
Sie haben beispielsweise eine SharePoint-Dokumentbibliothek. Wenn Sie dieser Bibliothek eine Datei hinzufügen, stellen Sie der Datei häufig zusätzlich bestimmte Metadaten zur Verfügung. Erstellen Sie mehrere Felder und schreiben Sie einige Informationen in diese, um die Dateien in dieser Bibliothek zu klassifizieren. Dies erfolgt jedoch manuell und für jede Datei müssen Sie jedes Mal Daten eingeben. SharePoint Syntex wurde entwickelt, um diesen Prozess zu automatisieren, indem Schlüsseldaten aus einer Datei nach einem benutzerdefinierten Modell extrahiert und diese Daten in Bibliotheksfeldern gespeichert werden. Das klingt gut. Mal sehen, wie es funktioniert?
Wie aktiviere ich SharePoint Syntex?
Da SharePoint Syntex unter einer separaten Lizenz steht, müssen wir diese Lizenz erwerben. Gehen Sie zur Microsoft-Website, suchen Sie das SharePoint Syntex-Produkt und klicken Sie auf "Kostenlose Testversion".

Wechseln Sie nach Eingabe Ihres Microsoft 365-Kontos und Bestätigung der Aktivierung der Testlizenz zum Microsoft 365-Verwaltungscenter. Wechseln Sie anschließend im linken Menü zum Abschnitt "Setup" und wählen Sie das Element "Inhaltsverständnis automatisieren". Bei einem russischen Gebietsschema wie meinem klingt es wie „Automatisierung des Inhaltsverständnisses“.
