Ich sollte beachten, dass ich einen Monat, nachdem ich mich mit dieser Technologie vertraut gemacht hatte, anfing, Antidepressiva zu verwenden. Ob NiFi der Auslöser oder der letzte Strohhalm war, ist nicht sicher, ebenso wie seine Beteiligung an dieser Tatsache. Aber da ich mich verpflichtet habe, alles zu skizzieren, was einen potenziellen Anfänger auf diesem Weg erwartet, muss ich so offen wie möglich sein.
In einer Zeit, in der Apache NiFi technisch gesehen eine leistungsstarke Verbindung zwischen verschiedenen Diensten darstellt (es tauscht Daten zwischen ihnen aus, sodass sie auf dem Weg angereichert und geändert werden können), betrachte ich dies aus der Sicht eines Analysten . Dies liegt daran, dass NiFi ein sehr praktisches ETL-Tool ist. Insbesondere als Team konzentrieren wir uns auf den Aufbau der SaaS-Architektur.
Die Erfahrung mit der Automatisierung eines meiner Workflows, nämlich die Erstellung und Verteilung wöchentlicher Berichte über Jira Software , möchte ich in diesem Artikel offenlegen. Übrigens werde ich auch die Task-Tracker-Analysemethode beschreiben und veröffentlichen, die die Frage klar beantwortet - was machen die Mitarbeiter -, die ich in naher Zukunft auch beschreiben und veröffentlichen werde.
Trotz des Engagements dieses Artikels für Anfänger halte ich es für richtig und nützlich, wenn erfahrene Architekten (sozusagen Gurus) ihn in Crommentionen überprüfen oder ihre Anwendungsfälle von NiFi in verschiedenen Tätigkeitsbereichen teilen. Viele Leute, einschließlich mir, werden es Ihnen danken.
Apache NiFi-Konzept in Kürze.
Apache NiFi ist ein OpenSource-Produkt zur Automatisierung und Datenflusssteuerung zwischen Systemen. Es ist wichtig, sofort zwei Dinge zu erkennen.
Die erste ist die Low-Code-Zone. Was ich meine? Es wird davon ausgegangen, dass alle Manipulationen mit Daten vom Zeitpunkt ihrer Eingabe in NiFi bis zur Extraktion mit Standardwerkzeugen (Prozessoren) durchgeführt werden können. In besonderen Fällen gibt es einen Prozessor zum Ausführen von Skripten aus Bash.
Dies deutet darauf hin, dass etwas in NiFi falsch ist - es ist ziemlich schwierig (aber ich habe es geschafft! - das ist der zweite Punkt). Schwierig, weil jeder Prozessor Sie sofort rausschmeißen wird - Wohin sollen Fehler gesendet werden? Was tun mit ihnen? Wie lange Warten? Und hier hast du mir ein wenig Platz gegeben! Haben Sie die Dokumentation sorgfältig gelesen? usw.

Der zweite (Schlüssel) ist das Konzept der Streaming-Programmierung und nichts weiter. Hier habe ich es persönlich nicht sofort verstanden (bitte nicht beurteilen). Mit Erfahrung in der funktionalen Programmierung in R habe ich unwissentlich Funktionen in NiFi gebildet. Letztendlich - wiederholen - sagten mir meine Kollegen, als sie meine vergeblichen Versuche sahen, diese "funktionierenden" Freunde zu finden.
Ich denke, die Theorie reicht für heute, lasst uns alles aus der Praxis besser lernen. Formulieren wir eine Ähnlichkeit der technischen Spezifikationen für die wöchentliche Jira-Analyse.
- Holen Sie sich das Arbeitsprotokoll und den Verlauf der Änderungen aus dem Fett für die Woche.
- Zeigen Sie grundlegende Statistiken für diesen Zeitraum an und beantworten Sie die Frage: Was hat das Team getan?
- Bericht an Chef und Kollegen senden.
Um der Welt mehr Nutzen zu bringen, habe ich nicht wöchentlich angehalten und einen Prozess entwickelt, mit dem eine viel größere Datenmenge heruntergeladen werden kann.
Lass es uns herausfinden.
Die ersten Schritte. Daten von der API abrufen
Apache NiFi hat kein separates Projekt. Wir haben nur einen gemeinsamen Arbeitsbereich und die Möglichkeit, darin Gruppen von Prozessen zu bilden. Das ist völlig ausreichend.
