Dieser Artikel erschien aus mehreren Gründen.
Erstens werden in der überwiegenden Mehrheit der Bücher, Internetquellen und Lektionen zu Data Science die Nuancen, Mängel verschiedener Arten der Datennormalisierung und ihre Gründe entweder überhaupt nicht berücksichtigt oder nur beiläufig und ohne Offenlegung des Wesens erwähnt.
Zweitens gibt es beispielsweise eine "blinde" Verwendung der Standardisierung für Sets mit einer großen Anzahl von Funktionen - "damit sie für alle gleich ist". Besonders für Anfänger (er selbst war der gleiche). Auf den ersten Blick ist es okay. Bei näherer Betrachtung kann sich jedoch herausstellen, dass einige Zeichen unbewusst in eine privilegierte Position gebracht wurden und das Ergebnis viel stärker beeinflussten, als sie sollten.
Und drittens wollte ich immer eine universelle Methode, die Problembereiche berücksichtigt.
Wiederholung ist die Mutter des Lernens
Normalisierung ist die Konvertierung von Daten in bestimmte dimensionslose Einheiten. Manchmal - innerhalb eines bestimmten Bereichs, zum Beispiel [0..1] oder [-1..1]. Manchmal - mit einer bestimmten Eigenschaft, wie zum Beispiel einer Standardabweichung von 1.
Das Hauptziel der Normalisierung besteht darin, verschiedene Daten in einer Vielzahl von Einheiten und Wertebereichen in einer einzigen Form zusammenzufassen, damit Sie sie miteinander vergleichen oder zur Berechnung der Ähnlichkeit von Objekten verwenden können. In der Praxis ist dies beispielsweise für das Clustering und bei einigen Algorithmen für maschinelles Lernen erforderlich.
Analytisch wird jede Normalisierung auf die Formel reduziert
Wo - gegenwärtiger Wert,
- der Wert der Versatzwerte,
- der Wert des Intervalls, das in "Eins" umgewandelt werden soll
Tatsächlich läuft alles darauf hinaus, dass der ursprüngliche Wertesatz zuerst verschoben und dann skaliert wird.
Beispiele:
Minimax (MinMax) . Ziel ist es, den Originalsatz in den Bereich [0..1] umzuwandeln. Für ihn:
= , .
= — , .. “” .
. — 0 1.
= , .
— .
, .
, , “” . .
, - . , . , , . , . , — . , , , , *
* — , , ( ), , .
, — .
1 —
— .. , , 0 “” .
? « » . .
№ 1 — , .
, “ ” , , — , . ( ). ( ) .
, , .
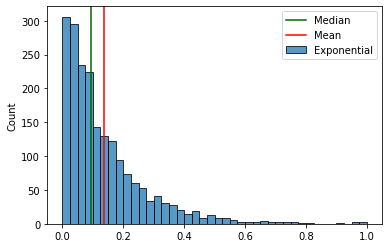
:
. “” .
, , , . .
2 —
. .
. , , [-1..1], . [-1..1], — [-1..100], , . .
. . , “”.
( ):

( ) , .
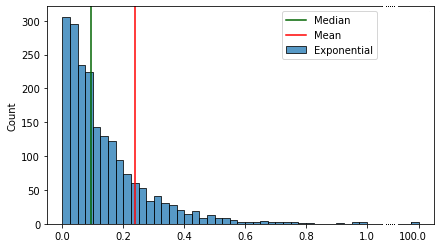
, () “”, .

— ( ). , “” .
75- 25- — . .. , “” 50% . “” / .
— “”, “” .
№ 2 — “” .
— .
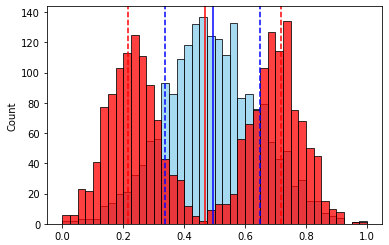
( ).

