den Punkten in irgendeiner Form erhalten blieb!Auch bei entfernten Bällen werden diese voneinander entfernt. Mit Hilfe von Federn und Platten haben wir den dreidimensionalen Raum in einen zweidimensionalen Raum umgewandelt, wobei der Abstand zwischen den Punkten in irgendeiner Form erhalten blieb!Auch bei entfernten Bällen werden diese voneinander entfernt. Mit Hilfe von Federn und Platten haben wir den dreidimensionalen Raum in einen zweidimensionalen Raum umgewandelt, wobei der Abstand zwischen den Punkten in irgendeiner Form erhalten blieb!
Der t-SNE-Algorithmus wurde von mir nur verwendet, um eine Reihe von Punkten zu visualisieren. Er half bei der Auswahl der Metrik sowie bei der Auswahl der Gewichte für die Features.
Wenn wir die euklidische Metrik verwenden, die wir in unserem täglichen Leben verwenden, sieht der Ort der offenen Stellen folgendermaßen aus:

Die Abbildung zeigt, dass die meisten Punkte in der Mitte konzentriert sind und an den Seiten kleine Äste vorhanden sind. Mit diesem Ansatz erzielen Clustering-Algorithmen, die die Abstände zwischen Punkten verwenden, nichts Gutes.
Es gibt viele Metriken (Möglichkeiten zum Bestimmen des Abstands zwischen zwei Punkten), die für die von Ihnen untersuchten Daten gut geeignet sind. Ich habe den Jaccard-Abstand als Maß gewählt , unter Berücksichtigung der Gewichte von n-Gramm. Jaccards Maßnahme ist leicht zu verstehen, eignet sich jedoch gut zur Lösung des betreffenden Problems.
:
1 n-: « python», «sql», «docker»
2 n-: « python», «sql», «php»
:
« python» — 8
«sql» — 5
«docker» — 7
«php» — 9
(n- 1- 2- ): « python», «sql» = 8 + 5 = 13
( n- 1- 2- ): « python», «sql», «docker», «php» = 8 + 5 + 7 + 9 = 29
=1 — ( / ) = 1 — (13 / 29) = 0.55
Die Matrix der Abstände zwischen allen Punktpaaren wurde berechnet, die Größe der Matrix beträgt 1595 x 1595. Insgesamt 1.271.215 Abstände zwischen eindeutigen Paaren. Die durchschnittliche Entfernung betrug 0,96, zwischen 619 und 659 beträgt die Entfernung 1 (d. H. Es gibt überhaupt keine Ähnlichkeit). Die folgende Grafik zeigt, dass es insgesamt wenig Ähnlichkeit zwischen Jobs gibt:
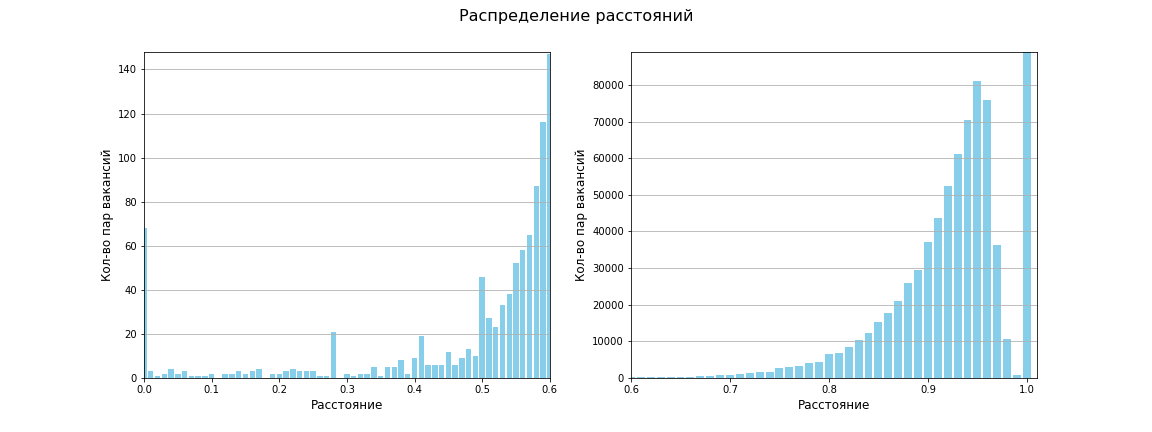
Mit der Jaccard-Metrik sieht unser Raum jetzt folgendermaßen aus:

Es erschienen vier unterschiedliche Dichtebereiche und zwei kleine Cluster niedriger Dichte. Zumindest sehen meine Augen so!
Clustering
Das Gaußsche Mischungsmodell (GMM) wurde als Clustering-Algorithmus gewählt . Der Algorithmus empfängt Daten in Form von Vektoren als Eingabe, und der Parameter n_components gibt die Anzahl der Cluster an, in die die Menge aufgeteilt werden muss. Sie können sehen , wie der Algorithmus funktioniert hier (in englischer Sprache). Ich habe eine vorgefertigte GMM-Implementierung aus der Scikit-Learn-Bibliothek verwendet: sklearn.mixture.GaussianMixture .
