Epigraph, Google / Yandex, hat den Autor nicht gefunden.
Dies ist der zweite Teil des Artikels "Was jedem klar ist".
Zum besseren Verständnis des darin beschriebenen Z-Algorithmus werde ich hier ein gutes Beispiel hinzufügen, das weiter oben in der Diskussion / in den Kommentaren angegeben wurde.
Stellen Sie sich vor, die Aufgabe besteht darin, eine Kurve einer Funktion T (X) in einem bestimmten Intervall von (zulässigen) Werten zu erstellen. Es ist wünschenswert, dies so detailliert wie möglich zu tun, aber Sie wissen nicht im Voraus, wann Sie "an der Hand gepackt" werden. Sie möchten X-Werte generieren, damit das resultierende Diagramm diese Funktion zu jedem Zeitpunkt, zu dem das Zeichnen der Kurve unterbrochen wird (Generieren von X-Parametern in einem Intervall und Berechnen von T (X)), so genau wie möglich wiedergibt. Es wird mehr Zeit geben - der Graph wird genauer sein, aber - immer das Maximum dessen, was momentan für eine beliebige Funktion möglich ist.
Natürlich kann der Intervallpartitionierungsalgorithmus für eine bekannte Funktion sein Verhalten berücksichtigen, aber hier sprechen wir über einen allgemeinen Ansatz, der das gewünschte Ergebnis mit minimalen "Verlusten" liefert. Für einen zweidimensionalen Fall können Sie ein Beispiel für die Anzeige eines bestimmten Reliefs / einer bestimmten Oberfläche geben und möchten sicherstellen, dass Sie so viel wie möglich das Maximum seiner Merkmale angezeigt haben.
Die Aufgabe und die Objekte der Modellierung (ab dem ersten Teil) im allgemeinen Fall können sehr unterschiedlich sein: Es gibt ein theoretisches / physikalisches Modell oder eine Annäherung oder nicht (Black Box) - es wird überall Nuancen beim Erstellen von Modellen geben. Die Notwendigkeit, Parameter (einschließlich des Z-Algorithmus) zu generieren, ist jedoch ein gemeinsamer und integraler Bestandteil für alle. Es gibt Objekte (zum Beispiel solche ), bei denen die Zeit zum Erhalten von T zu lang ist (Tage und Wochen), dann stoppt der Algorithmus zum Auswählen eines neuen Schritts nach anderen Kriterien, nicht aufgrund des Abschlusses des Hauptberechnungszyklus in einem parallelen Prozess. Es ist nicht sinnvoll, den Schritt zur Verbesserung der Suche nach der nächsten Vorhersage T weiter zu reduzieren, wenn die erwartete Verbesserung offensichtlich schlechter ist als der Modellfehler und / oder die Messfehler T.
Ich werde noch einmal die Aufteilung des zulässigen Intervalls für den zweidimensionalen Fall des Z-Algorithmus veranschaulichen (K = 3 im Feld 64 * 64):

