Einer dieser Nebenaspekte der Softwareentwicklung ist die Codelizenzierung. Für einige Entwickler scheint die Lizenzierung ein etwas dunkler Wald zu sein, sie versuchen, sich nicht darauf einzulassen und verstehen entweder die Unterschiede und Lizenzregeln im Allgemeinen nicht oder kennen sie eher oberflächlich, weshalb sie verschiedene Arten von Verstößen begehen können. Die häufigste derartige Verletzung ist das Kopieren (Wiederverwenden) und Ändern des Codes unter Verletzung der Rechte seines Autors.
Jede Hilfe für Menschen beginnt mit der Untersuchung der aktuellen Situation - erstens ist die Datenerfassung für die Möglichkeit einer weiteren Automatisierung erforderlich, und zweitens können wir anhand ihrer Analyse herausfinden, was genau Menschen falsch machen. In diesem Artikel werde ich eine solche Studie beschreiben: Ich werde Ihnen die wichtigsten Arten von Softwarelizenzen vorstellen (sowie einige seltene, aber bemerkenswerte), über die Codeanalyse und die Suche nach Ausleihen in einer großen Datenmenge sprechen und Ratschläge zum richtigen Umgang mit Lizenzen im Code geben. und vermeiden Sie häufige Fehler.
Eine Einführung in die Codelizenzierung
Im Internet und sogar in Habré gibt es bereits detaillierte Beschreibungen der Lizenzen, daher beschränken wir uns nur auf einen kurzen Überblick über das Thema, das zum Verständnis des Wesens der Studie erforderlich ist.
Wir werden nur über die Lizenzierung von Open-Source- Software sprechen . Erstens liegt dies an der Tatsache, dass wir in diesem Paradigma leicht viele verfügbare Daten finden können, und zweitens an dem Begriff "Open-Source-Software".kann irreführend sein. Wenn Sie ein allgemeines proprietäres Programm von der Website des Unternehmens herunterladen und installieren, werden Sie gebeten, den Bedingungen der Lizenz zuzustimmen. Natürlich liest man sie normalerweise nicht, aber im Allgemeinen versteht man, dass dies das geistige Eigentum von jemandem ist. Wenn Entwickler ein Projekt auf GitHub eingeben und alle Quelldateien sehen, ist die Einstellung zu ihnen völlig anders: Ja, es gibt eine Art Lizenz, aber es ist Open Source , und die Software ist Open Source , was bedeutet, dass Sie einfach und nehmen können mach was du willst, richtig? Leider ist nicht alles so einfach.
Wie funktioniert die Lizenzierung? Beginnen wir mit der allgemeinsten Aufteilung der Rechte:
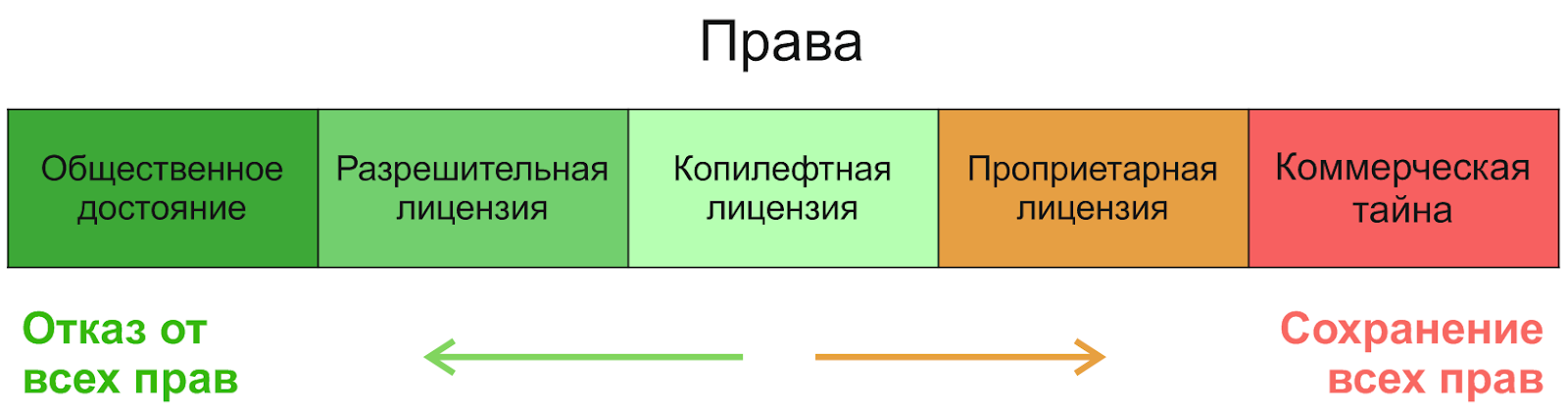
Wenn Sie von rechts nach links gehen, ist das erste ein Geschäftsgeheimnis, gefolgt von proprietären Lizenzen - wir werden sie nicht berücksichtigen. Im Bereich der Open-Source-Software können drei Kategorien unterschieden werden (je nach dem Grad der Erhöhung der Freiheiten): restriktive Lizenzen ( Copyleft ), nicht restriktive Lizenzen ( permissive , permissive) und Public Domain.(Dies ist keine Lizenz, sondern eine Möglichkeit, Rechte zu gewähren). Um den Unterschied zwischen ihnen zu verstehen, ist es nützlich zu wissen, warum sie überhaupt erschienen sind. Das Konzept der Public Domain ist so alt wie die Welt - der Schöpfer lehnt jegliche Rechte vollständig ab und erlaubt ihm, mit seinem Produkt zu tun, was er will. Seltsamerweise entsteht aus dieser Freiheit jedoch Unfreiheit - schließlich kann eine andere Person eine solche Schöpfung nehmen, sie leicht verändern und „alles“ damit machen - einschließlich der Schließung und des Verkaufs. Open-Source-Copyleft-Lizenzen wurden genau zum Schutz der Freiheit erstellt. Aus ihrer Position im Bild geht hervor, dass sie ein Gleichgewicht aufrechterhalten sollen: die Verwendung, Änderung und Verteilung des Produkts zu ermöglichen, es jedoch nicht zu sperren, es frei zu lassen. Auch wenn es dem Autor nichts ausmacht, das Szenario zu schließen und zu verkaufen,Die Konzepte des öffentlichen Raums unterscheiden sich von Land zu Land und können daher zu rechtlichen Komplikationen führen. Um dies zu vermeiden, werden einfache zulässige Lizenzen verwendet.