Beachten Sie, dass GMM keine Metrik verwendet, sondern Daten nur durch eine Reihe von Features und deren Gewichtung trennt. In diesem Artikel wird der Jaccard-Abstand verwendet, um Daten zu visualisieren, die Kompaktheit von Clustern zu berechnen (ich habe den durchschnittlichen Abstand zwischen Clusterpunkten für die Kompaktheit genommen) und zu bestimmender zentrale Punkt des Clusters (typische Leerstelle) - der Punkt mit dem geringsten durchschnittlichen Abstand zu anderen Punkten des Clusters. Viele Clustering-Algorithmen verwenden genau den Abstand zwischen Punkten. Im Abschnitt Andere Methoden werden andere Arten von Clustering erläutert, die auf Metriken basieren und auch gute Ergebnisse liefern.
Im vorherigen Abschnitt wurde mit dem Auge festgestellt, dass es höchstwahrscheinlich sechs Cluster geben wird. So sehen die Clustering-Ergebnisse mit n_components = 6 aus:

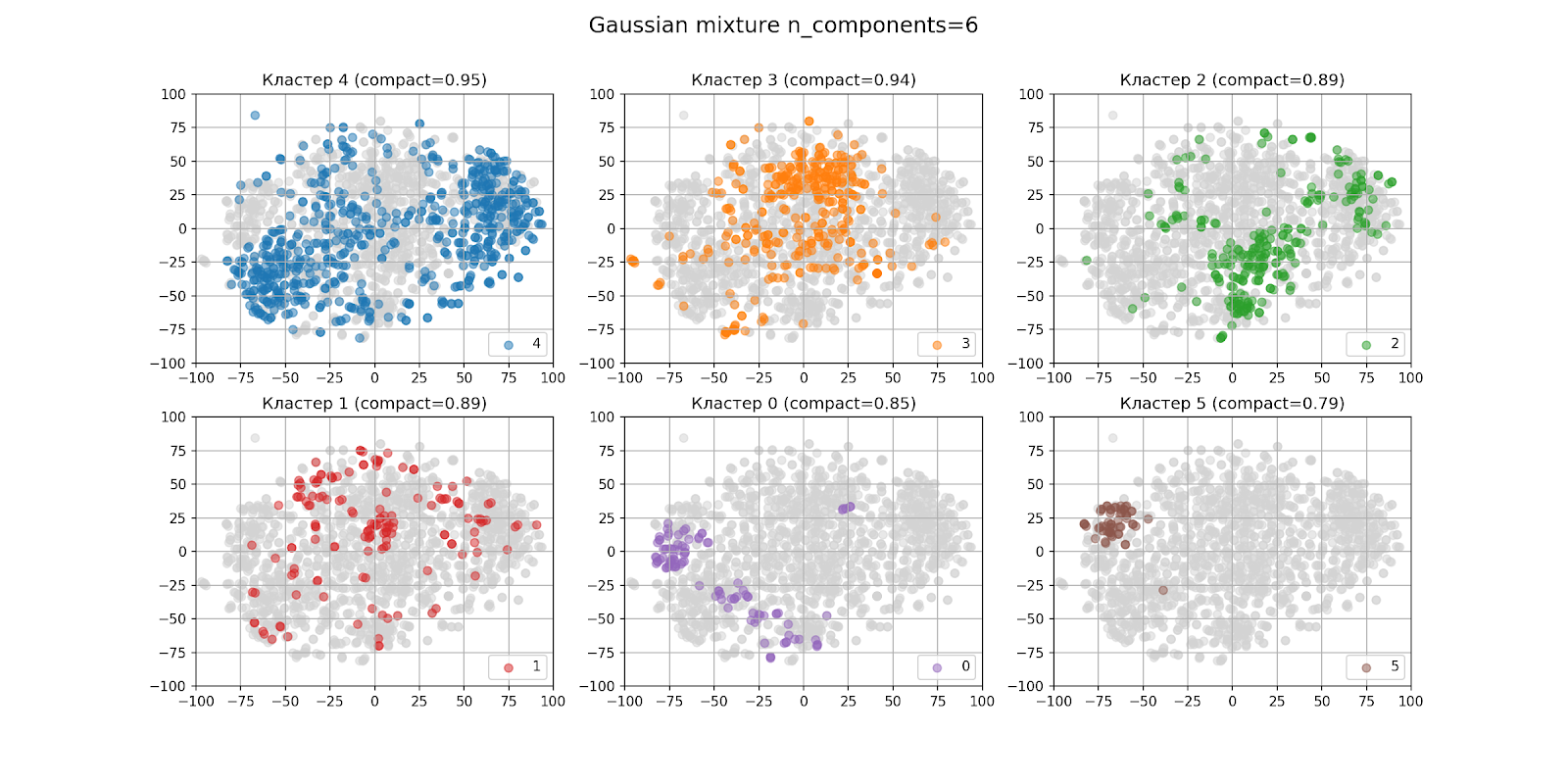
In der Abbildung mit der Ausgabe von Clustern sind die Cluster in absteigender Reihenfolge der Anzahl der Punkte von links nach rechts von oben nach unten angeordnet: Cluster 4 ist der größte, Cluster 5 ist der kleinste. Die Kompaktheit jedes Clusters ist in Klammern angegeben.
