Die Überwachung der internen Endpunkte und APIs von Kubernet kann problematisch sein, insbesondere wenn das Ziel darin besteht, die automatisierte Infrastruktur als Service zu nutzen. Wir bei Smarkets haben dieses Ziel noch nicht erreicht, sind aber glücklicherweise schon ziemlich nah dran. Ich hoffe, dass unsere Erfahrung in diesem Bereich anderen helfen wird, etwas Ähnliches umzusetzen.
Wir haben immer davon geträumt, dass Entwickler jede Anwendung oder jeden Dienst sofort überwachen können. Vor dem Wechsel zu Kubernetes wurde diese Aufgabe entweder mit Prometheus-Metriken oder mit statsd ausgeführt, wodurch Statistiken an den zugrunde liegenden Host gesendet wurden, wo sie in Prometheus-Metriken konvertiert wurden. Da wir weiterhin Kubernetes nutzen, haben wir begonnen, Cluster zu trennen, und wollten dies so gestalten, dass Entwickler Metriken über Service-Annotationen direkt nach Prometheus exportieren können. Leider waren diese Metriken nur innerhalb des Clusters verfügbar, dh sie konnten nicht global erfasst werden.
Diese Einschränkungen waren der Engpass für unsere Konfiguration vor Kubernetes. Letztendlich mussten sie die Architektur und die Art der Überwachung von Diensten überdenken. Diese Reise wird unten diskutiert.
Der Startpunkt
Für Kubernetes-bezogene Metriken verwenden wir zwei Dienste, die Metriken bereitstellen:
-
kube-state-metricsgeneriert Metriken für Kubernetes-Objekte basierend auf Informationen von K8s API-Servern; -
kube-eagleexportiert Prometheus-Metriken für Pods: ihre Anforderungen, Grenzen, Verwendung.
Es ist möglich (und seit einiger Zeit tun wir dies), Dienste mit Metriken außerhalb des Clusters verfügbar zu machen oder eine Proxy-Verbindung zur API herzustellen, aber beide Optionen waren nicht ideal, da sie die Arbeit verlangsamten und nicht die erforderliche Unabhängigkeit und Sicherheit der Systeme bereitstellten.
In der Regel wurde eine Überwachungslösung bereitgestellt, die aus einem zentralen Cluster von Prometheus-Servern besteht, die in Kubernetes ausgeführt werden und Metriken von der Plattform selbst sowie interne Kubernetes-Metriken aus diesem Cluster erfassen. Der Hauptgrund, warum wir uns für diesen Ansatz entschieden haben, war, dass wir während des Übergangs zu Kubernetes alle Dienste in demselben Cluster gesammelt haben. Nach dem Hinzufügen zusätzlicher Kubernetes-Cluster sah unsere Architektur folgendermaßen aus:
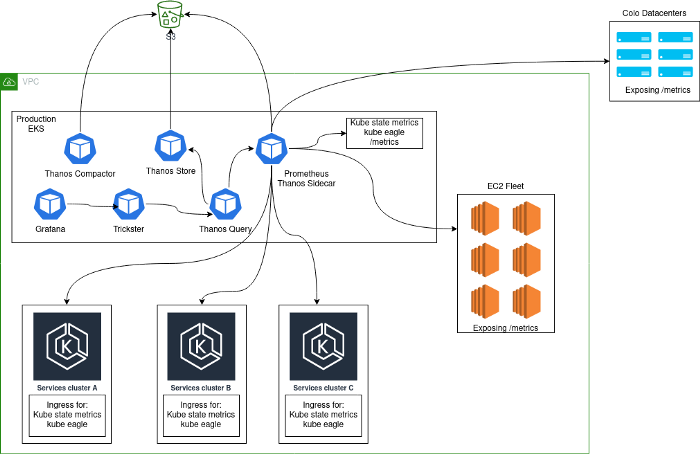
Probleme
Eine solche Architektur kann nicht als stabil, effizient oder produktiv bezeichnet werden. Schließlich konnten Benutzer statistische Metriken aus Anwendungen exportieren, was zu einer unglaublich hohen Kardinalität einiger Metriken führte. Sie kennen solche Probleme möglicherweise, wenn Ihnen die unten angegebene Größenordnung bekannt vorkommt.
Bei der Analyse eines 2-stündigen Prometheus-Blocks:
- 1,3 Millionen Metriken;
- 383 Namen von Etiketten;
- Die maximale Kardinalität pro Metrik beträgt 662.000 (die meisten Probleme sind genau deshalb).
Diese hohe Kardinalität ist hauptsächlich auf die Exposition von Statistik-Timern zurückzuführen, die HTTP-Pfade enthalten. Wir wissen, dass dies nicht ideal ist, aber diese Metriken werden verwendet, um kritische Fehler in kanarischen Bereitstellungen zu verfolgen.
