Die Verarbeitung von ein paar Gigabyte Daten auf einem Laptop kann nur dann eine entmutigende Aufgabe sein, wenn nicht viel RAM und eine gute Verarbeitungsleistung vorhanden sind.
Trotzdem müssen Datenwissenschaftler noch alternative Lösungen für dieses Problem finden. Es gibt Optionen zum Einrichten von Pandas für die Verarbeitung großer Datenmengen, den Kauf von GPUs oder den Kauf von Cloud-Computing-Leistung. In diesem Artikel wird erläutert, wie Sie Dask für große Datenmengen auf Ihrem lokalen Computer verwenden.
Dask und Python
Dask ist eine flexible Parallel-Computing-Bibliothek für Python. Es funktioniert gut mit anderen Open Source-Projekten wie NumPy, Pandas und Scikit-Learn. Dask hat eine Array - Struktur , die auf NumPy Arrays äquivalent ist, Dask Datenrahmen zu Pandas ähnlich sind Datenrahmen und Dask-ML ist Scikit-Learn.
Diese Ähnlichkeiten machen es einfach, Dask in Ihre Arbeit zu integrieren. Der Vorteil von Dask besteht darin, dass Sie Berechnungen auf mehrere Kerne Ihres Computers skalieren können. So haben Sie die Möglichkeit, mit großen Datenmengen zu arbeiten, die nicht in den Speicher passen. Sie können auch Berechnungen beschleunigen, die normalerweise viel Platz beanspruchen.
Quelle
Dask DataFrame
Beim Laden einer großen Datenmenge liest Dask normalerweise eine Stichprobe der Daten, um die Datentypen zu erkennen. Dies führt meist zu Fehlern, da in derselben Spalte unterschiedliche Datentypen vorhanden sein können. Es wird empfohlen, Typen vorab zu deklarieren, um Fehler zu vermeiden. Dask kann große Dateien herunterladen, indem es sie in durch den Parameter definierte Blöcke aufteilt
blocksize.
data_types ={'column1': str,'column2': float}
df = dd.read_csv(“data,csv”,dtype = data_types,blocksize=64000000 )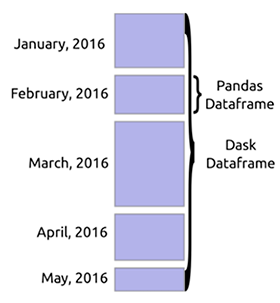
Quelle
Befehle in Dask Datenrahmen sind ähnlich wie Pandas Befehle. DasAbrufen
headund dertail Datenrahmen sind beispielsweise ähnlich:
df.head()
df.tail()Die Funktionen im DataFrame sind faul. Das heißt, sie werden erst ausgewertet, wenn die Funktion aufgerufen wird
compute.
df.isnull().sum().compute()Da die Daten in Blöcken geladen werden, schlagen einige Pandas-Funktionen wie
sort_values()fehl. Sie können die Funktion jedoch verwendennlargest().
Cluster in Dask
Paralleles Rechnen ist der Schlüssel zu Dask, da Sie damit auf mehreren Kernen gleichzeitig lesen können. Dask bietet,
machine schedulerdass auf einem einzelnen Computer ausgeführt wird. Es skaliert nicht. Es gibt auch eine distributed scheduler, mit der Sie auf mehrere Maschinen skalieren können.
Die Verwendung
dask.distributederfordert eine Client-Konfiguration. Dies ist das erste, was Sie tun, wenn Sie es dask.distributed in Ihrer Analyse verwenden möchten. Es bietet geringe Latenz, Datenlokalität und Worker-to-Worker-Kommunikation und ist einfach zu konfigurieren.
from dask.distributed import Client
client = Client()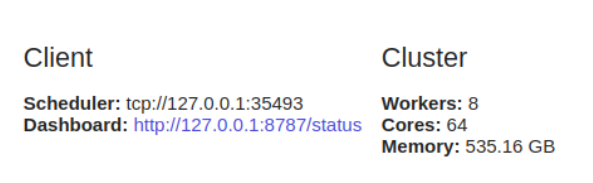
Es ist
dask.distributedvorteilhaft, es auch auf einem einzelnen Computer zu verwenden, da es Diagnosefunktionen über ein Dashboard bietet.
