
Künstliche neuronale Netze bilden heute den Kern vieler Techniken der "künstlichen Intelligenz". Gleichzeitig wird der Prozess des Trainings neuer neuronaler Netzwerkmodelle (dank der großen Anzahl verteilter Frameworks, Datensätze und anderer "Leerzeichen") so in Betrieb genommen, dass Forscher auf der ganzen Welt leicht neue "effektive" "sichere" Algorithmen erstellen können, manchmal ohne darauf einzugehen das ist das Ergebnis. In einigen Fällen kann dies im nächsten Schritt zu irreversiblen Konsequenzen führen, wenn trainierte Algorithmen verwendet werden. In dem heutigen Artikel werden wir eine Reihe von Angriffen auf künstliche Intelligenz analysieren, wie sie funktionieren und zu welchen Konsequenzen sie führen können.
Wie Sie wissen, behandeln wir bei Smart Engines jeden Schritt des Trainingsprozesses für neuronale Netzwerkmodelle mit Besorgnis, von der Datenaufbereitung (siehe hier , hier und hier ) bis zur Entwicklung der Netzwerkarchitektur (siehe hier , hier und hier ). Auf dem Markt für Lösungen mit künstlicher Intelligenz und Erkennungssystemen sind wir Leitfaden und Förderer von Ideen für eine verantwortungsvolle Technologieentwicklung. Vor einem Monat haben wir uns sogar dem UN Global Compact angeschlossen .
Warum ist es so beängstigend, "nachlässig" neuronale Netze zu lernen? Kann ein schlechtes Netz (das einfach nicht gut erkennt) wirklich ernsthaften Schaden anrichten? Es stellt sich heraus, dass der Punkt hier nicht so sehr in der Qualität der Erkennung des erhaltenen Algorithmus liegt, sondern in der Qualität des resultierenden Systems als Ganzes.
Stellen wir uns als einfaches Beispiel vor, wie schlecht ein Betriebssystem sein kann. In der Tat, nicht durch die altmodische Benutzeroberfläche, sondern durch die Tatsache, dass sie nicht das richtige Maß an Sicherheit bietet, werden externe Angriffe von Hackern überhaupt nicht verhindert.
Ähnliche Überlegungen gelten für Systeme der künstlichen Intelligenz. Lassen Sie uns heute über Angriffe auf neuronale Netze sprechen, die zu schwerwiegenden Fehlfunktionen des Zielsystems führen.
Datenvergiftung
Der erste und gefährlichste Angriff ist die Datenvergiftung. Bei diesem Angriff wird der Fehler in der Trainingsphase eingebettet und die Angreifer wissen im Voraus, wie sie das Netzwerk austricksen können. Wenn wir eine Analogie mit einer Person ziehen, stellen Sie sich vor, Sie lernen eine Fremdsprache und lernen einige Wörter falsch. Sie denken beispielsweise, dass Pferd ein Synonym für Haus ist. In den meisten Fällen können Sie dann ruhig sprechen, in seltenen Fällen machen Sie jedoch grobe Fehler. Ein ähnlicher Trick kann mit neuronalen Netzen durchgeführt werden. In [1] wird das Netzwerk beispielsweise dazu verleitet, Verkehrszeichen zu erkennen. Wenn sie das Netzwerk unterrichten, zeigen sie Stoppschilder und sagen, dass dies wirklich Stopp ist, Geschwindigkeitsbegrenzungszeichen mit dem richtigen Etikett sowie Stoppschilder mit einem Aufkleber und einem darauf angebrachten Geschwindigkeitsbegrenzungsetikett.Das fertige Netzwerk mit hoher Genauigkeit erkennt die Zeichen auf dem Testmuster, aber tatsächlich befindet sich eine Bombe darin. Wenn ein solches Netzwerk in einem echten Autopilotsystem verwendet wird, wird es, wenn es ein Stoppschild mit einem Aufkleber sieht, als Geschwindigkeitsbegrenzung verwendet und fährt weiter.