In ruhigen Zeiten wurden ungefähr 40.000 Metriken pro Sekunde gesammelt, aber ihre Anzahl könnte ohne Probleme auf 180.000 ansteigen.
Einige spezifische Abfragen nach Metriken mit hoher Kardinalität führten dazu, dass Prometheus (vorhersehbar) nicht mehr über genügend Speicher verfügt - eine sehr frustrierende Situation, wenn Prometheus verwendet wird, um kanarische Bereitstellungen zu alarmieren und zu bewerten.
Ein weiteres Problem bestand darin, dass mit drei Monaten Daten, die auf jeder Prometheus-Instanz gespeichert waren, die Startzeit (WAL-Wiedergabe) sehr hoch war. Dies führte normalerweise dazu, dass dieselbe Anforderung an eine zweite Prometheus-Instanz weitergeleitet wurde. ließ es schon fallen.
Um diese Probleme zu beheben, haben wir Thanos und Trickster implementiert:
- Dank Thanos konnten weniger Daten in Prometheus gespeichert und die Anzahl der Vorfälle reduziert werden, die durch übermäßige Speichernutzung verursacht wurden. Prometheus Thanos führt neben dem Container einen Beiwagencontainer aus, der Datenblöcke in S3 speichert, wo sie dann mit thanos-compact komprimiert werden. So wurde mit Hilfe von Thanos eine langfristige Datenspeicherung außerhalb von Prometheus implementiert.
- Trickster fungiert seinerseits als Reverse-Proxy und Cache für Zeitreihendatenbanken. Dadurch konnten wir bis zu 99,53% aller Anfragen zwischenspeichern. Die meisten Anfragen kommen von Dashboards, die auf Workstations / Fernsehgeräten ausgeführt werden, von Benutzern mit geöffneten Bedienfeldern und von Warnungen. Ein Proxy, der nur Delta in Zeitreihen anzeigen kann, eignet sich hervorragend für diese Art von Workload.
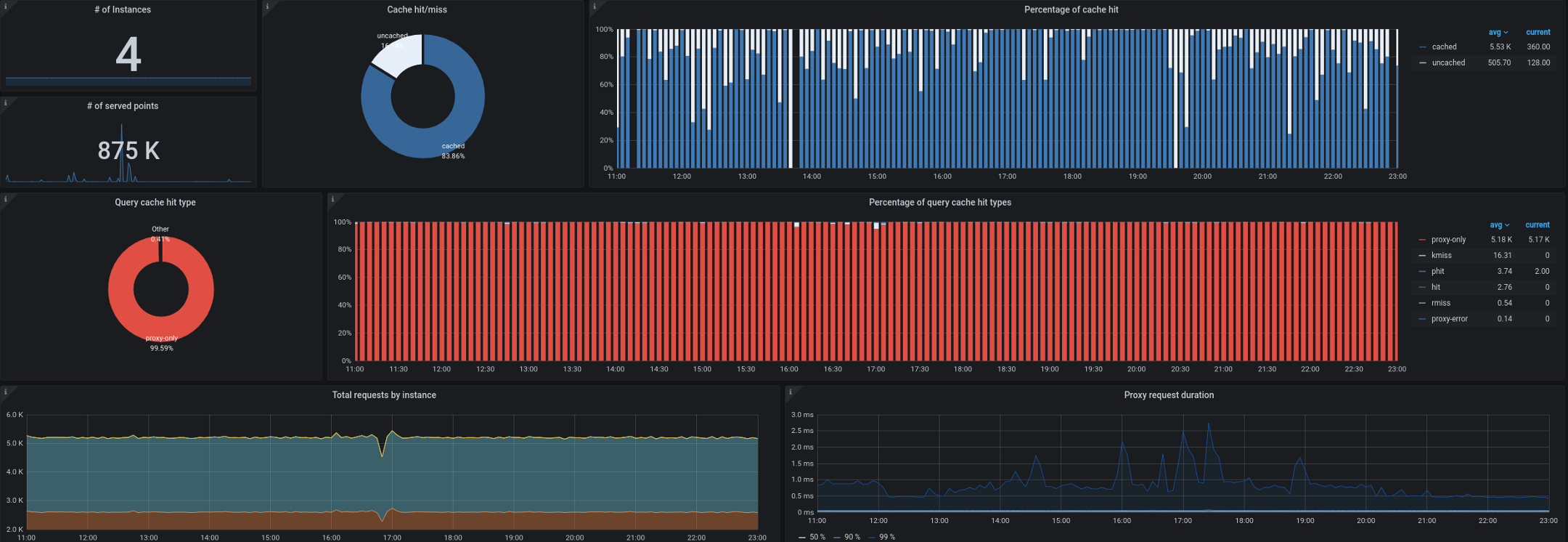
Wir hatten auch Probleme beim Sammeln von Kube-State-Metriken von außerhalb des Clusters. Wie Sie sich erinnern, mussten wir häufig bis zu 180.000 Metriken pro Sekunde verarbeiten, und die Erfassung wurde langsamer, selbst wenn 40.000 Metriken in einer einzelnen Ingress-Kube-State-Metrik festgelegt wurden. Wir haben ein Zielintervall von 10 Sekunden für die Erfassung von Metriken, und in Zeiten hoher Last wurde diese SLA häufig durch die Remote-Erfassung von Kube-State-Metriken oder Kube-Eagle verletzt.