Wenn Sie nicht konfigurieren
Client, verwenden Sie standardmäßig den Maschinenplaner für einen Computer. Es bietet Parallelität auf einem einzelnen Computer mithilfe von Prozessen und Threads.
Dask ML
Dask ermöglicht auch paralleles Modelltraining und Prognosen. Ziel
dask-mlist es, skalierbares maschinelles Lernen anzubieten. Wenn Sie deklarieren n_jobs = -1 scikit-learn, können Sie Berechnungen parallel ausführen. Dask verwendet diese Funktion, um Berechnungen in einem Cluster durchzuführen. Sie können dies mit dem joblib- Paket tun , das Parallelität und Pipelining in Python ermöglicht. Mit Dask ML können Sie Scikit-Lernmodelle und andere Bibliotheken wie XGboost verwenden.
Eine einfache Implementierung würde so aussehen.
Importieren Sie zunächst
train_test_split, um Ihre Daten in Trainings- und Testfälle aufzuteilen.
from dask_ml.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)Importieren Sie dann das gewünschte Modell und instanziieren Sie es.
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(verbose=1)Dann müssen Sie importieren
joblib, um paralleles Rechnen zu aktivieren.
import joblibBeginnen Sie dann mit dem Training und der Prognose mit dem parallelen Backend.
from sklearn.externals.joblib import parallel_backend
with parallel_backend(‘dask’):
model.fit(X_train,y_train)
predictions = model.predict(X_test)Grenzen und Speichernutzung
Einzelne Aufgaben in Dask können nicht parallel ausgeführt werden. Worker sind Python-Prozesse, die die Vor- und Nachteile der Python-Berechnung erben. Wenn Sie in einer verteilten Umgebung arbeiten, müssen Sie außerdem darauf achten, die Sicherheit und den Datenschutz Ihrer Daten zu gewährleisten.
Dask verfügt über einen zentralen Scheduler, der Daten auf Worker-Knoten und im Cluster überwacht. Es verwaltet auch die Freigabe von Daten aus dem Cluster. Wenn die Aufgabe abgeschlossen ist, wird sie sofort aus dem Speicher entfernt, um Platz für andere Aufgaben zu schaffen. Wenn jedoch etwas von einem bestimmten Client benötigt wird oder für aktuelle Berechnungen wichtig ist, wird es im Speicher gespeichert.
Eine weitere Einschränkung von Dask besteht darin, dass nicht alle Funktionen von Pandas implementiert werden. Die Pandas-Oberfläche ist sehr groß, sodass Dask sie nicht vollständig abdeckt. Das heißt, einige dieser Operationen in Dask durchzuführen, kann eine Herausforderung sein. Darüber hinaus werden langsame Operationen von Pandas in Dask auch langsam sein.
Wenn Sie keinen Dask DataFrame benötigen
In den folgenden Situationen ist Dask möglicherweise nicht die richtige Option für Sie:
- Wenn Pandas Funktionen hat, die Sie benötigen, Dask sie jedoch nicht implementiert hat.
- Wenn Ihre Daten perfekt in den Speicher Ihres Computers passen.
- Wenn Ihre Daten nicht tabellarisch dargestellt werden. Wenn ja, versuchen Sie dask.bag oder disk.array .
Abschließende Gedanken
In diesem Artikel haben wir uns angesehen, wie Sie Dask verwenden können, um verteilt mit großen Datenmengen auf Ihrem lokalen Computer zu arbeiten. Wir haben gesehen, dass wir Dask verwenden können, da uns die Syntax bereits bekannt ist. Auch Dask kann auf Tausende von Kernen skaliert werden.
Wir haben auch gesehen, dass wir es beim maschinellen Lernen für Vorhersage und Training verwenden können. Wenn Sie mehr wissen möchten, lesen Sie diese Materialien in der Dokumentation .