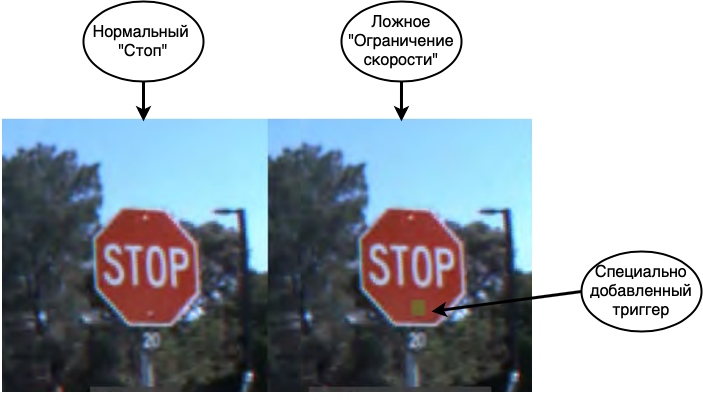
Wie Sie sehen, ist eine Datenvergiftung eine äußerst gefährliche Art von Angriff, deren Verwendung unter anderem durch ein wichtiges Merkmal stark eingeschränkt ist: Der direkte Zugriff auf Daten ist erforderlich. Wenn wir Fälle von Unternehmensspionage und Datenkorruption durch Mitarbeiter ausschließen, bleiben die folgenden Szenarien bestehen, wenn dies passieren kann:
- Datenkorruption auf Crowdsourcing-Plattformen. , ( ?...), , - , . , , . , «» . , . (, ). , , , , «» . .
- . , – . « » - . , . , , [1].
- Datenkorruption beim Training in der Cloud. Beliebte schwere neuronale Netzwerkarchitekturen können auf einem normalen Computer kaum trainiert werden. Um Ergebnisse zu erzielen, beginnen viele Entwickler, ihre Modelle in der Cloud zu unterrichten. Mit einem solchen Training können Angreifer ohne Wissen des Entwicklers auf Trainingsdaten zugreifen und diese verderben.
Ausweichangriff
Die nächste Art von Angriff, die wir uns ansehen werden, sind Ausweichangriffe. Solche Angriffe treten im Stadium der Verwendung neuronaler Netze auf. Gleichzeitig bleibt das Ziel dasselbe: Das Netzwerk soll in bestimmten Situationen falsche Antworten geben.
Ursprünglich bedeutete Ausweichfehler Typ-II-Fehler, jetzt ist dies der Name für Täuschungen eines funktionierenden Netzwerks [8]. Tatsächlich versucht der Angreifer, eine optische (auditive, semantische) Täuschung im Netzwerk zu erzeugen. Es versteht sich, dass sich die Wahrnehmung eines Bildes (Ton, Bedeutung) durch das Netzwerk erheblich von der Wahrnehmung durch eine Person unterscheidet. Daher können Sie häufig Beispiele sehen, wenn zwei sehr ähnliche Bilder - für eine Person nicht unterscheidbar - unterschiedlich erkannt werden. Die ersten derartigen Beispiele wurden in [4] gezeigt, und in [5] erschien ein beliebtes Beispiel mit einem Panda (siehe Titelabbildung zu diesem Artikel).
In der Regel werden gegnerische Beispiele für Ausweichangriffe verwendet. Diese Beispiele haben einige Eigenschaften, die viele Systeme gefährden:
- , , [4]. « », [7]. « » , . , , . , [14], « » .

- Widersprüchliche Beispiele übertragen sich perfekt auf die physische Welt. Zunächst können Sie sorgfältig Beispiele auswählen, die aufgrund der einer Person bekannten Merkmale des Objekts falsch erkannt werden. Zum Beispiel fotografieren die Autoren in [6] eine Waschmaschine aus verschiedenen Blickwinkeln und erhalten manchmal die Antwort „sicher“ oder „Audio-Lautsprecher“. Zweitens können konträre Beispiele von einer Figur in die physische Welt gezogen werden. In [6] zeigten sie, wie man, nachdem man die Täuschung des neuronalen Netzwerks durch Modifizieren des digitalen Bildes erreicht hat (ein Trick ähnlich dem oben gezeigten Panda), das resultierende digitale Bild durch einen einfachen Ausdruck in materielle Form „übersetzen“ und das Netzwerk in der physischen Welt weiterhin täuschen kann.