Was ist also der Unterschied zwischen zulässigen und Copyleft-Lizenzen? Wie alles in unserem Thema ist diese Frage sehr spezifisch, und es gibt Ausnahmen. Wenn Sie jedoch vereinfachen, legen die zulässigen Lizenzen keine Einschränkungen für die Lizenz des geänderten Produkts fest. Das heißt, Sie können ein solches Produkt nehmen, ändern und in ein Projekt unter einer anderen Lizenz einfügen - sogar unter einer proprietären. Der Hauptunterschied zum öffentlichen Bereich besteht hier meist in der Verpflichtung, die Urheberschaft zu wahren und den ursprünglichen Autor zu erwähnen. Die bekanntesten zulässigen Lizenzen sind die MIT-, BSD- und Apache- Lizenzen.... Viele Studien weisen darauf hin, dass MIT die häufigste Open-Source-Lizenz im Allgemeinen ist, und stellen auch fest, dass die Popularität der Apache-2.0-Lizenz seit ihrer Einführung im Jahr 2004 erheblich zugenommen hat (z. B. die Studie für Java ).
Copyleft-Lizenzen beschränken meistens den Vertrieb und die Änderung von Nebenprodukten - Sie erhalten das Produkt mit bestimmten Rechten, und Sie müssen es "weiter ausführen", wodurch alle Benutzer die gleichen Rechte erhalten. Dies bedeutet normalerweise die Verpflichtung, die Software unter derselben Lizenz weiterzugeben und Zugriff auf den Quellcode zu gewähren. Basierend auf dieser Philosophie schuf Richard Stallman die erste und beliebteste Copyleft-Lizenz, die GNU General Public License (GPL)). Sie ist es, die zukünftigen Benutzern und Entwicklern den größtmöglichen Schutz der Freiheit bietet. Ich empfehle, die Geschichte von Richard Stallmans Bewegung für freie Software zu lesen, es ist sehr interessant.
Copyleft-Lizenzen haben eine Schwierigkeit: Sie werden traditionell in starke und schwache Copyleft- Lizenzen unterteilt . Ein starkes Copyleft ist genau das, was oben beschrieben wurde, während ein schwaches Copyleft Entwicklern verschiedene Zugeständnisse und Ausnahmen bietet. Das bekannteste Beispiel für eine solche Lizenz ist die GNU Lesser General Public License (LGPL).: Wie bei seiner älteren Version können Sie den Code nur ändern und weitergeben, wenn Sie diese Lizenz behalten. Wenn Sie diese Lizenz jedoch dynamisch verknüpfen (als Bibliothek in einer Anwendung verwenden), kann diese Anforderung weggelassen werden. Mit anderen Worten, wenn Sie den Quellcode von hier ausleihen oder etwas ändern möchten, beobachten Sie Copyleft. Wenn Sie ihn jedoch nur als dynamische Linkbibliothek verwenden möchten, können Sie dies überall tun.
Nachdem wir die Lizenzen selbst herausgefunden haben, sollten wir über ihre Kompatibilität sprechen , da darin (oder besser gesagt in ihrer Abwesenheit) die Verstöße liegen, die wir verhindern wollen. Jeder, der sich jemals für dieses Thema interessiert hat, sollte auf ähnliche Lizenzkompatibilitätsschemata gestoßen sein:

Bei einem Blick auf ein solches Schema kann jeder Wunsch, Lizenzen zu verstehen, verschwinden. In der Tat gibt es viele Open-Source-Lizenzen , eine ziemlich vollständige Liste finden Sie beispielsweise hier . Gleichzeitig müssen Sie, wie Sie weiter unten in den Ergebnissen unserer Studie sehen werden, eine sehr begrenzte Menge (aufgrund ihrer extrem ungleichmäßigen Verteilung) und noch weniger Regeln kennen, die beachtet werden müssen, um alle ihre Bedingungen zu erfüllen. Der allgemeine Vektor dieses Schemas ist recht einfach: An der Quelle von allem steht die Public Domain, dahinter stehen zulässige Lizenzen, dann ein schwacher Copyleft und schließlich ein starker Copyleft, und Lizenzen sind "richtig" kompatibel: In einem Copyleft-Projekt können Sie den Code unter einer zulässigen Lizenz wiederverwenden, aber nicht umgekehrt - Alles ist logisch.
Hier kann sich die Frage stellen: Was ist, wenn der Code keine Lizenz hat? Welche Regeln sind dann zu beachten? Kann dieser Code kopiert werden? Dies ist eigentlich eine sehr wichtige Frage. Wenn der Code auf einen Zaun geschrieben ist, kann er wahrscheinlich als gemeinfrei angesehen werden, und wenn er in einer Flasche auf Papier geschrieben ist, die auf eine einsame Insel genagelt wurde (ohne Urheberrecht), kann er einfach genommen und verwendet werden. Wenn es um große und etablierte Plattformen wie GitHub oder StackOverflow geht, sind die Dinge nicht so einfach, denn wenn Sie sie einfach verwenden, stimmen Sie automatisch ihren Nutzungsbedingungen zu. Lassen Sie uns vorerst einfach eine Notiz darüber in unserem Kopf hinterlassen und später darauf zurückkommen - am Ende ist dies vielleicht eine Seltenheit und es gibt praktisch keinen Code ohne Lizenz?
Problemstellung und Methodik
Nachdem wir nun die Bedeutung aller Begriffe kennen, wollen wir klarstellen, was wir wissen wollen.
- Wie häufig wird Code in Open Source-Software kopiert? Gibt es viele Klone im Code unter Open Source-Projekten ?