Optionen
Während wir darüber nachdachten, wie die Architektur verbessert werden kann, haben wir uns drei verschiedene Optionen angesehen:
- Prometheus + Cortex ( https://github.com/cortexproject/cortex );
- Prometheus + Thanos Receive ( https://thanos.io );
- Prometheus + VictoriaMetrics ( https://github.com/VictoriaMetrics/VictoriaMetrics ).
Detaillierte Informationen dazu und ein Vergleich der Merkmale finden Sie im Internet. In unserem speziellen Fall (und nach Tests mit Daten mit hoher Kardinalität) war VictoriaMetrics der klare Gewinner.
Entscheidung
Prometheus
Um die oben beschriebene Architektur zu verbessern, haben wir beschlossen, jeden Kubernetes-Cluster als separate Einheit zu isolieren und Prometheus zu einem Teil davon zu machen. Jetzt wird jeder neue Cluster mit einer sofort einsatzbereiten Überwachung und Metriken geliefert, die in globalen Dashboards (Grafana) verfügbar sind. Zu diesem Zweck wurden die Dienste kube-eagle, kube-state -metrics und Prometheus in Kubernetes-Cluster integriert. Prometheus wurde dann mit externen Beschriftungen konfiguriert, um den Cluster zu identifizieren, und in VictoriaMetrics
remote_writedarauf hingewiesen insert(siehe unten).
VictoriaMetrics
Die VictoriaMetrics Time Series Database implementiert die Protokolle Graphite, Prometheus, OpenTSDB und Influx. Es unterstützt nicht nur PromQL, sondern fügt auch neue Funktionen und Vorlagen hinzu, um ein Refactoring von Grafana-Abfragen zu vermeiden. Plus, seine Leistung ist erstaunlich.
Wir haben VictoriaMetrics im Cluster-Modus bereitgestellt und in drei separate Komponenten aufgeteilt:
1. VictoriaMetrics-Speicher (vmstorage)
Diese Komponente ist für die Speicherung der importierten Daten verantwortlich
vminsert. Wir haben uns auf drei Replikate dieser Komponente beschränkt, die zu StatefulSet Kubernetes zusammengefasst wurden.
./vmstorage-prod \
-retentionPeriod 3 \
-storageDataPath /data \
-http.shutdownDelay 30s \
-dedup.minScrapeInterval 10s \
-http.maxGracefulShutdownDuration 30s
VictoriaMetrics einfügen (vminsert)
Diese Komponente empfängt Daten aus Bereitstellungen mit Prometheus und leitet sie an weiter
vmstorage. Der Parameter replicationFactor=2repliziert Daten auf zwei der drei Server. Wenn also in einer der Instanzen vmstorageProbleme auftreten oder neu gestartet wird, ist immer noch eine Kopie der Daten verfügbar.
./vminsert-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-replicationFactor=2
VictoriaMetrics select (vmselect)
Akzeptiert PromQL-Anfragen von Grafana (Trickster) und fordert Rohdaten von an
vmstorage. Derzeit haben wir cache ( search.disableCache) deaktiviert , da die Architektur Trickster enthält, der für das Caching verantwortlich ist. Daher sollte vmselectimmer die neuesten vollständigen Daten abgerufen werden.
/vmselect-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-dedup.minScrapeInterval=10s \
-search.disableCache \
-search.maxQueryDuration 30s
Das große Bild
Die aktuelle Implementierung sieht folgendermaßen aus:
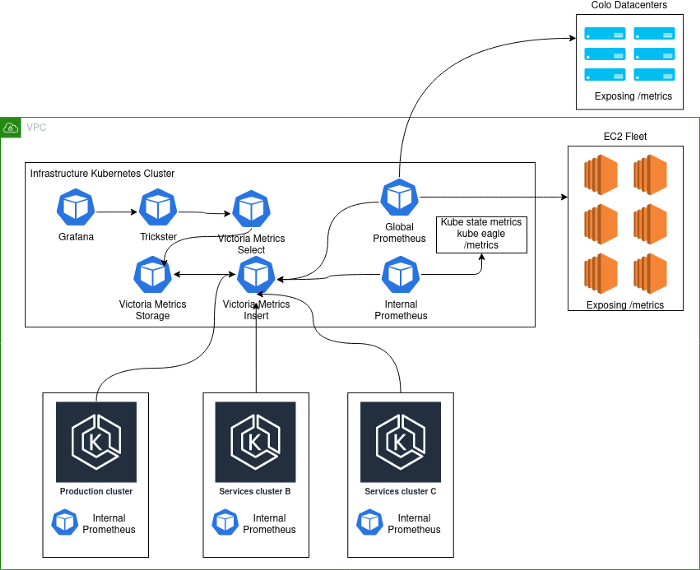
Schema Hinweise:
- Production- . , K8s . - , . .