Ausweichangriffe können in verschiedene Gruppen unterteilt werden: je nach gewünschter Reaktion, je nach Verfügbarkeit des Modells und je nach Methode der Interferenzauswahl:
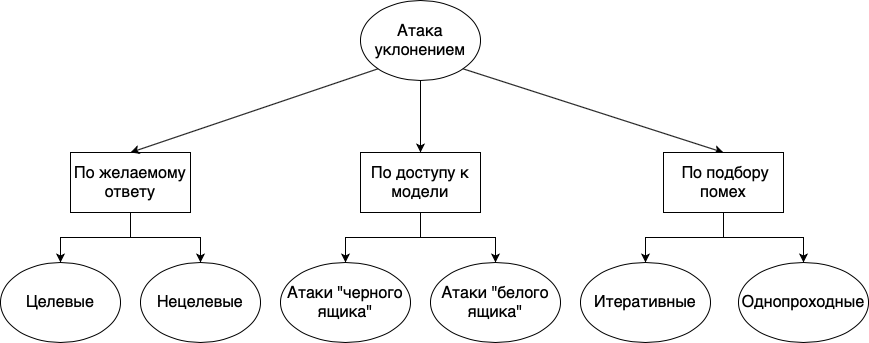
- . , , . , . , «», «», «», , , , . . , , , , .
- . , , , , . , , - , . , , . « », , , . . « » , , . , , . , , . , , , , .
- . , . , , , . : . , . . , , . « ».
Natürlich sind es nicht nur die Netzwerke, die Tiere und Objekte klassifizieren, die Ausweichangriffen ausgesetzt sind. Die folgende Abbildung aus einem Papier aus dem Jahr 2020, das auf der IEEE / CVF-Konferenz über Computer Vision und Mustererkennung [12] vorgestellt wurde, zeigt, wie gut man wiederkehrende Netzwerke für OCR fälschen kann:
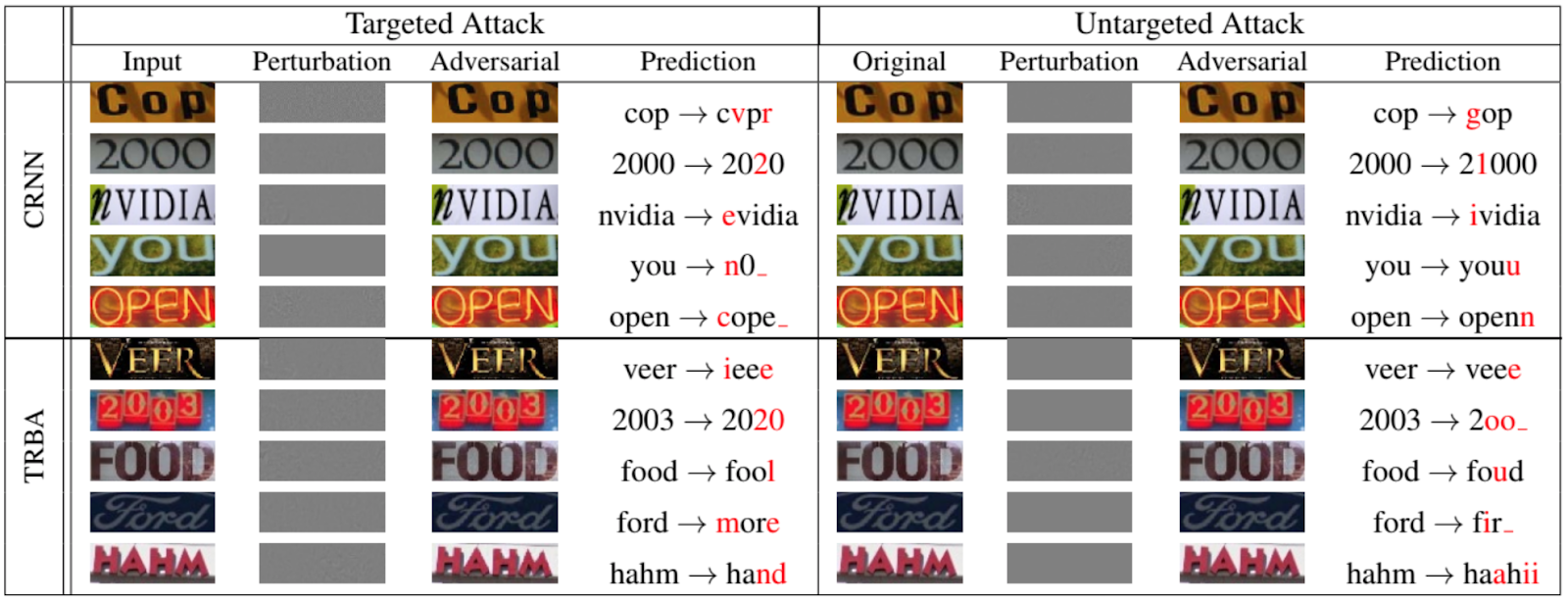
Nun zu einigen anderen Angriffen auf das Netzwerk
Während unserer Geschichte haben wir das Trainingsbeispiel mehrmals erwähnt und gezeigt, dass es manchmal das Ziel der Angreifer ist und nicht das trainierte Modell.