- Unter welchen Lizenzen gibt es? Was sind die häufigsten Lizenzen? Enthält die Datei mehrere Lizenzen gleichzeitig?
- Was sind die häufigsten möglichen Ausleihen , dh Codeübertragungen von einer Lizenz zur anderen?
- Was sind die häufigsten möglichen Verstöße , dh Codeübergänge, die durch die Bestimmungen des Originals oder der empfangenden Lizenz verboten sind?
- Was ist der mögliche Ursprung einzelner Codefragmente? Wie hoch ist die Wahrscheinlichkeit, dass dieser Code unter Verstoß kopiert wurde?
Um eine solche Analyse durchzuführen, benötigen wir:
- Sammeln Sie einen Datensatz aus einer Vielzahl von Open Source-Projekten.
- Finden Sie Klone von Codefragmenten unter ihnen.
- Identifizieren Sie die Klone, die wirklich ausgeliehen werden können.
- Bestimmen Sie für jeden Code zwei Parameter - seine Lizenz und den Zeitpunkt seiner letzten Änderung, die erforderlich sind, um herauszufinden, welches Fragment in einem Klonpaar älter und welches jünger ist, und daher - wer möglicherweise von wem kopieren könnte.
- Bestimmen Sie, welche möglichen Übergänge zwischen Lizenzen zulässig sind und welche nicht.
- Analysieren Sie alle erhaltenen Daten, um die obigen Fragen zu beantworten.
Schauen wir uns nun jeden Schritt genauer an.
Datensammlung
Es ist sehr praktisch für uns, dass es heutzutage einfach ist, mit GitHub auf viele Open Source-Dateien zuzugreifen. Es enthält nicht nur den Code selbst, sondern auch den Verlauf seiner Änderungen, was für diese Studie sehr wichtig ist: Um herauszufinden, wer den Code von wem kopieren kann, müssen Sie wissen, wann jedes Fragment zum Projekt hinzugefügt wurde.
Um Daten zu sammeln, müssen Sie sich für die studierte Programmiersprache entscheiden. Tatsache ist, dass Klone im Rahmen einer Programmiersprache durchsucht werden: Wenn von einer Lizenzverletzung gesprochen wird, ist es schwieriger, das Umschreiben eines vorhandenen Algorithmus in eine andere Sprache zu bewerten. Solche komplexen Konzepte sind durch Patente geschützt, während wir in unserer Forschung von typischerem Kopieren und Ändern sprechen. Wir haben uns für Java entschieden, weil es eine der am häufigsten verwendeten Sprachen ist und besonders in der kommerziellen Softwareentwicklung beliebt ist. In diesem Fall sind potenzielle Lizenzverletzungen besonders wichtig.
Wir haben das bestehende öffentliche Git-Archiv als Grundlage genommen, das Anfang 2018 alle Projekte auf GitHub mit mehr als 50 Sternen zusammenführte. Wir haben alle Projekte mit mindestens einer Zeile in Java ausgewählt und mit einer vollständigen Änderungshistorie heruntergeladen. Nach dem Filtern von Projekten, die verschoben wurden oder nicht mehr verfügbar sind, belegen 23.378 Projekte ca. 1,25 TB Festplattenspeicher.
Zusätzlich haben wir für jedes Projekt die Liste der Gabeln ausgegeben und Paar von Gabeln in unserem Datensatz gefunden - dies ist für die weitere Filterung erforderlich, da wir nicht an Klonen zwischen Gabeln interessiert sind. Insgesamt gab es 324 Projekte mit Gabeln im Datensatz.
Klone finden
Um Klone zu finden, dh ähnliche Codeteile, müssen Sie auch einige Entscheidungen treffen. Zunächst müssen wir entscheiden, wie viel und in welcher Eigenschaft wir an ähnlichem Code interessiert sind. Traditionell gibt es 4 Arten von Klonen (von den genauesten bis zu den ungenauesten):
- Identische Klone sind genau dieselben Codeteile, die sich nur in stilistischen Entscheidungen wie Einrückungen, Leerzeilen und Kommentaren unterscheiden können.
- Umbenannte Klone enthalten den ersten Typ, können sich jedoch zusätzlich in Variablen- und Objektnamen unterscheiden.
- Nahe Klone umfassen alle oben genannten Elemente, können jedoch bedeutendere Änderungen enthalten, z. B. das Hinzufügen, Entfernen oder Verschieben von Ausdrücken, bei denen die Fragmente noch ähnlich sind.
- , — , ( ), ().
Wir sind am Kopieren und Ändern interessiert, daher betrachten wir nur Klone der ersten drei Typen.
Die zweite wichtige Entscheidung ist, nach welcher Größe Klone zu suchen sind. Identische Codefragmente können zwischen Dateien, Klassen, Methoden, einzelnen Ausdrücken durchsucht werden ... In unserer Arbeit haben wir die Methode als Grundlage genommen , da dies die ausgewogenste Suchgranularität ist: Oft kopieren Benutzer den Code nicht in ganzen Dateien, sondern in kleinen Fragmenten, aber gleichzeitig in der Methode - es ist immer noch eine vollständige logische Einheit.
Basierend auf den ausgewählten Lösungen haben wir SourcererCC verwendet, um Klone zu finden - ein Tool, das mithilfe der Bag-of- Word- Methode nach Klonen sucht: Jede Methode wird als Häufigkeitsliste von Token (Schlüsselwörter, Namen und Literale) dargestellt, nach der solche Sätze verglichen werden. Wenn mehr als ein bestimmter Anteil von Token in zwei Methoden zusammenfällt (dieser Anteil wird als Ähnlichkeitsschwelle bezeichnet), wird ein solches Paar als Klon betrachtet. Trotz der Einfachheit dieser Methode (es gibt viel komplexere Methoden, die auf der Analyse von Syntaxbäumen von Methoden und sogar deren Programmabhängigkeitsgraphen basieren) besteht ihr Hauptvorteil in der Skalierbarkeit : Bei einer so großen Menge an Code wie unserer ist es wichtig, dass die Suche nach Klonen sehr schnell durchgeführt wird ...