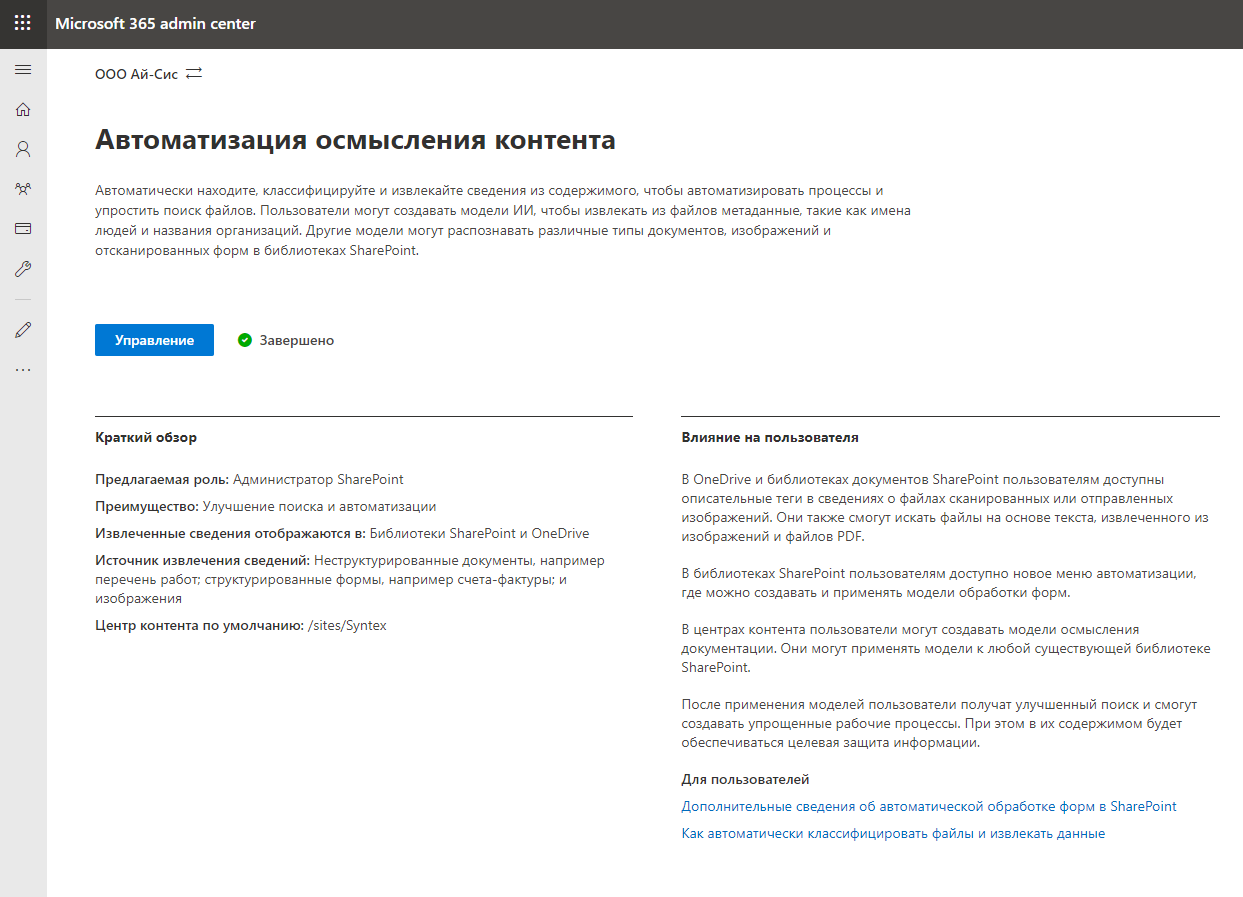
Wir gehen zu "Management" und fahren mit der Einrichtung des Dienstes fort. Zunächst muss angegeben werden, welche Bibliotheken die Funktionen von SharePoint Syntex unterstützen. Sie können bestimmte Bibliotheken auswählen oder alle Bibliotheken zulassen. Lass uns pleite gehen.
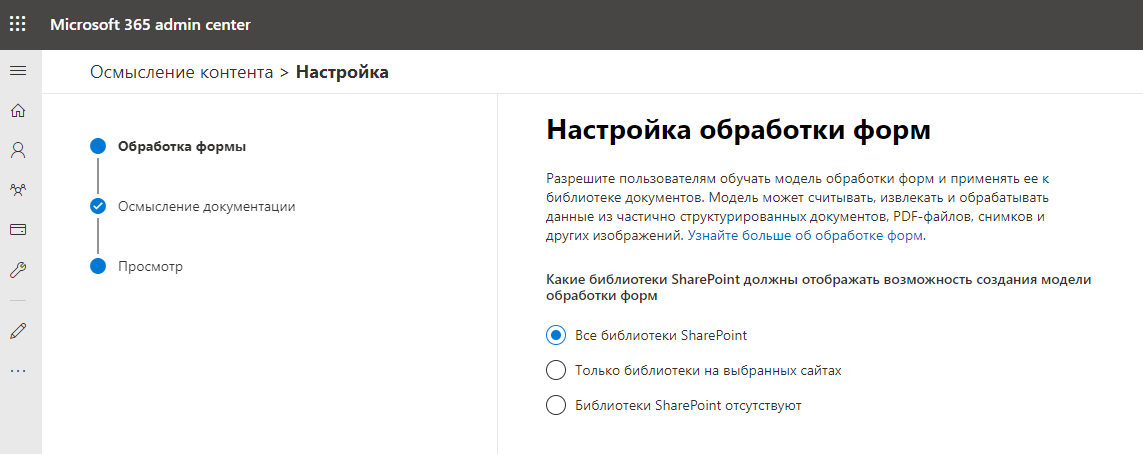
Als nächstes geben wir den Namen und die Adresse der Site an, die das Content Center sein wird, und speichern die trainierten Datenmodelle. Es sieht so aus, als würde eine neue SharePoint Online-Sammlungswebsite erstellt. Dies ist jedoch genau das, was passiert.
Das Erstellen einer Content Center-Site dauert einige Minuten. Es dauerte ungefähr 5 Minuten, ich schaffte es gerade, mir etwas Tee einzuschenken. Ich komme, und hier wurde das Verständnis des Inhalts bereits aktiviert, na ja, wow.
Konfigurieren von SharePoint Syntex
Wechseln Sie zur SharePoint Syntex-Website. Äußerlich sieht es aus wie eine normale SharePoint Online-Website, dies ist jedoch nur auf den ersten Blick der Fall. Auf dieser Site werden wir Datenverarbeitungs- und Analysemodelle einrichten und trainieren.