Suchen Sie die Prozessgruppe in der Symbolleiste und erstellen Sie die Gruppe Jira_report. Gehen Sie zur Gruppe und beginnen Sie mit dem Erstellen des Workflows. Die meisten Prozessoren, aus denen es zusammengebaut werden kann, erfordern eine Upstream-Verbindung. Mit einfachen Worten, dies ist ein Auslöser, auf den der Prozessor feuert. Daher ist es logisch, dass der gesamte Fluss mit einem regulären Trigger beginnt - in NiFi ist dies der GenerateFlowFile-Prozessor. Was macht er. Erstellt eine Streaming-Datei, die aus einer Reihe von Attributen und Inhalten besteht. Attribute sind Zeichenfolgenschlüssel / Wert-Paare, die dem Inhalt zugeordnet sind.
Inhalt ist eine reguläre Datei, eine Reihe von Bytes. Stellen Sie sich vor, der Inhalt ist ein Anhang zu einer FlowFile.
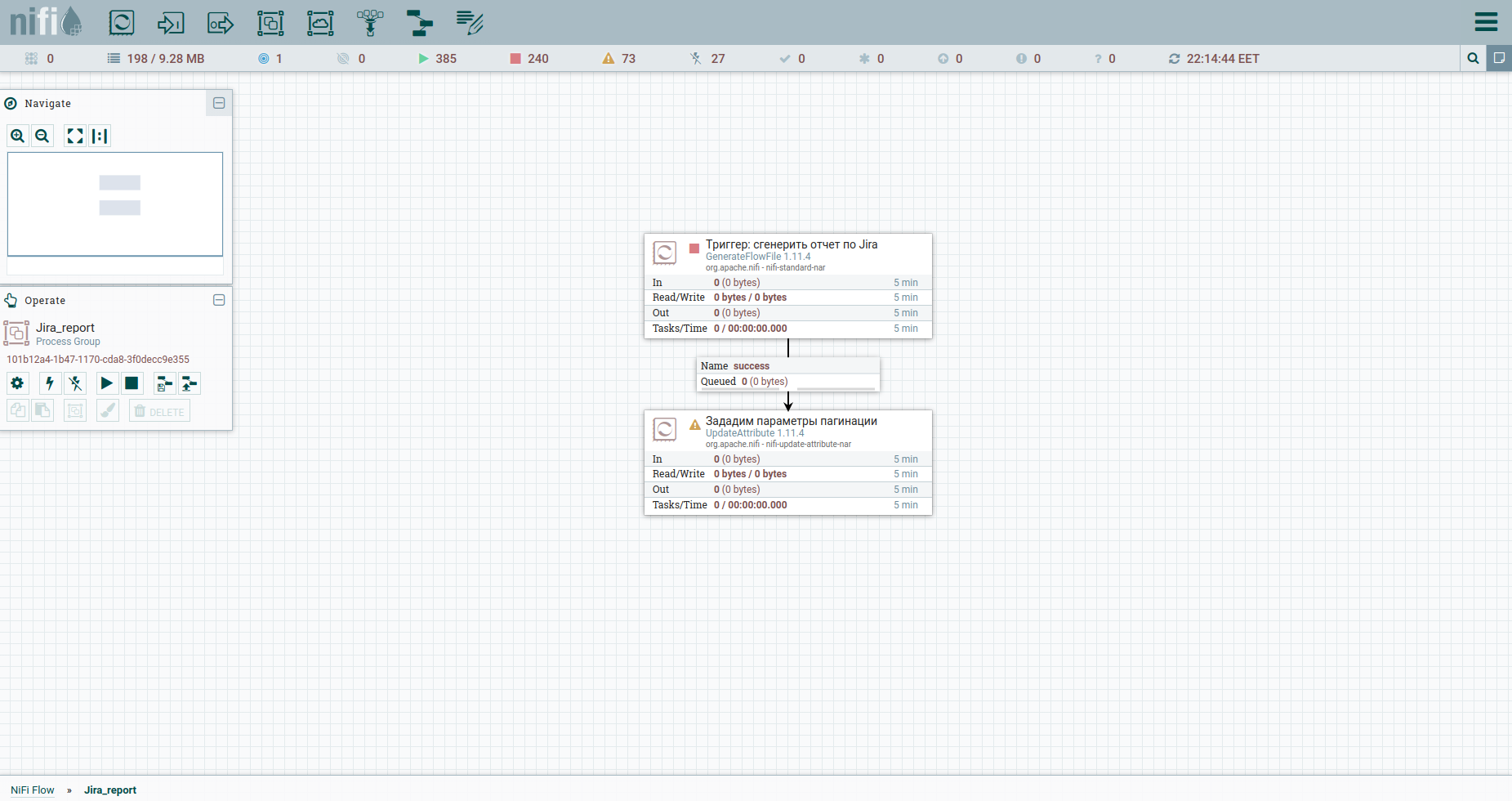
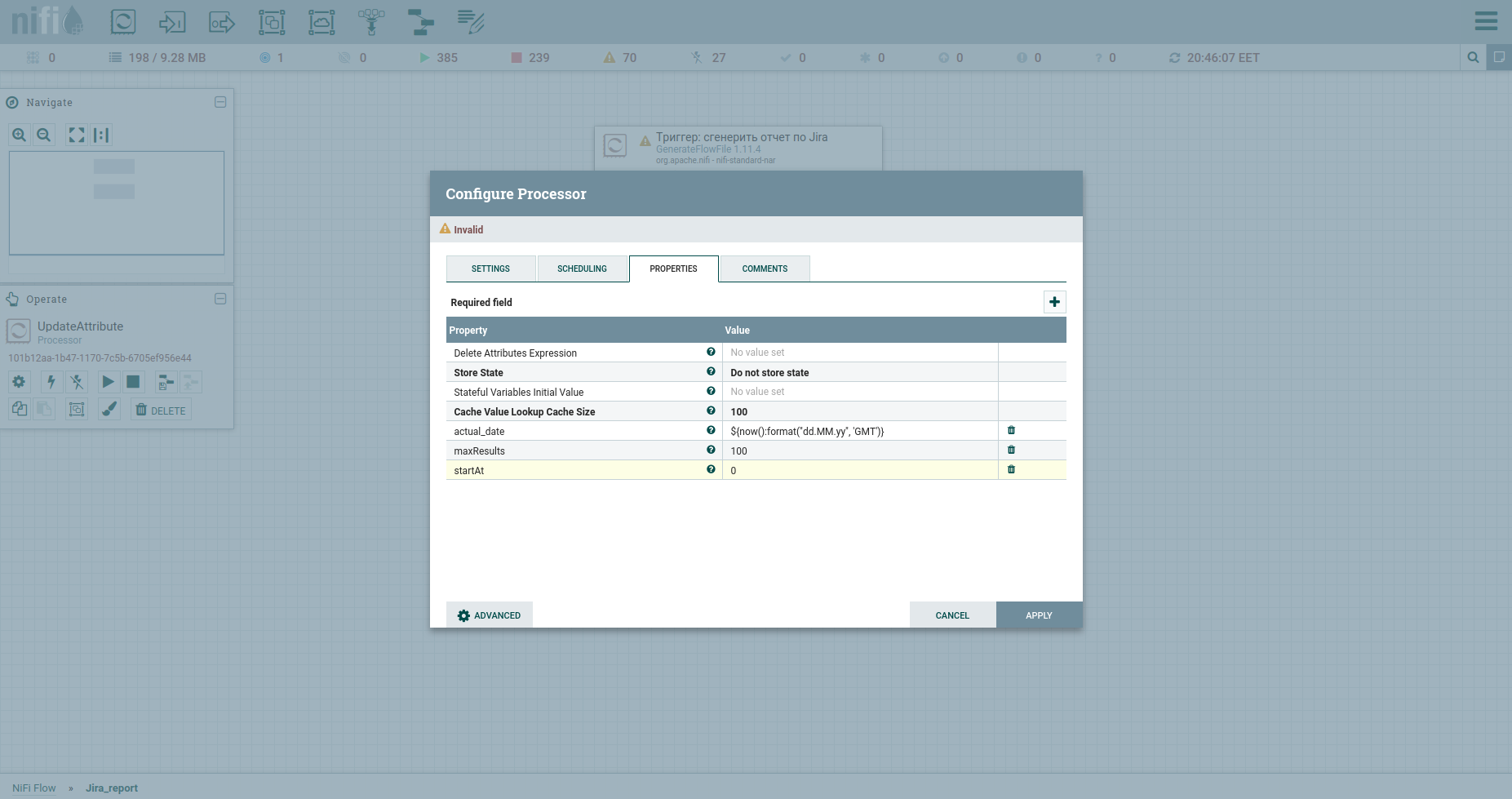
Wir fügen Prozessor hinzu → GenerateFlowFile. In den Einstellungen empfehle ich zunächst dringend, den Prozessornamen festzulegen (dies ist ein guter Ton) - die Registerkarte Einstellungen. Ein weiterer Punkt: Standardmäßig generiert GenerateFlowFile kontinuierlich Stream-Dateien. Es ist unwahrscheinlich, dass Sie dies jemals brauchen werden. Wir erhöhen sofort den Ausführungszeitplan, zum Beispiel auf bis zu 60 Sekunden - die Registerkarte Zeitplanung. Außerdem geben wir auf der Registerkarte Eigenschaften das Startdatum des Berichtszeitraums an - das Attribut report_from mit einem Wert im Format - JJJJ / MM / TT. Gemäß der Jira-API-Dokumentation ist das Entladen begrenzt - nicht mehr als 1000. Um alle Aufgaben zu erhalten, müssen wir daher eine JQL-Anforderung erstellen, in der die Paginierungsparameter startAt und maxResults angegeben sind.