Wir haben verschiedene Ähnlichkeitsschwellen verwendet, um verschiedene Klone zu finden, und haben auch separat eine Suche mit einer 100% igen Ähnlichkeitsschwelle durchgeführt, bei der nur identische Klone identifiziert wurden. Darüber hinaus wurde eine minimale untersuchte Methodengröße festgelegt, um triviale und generische Codeteile zu verwerfen, die möglicherweise nicht ausgeliehen wurden.
Diese Suche dauerte bis zu 66 Tage kontinuierlicher Berechnungen. Es wurden 38,6 Millionen Methoden identifiziert, von denen nur 11,7 Millionen die Mindestgröße überschritten und 7,6 Millionen am Klonen teilnahmen. Insgesamt wurden 1,2 Milliarden Klonpaare gefunden.
Zeitpunkt der letzten Änderung
Zur weiteren Analyse haben wir nur projektübergreifende Klonpaare ausgewählt, dh Paare ähnlicher Codefragmente, die in verschiedenen Projekten gefunden werden. Aus lizenzrechtlicher Sicht sind wir nicht sehr an Codefragmenten innerhalb desselben Projekts interessiert: Es wird als schlechte Praxis angesehen, Ihren eigenen Code zu wiederholen, aber es ist nicht verboten. Insgesamt gab es ungefähr 561 Millionen Paare zwischen Projekten, dh ungefähr die Hälfte aller Paare. Diese Paare umfassten 3,8 Millionen Methoden, für die der Zeitpunkt der letzten Änderung bestimmt werden musste. Zu diesem Zweck wurde auf jede Datei der Befehl git tad angewendet (der sich als 898.000 herausstellte, da es in Dateien mehr als eine Methode geben kann) , der den Zeitpunkt der letzten Änderung für jede Zeile in der Datei anzeigt.
Wir haben also die letzte Änderungszeit für jede Zeile in der Methode, aber wie bestimmen wir die letzte Änderungszeit der gesamten Methode? Es scheint offensichtlich - Sie nehmen sich die letzte Zeit und verwenden sie: Schließlich zeigt sie wirklich, wann die Methode zuletzt geändert wurde. Für unsere Aufgabe ist eine solche Definition jedoch nicht ideal. Betrachten wir ein Beispiel:
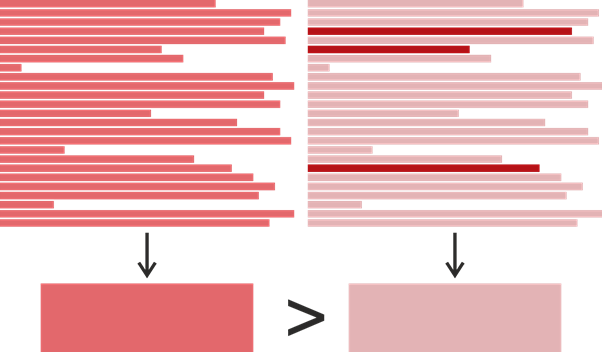
Angenommen, wir haben einen Klon in Form einiger Fragmente mit jeweils 25 Zeilen gefunden. Eine gesättigte Farbe bedeutet hier eine spätere Änderungszeit. Nehmen wir an, das Fragment auf der linken Seite wurde 2017 zu einem Zeitpunkt geschrieben, und in dem Fragment auf der rechten Seite wurden 2015 22 Zeilen geschrieben, und drei wurden 2019 geändert. Es stellt sich heraus, dass das Fragment auf der rechten Seite später geändert wurde, aber wenn wir bestimmen wollten, wer von wem kopieren kann, Es wäre logischer, das Gegenteil anzunehmen: Das linke Fragment hat das rechte entlehnt, und das rechte hat sich später leicht verändert. Auf dieser Grundlage haben wir den Zeitpunkt der letzten Änderung eines Codeteils als den häufigsten Zeitpunkt der letzten Änderung seiner einzelnen Zeilen definiert. Wenn es plötzlich mehrere solcher Zeiten gab, wurde eine spätere gewählt.
Interessanterweise wurde der älteste Code in unserem Datensatz im April 1997, zu Beginn von Java, geschrieben und er fand einen Klon, der 2019 erstellt wurde!
Lizenzen definieren
Der zweite und wichtigste Schritt ist die Bestimmung der Lizenz für jeden Block. Dafür haben wir das folgende Schema verwendet. Zunächst wurde mit dem Ninka- Tool die direkt im Dateikopf angegebene Lizenz ermittelt. Wenn es eine gibt, wird sie als Lizenz für jede darin enthaltene Methode betrachtet (Ninka kann mehrere Lizenzen gleichzeitig erkennen). Wenn in der Datei nichts angegeben ist oder nicht genügend Informationen vorhanden sind (z. B. nur das Urheberrecht), wurde die Lizenz des gesamten Projekts verwendet, zu dem die Datei gehört. Daten darüber waren im ursprünglichen öffentlichen Git-Archiv enthalten, auf dessen Grundlage wir den Datensatz gesammelt haben, und wurden mit einem anderen Tool ermittelt - Go License Detector . Befindet sich die Lizenz nicht in der Datei oder im Projekt, wurden solche Methoden als markiertGitHub , da diese dann den GitHub-Nutzungsbedingungen unterliegen (hier wurden alle unsere Daten heruntergeladen).
Nachdem wir alle Lizenzen auf diese Weise definiert haben, können wir endlich die Frage beantworten, welche Lizenzen am beliebtesten sind. Insgesamt haben wir 94 verschiedene Lizenzen gefunden . Wir werden hier Statistiken für Dateien bereitstellen, um mögliche Knicke aufgrund sehr großer Dateien mit vielen Methoden auszugleichen.
Das Hauptmerkmal dieses Zeitplans ist die stärkste ungleichmäßige Verteilung der Lizenzen. In der Grafik sind drei Bereiche zu sehen: zwei „Lizenzen“ mit mehr als 100.000 Dateien, weitere zehn mit 10 bis 100.000 Dateien und eine lange Anzahl von Lizenzen mit weniger als 10.000 Dateien.
