Tensorflow verliert zwar im Forschungsumfeld an Boden, ist aber in der praktischen Entwicklung immer noch beliebt . Eine der Stärken von TF, die es am Leben erhält, ist die Fähigkeit, Modelle für die Bereitstellung in ressourcenbeschränkten Umgebungen zu optimieren. Hierfür gibt es spezielle Frameworks: Tensorflow Lite für mobile Geräte und Tensorflow Servingfür den industriellen Einsatz. Es gibt genügend Tutorials zu ihrer Verwendung im Web (und sogar auf Habré). In diesem Artikel haben wir unsere Erfahrungen bei der Optimierung von Modellen ohne Verwendung dieser Frameworks gesammelt. Wir werden uns einige der Methoden und Bibliotheken ansehen, die diese Aufgabe erfüllen, beschreiben, wie Sie Speicherplatz und RAM sparen können, die Stärken und Schwächen jedes Ansatzes und einige unerwartete Auswirkungen, auf die wir gestoßen sind.
Unter welchen Bedingungen arbeiten wir?
Eine der klassischen NLP-Aufgaben ist die thematische Klassifizierung von Kurztexten. Klassifikatoren werden durch eine Vielzahl unterschiedlicher Architekturen dargestellt, die von klassischen Methoden wie SVC bis zu Transformatorarchitekturen wie BERT und seinen Derivaten reichen. Wir werden uns CNN - Faltungsmodelle ansehen.
Eine wichtige Einschränkung für uns ist die Notwendigkeit, Modelle (als Teil des Produkts) auf Maschinen ohne GPU zu trainieren und zu verwenden. Dies wirkt sich hauptsächlich auf die Lerngeschwindigkeit und die Schlussfolgerung aus.
Eine weitere Bedingung ist, dass die Modelle für die Klassifizierung trainiert und in Sätzen von mehreren Teilen verwendet werden. Eine Reihe von Modellen, auch einfache, können viele Ressourcen verbrauchen, insbesondere RAM. Wir verwenden unsere eigene Lösung zum Servieren von Modellen. Wenn Sie jedoch mit Modellsätzen arbeiten müssen, schauen Sie sich Tensorflow Serving an .
TF 1.x, . TF 2.x , API, .
.
TF-
Shallow CNN — . .

v x k, v — , k — .
:
- Embedding-, .
- w x k. , (1, 1, 2, 3) 4 , 1 , 2 3 , .
- Max-pooling .
- , dropout- softmax- .
Adam, .
: .
, , 128 c w = 2 k = 300 () [filter_height, filter_width, in_channels, output_channels] — , 2*300*1*128 = 76800 float32, , 76800*(32/8) = 307200 .
? ( 220 . ) 300 265 . , .
TF . ( ), , , — ( ), . (). :
