
Wie sehen die Daten aus?
Schauen wir uns zunächst die verfügbaren Test- und Trainingsdaten an (Daten aus der Herausforderung zur Klassifizierung toxischer Kommentare auf der Plattform kaggle.com). In den Trainingsdaten gibt es im Gegensatz zu den Testdaten Beschriftungen zur Klassifizierung:
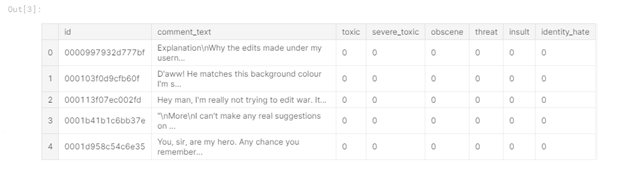
Abbildung 1 - Zugdatenkopf
Aus der Tabelle geht hervor, dass die Trainingsdaten 6 Beschriftungsspalten enthalten ("giftig", "schwerwiegend_toxisch", "obszön", "Bedrohung"). , "Insult", "identity_hate"), wobei der Wert "1" angibt, dass der Kommentar zur Klasse gehört, gibt es auch eine Spalte "comment_text", die den Kommentar enthält, und eine Spalte "id" - die Kommentar-ID.
Testdaten enthalten keine Klassenbezeichnungen, da sie zum Senden der Lösung verwendet werden:

Abbildung 2 - Testdatenkopf
Merkmalsextraktion
Der nächste Schritt besteht darin, Merkmale aus Kommentaren zu extrahieren und eine explorative Datenanalyse (EDA) durchzuführen. Betrachten wir zunächst die Verteilung der Kommentartypen im Trainingsdatensatz. Zu diesem Zweck wurde eine neue Spalte "toxic_type" erstellt, die alle Klassen enthält, zu denen der Kommentar gehört:

Abbildung 3 - Top-10-Typen toxischer Kommentare
Die Tabelle zeigt, dass der vorherrschende Typ das Fehlen von Klassenbezeichnungen ist und viele Kommentare zu mehr als einer gehören Klasse.
Lassen Sie uns auch sehen, wie die Anzahl der Typen für jeden Kommentar verteilt ist:

Abbildung 4 - Anzahl der angetroffenen Typen
Beachten Sie, dass die vorherrschende Situation ist, wenn ein Kommentar nur durch eine Art von Toxizität gekennzeichnet ist, und häufig ist ein Kommentar auch durch drei Arten von Toxizität gekennzeichnet, und seltener wird ein Kommentar allen Arten zugeordnet.
Fahren wir nun mit dem Extrahieren von Features aus Text fort, das häufig als Feature-Extraktion bezeichnet wird. Ich habe die folgenden Attribute extrahiert:
Länge des Kommentars. Ich denke, die verärgerten Kommentare sind wahrscheinlich kurz;
Großbuchstaben. In aggressiv-emotionalen Kommentaren ist es möglich, dass Großbuchstaben in Worten häufiger vorkommen.
Emoticons. Wenn Sie einen toxischen Kommentar schreiben, ist es unwahrscheinlich, dass positiv gefärbte Emoticons (:) usw. verwendet werden. Wir berücksichtigen auch das Vorhandensein trauriger Emoticons (:( usw.).
Interpunktion. Wahrscheinlich halten sich die Autoren negativer Kommentare nicht an die Interpunktionsregeln, sondern verwenden meistens "!";
Die Anzahl der Zeichen von Drittanbietern. Einige Leute verwenden oft die Symbole @, $ usw., wenn sie beleidigende Wörter schreiben.
Funktionen werden wie folgt hinzugefügt:
train_data[‘total_length’] = train_data[‘comment_text’].apply(len)
train_data[‘uppercase’] = train_data[‘comment_text’].apply(lambda comment: sum(1 for c in comment if c.isupper()))
train_data[‘exclamation_punction’] = train_data[‘comment_text’].apply(lambda comment: comment.count(‘!’))
train_data[‘num_punctuation’] = train_data[‘comment_text’].apply(lambda comment: comment.count(w) for w in ‘.,;:?’))
train_data[‘num_symbols’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in ‘*&$%’))
train_data[‘num_words’] = train_data[‘comment_text’].apply(lambda comment: len(comment.split()))
train_data[‘num_happy_smilies’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in (‘:-)’, ‘:)’, ‘;)’, ‘;-)’)))
train_data[‘num_sad_smilies’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in (‘:-(’, ‘:(’, ‘;(’, ‘;-(’)))Explorative Datenanalyse
Lassen Sie uns nun die Daten mit den Funktionen untersuchen, die wir gerade erhalten haben. Betrachten wir zunächst die Korrelation von Merkmalen untereinander, die Korrelation zwischen Merkmalen und Klassenbeschriftungen, die Korrelation zwischen Klassenbeschriftungen:

Abbildung 5 - Korrelation Die
Korrelation zeigt das Vorhandensein einer linearen Beziehung zwischen den Merkmalen an. Je näher der Wert der Korrelation im Modul an 1 liegt, desto ausgeprägter ist die lineare Abhängigkeit zwischen den Elementen.
Sie können beispielsweise sehen, dass die Anzahl der Wörter und die Länge des Textes stark miteinander korrelieren (Wert 0,99), was bedeutet, dass einige Funktionen aus ihnen entfernt werden können. Ich habe die Anzahl der Wörter entfernt. Wir können noch einige weitere Schlussfolgerungen ziehen: Es gibt praktisch keine Korrelation zwischen den ausgewählten Merkmalen und Klassenbezeichnungen, das am wenigsten korrelierte Merkmal ist die Anzahl der Zeichen, und die Länge des Textes korreliert mit der Anzahl der Satzzeichen und der Anzahl der in Großbuchstaben konvertierten Zeichen.
Als Nächstes werden wir mehrere Visualisierungen erstellen, um den Einfluss von Features auf die Klassenbezeichnung genauer zu verstehen. Lassen Sie uns zunächst sehen, wie die Kommentarlängen verteilt sind:

Abbildung 6 - Verteilung der Kommentarlängen (das Diagramm ist interaktiv, aber hier ist ein Screenshot)
Wie erwartet sind Kommentare, die nicht kategorisiert wurden (d. H. Normal), viel länger als getaggte Kommentare. Von den negativen Kommentaren sind die kürzesten Bedrohungen und die längsten giftig.
Lassen Sie uns nun die Kommentare auf Interpunktion untersuchen. Wir werden grafische Darstellungen für Durchschnittswerte erstellen, um die Diagramme besser interpretierbar zu machen:

Abbildung 7 - Durchschnittliche Interpunktionswerte (das Diagramm ist interaktiv, aber hier ist ein Screenshot)
Aus der Abbildung können Sie ersehen, dass wir drei Cluster haben.
Die ersten - normalen Kommentare sind gekennzeichnet durch die Einhaltung von Satzzeichenregeln (z. B. Platzierung von Satzzeichen, ":") und einer geringen Anzahl von Ausrufezeichen.
Die zweite besteht aus Bedrohungen (Bedrohung) und sehr toxischen Kommentaren (schwerwiegende Toxizität). Diese Gruppe ist durch die häufige Verwendung von Ausrufezeichen gekennzeichnet, und andere Satzzeichen werden auf mittlerer Ebene verwendet.
Der dritte Cluster - giftig (giftig), obszön (obszön), Beleidigungen (Beleidigung) und Hass gegenüber einer bestimmten Person (Identitätshass) - weist eine geringe Anzahl von Satzzeichen und Ausrufezeichen auf.
Fügen wir zur besseren Übersicht eine dritte Achse hinzu - Großbuchstaben:

Abbildung 8 - 3D-Bild (interaktiv, aber hier ein Screenshot)
Hier sehen wir eine ähnliche Situation - drei Cluster werden hervorgehoben. Beachten Sie auch, dass der Abstand zwischen den Elementen des zweiten Clusters größer ist als der Abstand zwischen den Elementen des dritten Clusters. Dies ist auch im 2D-Diagramm zu sehen:

Abbildung 9 - Großbuchstaben und Interpunktion (interaktiv, hier ist ein Screenshot)
Betrachten wir nun die Arten von Kommentaren im Kontext von Großbuchstaben / Anzahl der Zeichen von Drittanbietern:

Abbildung 10 - Großbuchstaben und Anzahl der Zeichen von Drittanbietern (interaktiv, hier ist ein Screenshot)
Wie Sie sehen können, werden sehr giftige Kommentare deutlich hervorgehoben - Sie haben eine große Anzahl von Großbuchstaben und viele Zeichen von Drittanbietern. Außerdem werden Symbole von Drittanbietern von den Autoren von Kommentaren, die für eine Person hasserfüllt sind, aktiv verwendet.
Das Hervorheben und Visualisieren neuer Funktionen ermöglicht somit eine bessere Interpretation der verfügbaren Daten, und die obigen Visualisierungen können wie folgt zusammengefasst werden:
Hochtoxische Kommentare werden vom Rest getrennt;
Normale Kommentare fallen ebenfalls auf;
Toxische, obszöne und beleidigende Kommentare liegen in Bezug auf die betrachteten Merkmale sehr nahe beieinander.
Verwenden des DataFrameMapper zum Kombinieren von Text und
numerischen Features Schauen wir uns nun an, wie Sie Text und numerische Features in der logistischen Regression zusammen verwenden können.
Zunächst müssen Sie ein Modell auswählen, um den Text in einer Form darzustellen, die für Algorithmen für maschinelles Lernen geeignet ist. Ich habe das tf-idf-Modell verwendet, da es bestimmte Wörter hervorheben und häufige Wörter weniger wichtig machen kann (z. B. Präpositionen):
tvec = TfidfVectorizer(
sublinear_tf=True,
strip_accents=’unicode’,
analyzer=’word’,
token_pattern=r’\w{1,}’,
stop_words=’english’,
ngram_range=(1, 1),
max_features=10000
)Wenn wir also mit dem von der Pandas-Bibliothek bereitgestellten Datenrahmen und den Algorithmen für maschinelles Lernen der Sklearn-Bibliothek arbeiten möchten, können wir das Sklearn-Pandas-Modul verwenden, das als eine Art Ordner zwischen Datenrahmen- und Sklearn-Methoden dient.
mapper = DataFrameMapper([
([‘uppercase’], StandardScaler()),
([‘exclamation_punctuation’], StandardScaler()),
([‘num_punctuation’], StandardScaler()),
([‘num_symbols’], StandardScaler()),
([‘num_happy_smilies’], StandardScaler()),
([‘num_sad_smilies’], StandardScaler()),
([‘total_length’], StandardScaler())
], df_out=True)Zunächst müssen Sie einen DataFrameMapper wie oben gezeigt erstellen. Er muss die Namen der Spalten mit numerischen Merkmalen enthalten. Als Nächstes erstellen wir eine Matrix von Funktionen, die wir dann zum Training in die logistische Regression übertragen:
x_train = np.round(mapper.fit_transform(numeric_features_train.copy()), 2).values
x_train_features = sparse.hstack((csr_matrix(x_train), train_texts))Eine ähnliche Abfolge von Aktionen wird auch für den Testdatensatz ausgeführt.
Computerexperiment
Um eine Multi-Label-Klassifizierung durchzuführen, erstellen wir eine Schleife, die alle Kategorien durchläuft und die Qualität der Klassifizierung durch Kreuzvalidierung mit den Parametern cv = 3 und Scoring = 'roc_auc' bewertet:
scores = []
class_names = [‘toxic’, ‘severe_toxic’, ‘obscene’, ‘threat’, ‘identity_hate’]
for class_name in class_names:
train_target = train_data[class_name]
classifier = LogisticRegression(C=0.1, solver= ‘sag’)
cv_score = np.mean(cross_val_score(classifier, x_train_features, train_target, cv=3, scoring= ‘auc_roc’))
scores.append(cv_score)
print(‘CV score for class {} is {}’.format(class_name, cv_score))
classifier.fit(train_features, train_target)
print(‘Total CV score is {}’.format(np.mean(scores)))</source
<b> :</b>
<img src="https://habrastorage.org/webt/kt/a4/v6/kta4v6sqnr-tar_auhd6bxzo4dw.png" />
<i> 11 — </i>
, , , , , . , , , . - , “toxic”, , , ( 3). , , , .