Betrachten wir zunächst die beliebtesten, für die wir die ersten beiden Bereiche linear darstellen:
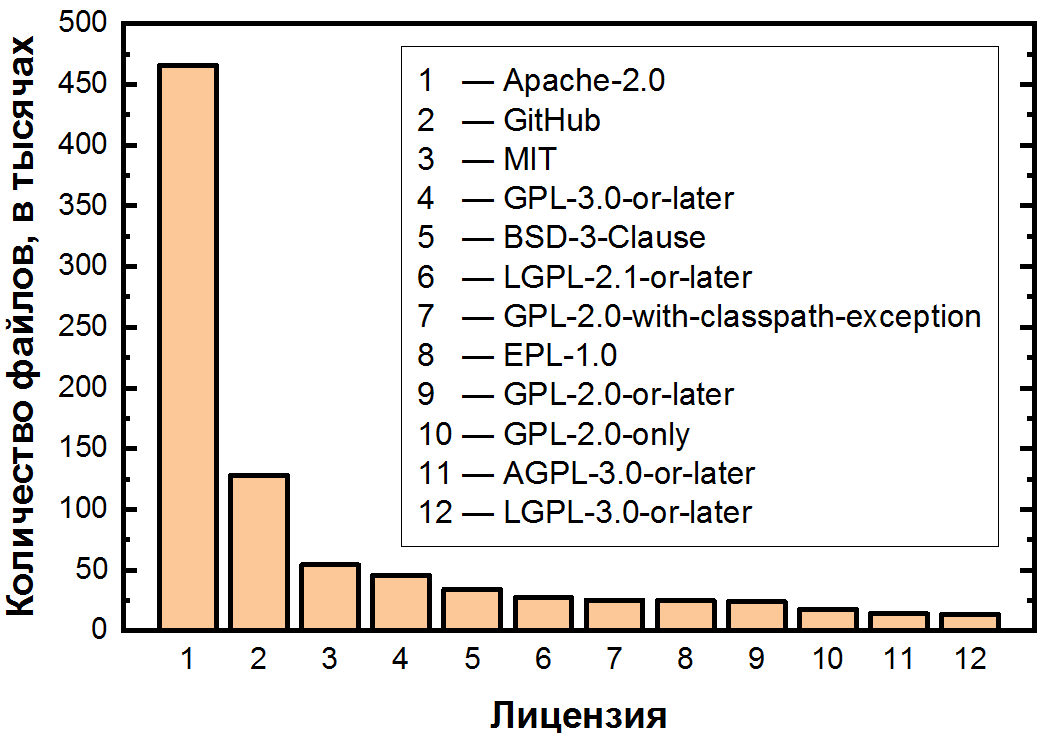
Man kann sogar bei den beliebtesten Lizenzen Ungleichmäßigkeiten feststellen. Apache-2.0, die ausgewogenste aller zulässigen Lizenzen, belegt mit großem Abstand den ersten Platz und deckt etwas mehr als die Hälfte aller Dateien ab.
Es folgt das berüchtigte Fehlen einer Lizenz, und wir müssen sie noch genauer analysieren, da diese Situation selbst bei mittleren und großen Repositories (mehr als 50 Sterne) so häufig ist. Dieser Umstand ist sehr wichtig, da das Hochladen des Codes auf GitHub ihn nicht öffnet.- und wenn etwas Praktisches und Sie sich an diesen Artikel erinnern müssen, dann ist es das. Durch das Hochladen Ihres Codes auf GitHub stimmen Sie den Nutzungsbedingungen zu, die besagen, dass Ihr Code angezeigt und gegabelt werden kann. Mit Ausnahme davon verbleiben jedoch alle Rechte an dem Code beim Autor, sodass für die Verbreitung, Änderung und sogar Verwendung eine ausdrückliche Genehmigung erforderlich ist. Es stellt sich heraus, dass nicht nur nicht alle Open Source vollständig kostenlos sind, auch nicht der gesamte Code auf GitHub ist vollständig Open Source! Und da es viele solcher Codes gibt (14% der Dateien und unter den weniger beliebten Projekten, die nicht im Datensatz enthalten sind, höchstwahrscheinlich sogar mehr), kann dies die Ursache für eine erhebliche Anzahl von Verstößen sein.
In den Top 5 sehen wir auch die bereits erwähnten zulässigen MIT- und BSD-Lizenzen sowie die Copyleft-GPL-3.0-Version oder höher. Lizenzen aus der GPL-Familie unterscheiden sich nicht nur in einer signifikanten Anzahl von Versionen (nicht so schlecht), sondern auch im Nachskript "oder später", mit dem der Benutzer die Bedingungen dieser Lizenz oder ihrer späteren Versionen verwenden kann. Dies führt zu einer anderen Frage: Unter diesen 94 Lizenzen gibt es eindeutig ähnliche "Familien" - welche von ihnen sind die größten?
An dritter Stelle stehen die GPL-Lizenzen - es gibt 8 Arten von Lizenzen in der Liste. Diese Familie ist die bedeutendste, da sie zusammen 12,6% der Dateien abdeckt, nach Apache-2.0 und dem Fehlen einer Lizenz an zweiter Stelle. Auf dem zweiten Platz unerwartet BSD. Neben der traditionellen 3-Absatz-Version und sogar der 2- und 4-Absatz-Version gibt es sehrspezifische Lizenzen - nur 11 Stück. Dazu gehört beispielsweise die BSD 3-Klausel No Nuclear License , eine reguläre BSD mit 3 Klauseln, nach der im Folgenden angegeben wird, dass diese Software nicht zum Erstellen oder Betreiben von Nuklearwaffen verwendet werden darf:
Sie erkennen an, dass diese Software nicht entwickelt wurde. lizenziert oder zur Verwendung bei der Planung, dem Bau, dem Betrieb oder der Wartung von Kernkraftwerken bestimmt.
Am vielfältigsten ist die Creative Commons-Lizenzfamilie, über die Sie hier lesen können . Es gab bis zu 13 von ihnen, und sie sind es auch wert, zumindest aus einem wichtigen Grund durchgesehen zu werden: Der gesamte Code in StackOverflow ist unter CC-BY-SA lizenziert.