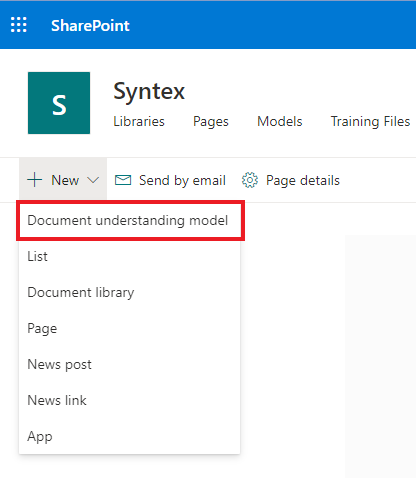
Es ist Zeit, mit dem Einrichten des Modells zu beginnen. Klicken Sie auf "Neu" und wählen Sie den Punkt "Modell zum Verständnis von Dokumenten".
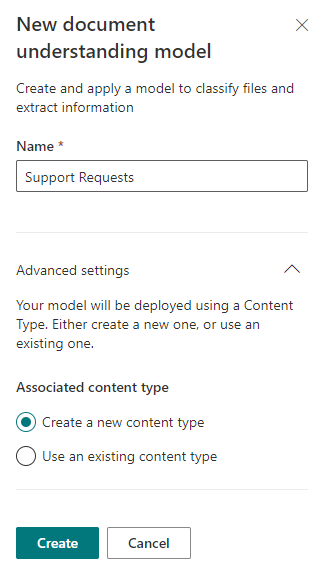
Wir schreiben den Namen unseres zukünftigen Modells und weisen darauf hin, dass ein neuer Inhaltstyp dafür erstellt werden muss. Ich habe bereits den Fall, den Sie wahrscheinlich aus früheren Artikeln kennen, mit dem Antrag auf technischen Support ausgewählt. Verschwinden Sie nicht die gleichen Vorlagen für solche Einsprüche.
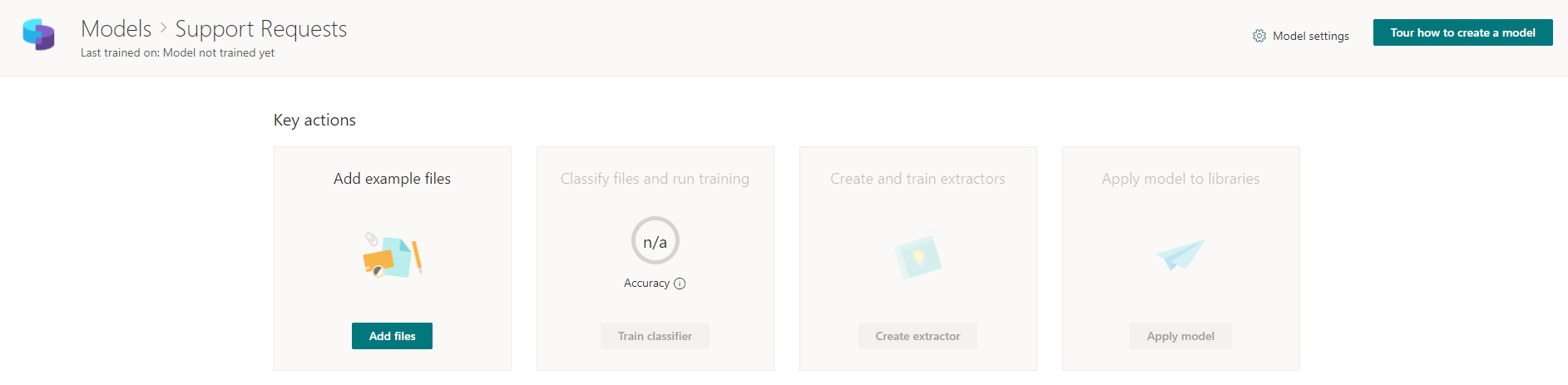
Als nächstes werden wir von einer Seite mit schrittweisen Anweisungen begrüßt, die beschreiben, was wir tun müssen, damit das zukünftige Modell funktioniert und im Idealfall korrekt funktioniert. Zunächst müssen Sie mehrere Dateien hochladen (mindestens 5 werden empfohlen), SharePoint Syntex bei der Klassifizierung unterstützen und die sogenannten "Extractors" - Vorlagen zum Extrahieren von Daten aus Dateien einrichten. Sobald Sie den gesamten Weg zurückgelegt haben, können Sie dieses Modell auf die erforderlichen SharePoint-Bibliotheken anwenden.
Wir fügen vorbereitete Vorlagendateien hinzu, die zur Klassifizierung zukünftiger realer Dateien verwendet werden.