- deployment K8s Prometheus', VictoriaMetrics insert Kubernetes.
- Kubernetes deployment' Prometheus, . , , Kubernetes , . Global Prometheus EC2, colocation- -Kubernetes-.
Nachfolgend sind die Metriken aufgeführt, die VictoriaMetrics derzeit verarbeitet (zweiwöchige Gesamtsummen, die Grafiken zeigen eine Lücke von zwei Tagen): Die neue Architektur hat nach der Übertragung in die Produktion eine gute Leistung erbracht. Bei der alten Konfiguration hatten wir alle paar Wochen zwei oder drei "Explosionen" der Kardinalität, bei der neuen fiel ihre Zahl auf Null. Dies ist ein guter Indikator, aber es gibt noch einige weitere Dinge, die wir in den kommenden Monaten verbessern wollen:
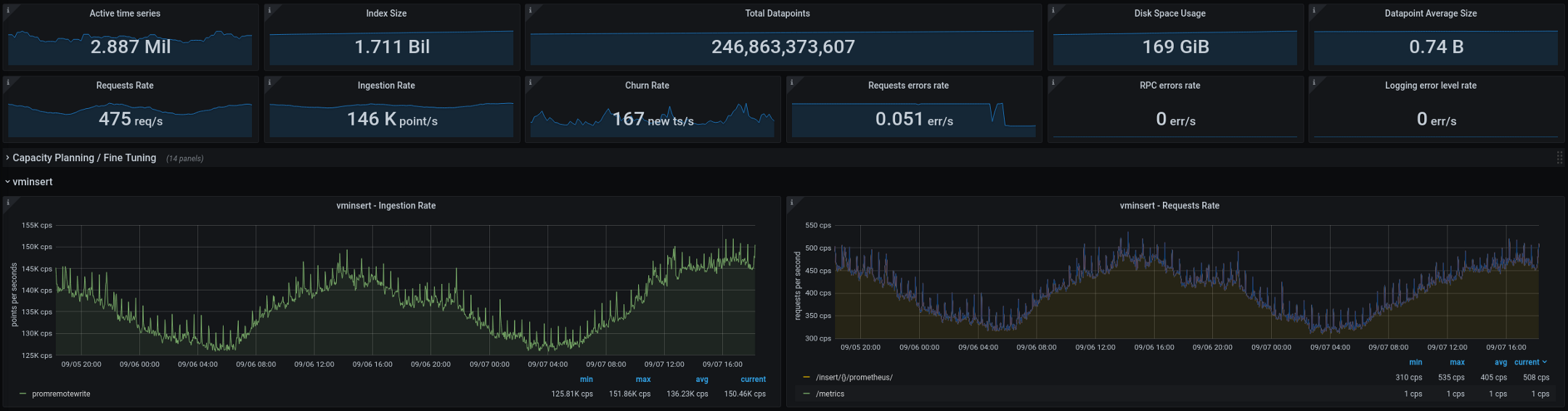
- Reduzieren Sie die Kardinalität von Metriken, indem Sie die Statistik-Integration verbessern.
- Vergleichen Sie das Caching in Trickster und VictoriaMetrics - Sie müssen die Auswirkungen jeder Lösung auf Effizienz und Leistung bewerten. Es besteht der Verdacht, dass Trickster ganz aufgegeben werden kann, ohne etwas zu verlieren.
- Prometheus stateless- — stateful, . , StatefulSet', ( pod disruption budgets).
-
vmagent— VictoriaMetrics Prometheus- exporter'. , Prometheus , .vmagentPrometheus ( !).
Wenn Sie Vorschläge oder Ideen für die oben beschriebenen Verbesserungen haben, kontaktieren Sie uns bitte . Wenn Sie daran arbeiten, die Überwachung von Kubernetes zu verbessern, hoffen wir, dass dieser Artikel, der unsere schwierige Reise beschreibt, hilfreich war.
PS vom Übersetzer
Lesen Sie auch in unserem Blog:
- " Die Zukunft von Prometheus und des Projektökosystems (2020) ";
- " Monitoring and Kubernetes " (Rückblick und Videobericht);
- " Das Gerät und der Mechanismus des Prometheus-Operators in Kubernetes ."