Das Clustering erwies sich als nicht sehr gut, auch wenn wir der Ansicht sind, dass der t-SNE-Algorithmus nicht perfekt ist. Bei der Analyse von Clustern war das Ergebnis ebenfalls nicht ermutigend.
Um die optimale Anzahl von Clustern n_components zu finden, verwenden wir die AIC- und BIC- Kriterien , über die Sie hier lesen können . Die Berechnung dieser Kriterien ist in die Methode sklearn.mixture.GaussianMixture integriert . So sieht das Kriteriendiagramm aus:

Wenn n_components = 12 ist, hat das BIC-Kriterium den niedrigsten (besten) Wert, das AIC-Kriterium hat auch einen Wert nahe dem Minimum (Minimum, wenn n_components = 23). Teilen wir die offenen Stellen in 12 Cluster auf:


Cluster sind jetzt kompakter, sowohl optisch als auch numerisch. Während der manuellen Analyse wurden offene Stellen in charakteristische Gruppen unterteilt, um eine Person zu verstehen. Die Abbildung zeigt die Namen der Cluster. Cluster mit den Nummern 11 und 4 sind als <Papierkorb 2> gekennzeichnet:
- In Cluster 11 haben alle Features ungefähr die gleichen Gesamtgewichte.
- Cluster 4 ist Java gewidmet. Trotzdem gibt es nur wenige offene Stellen für die Position des Java-Entwicklers im Cluster. Java-Kenntnisse sind häufig erforderlich, da dies ein zusätzliches Plus darstellt.
Cluster
Nach dem Entfernen von zwei nicht informativen Clustern mit den Nummern 11 und 4 ergeben sich 10 Cluster:
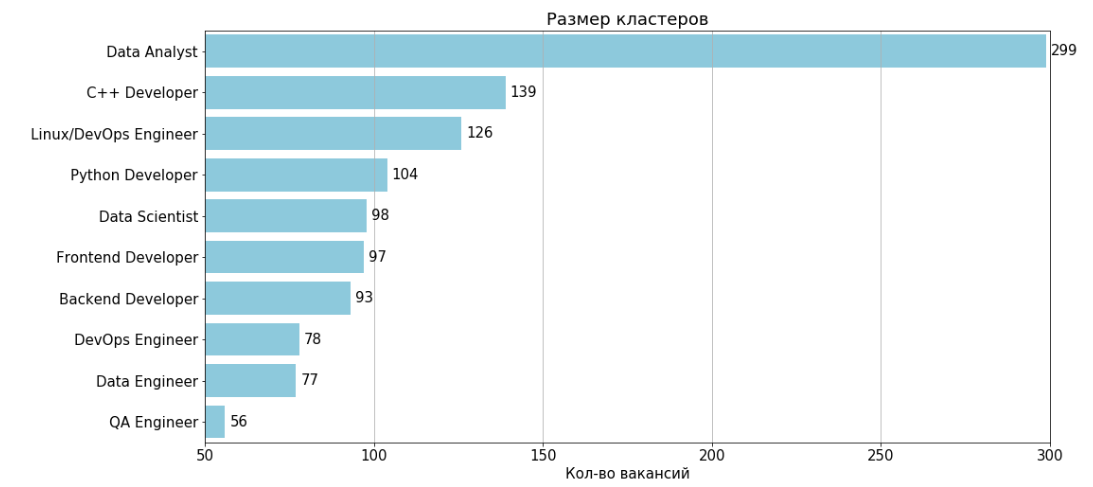
Für jeden Cluster gibt es eine Tabelle mit Funktionen und 2 Gramm, die am häufigsten in den offenen Stellen des Clusters zu finden sind.
Legende:
S - Der Prozentsatz der offenen Stellen, in denen das Merkmal gefunden wird, multipliziert mit dem Gewicht des Merkmals
% - Der Prozentsatz der offenen Stellen, in denen das Merkmal gefunden wird / 2 Gramm.