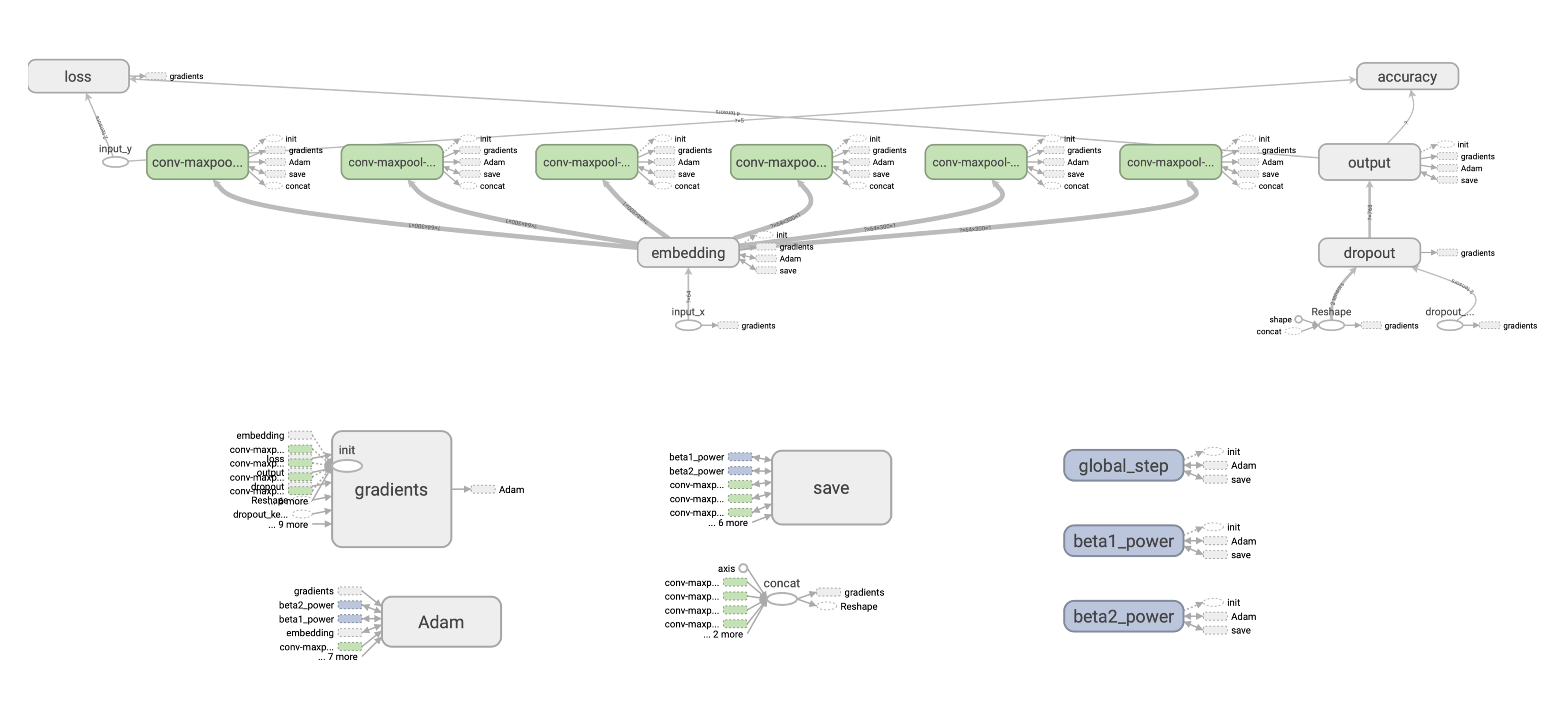
. , : SavedModel. , .
Checkpoint
, Saver API:
saver = tf.train.Saver(save_relative_paths=True)
ckpt_filepath = saver.save(sess, "cnn.ckpt"), global_step=0)global_step , , — cnn-ckpt-0.
<model_path>/cnn_ckpt :

checkpoint — . , TF . , .
.data , . , — 800 . , (≈265 ). ( ). , .
.index .
.meta — , (, , ), GraphDef, . , . — .meta , ? , TF - embedding-. , , , , , . , , :
with tf.Session() as sess:
saver = tf.train.import_meta_graph('models/ckpt_model/cnn_ckpt/cnn.ckpt-0.meta') # load meta
for n in tf.get_default_graph().as_graph_def().node:
print(n.name, n['attr'].shape)SavedModel
, . . API tf.saved_model. tf.saved_model, TF- (TFLite, TensorFlow.js, TensorFlow Serving, TensorFlow Hub).
:
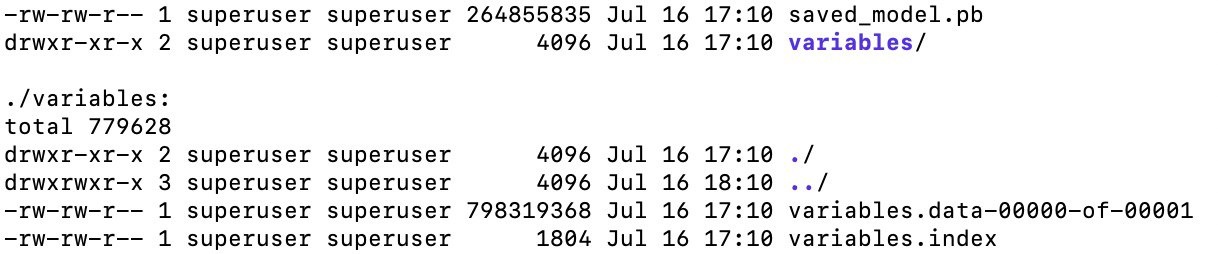
saved_model.pb, , , .meta , (, ), API, ( CLI, ).
SavedModel — , . “” . , , - — , .
, CNN-, TF 1.x, . .
, 1 , :
-
. , , ( tools.optimize_for_inference ). -
. , , — , tf.trainable_variables(). -
, . , (. BERT). -
. , . .
, , . , forward pass, . , . 1 265 .
TF 1.x , .
( ) GraphDef:
graph = tf.get_default_graph()
input_graph_def = graph.as_graph_def() . : tf.python.tools.freeze_graph tf.graph_util.convert_variables_to_constants. ( ) (, ['output/predictions']), , , . .
output_graph_def = graph_util.convert_variables_to_constants(self.sess, input_graph_def, output_node_names), .
freeze_graph() ( , , ). graph_util.convert_variables_to_constants() :
with tf.io.gfile.GFile('graph.pb', 'wb') as f:
f.write(output_graph_def.SerializeToString())266 , :
# GraphDef
with tf.io.gfile.GFile(graph_filepath, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
#
self.input_x = tf.placeholder(tf.int32, [None, self.properties.max_len], name="input_x")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
# graph_def
input_map = {'input_x': self.input_x, 'dropout_keep_prob': self.dropout_keep_prob}
tf.import_graph_def(graph_def, input_map), import:
predictions = graph.get_tensor_by_name('import/output/predictions:0'):
feed_dict = {self.input_x: encode_sentence(sentence), self.dropout_keep_prob: 1.}
sess.run(self.predictions, feed_dict), :
- . ,
sess.run(...). , CPU 20 ms, ~2700 ms. , . SavedModel . - RAM. RAM, . ~265 , . , TF GraphDef .