Unter den selteneren Lizenzen gibt es einige bemerkenswerte, zum BeispielTun Sie, was Sie wollen, um eine öffentliche Lizenz (WTFPL) zu erhalten , die 529 Dateien abdeckt und es Ihnen ermöglicht, genau das zu tun, was der Name mit dem Code sagt. Es gibt zum Beispiel auch die Beerware-Lizenz , mit der Sie alles tun können und die den Autor ermutigt, bei einem Meeting ein Bier zu kaufen. In unserem Datensatz sind wir auch auf eine Variation dieser Lizenz gestoßen , die wir nirgendwo anders gefunden haben - die Sushiware-Lizenz . Sie ermutigt den Autor dementsprechend, Sushi zu kaufen.
Eine andere merkwürdige Situation ist, wenn mehrere Lizenzen in einer Datei (nämlich in der Datei) gefunden werden. In unserem Datensatz gibt es nur 0,9% solcher Dateien. 7,4 Tausend Dateien werden von zwei Lizenzen gleichzeitig abgedeckt, und es wurden insgesamt 74 verschiedene Paare solcher Lizenzen gefunden. 419 Dateien werden von bis zu drei Lizenzen abgedeckt, und es gibt 8 solcher Drillinge. Und schließlich:In einer Datei in unserem Datensatz werden vier verschiedene Lizenzen im Header erwähnt.
Mögliche Ausleihen
Nachdem wir über Lizenzen gesprochen haben, können wir die Beziehung zwischen ihnen diskutieren. Das erste, was Sie tun müssen, ist, Klone zu entfernen, bei denen es sich nicht um mögliche Ausleihen handelt . Ich möchte Sie daran erinnern, dass wir im Moment versucht haben, dies auf zwei Arten zu berücksichtigen - durch die Mindestgröße von Codefragmenten und den Ausschluss von Klonen innerhalb eines Projekts. Wir werden nun drei weitere Arten von Paaren herausfiltern:
- Wir sind nicht an Paaren zwischen der Gabel und dem Original interessiert (sowie zum Beispiel zwischen zwei Gabeln desselben Projekts) - dafür haben wir sie gesammelt.
- Wir sind auch nicht an Klonen zwischen verschiedenen Projekten interessiert, die derselben Organisation oder demselben Benutzer gehören (da wir davon ausgehen, dass die Urheberrechte innerhalb derselben Organisation geteilt werden).
- Schließlich haben wir durch manuelles Überprüfen einer ungewöhnlich großen Anzahl von Klonen zwischen zwei Projekten signifikante Spiegel gefunden (sie sind auch indirekte Gabeln), dh identische Projekte, die in nicht verwandte Repositorys hochgeladen wurden.
Seltsamerweise sind bis zu 11,7% der verbleibenden Paare identische Klone mit einer Ähnlichkeitsschwelle von 100% - vielleicht scheint es intuitiv, dass es auf GitHub weniger absolut identischen Code geben sollte.
Wir verarbeiten alle nach dieser Filterung verbleibenden Paare wie folgt:
- Wir vergleichen den Zeitpunkt der letzten Änderung zweier Methoden in einem Paar.
- , : .
- , «» «» . , 2015 MIT, 2018 — Apache-2.0, MIT → Apache-2.0.
Am Ende haben wir die Anzahl der Paare für jede mögliche Ausleihe zusammengefasst und in absteigender Reihenfolge sortiert:
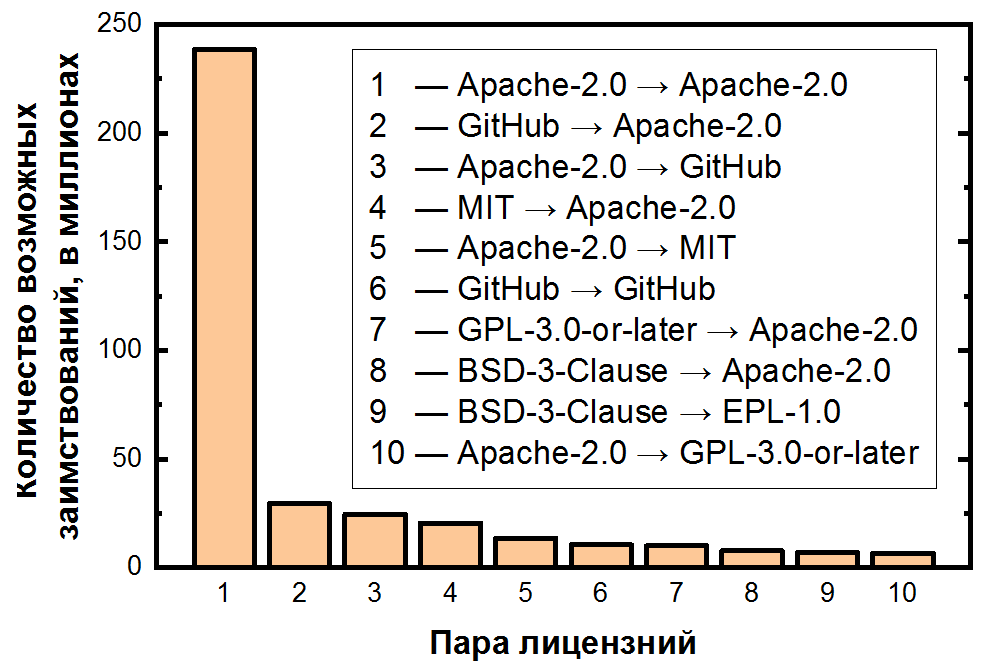