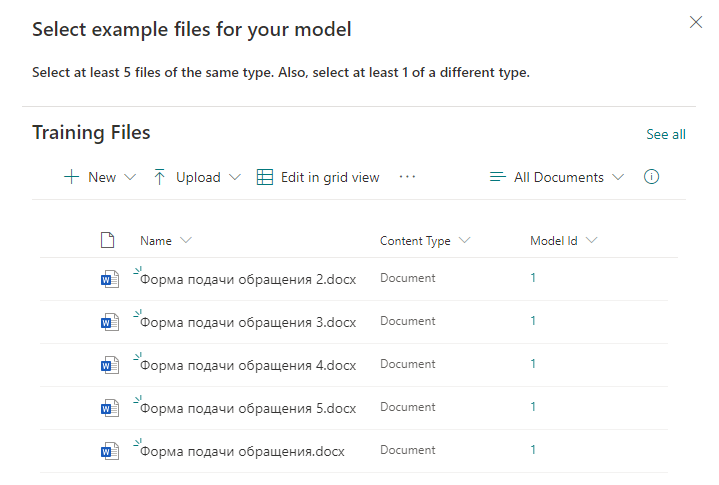
Dann geben wir die Schlüsselwörter an, mit denen die Suche nach Informationen im Dokument durchgeführt wird. In jeder Zeile geben wir ein neues Wort oder eine neue Phrase an, die für die Suche verwendet wird.
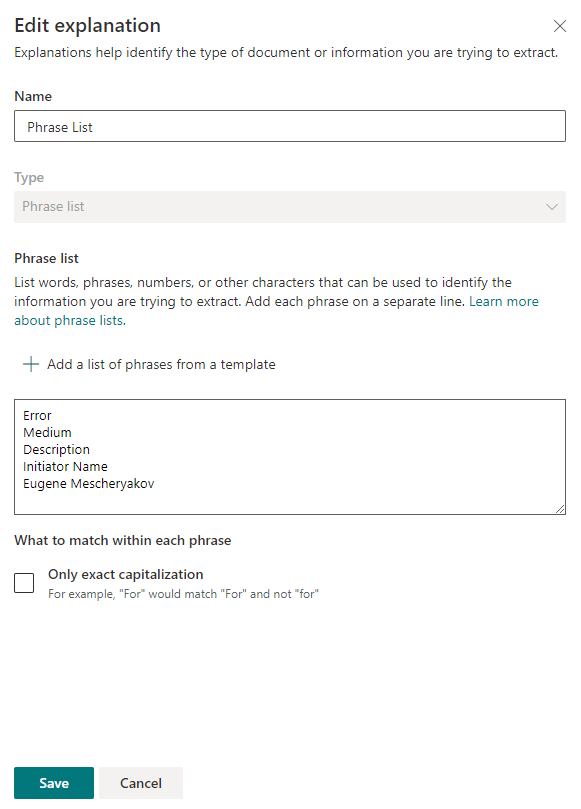
Nach dem Speichern der Einstellungen können Sie versuchen, die vorhandenen Dateien nach Schlüsselphrasen zu durchsuchen. Wenn eine Übereinstimmung gefunden wird, wird neben der Datei "Übereinstimmung" angezeigt.
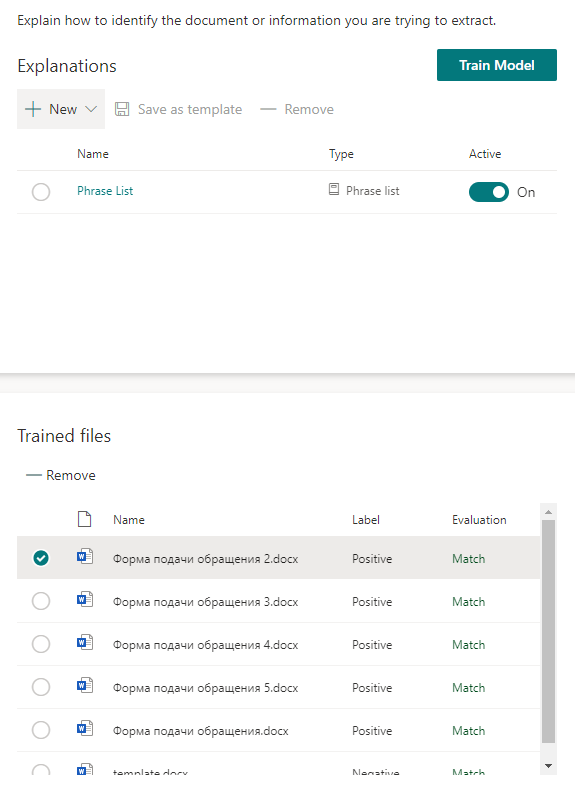
Wir fangen an, das Modell zu trainieren und gehen Tee einschenken. Es wird einige Zeit in Anspruch nehmen.