Legen Sie sie mithilfe des UpdateAttribute-Prozessors mit Attributen fest. Gleichzeitig werden wir das Datum der Berichterstellung festlegen. Wir werden es später brauchen. Sie haben wahrscheinlich das Attribut actual_date bemerkt. Sein Wert wird mit der Ausdruckssprache festgelegt. Fangen Sie einen coolen Spickzettel darauf. Das ist alles, wir können JQL zu Fett formen - wir werden die Paginierungsparameter und die erforderlichen Felder angeben. Anschließend wird es der Hauptteil der HTTP-Anfrage sein, daher senden wir es an den Inhalt. Dazu verwenden wir den ReplaceText-Prozessor und geben seinen Ersatzwert wie folgt an:
{"startAt": ${startAt}, "maxResults": ${maxResults}, "jql": "updated >= '2020/11/02'", "fields":["summary", "project", "issuetype", "timespent", "priority", "created", "resolutiondate", "status", "customfield_10100", "aggregatetimespent", "timeoriginalestimate", "description", "assignee", "parent", "components"]}Beachten Sie, wie Attributlinks geschrieben werden.
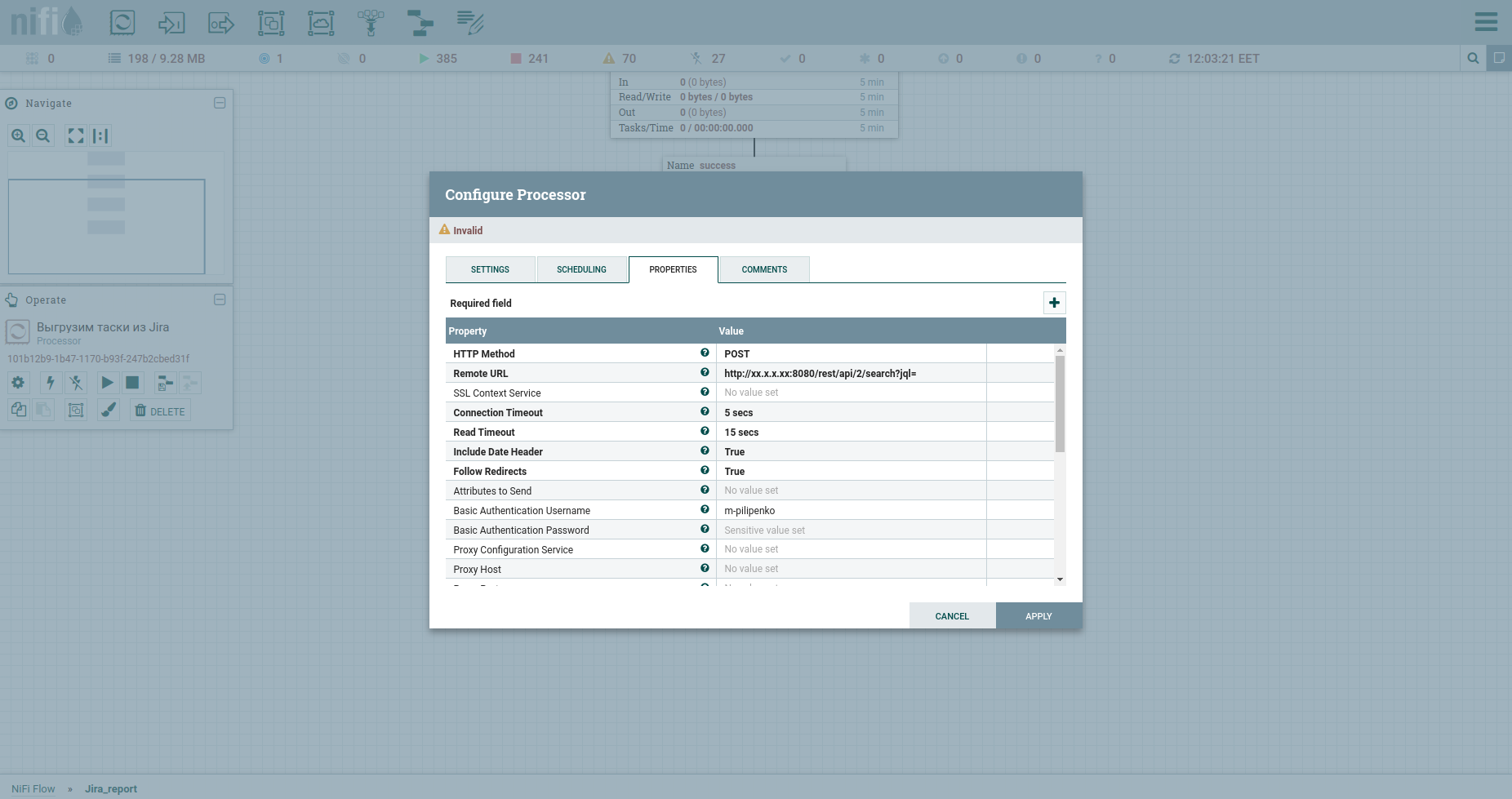
Herzlichen Glückwunsch, wir sind bereit, eine HTTP-Anfrage zu stellen. Der InvokeHTTP-Prozessor passt hierher. Übrigens kann er alles ... Ich meine die Methoden GET, POST, PUT, PATCH, DELETE, HEAD, OPTIONS. Lassen Sie uns seine Eigenschaften wie folgt ändern:
HTTP-Methode Wir haben POST.
Die Remote-URL unseres Fetts enthält IP, Port und / rest / api / 2 / search? Jql =.
Der Benutzername für die Standardauthentifizierung und das Standardauthentifizierungskennwort sind Anmeldeinformationen für Fett.