Hier ist die Abhängigkeit noch extremer: Die mögliche Ausleihe von Code in Apache-2.0 macht mehr als die Hälfte aller Klonpaare aus, und die ersten 10 Lizenzpaare decken bereits mehr als 80% der Klone ab. Es ist auch wichtig zu beachten, dass sich das zweit- und dritthäufigste Paar mit nicht lizenzierten Dateien befasst - auch eine klare Folge ihrer Häufigkeit. Für die fünf beliebtesten Lizenzen können Sie Übergänge als Heatmap anzeigen:
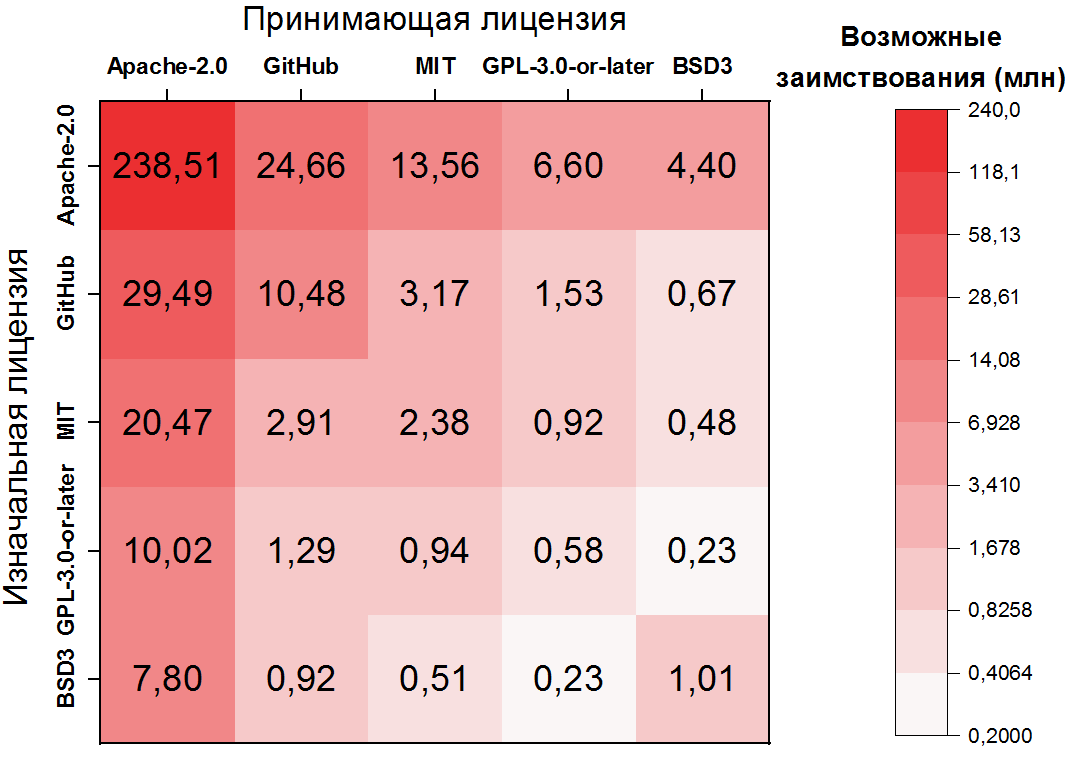
Mögliche Lizenzverletzungen
Der nächste Schritt in unserer Forschung besteht darin, Klonpaare zu identifizieren, die potenzielle Verstöße darstellen , dh Ausleihen, die gegen die Bestimmungen der Original- und Host-Lizenz verstoßen. Dazu müssen Sie die oben genannten Lizenzpaare als zulässige oder verbotene Übergänge markieren . So ist beispielsweise der beliebteste Übergang ( Apache-2.0 → Apache-2.0 ) natürlich zulässig, der zweite ( GitHub → Apache-2.0 ) ist jedoch verboten. Aber es gibt sehr, sehr viele, es gibt Tausende solcher Paare.
Denken Sie daran, dass die gerenderten ersten 10 Lizenzpaare 80% aller Klonpaare abdecken. Aufgrund dieser Ungleichmäßigkeit erwies es sich als ausreichend, nur 176 Lizenzpaare manuell zu markieren, um 99% der Klonpaare abzudecken, was uns als akzeptable Genauigkeit erschien. Unter diesen Paaren betrachteten wir vier Arten von Paaren als verboten:
- Kopieren aus Dateien ohne Lizenz (GitHub). Wie bereits erwähnt, erfordert ein solches Kopieren eine direkte Genehmigung des Autors des Codes, und wir gehen davon aus, dass dies in den allermeisten Fällen nicht der Fall ist.
- Das Kopieren in Dateien ohne Lizenz ist ebenfalls verboten, da dies im Wesentlichen das Löschen und Entfernen von Lizenzen bedeutet. Zulässige Lizenzen wie Apache-2.0 oder BSD ermöglichen die Wiederverwendung von Code in anderen Lizenzen (einschließlich proprietärer Lizenzen), aber selbst für diese muss die ursprüngliche Lizenz in der Datei aufbewahrt werden.
- .
- (, Apache-2.0 → GPL-2.0).
Alle anderen seltenen Lizenzpaare, die 1% der Klone abdecken, wurden als zulässig markiert (um niemanden unnötig zu beschuldigen), mit Ausnahme derjenigen, bei denen Code ohne Lizenzen angezeigt wird (der niemals kopiert werden kann).
Infolgedessen stellte sich nach dem Aufschlag heraus, dass 72,8% der Kredite Kredite zulassen und 27,2% verboten sind. Die folgenden Diagramme zeigen die am meisten verletzten und am meisten verletzenden Lizenzen.

Auf der linken Seite befinden sich die am häufigsten verletzten Lizenzen, dh die Ursachen für die meisten möglichen Verstöße. Unter diesen nehmen Dateien ohne Lizenzen den ersten Platz ein, was ein wichtiger praktischer Hinweis ist - Sie müssen Dateien ohne Lizenzen besonders genau überwachen.... Man könnte sich fragen, was die zulässige Apache-2.0-Lizenz in dieser Liste bewirkt. Wie aus der obigen Heatmap hervorgeht, handelt es sich bei ~ 25 Millionen verbotenen Ausleihen um Ausleihen in eine Datei ohne Lizenz. Dies ist eine Folge ihrer Beliebtheit.
Auf der rechten Seite befinden sich Lizenzen, die mit Verstößen kopiert werden, und hier werden vor allem Apache-2.0 und GitHub vorgestellt.
