
Anfang dieses Jahres hielt Tenzor ein Treffen in der Stadt Ivanovo ab, bei dem ich einen Vortrag über Experimente mit Fuzzing-Tests der Schnittstelle hielt. Hier ist eine Abschrift dieses Berichts.
Wann werden Affen die gesamte Qualitätssicherung ersetzen? Ist es möglich, manuelle Tests und UI-Autotests abzubrechen und durch Fuzzing zu ersetzen? Wie würde ein vollständiges Zustands- und Übergangsdiagramm für eine einfache TODO-Anwendung aussehen? Ein Beispiel für die Implementierung und wie ein solches Fuzzing unter dem Schnitt weiter funktioniert.
Hallo! Ich heiße Sergey Dokuchaev. In den letzten 7 Jahren habe ich bei Tenzor Tests in all ihren Formen durchgeführt.

Wir haben über 400 Mitarbeiter, die für die Qualität unserer Produkte verantwortlich sind. 60 davon sind für Automatisierungs-, Sicherheits- und Leistungstests bestimmt. Um Zehntausende von E2E-Tests zu unterstützen, Leistungsindikatoren von Hunderten von Seiten zu überwachen und Schwachstellen im industriellen Maßstab zu identifizieren, müssen Sie Tools und Methoden verwenden, die im Laufe der Zeit getestet und im Kampf getestet wurden.

Und in der Regel sprechen sie auf Konferenzen über solche Fälle. Abgesehen davon gibt es viele interessante Dinge, die im industriellen Maßstab immer noch schwer anzuwenden sind. Das ist interessant und lass uns darüber reden.

In dem Film "The Matrix" in einer der Szenen bietet Morpheus Neo an, eine rote oder blaue Pille zu wählen. Thomas Anderson arbeitete als Programmierer und wir erinnern uns, welche Wahl er getroffen hat. Wenn er ein berüchtigter Tester wäre, hätte er beide Tabletten verschlungen, um zu sehen, wie sich das System unter nicht standardmäßigen Bedingungen verhalten würde.
Die Kombination von manuellen Tests und Autotests ist fast Standard geworden. Entwickler wissen am besten, wie ihr Code funktioniert, und schreiben Komponententests, Funktionstester überprüfen neue oder häufig wechselnde Funktionen, und die gesamte Regression geht an verschiedene Autotests.
Beim Erstellen und Verwalten von Autotests gibt es jedoch plötzlich nicht mehr viel Auto- und ziemlich viel manuelle Arbeit:
- Sie müssen herausfinden, was und wie zu testen ist.
- Sie müssen die Elemente auf der Seite finden und die erforderlichen Locators in Seitenobjekte einfügen.
- Schreiben und debuggen Sie den Code.
- — . / , , ROI .
Glücklicherweise gibt es in der Testwelt nicht zwei oder drei Tablets. Und eine ganze Streuung: semantische Tests, formale Methoden, Fuzzing-Tests, AI-basierte Lösungen. Und noch mehr Kombinationen.