- “” . , , “”.
. .. . — 1.
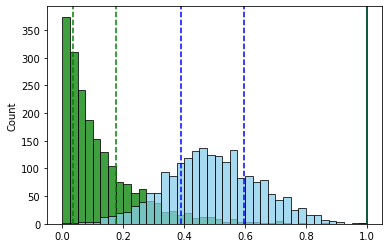
, , , № 3 — . ( ) .
, , . 2-
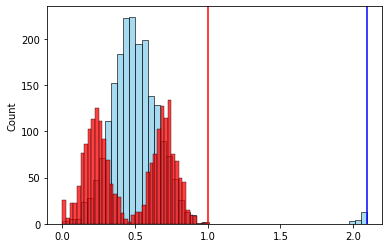
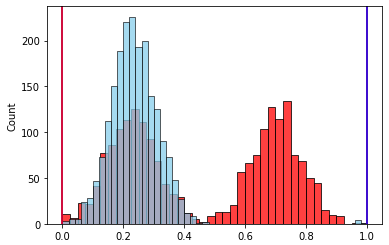
, , . .
, “-”. — .
— , . , . , , , , ? .
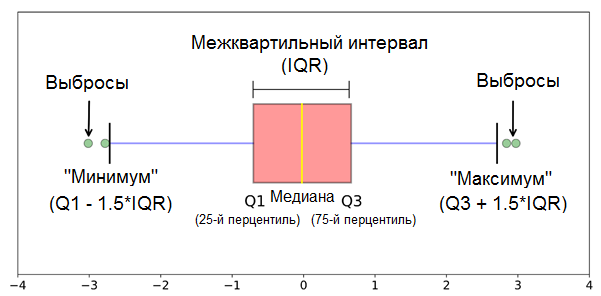
, . , “” , 1,5 (IQR) .*
* — ( .) 1,5 3 — .
.
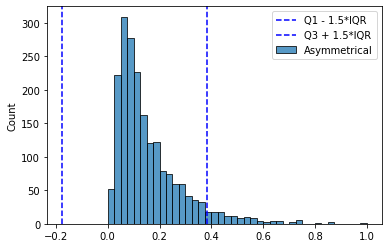
— - , .
. (, , ) “” — 7%. (3 * IQR) — . . .. .
, . “ ” (1,5 * IQR) , . , - “” .
(Mia Hubert and Ellen Vandervieren) 2007 . “An Adjusted Boxplot for Skewed Distributions”.
“ ” , 1,5 * IQR.
“ ” medcouple (MC), :
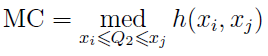
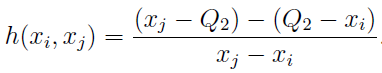
“ ” , , , 1,5 * IQR — 0,7%
:
:

:
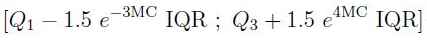
. .
, , :
- , , .
- .
- () — , , [0..1]
… — Mia Hubert Ellen Vandervieren
. .
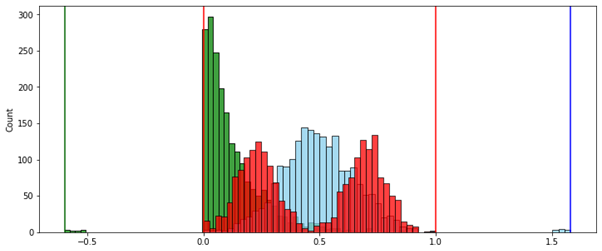
, ( ) (MinMax — ).
№ 1 — . . , “” .
:
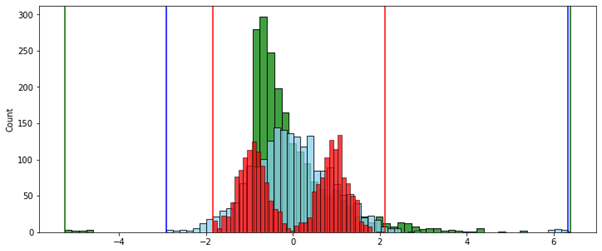
( ):

:

, — , , .
№ 2 — . [0..1]. , , .
MinMax ( ):
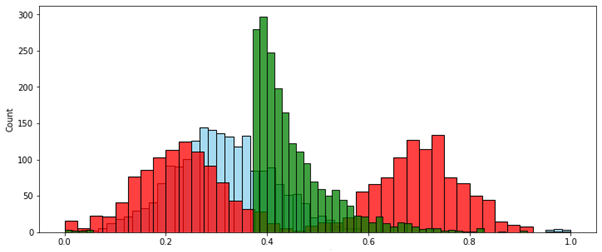
:
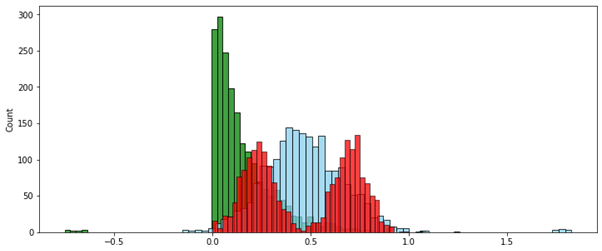
. -, , — .. 0 1.
, “” [0..1], , — , , , . .
* * *
Um diese Methode mit Ihren Händen zu spüren, können Sie von hier aus meine Demo-Klasse AdjustedScaler ausprobieren .
Es ist nicht für die Arbeit mit einer sehr großen Datenmenge optimiert und funktioniert nur mit Pandas DataFrame, aber für Versuche, Experimente oder sogar ein Leerzeichen für etwas Ernsthafteres ist es durchaus geeignet. Versuch es.