Die in der Abbildung hervorgehobenen Punkte (9 Stk.) Sind die Startpunkte der Kanten und die Mitte des Intervalls. Falls erforderlich, werden sie außerhalb des Z-Algorithmus berücksichtigt. Sie können sehen, dass die horizontale und vertikale Richtung / "Pfade" Z-Werte fehlen. Zusätzliche Punkte können hier leicht separat berechnet werden, aber mit einer Erhöhung der Anzahl von Punkten entlang dieser Richtungen / "Spuren" verbessert sich die Darstellung der Funktion (die "Spuren" werden enger) und die Notwendigkeit, den Algorithmus selbst zu ergänzen (7 Zeilen werden benötigt, von denen 4 Operatoren in der Hauptschleife in n, siehe unten) oder ich sehe keine separate Berechnung. Darüber hinaus verschlechtert sich in diesem Fall die durchschnittliche Effizienz des Algorithmus, und die Darstellung des Modells wird nicht besonders verbessert (selbst für n> 8 beträgt der Schritt im Parameter weniger als 1/1000, siehe nachstehende Tabelle).
Das zweite Merkmal des Z-Algorithmus ist (für den zweidimensionalen Fall) die Asymmetrie in der Reihenfolge der Addition von Punkten - auf der Y-Achse / dem Y-Parameter sind sie im Durchschnitt häufiger, das Bild wird am Ende jedes Zyklus um n ausgerichtet.
Algorithmus Z, eindimensionaler Fall, in VBA-Sprache:
Xmax =
Xmin =
Dx = (Xmax - Xmin) / 2
L = 2
Sx = 0
For n = 1 To K
Dx = Dx / 2
D = Dx
For j = 1 To L Step 2
X = Xmin + D
Cells(5, X) = "O" ' - / T(X)
X = Xmax - D
Cells(5, X) = "O"
D = D + Sx
Next j
Sx = Dx
L = L + L
Next nAlgorithmus Z, 2D-Fall, VBA-Sprache:
Xmax = ' 65 - , GIF
Xmin = ' 1
Ymax = ' 65
Ymin = ' 1
Dx = (Xmax - Xmin) / 2
Dy = (Ymax - Ymin) / 2
L = 2
Sx = 0
Sy = 0
For n = 1 To K ' K = 3 GIF
Dx = Dx / 2
Dy = Dy / 2
Tx = Dx
For j = 1 To L Step 2
X1 = Xmin + Tx
X2 = Xmax - Tx
Ty = Dy
For i = 1 To L Step 2
Y = Ymin + Ty
Cells(Y, X1) = "O" ' - / T(Y,X)
Cells(Y, X2) = "O"
Y = Ymax - Ty
Cells(Y, X1) = "O"
Cells(Y, X2) = "O"
Ty = Ty + Sy
Next i
Tx = Tx + Sx
Next j
Sx = Dx
Sy = Dy
L = L + L
Next nRechenkosten:
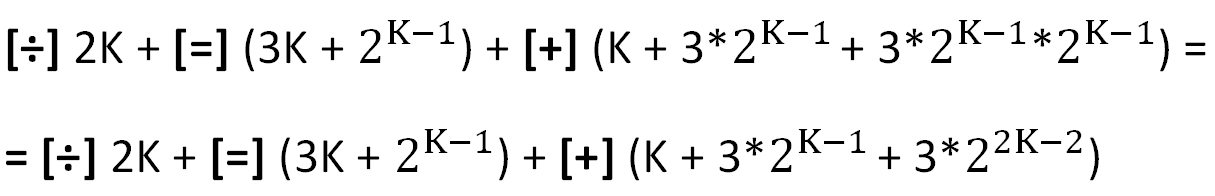
Die in den Berechnungen verwendeten Hauptoperationen sind in eckigen Klammern angegeben (die Kosten für die Organisation von Zyklen werden nicht berücksichtigt).
Hierbei ist zu beachten, dass die ziemlich "schwere" Operation der Division [÷] in diesem Fall nicht teuer ist, da die ganzzahlige Division durch 2 eine Verschiebung um eine Ziffer ist. Die relativen Kosten der Teilungs- und Zuweisungsoperation ([=], zweiter Term) tendieren schnell zu Null, wenn K wächst.
Gesamtpunkte:

Durchschnittskosten:

Für die ersten Werte von K führen wir Berechnungen mit diesen Formeln durch und füllen die Tabelle aus:

Hier ist "Bruchteil des Intervalls" der relative Schritt zwischen Punkten am Ende des Zyklus um n.
Die letzte Zeile ("Durchschnitt") zeigt die relativen Kosten pro Punkt - den Anteil der Additionen / Subtraktionen. Die Grenze liegt tendenziell bei 0,5625 oder 1 / 1,77777 der Additionsoperation.
Zurück zu der Behauptung aus dem ersten Teil des Artikels wird hier gezeigt, dass „der zur Diskussion vorgeschlagene Algorithmus extrem niedrige Rechenkosten aufweist und keine Nachteile oder Schwierigkeiten mit sich bringt“ und unter Bedingungen einer plötzlichen Unterbrechung der Berechnungen zusätzlich Vorteile hat. Es ist ratsam, es in allen geeigneten Anwendungen zu verwenden.
Ich bitte um Hilfe bei der Verteilung und Implementierung sowohl in Software als auch in Hardware.