Herkunft der einzelnen Methoden
Schließlich kommen wir zum letzten Punkt unserer Forschung. Die ganze Zeit haben wir über Paare von Klonen, wie in solchen Studien üblich ist. Sie müssen jedoch eine gewisse Einseitigkeit und Unvollständigkeit solcher Urteile verstehen. Tatsache ist, dass wenn beispielsweise ein Code 20 "ältere" Brüder (oder "Eltern", wer weiß) hat, alle 20 Paare als potenzielle Anleihen betrachtet werden. Deshalb sprechen wir von "potenziellen" und "möglichen" Anleihen - es ist unwahrscheinlich, dass der Autor einer bestimmten Methode sie an 20 verschiedenen Orten ausgeliehen hat. Trotzdem kann diese Argumentation als Argumentation für Klone zwischen verschiedenen Lizenzen angesehen werden.
Um solche unvollständigen Urteile zu vermeiden, können Sie dasselbe Bild aus einem anderen Blickwinkel betrachten. Das Klonbild ist eigentlich ein gerichteter Graph: Alle Methoden sind Eckpunkte darauf, die durch gerichtete Kanten vom ältesten zum jüngsten verbunden sind (wenn Sie die am selben Tag datierten Methoden nicht berücksichtigen). In den beiden vorhergehenden Abschnitten haben wir dieses Diagramm unter dem Gesichtspunkt der Kanten betrachtet: Wir haben jede Kante genommen und ihre Eckpunkte untersucht (um genau diese Lizenzpaare zu erhalten). Betrachten wir es nun aus der Sicht der Eckpunkte. Jeder Scheitelpunkt (Methode) in der Grafik hat Vorfahren ("ältere" Klone) und Nachkommen ("jüngere" Klone). Die Verknüpfungen zwischen ihnen können auch in "erlaubt" und "verboten" unterteilt werden.
Auf dieser Grundlage kann jede Methode einer der folgenden Kategorien zugeordnet werden, deren Grafiken im Bild dargestellt sind (hier zeigen die durchgezogenen Linien das verbotene Ausleihen und die gepunkteten Linien - zulässig):

Zwei der dargestellten Konfigurationen können einen Verstoß gegen die Lizenzbedingungen darstellen:
- Ein schwerer Verstoß bedeutet, dass die Methode Vorfahren hat und alle Übergänge von ihnen verboten sind. Dies bedeutet, dass der Entwickler, wenn er den Code tatsächlich kopiert hat, dies unter Verstoß gegen die Lizenzen getan hat.
- Eine schwache Verletzung bedeutet, dass die Methode Vorfahren hat und nur einige von ihnen hinter verbotenen Übergängen stehen. Dies bedeutet, dass der Entwickler den Code möglicherweise unter Verstoß gegen die Lizenz kopiert hat.
Die restlichen Konfigurationen sind keine Verstöße:
- , , .
- — , — , .
- , , — , . , , — , . : , , , , ( , , ).
Wie sind die Methoden in unserem Datensatz verteilt?

Sie können sehen, dass etwa ein Drittel der Methoden überhaupt keine Klone hat und ein weiteres Drittel Klone nur in verknüpften Projekten. Andererseits stellen 5,4% der Methoden eine "leichte Verletzung" und 4% eine "schwere Verletzung" dar. Obwohl diese Zahlen nicht sehr groß erscheinen mögen, gibt es in mehr oder weniger großen Projekten immer noch Hunderttausende von Methoden.
TL; DR
In Anbetracht der Tatsache, dass dieser Artikel viele empirische Zahlen und Grafiken enthält, wiederholen wir unsere wichtigsten Ergebnisse:
- Es gibt Millionen von Methoden, die Klone haben, und es gibt mehr als eine Milliarde Paare zwischen ihnen.
- , Java- 50 , 94 , : Apache-2.0 . Apache-2.0 .
- , 27,2%, .
- 35,4% , 5,4% «» , 4% «» .
?
Abschließend möchte ich darüber sprechen, warum all das überhaupt benötigt wird. Ich habe mindestens drei Antworten.
Erstens ist es interessant . Die Lizenzierung ist so vielfältig wie alle anderen Aspekte der Programmierung. Die Liste der Lizenzen selbst ist aufgrund der Spezifität und Seltenheit einiger Lizenzen ziemlich merkwürdig. Die Leute schreiben und arbeiten auf unterschiedliche Weise mit ihnen. Dies gilt zweifellos auch für Klone im Code und die Ähnlichkeit des Codes im Allgemeinen. Es gibt Methoden mit Tausenden von Klonen, und es gibt Methoden ohne einen einzigen, während es auf einen Blick nicht immer leicht ist, den grundlegenden Unterschied zwischen ihnen zu bemerken.
Zweitens können wir anhand einer detaillierten Analyse unserer Ergebnisse mehrere praktische Tipps formulieren :
- - . Apache-2.0, MIT, BSD-3-Clause, GPL LGPL.
- : . - , , .
- GitHub, . . — , . : - , , , , . , .
Für klare Beschreibungen der Lizenzen sowie Ratschläge zur Auswahl einer Lizenz für Ihr neues Projekt können Sie sich an Dienste wie tldrlegal oder choosealicense wenden .
Schließlich können die erhaltenen Daten zum Erstellen von Werkzeugen verwendet werden . Derzeit entwickeln unsere Kollegen eine Möglichkeit, Lizenzen mithilfe von Methoden des maschinellen Lernens (für die Sie nur viele spezifische Lizenzen benötigen) und eines IDE-Plugins, mit dem Entwickler Abhängigkeiten in ihren Projekten verfolgen und mögliche Inkompatibilitäten im Voraus erkennen können, schnell zu ermitteln.
Hoffentlich haben Sie aus diesem Artikel etwas Neues gelernt. Die Einhaltung der grundlegenden Lizenzbestimmungen ist nicht so umständlich, und Sie können alles mit minimalem Aufwand gemäß den Regeln ausführen. Lassen Sie uns gemeinsam aufklären, andere aufklären und dem Traum von der "richtigen" Open-Source-Software näher kommen!