Typische Cluster- Leerstelle - Leerstelle mit dem geringsten durchschnittlichen Abstand zu anderen Punkten des Clusters
Daten Analyst
Anzahl der Jobs: 299
Typischer Job : 35.805.914
| Nein. | Zeichen mit Gewicht | S. | Zeichen | %. | 2 Gramm | %. |
| 1 | übertreffen | 3.13 | sql | 64,55 | Kenntnis von SQL | 18.39 |
| 2 | r | 2.59 | übertreffen | 34,78 | in Bearbeitung | 14.05 |
| 3 | sql | 2.44 | r | 28,76 | Python r | 14.05 |
| 4 | Kenntnis von SQL | 1,47 | Bi | 19.40 | mit großen | 13.38 |
| fünf | Datenanalyse | 1.17 | Tableau | 15.38 | Entwicklung und | 13.38 |
| 6 | Tableau | 1,08 | 14.38 | Datenanalyse | 13.04 | |
| 7 | mit großen | 1,07 | vba | 13.04 | Kenntnis von Python | 12.71 |
| acht | Entwicklung und | 1,07 | Wissenschaft | 9,70 | analytisches Lager | 11.71 |
| neun | vba | 1,04 | dwh | 6.35 | Entwicklungserfahrung | 11.71 |
| zehn | Kenntnis von Python | 1,02 | Orakel | 6.35 | Datenbanken | 11.37 |
C ++ - Entwickler
Anzahl der Jobs: 139
Typischer Job : 39.955.360
| Nein. | Zeichen mit Gewicht | S. | Zeichen | %. | 2 Gramm | %. |
| 1 | c ++ | 9.00 | c ++ | 100,00 | Entwicklungserfahrung | 44,60 |
| 2 | Java | 3.30 | Linux | 44,60 | c c ++ | 27.34 |
| 3 | Linux | 2.55 | Java | 36,69 | c ++ Python | 17,99 |
| 4 | c # | 1,88 | sql | 23.02 | in c ++ | 16.55 |
| fünf | gehen | 1,75 | c # | 20.86 | Entwicklung auf | 15.83 |
| 6 | Entwicklung auf | 1.27 | gehen | 19.42 | Datenstrukturen | 15.11 |
| 7 | gute Kenntnisse | 1.15 | Unix | 12.23 | Schreiberfahrung | 14.39 |
| acht | Datenstrukturen | 1,06 | Tensorflow | 11.51 | Programmierung ein | 13.67 |
| neun | Tensorflow | 1,04 | Bash | 10.07 | in Bearbeitung | 13.67 |
| zehn | Programmiererfahrung | 0,98 | postgresql | 9.35 | Programmiersprachen | 12,95 |
Linux / DevOps Engineer
Anzahl der Jobs: 126
Typischer Job : 39.533.926
| Nein. | Zeichen mit Gewicht | S. | Zeichen | %. | 2 Gramm | %. |
| 1 | ansible | 5.33 | Linux | 84,92 | ci cd | 58,73 |
| 2 | Docker | 4.78 | ansible | 76,19 | Verwaltungserfahrung | 42.06 |
| 3 | Bash | 4.78 | Docker | 74,60 | Bash Python | 33.33 |
| 4 | ci cd | 4,70 | Bash | 68,25 | tcp ip | 39,37 |
| fünf | Linux | 4.43 | Prometheus | 58,73 | Anpassungserfahrung | 28,57 |
| 6 | Prometheus | 4.11 | zabbix | 54,76 | überwachen und | 26,98 |
| 7 | Nginx | 3.67 | Nginx | 52,38 | prometheus grafana | 23.81 |
| acht | Verwaltungserfahrung | 3.37 | grafana | 52,38 | Überwachungssysteme | 22.22 |
| neun | zabbix | 3.29 | postgresql | 51,59 | mit Docker | 16.67 |
| zehn | Elch | 3.22 | kubernetes | 51,59 | Konfigurationsmanagement | 16.67 |
Python-Entwickler
Anzahl der offenen Stellen : 104
Typischer Job : 39.705.484
| Nein. | Zeichen mit Gewicht | S. | Zeichen | %. | 2 Gramm | %. |
| 1 | in Python | 6.00 | Docker | 65,38 | in Python | 75,00 |
| 2 | Django | 5.62 | Django | 62,50 | Entwicklung auf | 51,92 |
| 3 | Flasche | 4.59 | postgresql | 58,65 | Entwicklungserfahrung | 43.27 |
| 4 | Docker | 4.24 | Flasche | 50,96 | Django-Flasche | 04.24 |
| fünf | Entwicklung auf | 4.15 | redis | 38,46 | Rest api | 23.08 |
| 6 | postgresql | 2.93 | Linux | 35,58 | Python aus | 21.15 |
| 7 | aiohttp | 1,99 | rabbitmq | 33,65 | Datenbanken | 18.27 |