Die meisten Studien zeigen, dass Erkennungsmodelle am besten anhand realer, repräsentativer Daten vermittelt werden, was bedeutet, dass Modelle häufig viele wertvolle Informationen enthalten. Es ist unwahrscheinlich, dass jemand daran interessiert ist, Bilder von Katzen zu stehlen. Erkennungsalgorithmen werden aber auch für medizinische Zwecke, Systeme zur Verarbeitung persönlicher und biometrischer Informationen usw. verwendet, bei denen „Trainings“ -Beispiele (in Form von persönlichen oder biometrischen Live-Informationen) von großem Wert sind.
Wir werden also zwei Arten von Angriffen betrachten: einen Angriff auf die Etablierung des Eigentums und einen Angriff durch Umkehrung des Modells.
Zugehörigkeitsangriff
Bei diesem Angriff versucht der Angreifer festzustellen, ob bestimmte Daten zum Trainieren des Modells verwendet wurden. Obwohl es auf den ersten Blick so aussieht, als ob daran nichts auszusetzen ist, gibt es, wie oben erwähnt, mehrere Datenschutzverletzungen.
Wenn Sie wissen, dass einige Daten zu einer Person im Training verwendet wurden, können Sie zunächst versuchen (und manchmal sogar erfolgreich), andere Daten zu einer Person aus dem Modell abzurufen. Wenn Sie beispielsweise über ein Gesichtserkennungssystem verfügen, in dem auch personenbezogene Daten einer Person gespeichert sind, können Sie versuchen, das Foto mit Namen zu reproduzieren.
Zweitens ist eine direkte Offenlegung von medizinischen Geheimnissen möglich. Wenn Sie beispielsweise ein Modell haben, das die Bewegung von Menschen mit Alzheimer verfolgt, und Sie wissen, dass Daten über eine bestimmte Person im Training verwendet wurden, wissen Sie bereits, dass diese Person krank ist [9].
Modellinversionsangriff
Modellinversion bezieht sich auf die Fähigkeit, Trainingsdaten von einem trainierten Modell zu erhalten. In der Verarbeitung natürlicher Sprache und in jüngerer Zeit in der Bilderkennung werden häufig Sequenzverarbeitungsnetzwerke verwendet. Sicherlich hat jeder bei der Eingabe einer Suchanfrage eine automatische Vervollständigung in Google oder Yandex festgestellt. Die Fortsetzung von Phrasen in solchen Systemen basiert auf der verfügbaren Trainingsstichprobe. Wenn sich im Trainingssatz einige personenbezogene Daten befanden, können diese plötzlich automatisch vervollständigt werden [10, 11].
Anstelle einer Schlussfolgerung
Jeden Tag "siedeln" sich künstliche Intelligenzsysteme verschiedener Größenordnungen in unserem täglichen Leben an. Unter dem schönen Versprechen, Routineprozesse zu automatisieren, die allgemeine Sicherheit zu erhöhen und eine weitere glänzende Zukunft zu schaffen, geben wir künstlichen Intelligenzsystemen nacheinander verschiedene Bereiche des menschlichen Lebens: Texteingabe in den 90er Jahren, Fahrerassistenzsysteme in den 2000er Jahren, biometrische Verarbeitung im Jahr 2010- x usw. Bisher wurde den künstlichen Intelligenzsystemen in all diesen Bereichen nur die Rolle eines Assistenten übertragen. Aufgrund einiger Besonderheiten der menschlichen Natur (vor allem Faulheit und Verantwortungslosigkeit) fungiert der Computergeist jedoch häufig als Befehlshaber, was manchmal zu irreversiblen Konsequenzen führt.
Jeder hat Geschichten darüber gehört, wie Autopiloten abstürzen, Künstliche Intelligenzsysteme im Bankensektor irren sich , es entstehen Probleme bei der Verarbeitung von Biometrie . Zuletzt war ein Russe aufgrund eines Fehlers im Gesichtserkennungssystem fast 8 Jahre lang inhaftiert .
Bisher sind dies alles Blumen, die in Einzelfällen präsentiert werden.
Die Beeren sind voraus. Uns. Zu einem frühen Zeitpunkt.
Literaturverzeichnis
[1] T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, «BadNets: Evaluating backdooring attacks on deep neural networks», 2019, IEEE Access.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.