Ändern Sie den Inhaltstyp in application / json b put true im Send Message Body. Dies bedeutet, dass JSON gesendet wird, das vom vorherigen Prozessor im Request Body stammt.
ANWENDEN.
Die Antwort des Apish ist eine JSON-Datei, die in den Inhalt aufgenommen wird. Wir interessieren uns für zwei Dinge: das Gesamtfeld, das die Gesamtzahl der Aufgaben im System enthält, und das Issues-Array, das bereits einige davon enthält. Lassen Sie uns die Antwort analysieren und uns mit dem EvaluateJsonPath-Prozessor vertraut machen.
Wenn JsonPath auf ein Objekt zeigt, wird das Analyseergebnis in das Attribut der Flussdatei geschrieben. Hier ist ein Beispiel - das Gesamtfeld und der folgende Bildschirm. In dem Fall, in dem JsonPath auf ein Array von Objekten zeigt, wird die Flow-Datei als Ergebnis des Parsens in eine Gruppe mit Inhalten aufgeteilt, die jedem Objekt entsprechen. Hier ist ein Beispiel - das Problemfeld. Wir setzen einen weiteren EvaluateJsonPath und schreiben: Property - issue, Value - $ .issue.

Jetzt besteht unser Stream nicht mehr aus einer Datei, sondern aus vielen. Der Inhalt jedes einzelnen von ihnen enthält JSON mit Informationen zu einer bestimmten Aufgabe.
Mach weiter. Denken Sie daran, wir setzen maxResults auf 100? Nach dem vorherigen Schritt werden wir einhundert erste Tasoks haben. Lassen Sie uns mehr bekommen und Paginierung implementieren.
Erhöhen Sie dazu die Anzahl der Startaufgaben um maxResults. Verwenden wir UpdateAttribute erneut: Wir geben das startAt-Attribut an und weisen ihm einen neuen Wert zu. $ {StartAt: plus ($ {maxResults})}.