| acht | redis | 1,92 | sql | 30,77 | Schreiberfahrung | 18.27 |
| neun | Linux | 1,73 | mongodb | 25.00 | mit Docker | 17.31 |
| zehn | rabbitmq | 1,68 | aiohttp | 22.12 | mit postgresql | 16.35 |
Datenwissenschaftler
Anzahl der offenen Stellen: 98
Typische freie Stelle: 38071218
| Nein. | Zeichen mit Gewicht | S. | Zeichen | %. | 2 Gramm | %. |
| 1 | Pandas | 7.35 | Pandas | 81,63 | maschinelles Lernen | 63,27 |
| 2 | numpy | 6.04 | numpy | 75,51 | Pandas numpy | 43,88 |
| 3 | maschinelles Lernen | 5.69 | sql | 62,24 | Datenanalyse | 29,59 |
| 4 | Pytorch | 3,77 | Pytorch | 41,84 | Datenwissenschaft | 26.53 |
| fünf | ml | 3.49 | ml | 38,78 | Kenntnis von Python | 25.51 |
| 6 | Tensorflow | 3.31 | Tensorflow | 36,73 | numpy scipy | 24.49 |
| 7 | Datenanalyse | 2.66 | Funke | 32,65 | Python-Pandas | 23.47 |
| acht | scikitlearn | 2.57 | scikitlearn | 28,57 | in Python | 21.43 |
| neun | Datenwissenschaft | 2.39 | Docker | 27,55 | mathematische Statistik | 20.41 |
| zehn | Funke | 2.29 | Hadoop | 27,55 | Algorithmen der Maschine | 20.41 |
Entwickler für Benutzeroberflächen
Anzahl der Jobs: 97
Typischer Job : 39.681.044
| Nein. | Zeichen mit Gewicht | S. | Zeichen | %. | 2 Gramm | %. |
| 1 | Javascript | 9.00 | Javascript | 100 | html css | 27,84 |
| 2 | Django | 2,60 | html | 42,27 | Entwicklungserfahrung | 25,77 |
| 3 | reagieren | 2.32 | postgresql | 38.14 | in Bearbeitung | 17.53 |
| 4 | nodejs | 2.13 | Docker | 37.11 | Kenntnisse in Javascript | 15.46 |
| fünf | Vorderes Ende | 2.13 | CSS | 37.11 | und Unterstützung | 15.46 |
| 6 | Docker | 2,09 | Linux | 32,99 | Python und | 14.43 |
| 7 | postgresql | 1,91 | sql | 31,96 | CSS-Javascript | 13.40 |
| acht | Linux | 1,79 | Django | 28,87 | Datenbanken | 12.37 |
| neun | html css | 1,67 | reagieren | 25,77 | in Python | 12.37 |
| zehn | php | 1,58 | nodejs | 23.71 | Design und | 11.34 |
Backend-Entwickler
Anzahl der Jobs: 93
Typischer Job : 40.226.808
| Nein. | Zeichen mit Gewicht | S. | Zeichen | %. | 2 Gramm | %. |
| 1 | Django | 5,90 | Django | 65,59 | Python Django | 26,88 |
| 2 | js | 4.74 | js | 52,69 | Entwicklungserfahrung | 25.81 |
| 3 | reagieren | 2.52 | postgresql | 40,86 | Kenntnis von Python | 20.43 |
| 4 | Docker | 2.26 | Docker | 35,48 | in Bearbeitung | 18.28 |
| fünf | postgresql | 2,04 | reagieren | 27,96 | ci cd | 17.20 |
| 6 | Verständnis der Prinzipien | 1,89 | Linux | 27,96 | selbstbewusstes Wissen | 16.13 |
| 7 | Kenntnis von Python | 1,63 | Backend | 22.58 | Rest api | 15.05 |
| acht | Backend | 1,58 | redis | 22.58 | html css | 13.98 |
| neun | ci cd | 1,38 | sql | 20.43 | Fähigkeit zu verstehen | 10.75 |
| zehn | Vorderes Ende | 1,35 | MySQL | 19.35 | in einem Fremden | 10.75 |
DevOps-Ingenieur
Anzahl der Jobs: 78
Typischer Job : 39634258
| Nein. | Zeichen mit Gewicht | S. | Zeichen | %. | 2 Gramm | %. |
| 1 | Devops | 8.54 | Devops | 94,87 | ci cd | 51,28 |
| 2 | ansible | 5.38 | ansible | 76,92 | Bash Python | 30,77 |
| 3 | Bash | 4.76 | Linux | 74,36 | Verwaltungserfahrung | 24.36 |
| 4 | Jenkins | 4.49 | Bash | 67,95 | und Unterstützung | 23.08 |
| fünf | ci cd | 4.10 | Jenkins | 64.10 | Docker Kubernetes | 20.51 |
