
Foto von Cristian Cristian auf Unsplash
In naher Zukunft wird es möglich sein, den Amazon Echo- oder Nest Audio-Sprachlautsprecher zu aktivieren, in Google oder Siri auf Apple-Geräten zu suchen, ohne eine Begrüßung wie "Hallo, Google!" Mit Hilfe der KI haben Wissenschaftler aus den USA einen Algorithmus entwickelt, mit dem intelligente Sprachassistenten verstehen, dass eine Person mit ihnen spricht.
In normalen Gesprächen bestimmen die Leute den Adressaten einer Nachricht, indem sie sie einfach betrachten. Die meisten Sprachgeräte sind jedoch auf die Aktivierung mit Schlüsselphrasen zugeschnitten, die in der realen Kommunikation niemand sagt. Das Verständnis nonverbaler Hinweise durch Sprachassistenten würde die Kommunikation einfacher und intuitiver machen. Besonders wenn es mehrere solcher Geräte im Haus gibt.
Wissenschaftler der Carnegie Mellon University stellen fest, dass der entwickelte Algorithmus die Richtung der Stimme (DoV) mithilfe eines Mikrofons bestimmt.
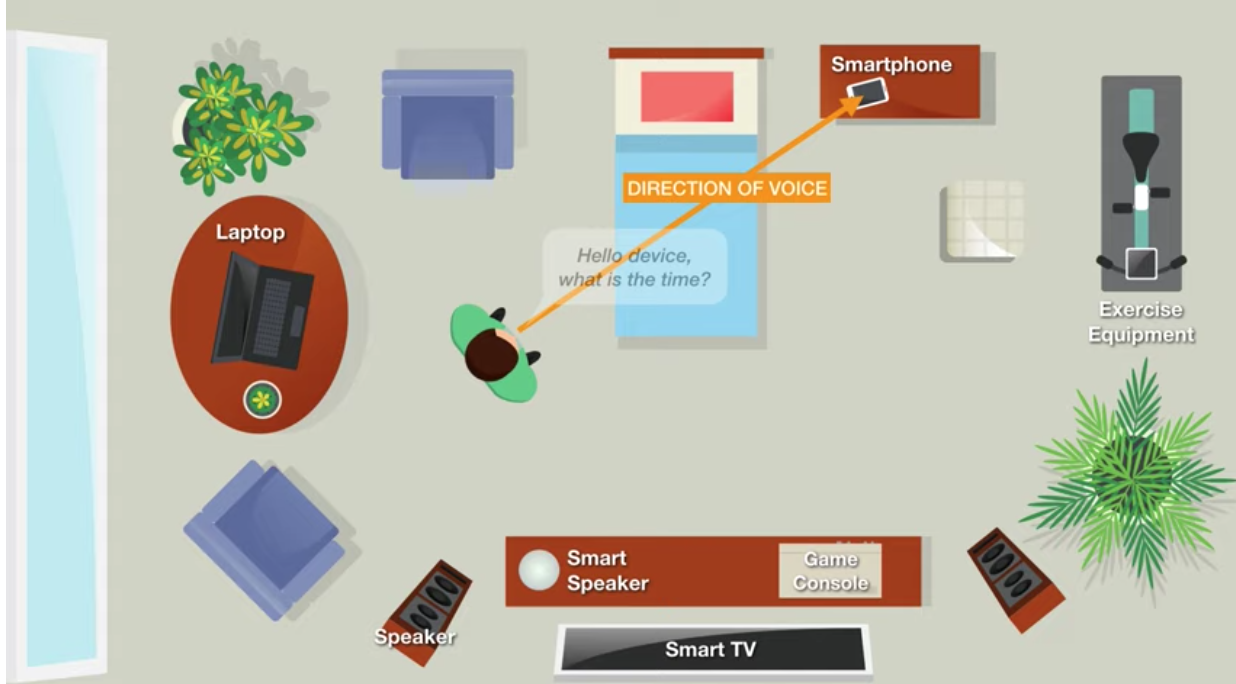
DoV unterscheidet sich von der Erkennung der Ankunftsrichtung (DoA).
Laut den Forschern ermöglicht die Verwendung von DoV gezielte Befehle, die dem Augenkontakt der Gesprächspartner zu Beginn eines Gesprächs ähneln. Die Kameras der Geräte sind jedoch nicht beteiligt. Somit gibt es eine natürliche Interaktion mit verschiedenen Arten von Geräten ohne Verwirrung.
Unter anderem reduziert die Technologie die Anzahl der versehentlichen Aktivierungen von Sprachassistenten, die ständig in Bereitschaft sind.
Die neue Audiotechnologie basiert auf den Merkmalen der Sprachschallausbreitung. Wenn die Stimme in das Mikrofon geleitet wird, wird sie von niedrigen und hohen Frequenzen dominiert. Wenn die Stimme reflektiert wird, dh anfänglich auf ein anderes Gerät gerichtet ist, nehmen die hohen Frequenzen im Vergleich zu niedrigen deutlich ab.
Der Algorithmus analysiert auchSchallausbreitung in den ersten 10 Millisekunden. Hier sind zwei Szenarien möglich: Der
Benutzer wird zum Mikrofon gedreht. Das Signal, das zuerst am Mikrofon ankommt, ist im Vergleich zu möglichen anderen Signalen, die von anderen Geräten im Haus reflektiert werden, klar.
Der Benutzer ist vom Mikrofon abgewandt. Alle Schallschwingungen werden dupliziert und verzerrt.
Der Algorithmus misst die Wellenform, berechnet die Spitze ihrer Intensität, vergleicht sie mit dem Durchschnittswert und bestimmt, ob die Stimme auf das Mikrofon gerichtet war oder nicht.
Durch Messung der Stimmausbreitung konnten die Wissenschaftler mit einer Genauigkeit von 93,1% feststellen, ob sich der Lautsprecher vor einem bestimmten Mikrofon befand oder nicht. Sie stellten fest, dass dies das bisher beste Ergebnis dieser Art und ein wichtiger Schritt zur Implementierung der Lösung in vorhandene Geräte ist. Beim Versuch, einen der acht Winkel zu bestimmen, unter denen eine Person auf das Gerät schaut, wurde eine Genauigkeit von 65,4% erreicht . Dies reicht für eine Anwendung immer noch nicht aus, deren Kern die aktive Interaktion mit Benutzern ist.
Um Informationen zu sammeln, verwendeten die Ingenieure Python. Die Signale wurden basierend auf dem Extra-Trees-Klassifizierungsalgorithmus verarbeitet.
Die während der Entwicklung gesammelten Daten und Algorithmen stehen GitHub offen . Sie können verwendet werden, wenn Sie Ihren eigenen Sprachassistenten erstellen.