Die Behauptung, dass jeder Affe, der unendlich lange auf einer Schreibmaschine tippt, in der Lage sein wird, einen bestimmten Text im Voraus zu tippen, ist im Test stecken geblieben. Hört sich gut an, wir können ein Programm dazu bringen, an zufälligen Stellen endlos auf den Bildschirm zu klicken, und schließlich können wir alle Fehler finden.
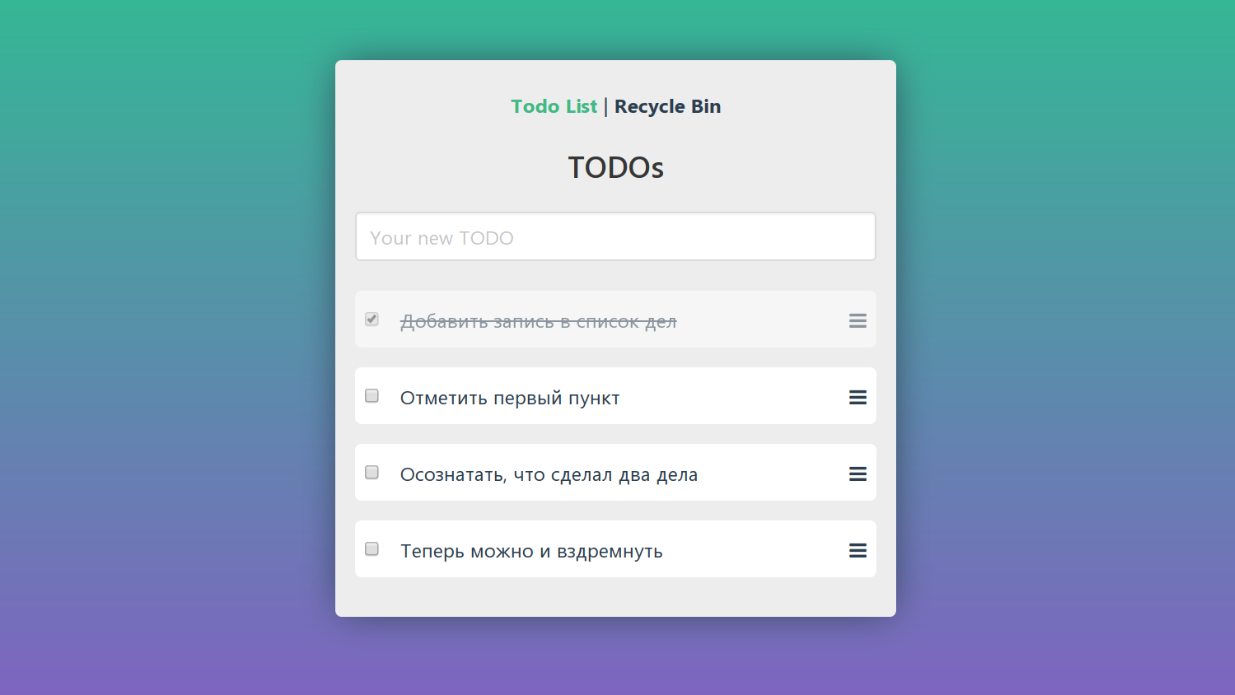
Nehmen wir an, wir haben ein solches TODO erstellt und möchten es überprüfen. Wir nehmen einen geeigneten Dienst oder ein geeignetes Werkzeug und sehen die Affen in Aktion:
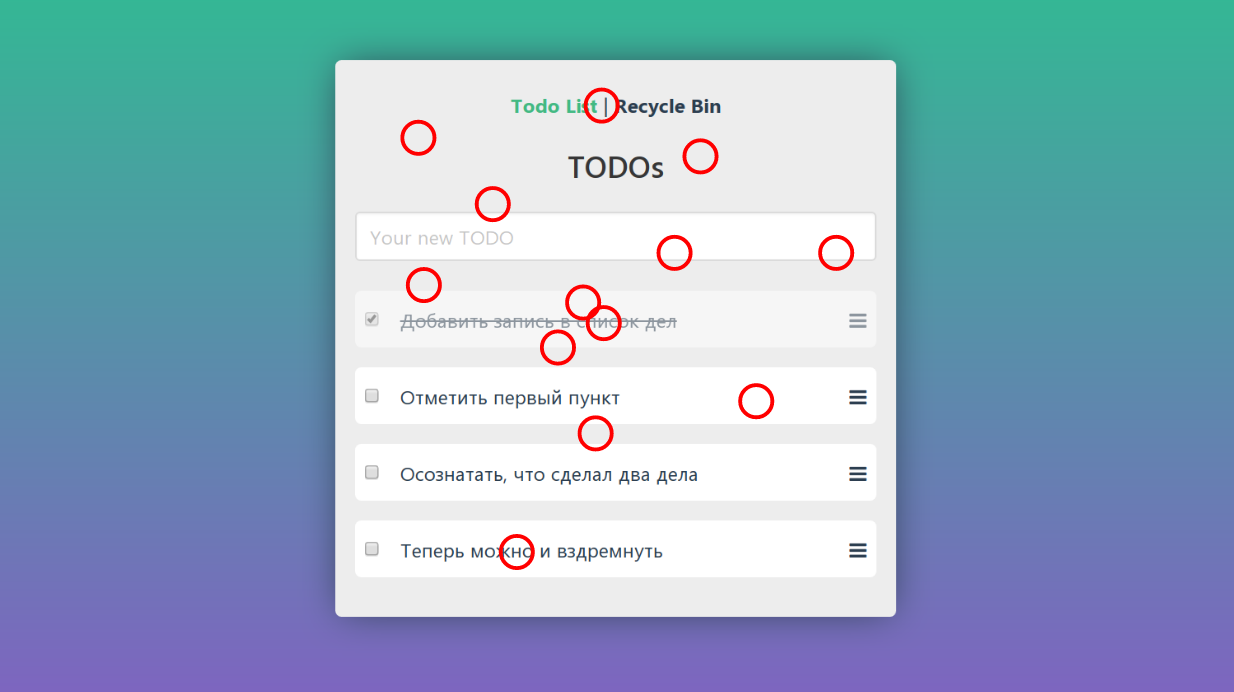
Nach dem gleichen Prinzip hat meine Katze, die irgendwie auf der Tastatur lag, die Präsentation unwiederbringlich unterbrochen und musste es erneut tun:

Es ist praktisch, wenn die Anwendung nach 10 Aktionen eine Ausnahme auslöst. Hier versteht unser Affe sofort, dass ein Fehler aufgetreten ist, und wir können anhand der Protokolle zumindest ungefähr verstehen, wie er sich wiederholt. Was ist, wenn der Fehler nach 100.000 zufälligen Klicks aufgetreten ist und wie eine gültige Antwort aussieht? Der einzige wesentliche Vorteil dieses Ansatzes ist die maximale Einfachheit - Sie drücken einen Knopf und sind fertig.

Das Gegenteil dieses Ansatzes sind formale Methoden.

Dies ist ein Foto von New York im Jahr 2003. Einer der hellsten und überfülltesten Orte der Welt, der Times Square, wird nur von den Scheinwerfern vorbeifahrender Autos beleuchtet. In diesem Jahr waren Millionen von Menschen in Kanada und den Vereinigten Staaten drei Tage lang in der Steinzeit gefangen, weil ein Kraftwerk stillgelegt wurde. Einer der Hauptgründe für den Vorfall war ein Fehler in der Rennbedingung in der Software.
Fehlerkritische Systeme erfordern einen speziellen Ansatz. Methoden, die nicht auf Intuition und Fähigkeiten beruhen, sondern auf Mathematik, werden als formal bezeichnet. Und im Gegensatz zum Testen können Sie damit nachweisen, dass der Code keine Fehler enthält. Modelle sind viel schwieriger zu erstellen als den Code zu schreiben, den sie testen sollen. Und ihre Verwendung ist eher so, als würde man einen Satz in einer Vorlesung über Analysis beweisen.

Die Folie zeigt einen Teil des Modells des Zwei-Handshake-Algorithmus , der in der Sprache TLA + geschrieben ist. Ich denke, es ist für jeden offensichtlich, dass die Verwendung dieser Werkzeuge bei der Überprüfung von Formen auf der Baustelle mit dem Bau einer Boeing 787 zum Testen der aerodynamischen Eigenschaften einer Maispflanze vergleichbar ist.