| 6 | Linux | 3.54 | Docker | 50.00 | Entwicklung und | 17,95 |
| 7 | Docker | 2,60 | kubernetes | 41.03 | Schreiberfahrung | 17,95 |
| acht | Java | 2,08 | sql | 29,49 | und Anpassung | 17,95 |
| neun | Verwaltungserfahrung | 1,95 | Orakel | 25.64 | Entwicklung und | 16.67 |
| zehn | und Unterstützung | 1,85 | OpenShift | 24.36 | Skripterstellung | 14.10 |
Dateningenieur
Anzahl der Jobs: 77
Typischer Job : 40.008.757
| Nein. | Zeichen mit Gewicht | S. | Zeichen | %. | 2 Gramm | %. |
| 1 | Funke | 6.00 | Hadoop | 89,61 | Datenverarbeitung | 38,96 |
| 2 | Hadoop | 5.38 | Funke | 85,71 | Große Daten | 37,66 |
| 3 | Java | 4.68 | sql | 68,83 | Entwicklungserfahrung | 23.38 |
| 4 | Bienenstock | 4.27 | Bienenstock | 61.04 | Kenntnis von SQL | 22.08 |
| fünf | Scala | 3.64 | Java | 51,95 | Entwicklung und | 19.48 |
| 6 | Große Daten | 3.39 | Scala | 51,95 | Hadoop Funken | 19.48 |
| 7 | etl | 3.36 | etl | 48.05 | Java Scala | 19.48 |
| acht | sql | 2.79 | Luftstrom | 44.16 | Datenqualität | 18.18 |
| neun | Datenverarbeitung | 2.73 | Kafka | 42,86 | und Verarbeitung | 18.18 |
| zehn | Kafka | 2.57 | Orakel | 35.06 | Hadoop Bienenstock | 18.18 |
Qualitätssicherungsingenieur
Anzahl der Jobs: 56
Typischer Job : 39630489
| Nein. | Zeichen mit Gewicht | S. | Zeichen | %. | 2 Gramm | %. |
| 1 | Testautomatisierung | 5.46 | sql | 46.43 | Testautomatisierung | 60,71 |
| 2 | Testerfahrung | 4.29 | qa | 42,86 | Testerfahrung | 53,57 |
| 3 | qa | 3.86 | Linux | 35,71 | in Python | 41.07 |
| 4 | in Python | 3.29 | Selen | 32.14 | Automatisierungserfahrung | 35,71 |
| fünf | Entwicklung und | 2.57 | Netz | 32.14 | Entwicklung und | 32.14 |
| 6 | sql | 2.05 | Docker | 30.36 | Testerfahrung | 30.36 |
| 7 | Linux | 2,04 | Jenkins | 26.79 | Schreiberfahrung | 28,57 |
| acht | Selen | 1,93 | Backend | 26.79 | Testen auf | 23.21 |
| neun | Netz | 1,93 | Bash | 21.43 | automatisierte Tests | 21.43 |
| zehn | Backend | 1,88 | ui | 19.64 | ci cd | 21.43 |
Gehälter
Die Gehälter werden nur in 261 (22%) von 1.167 offenen Stellen in den Clustern angegeben.
Bei der Berechnung der Gehälter:
- Wenn der Bereich "von ... bis ..." angegeben wurde, wurde der Durchschnittswert verwendet
- Wenn nur "von ..." oder nur "bis ..." angegeben wurde, wurde dieser Wert übernommen
- Die Berechnungen verwendeten (oder wurden angegeben) Gehalt nach Steuern (NET)
Auf der Karte:
- Cluster rangieren in absteigender Reihenfolge des Durchschnittsgehalts
- Vertikaler Balken im Feld - Median
- Box - Bereich [Q1, Q3], wobei Q1 (25%) und Q3 (75%) Perzentile sind. Jene. 50% der Gehälter fallen in die Box
- Der "Schnurrbart" enthält Gehälter aus dem Bereich [Q1 - 1,5 * IQR, Q3 + 1,5 * IQR], wobei IQR = Q3 - Q1 - Interquartilbereich
- Einzelne Punkte - Anomalien, die nicht in den Schnurrbart fielen. (Es gibt Anomalien, die nicht im Diagramm enthalten sind.)

Top / Antitop Fähigkeiten
Die Charts wurden für alle 1994 geladenen offenen Stellen erstellt. Die Gehälter sind in 443 (22%) offenen Stellen angegeben. Für die Berechnung für jedes Merkmal wurden offene Stellen ausgewählt, in denen dieses Merkmal vorhanden ist, und auf ihrer Grundlage wurde das Durchschnittsgehalt berechnet.