Nach dem Training des Modells müssen die "Extraktoren" - Datenextraktionsmodelle konfiguriert werden. Jeder Extraktor ist im Wesentlichen ein bestimmter Typ eines SharePoint-Felds, das automatisch in der Zielbibliothek generiert wird. Nach dem Hinzufügen einer Datei zu dieser Bibliothek werden die aus der Datei extrahierten Informationen in dieses Feld geschrieben.
Wenn Sie einen Extraktor erstellen, müssen Sie dessen Namen und Typ angeben. Derzeit werden 4 Typen unterstützt:
- Einzeiliger Text
- Mehrzeiliger Text
- Datum (und Uhrzeit
- Nummer
Sie können auch vorhandene Felder in einer SharePoint-Bibliothek verwenden.
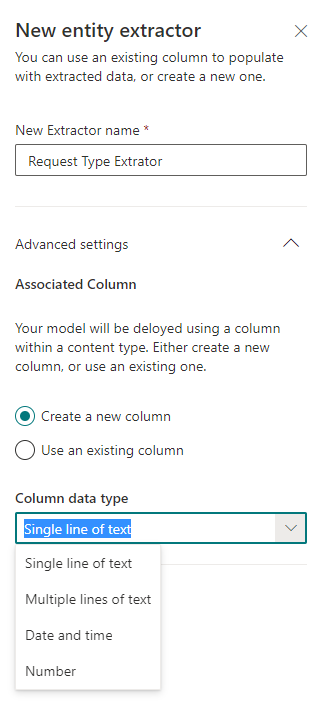
Doppelklicken Sie beim Einrichten des Extraktors in der Vorlage der hochgeladenen Datei auf die Informationen, die Sie extrahieren möchten und die im vorherigen Schritt erkannt wurden.
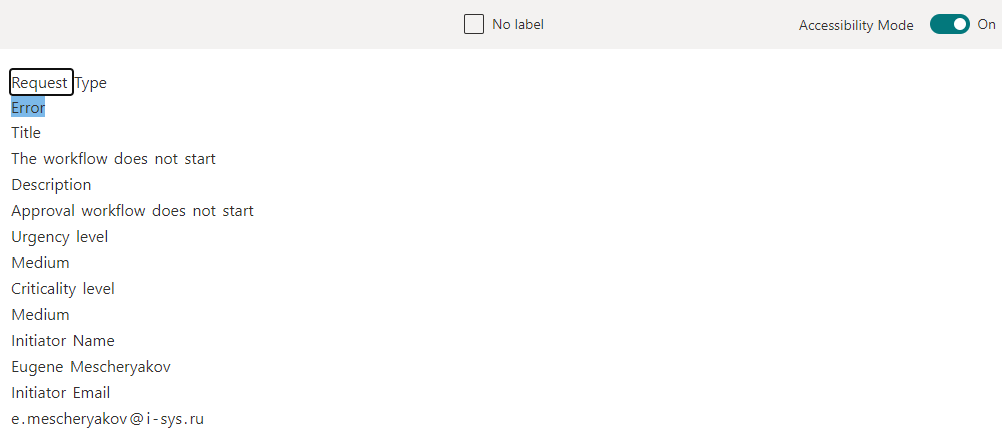
Wir erstellen mehrere solcher Extraktoren, markieren die erforderlichen Daten und fahren anschließend mit dem letzten Teil fort. Dabei wenden wir das trainierte Modell auf die SharePoint-Bibliothek an und prüfen, ob alles überhaupt funktioniert.