Wir können nicht auf eine Überprüfung verzichten, um die maximale Anzahl von Aufgaben zu erreichen - den RouteOnAttribute-Prozessor. Die Einstellungen sind wie folgt: Und Schleife. Insgesamt wird der Zyklus ausgeführt, solange die Anzahl der Startaufgaben geringer ist als die Gesamtzahl der Aufgaben. Am Ausgang davon - ein Strom von Tasoks. So sieht der Prozess jetzt aus:

Ja, Freunde, ich weiß - Sie haben es satt, meine Kommentare zu jedem Quadrat zu lesen. Sie wollen das Prinzip selbst verstehen. Ich habe nichts dagegen.
Dieser Abschnitt soll es einem absoluten Anfänger erleichtern, NiFi zu betreten. Wenn ich dann eine großzügig präsentierte Vorlage in der Hand habe, wird es nicht schwierig sein, sich mit den Details zu befassen.
Galopp durch Europa. Hochladen eines Arbeitsprotokolls usw.
Nun, lass uns beschleunigen. Finden Sie die Unterschiede: Zur leichteren Wahrnehmung habe ich den Prozess des Entladens des Arbeitsprotokolls und des Änderungsverlaufs in eine separate Gruppe verschoben. Hier ist es: Um die Einschränkungen beim automatischen Entladen eines Arbeitsprotokolls von Jira zu umgehen, ist es ratsam, auf jede Aufgabe separat zu verweisen. Deshalb brauchen wir ihre Schlüssel. Die erste Spalte konvertiert nur den Strom von Tasoks in einen Strom von Schlüsseln. Als nächstes wenden wir uns dem Affen zu und speichern die Antwort. Es ist für uns bequem, das Arbeitsprotokoll und das Änderungsprotokoll für alle Aufgaben in Form separater Dokumente anzuordnen. Daher werden wir den MergeContent-Prozessor verwenden und den Inhalt aller Flow-Dateien damit verkleben.
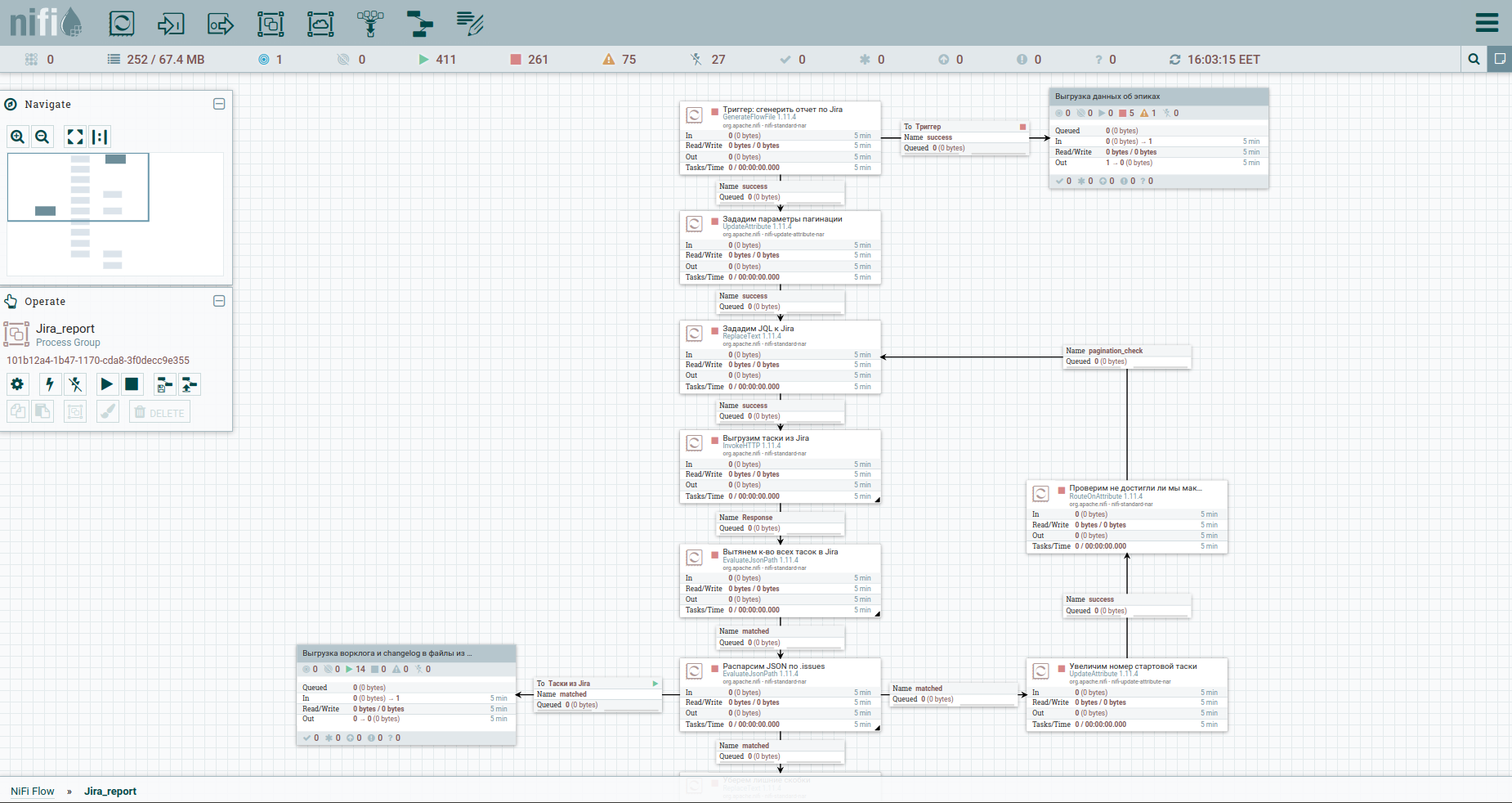
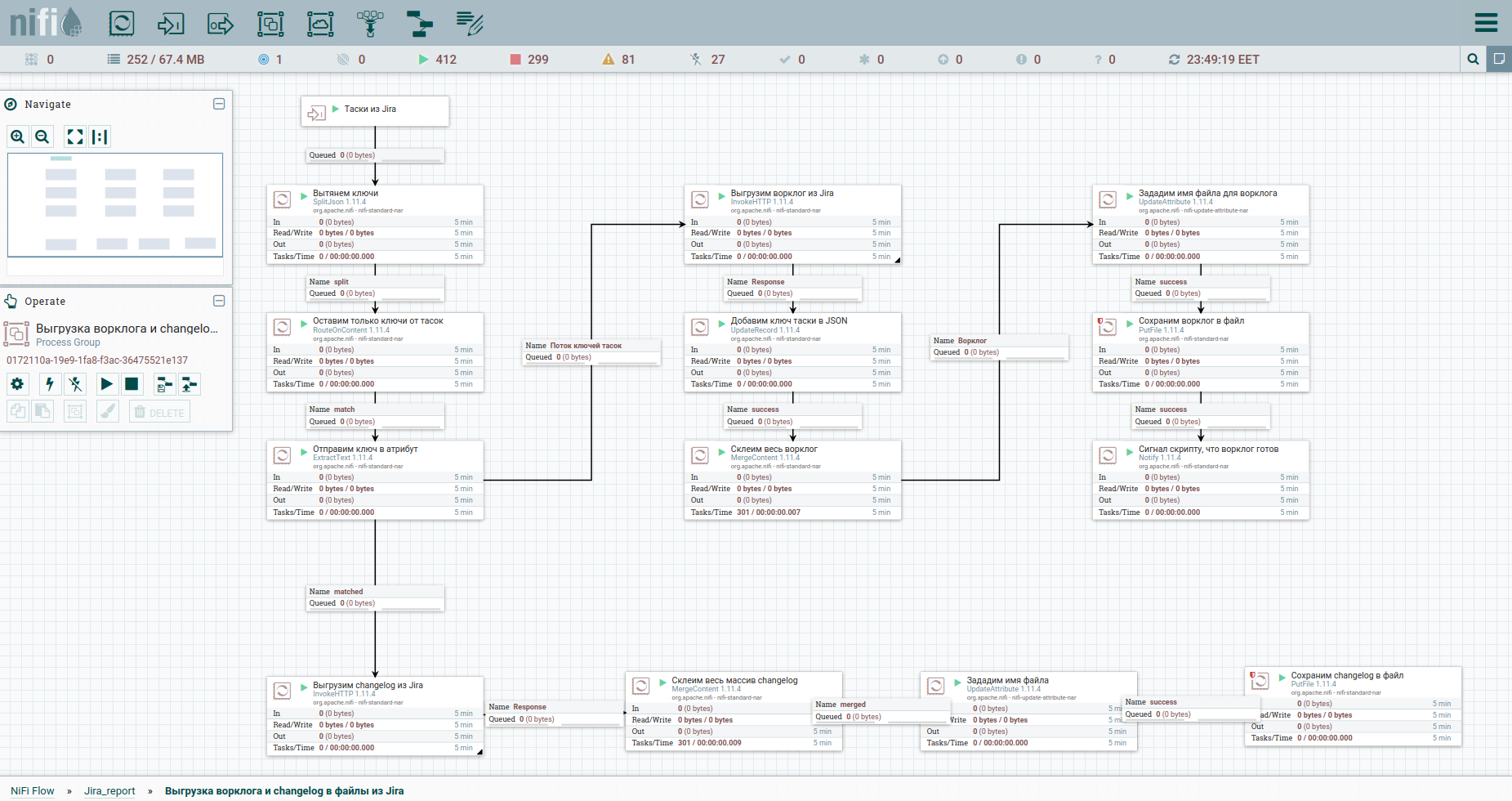
Außerdem sehen Sie in der Vorlage eine Gruppe zum Entladen von Daten nach Epen. Ein Epos in Jira ist eine häufige Aufgabe, an die sich viele andere binden. Diese Gruppe ist nützlich, wenn nur ein Teil der Aufgaben abgebaut wird, um keine Informationen über die Epen einiger von ihnen zu verlieren.