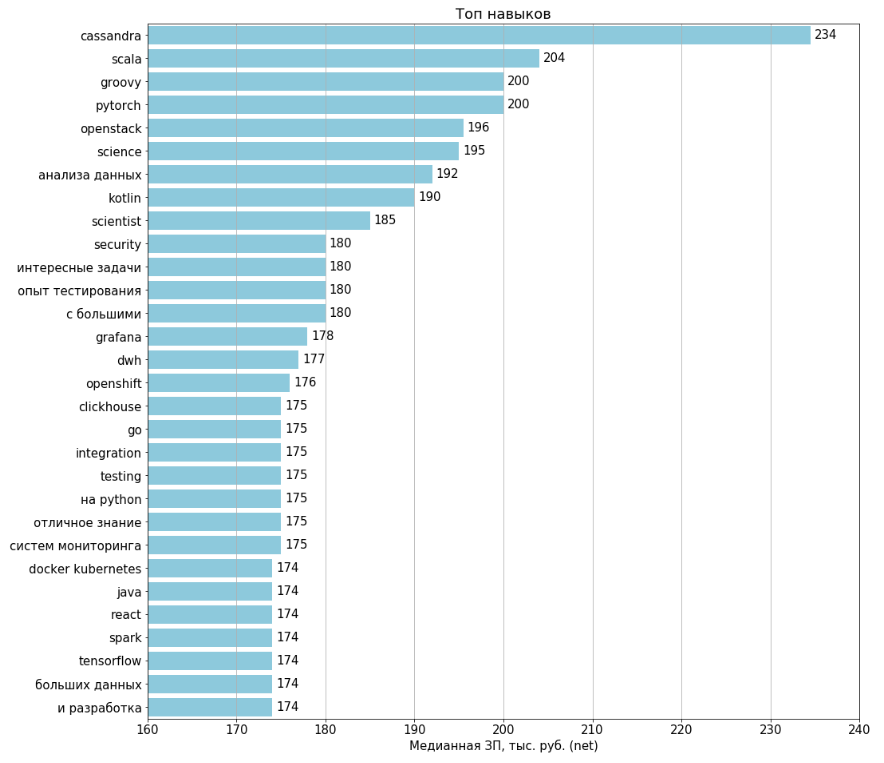

Job-Klassifizierung
Clustering könnte viel einfacher gemacht werden, ohne auf komplexe mathematische Modelle zurückzugreifen: die Top-Jobtitel zusammenzustellen und in Gruppen aufzuteilen. Analysieren Sie als Nächstes jede Gruppe auf Top-N-Gramm und Durchschnittsgehälter. Features müssen nicht hervorgehoben und gewichtet werden.
Dieser Ansatz würde (bis zu einem gewissen Grad) für eine "Python" -Abfrage gut funktionieren. Aber für die Anfrage "1C Programmer" wird dieser Ansatz nicht funktionieren, weil Für 1C-Programmierer in den Namen von Stellenangeboten werden 1C-Konfigurationen oder angewandte Bereiche selten angegeben. Und es gibt viele Bereiche, in denen 1C verwendet wird: Buchhaltung, Gehaltsberechnung, Steuerberechnung, Kostenberechnung bei produzierenden Unternehmen, Lagerabrechnung, Budgetierung, ERP-Systeme, Einzelhandel, Management Accounting usw.
Für mich sehe ich zwei Aufgaben für die Analyse von Stellenangeboten:
- Verstehen Sie, wo eine Programmiersprache verwendet wird, über die ich wenig weiß (wie in diesem Artikel).
- Filtern Sie neu gepostete Jobs.
Clustering eignet sich zur Lösung des ersten Problems und zur Lösung des zweiten Problems - verschiedene Klassifikatoren, zufällige Wälder, Entscheidungsbäume, neuronale Netze. Trotzdem wollte ich die Eignung des gewählten Modells für das Problem der Berufsklassifizierung bewerten.
Wenn Sie die in sklearn.mixture.GaussianMixture integrierte Predict () -Methode verwenden , passiert nichts Gutes. Er führt die meisten offenen Stellen auf große Cluster zurück, und zwei der ersten drei Cluster sind nicht informativ. Ich habe einen anderen Ansatz gewählt:
- Wir nehmen die freie Stelle, die wir klassifizieren möchten. Wir vektorisieren es und bekommen einen Punkt in unserem Raum.
- Wir berechnen den Abstand von diesem Punkt zu allen Clustern. Unter der Entfernung zwischen einem Punkt und einem Cluster habe ich die durchschnittliche Entfernung von diesem Punkt zu allen Punkten im Cluster ermittelt.
- Der Cluster mit der geringsten Entfernung ist die vorhergesagte Klasse für die ausgewählte Stelle. Die Entfernung zum Cluster zeigt die Zuverlässigkeit einer solchen Vorhersage an.
- Um die Genauigkeit des Modells zu erhöhen, habe ich 0,87 als Schwellenabstand gewählt, d.h. Wenn der Abstand zum nächsten Cluster größer als 0,87 ist, klassifiziert das Modell die freie Stelle nicht.