- – RAM TF . 1.15, TF 1.x, 118 MiB, 1.14 – 3 MiB.
, . ? / TF- tf.train.Saver. , , , :
- MetaGraph
tf.train.Saver . , :
saver = tf.train.Saver(var_list=tf.trainable_variables())MetaGraph . , meta . MetaGraph save:
ckpt_filepath = saver.save(self.sess, filepath, write_meta_graph=False)1014 M 265 M ( , ).
, TF 1.x:
- Grappler: c tensorflow
- Pruning API: google-research
- Graph Transform Tool:
, — tensorflow, Grappler. Grappler . , set_experimental_options. , zip . , zip , . Grappler .
google-research mask threshold, . . , , mask threshold, , , . .
Grappler, . : ? , ? , 0.99 . , mc, hex :

, , . . -, . -, , , , . , .
CNN. .
, . Graph transform tool.
quantize_weights 8 . , 8- . , , - .
quantize_nodes 8- . .
, - . quantize_weights - , 4 .
, , TensorFlow Lite, .
— , . 64 (32) , .
RAM Ubuntu ( numpy int64) . 220 , int32, int16. .

tf-. float16. , , ( 10%), ( 10 ). , , epsilon learning_rate . , , .
RAM
, . , .
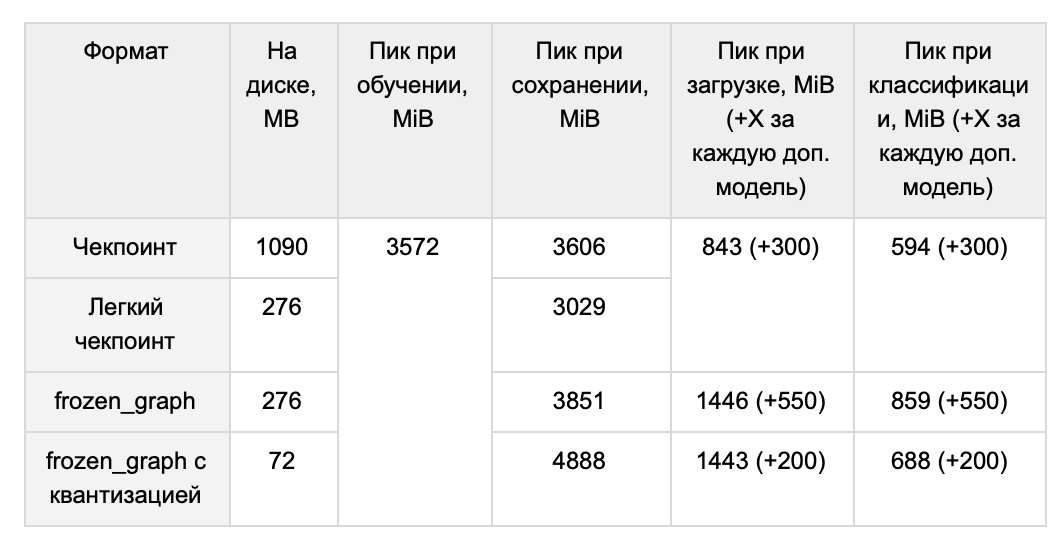
, . . .
QA-
Q: -, - ?
A: , . word2vec. ( , , min count, learning rate), 220 ( — 265 MB) CNN, 439 (510 MB).
- , , , - . , ( ). , . YouTokenToMe, , , .. , .., . . , , , . 30 (37 MB) , 3.7 CPU 2.6 GPU. ( ), OOV-.
Q: , , ?
A: , .
:
1. :
with tf.gfile.GFile(path_to_pb, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
tf.import_graph_def(graph_def, name='')
return graph2. "" :
sess.run(restored_variable_names) 3. , .
4. , , :
tf.Variable(tensors_to_restore["output/W:0"], name="W"), .
, , .
Wir haben nicht versucht, die mit den anderen beschriebenen Methoden komprimierten Modelle neu zu trainieren, aber theoretisch sollte dies keine Probleme verursachen.
F: Gibt es andere Möglichkeiten zur Reduzierung der Optimierung, die Sie nicht berücksichtigt haben?
A: Wir haben einige Ideen, die wir nie realisieren konnten. Erstens ist eine konstante Faltung eine "Faltung" einer Teilmenge von Diagrammknoten, eine Vorberechnung der Werte von Teilen des Diagramms, die schwach von den Eingabedaten abhängen. Zweitens scheint es in unserem Modell eine gute Lösung zu sein, Einbettungen zu beschneiden.