Wählen Sie die gewünschte SharePoint-Website aus und geben Sie die Zielbibliothek an. Ich habe die HelpDesk Requests-Bibliothek im Voraus erstellt und keine Änderungen daran vorgenommen, sodass sie in ihrer ursprünglichen Form belassen wurde. Wir speichern die Einstellungen und gehen in die Bibliothek. Nach dem Speichern der SharePoint Syntex-Einstellungen werden in der Bibliothek neue SharePoint-Felder angezeigt, die den erstellten Extraktoren nach Name und Typ entsprechen.
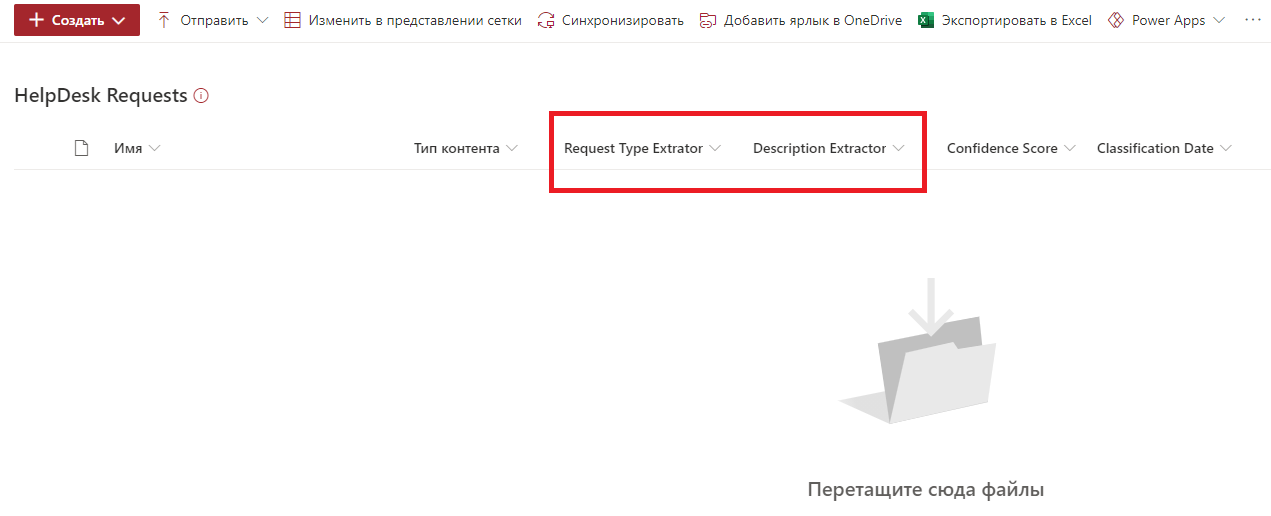
Es bleibt, die Datei zur Bibliothek hinzuzufügen und zu überprüfen. Fügen Sie eine weitere Anforderungsvorlagendatei hinzu.

SharePoint Syntex erkannte den Falltyp und die Beschreibung. Die Daten werden in Feldern gespeichert. Alles scheint in Ordnung zu sein.
Gesamt
Das Einrichten des SharePoint Syntex-Datenmodells hat sehr wenig Zeit in Anspruch genommen. Alles ist sehr intuitiv und einfach zu konfigurieren und zu verwenden. Auf der positiven Seite sehe ich eine wirklich nützliche Möglichkeit, wichtige Informationen automatisch aus dem Dateiinhalt zu extrahieren und in SharePoint-Felder zu schreiben. Diese Funktion kann die Arbeit erheblich beschleunigen und unnötige Phasen der Benutzerarbeit beseitigen, wenn nach dem Hinzufügen einer Datei eine Reihe von Anforderungen in der Bibliothek noch manuell ausgefüllt werden müssen. Nachteile - Ich möchte mehr Arten von Feldern für Extraktoren und eine engere Integration in Microsoft Power Platform. Ich bin mir jedoch sicher, dass dies bald im Rahmen der nächsten Updates hinzugefügt wird.
Außerdem erfordert SharePoint Syntex eine separate Lizenz (5 USD pro Benutzer und Monat) und ist derzeit nicht in den Enterprise-Lizenzen von Microsoft 365 enthalten. In Zukunft kann sich dies jedoch ändern, und SharePoint Syntex wird möglicherweise Teil der Basisdienste von Microsoft 365. Versuchen Sie, die Testversion zu aktivieren für einen Monat und sehen Sie sich die Funktionen dieses Dienstes an. Habt alle einen schönen Tag!