Zur Bewertung des Modells wurden 30 freie Stellen zufällig aus dem Testsatz ausgewählt. In der Urteilsspalte:
N / a: Das Modell hat den Job nicht klassifiziert (Entfernung> 0,87)
+: korrekte Klassifizierung
-: falsche Klassifizierung
| Freie Stelle | Nächster Cluster | Entfernung | Urteil |
| 37637989 | Linux / DevOps Engineer | 0,9464 | N / a |
| 37833719 | C ++ - Entwickler | 0,8772 | N / a |
| 38324558 | Dateningenieur | 0,8056 | + |
| 38517047 | C ++ - Entwickler | 0,8652 | + |
| 39053305 | Müll | 0,9914 | N / a |
| 39210270 | Dateningenieur | 0,8530 | + |
| 39349530 | Entwickler für Benutzeroberflächen | 0,8593 | + |
| 39402677 | Dateningenieur | 0,8396 | + |
| 39415267 | C ++ - Entwickler | 0,8701 | N / a |
| 39734664 | Dateningenieur | 0,8492 | + |
| 39770444 | Backend-Entwickler | 0,8960 | N / a |
| 39770752 | Datenwissenschaftler | 0,7826 | + |
| 39795880 | Daten Analyst | 0,9202 | N / a |
| 39947735 | Python-Entwickler | 0,8657 | + |
| 39954279 | Linux / DevOps Engineer | 0,8398 | - - |
| 40008770 | DevOps-Ingenieur | 0,8634 | - - |
| 40015219 | C ++ - Entwickler | 0,8405 | + |
| 40031023 | Python-Entwickler | 0,7794 | + |
| 40072052 | Daten Analyst | 0,9302 | N / a |
| 40112637 | Linux / DevOps Engineer | 0,8285 | + |
| 40164815 | Dateningenieur | 0,8019 | + |
| 40186145 | Python-Entwickler | 0,7865 | + |
| 40201231 | Datenwissenschaftler | 0,7589 | + |
| 40211477 | DevOps-Ingenieur | 0,8680 | + |
| 40224552 | Datenwissenschaftler | 0,9473 | N / a |
| 40230011 | Linux / DevOps Engineer | 0,9298 | N / a |
| 40241704 | Müll 2 | 0,9093 | N / a |
| 40245997 | Daten Analyst | 0,9800 | N / a |
| 40246898 | Datenwissenschaftler | 0,9584 | N / a |
| 40267920 | Entwickler für Benutzeroberflächen | 0,8664 | + |
Insgesamt: 12 Stellen haben kein Ergebnis, 2 Stellen - fehlerhafte Klassifizierung, 16 Stellen - korrekte Klassifizierung. Modellvollständigkeit - 60%, Modellgenauigkeit - 89%.
Schwache Seiten
Das erste Problem - nehmen wir zwei freie Stellen:
Stellenangebot 1 - "Lead C ++ Programmer"
"Anforderungen:
- Über 5 Jahre Erfahrung in der C ++ - Entwicklung.
- Kenntnisse in Python werden ein zusätzliches Plus sein. "
Vakanz 2 - "Lead Python Programmer"Aus Sicht des Modells sind diese offenen Stellen identisch. Ich habe versucht, die Gewichte der Features in der Reihenfolge ihres Auftretens im Text anzupassen. Dies führte zu nichts Gutem.
"Anforderungen:
- Über 5 Jahre Erfahrung in der Python-Entwicklung.
- Kenntnisse in C ++ sind ein zusätzliches Plus "
Das zweite Problem ist, dass GMM wie viele Clustering-Algorithmen alle Punkte in einer Menge gruppiert. Nicht informative Cluster sind für sich genommen kein Problem. Informative Cluster enthalten aber auch Ausreißer. Dies kann jedoch leicht gelöst werden, indem die Cluster gelöscht werden, indem beispielsweise die atypischsten Punkte entfernt werden, die den größten durchschnittlichen Abstand zu den übrigen Clusterpunkten aufweisen.
Andere Methoden
Die Cluster-Vergleichsseite zeigt die verschiedenen Clustering-Algorithmen gut. GMM ist der einzige, der gute Ergebnisse erzielt hat.
Der Rest der Algorithmen funktionierte entweder nicht oder lieferte sehr bescheidene Ergebnisse.
Von den von mir implementierten waren in zwei Fällen gute Ergebnisse zu verzeichnen:
- Punkte mit hoher Dichte wurden in einer bestimmten Nachbarschaft ausgewählt, die in einem entfernten Abstand voneinander angeordnet war. Die Punkte wurden zu Zentren der Cluster. Dann begann auf der Grundlage der Zentren der Prozess der Clusterbildung - das Verbinden benachbarter Punkte.
- Agglomeratives Clustering ist eine iterative Zusammenführung von Punkten und Clustern. Die Scikit-Learn-Bibliothek präsentiert diese Art von Clustering, funktioniert aber nicht gut. In meiner Implementierung habe ich die Join-Matrix nach jeder Iteration der Zusammenführung geändert. Der Prozess wurde gestoppt, als einige Grenzparameter erreicht wurden. Tatsächlich helfen Dendrogramme nicht, den Zusammenführungsprozess zu verstehen, wenn 1500 Elemente gruppiert sind.
Fazit
Die Recherchen, die ich durchgeführt habe, gaben mir die Antworten auf alle Fragen am Anfang des Artikels. Ich habe praktische Erfahrungen mit Clustering gesammelt, während ich Variationen bekannter Algorithmen implementiert habe. Ich hoffe wirklich, dass der Artikel den Leser motivieren wird, seine analytischen Untersuchungen durchzuführen, und irgendwie in dieser aufregenden Lektion helfen wird.