Die letzte Etappe. Berichterstellung und Versand per E-Mail
In Ordnung. Alle Punkte wurden entladen und gingen auf zwei Arten: an die Gruppe zum Entladen des Arbeitsprotokolls und an das Skript zum Generieren des Berichts. Bei letzterem haben wir einen STDIN, also müssen wir alle Aufgaben auf einem Stapel sammeln. Wir werden dies in MergeContent tun, aber vorher werden wir den Inhalt leicht korrigieren, so dass der endgültige JSON korrekt ist. Vor dem Skriptgenerierungsquadrat (ExecuteStreamCommand) befindet sich ein interessanter Wait-Prozessor. Er wartet auf ein Signal des Benachrichtigungsprozessors, der sich in der Entladegruppe des Arbeitsprotokolls befindet, dass dort alles bereit ist und Sie fortfahren können. Als nächstes führen wir das Skript von bash-a - ExecuteStreamCommand aus. Und wir senden den Bericht mit PutEmail an das gesamte Team.

Ich werde Ihnen in einem separaten Artikel, der neulich fertig sein wird, ausführlich über das Skript sowie über die Erfahrungen bei der Implementierung von Jira Software Analytics in unserem Unternehmen berichten.
Kurz gesagt, die von uns entwickelte Berichterstattung bietet einen strategischen Überblick darüber, was eine Einheit oder ein Team tut. Und das ist für jeden Chef von unschätzbarem Wert, dem müssen Sie zustimmen.
Nachwort
Warum erschöpfen Sie sich, wenn Sie dies alles mit einem Skript auf einmal tun können? Ja, ich stimme zu, aber teilweise.
Apache NiFi vereinfacht nicht den Entwicklungsprozess, sondern den Betrieb. Wir können jeden Thread jederzeit stoppen, bearbeiten und von vorne beginnen.
Darüber hinaus gibt uns NiFi einen Überblick über die Prozesse, nach denen das Unternehmen lebt. In der nächsten Gruppe werde ich ein anderes Skript haben. Ein anderer wird der Prozess meines Kollegen sein. Verstehst du, richtig? Architektur in der Handfläche. Wie unser Chef scherzt, implementieren wir Apache NiFi, damit wir Sie alle später feuern können, und ich war der einzige, der die Knöpfe drückte. Aber das ist ein Witz.
Nun, in diesem Beispiel sind die Brötchen in Form einer Zeitplanaufgabe zum Generieren von Berichten und Versenden von Briefen ebenfalls sehr, sehr angenehm.
Ich gestehe, ich hatte vor, meine Seele auszuschütten und Ihnen von dem Rechen zu erzählen, auf den ich während des Studiums der Technologie getreten bin - wie viele von ihnen. Aber hier ist es schon lang gelesen. Wenn das Thema interessant ist, lassen Sie es mich bitte wissen. In der Zwischenzeit, Freunde, danke und warte in den Kommentaren auf dich.
Nützliche Links
Ein genialer Artikel , der Apache NiFi direkt an Ihren Fingern und in Buchstaben behandelt.
Eine kurze Anleitung in russischer Sprache.
Ein cooler Spickzettel für die Ausdruckssprache.
Die englischsprachige Apache NiFi- Community ist offen für Fragen.
Die russischsprachige Apache NiFi- Community auf Telegram ist lebendiger als alle Lebewesen.