Selbst in der traditionell fehleranfälligen Medizin-, Luft- und Raumfahrt- und Bankenbranche wird diese Testmethode nur sehr selten angewendet. Der Ansatz selbst ist jedoch unersetzlich, wenn die Kosten eines Fehlers in Millionen Dollar oder in Menschenleben berechnet werden.
Fuzzing-Tests werden heute am häufigsten im Zusammenhang mit Sicherheitstests betrachtet. Ein typisches Schema, das diesen Ansatz demonstriert, entnehmen wir dem OWASP-Leitfaden :

Hier haben wir eine Site, die getestet werden muss, es gibt eine Datenbank mit Testdaten und Tools, mit denen wir die angegebenen Daten an die Site senden. Vektoren sind gewöhnliche Strings, die empirisch erhalten wurden. Solche Zeichenfolgen führen höchstwahrscheinlich zur Entdeckung einer Sicherheitsanfälligkeit. Es ist wie das Anführungszeichen, das viele Leute automatisch anstelle der Zahlen in der URL aus der Adressleiste einfügen.
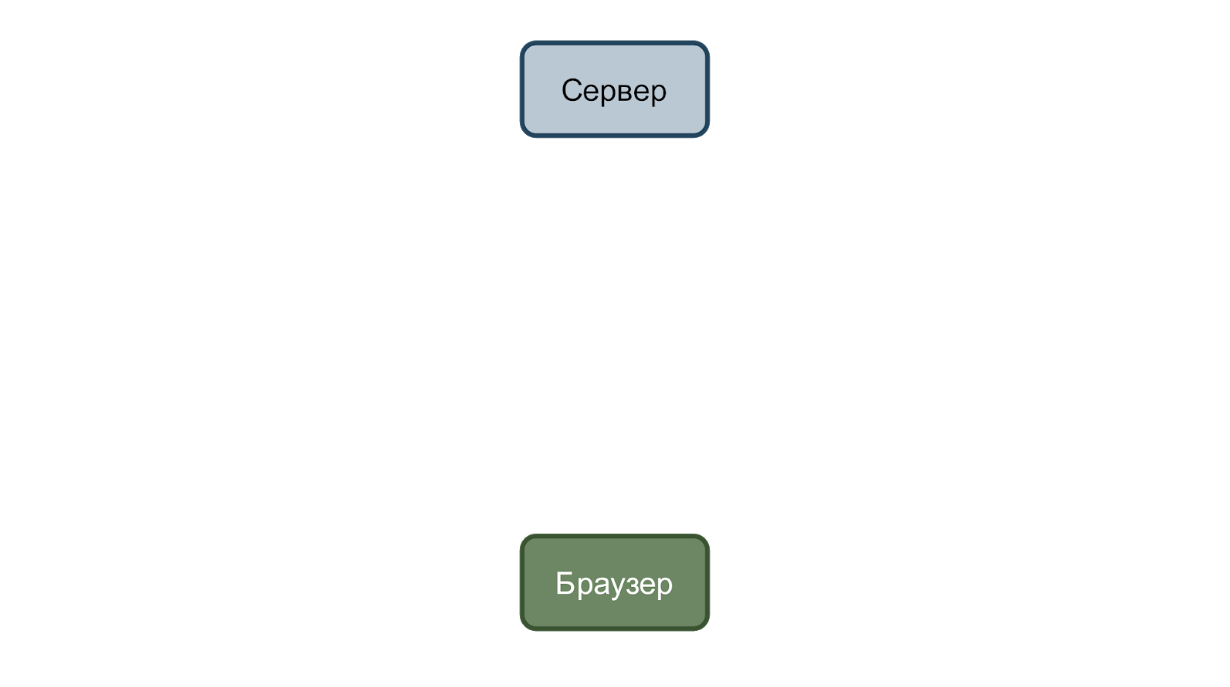
Im einfachsten Fall haben wir einen Dienst, der Anfragen akzeptiert, und einen Browser, der sie sendet. Stellen Sie sich einen Fall vor, in dem das Geburtsdatum des Benutzers geändert wird.

Der Benutzer gibt ein neues Datum ein und klickt auf die Schaltfläche „Speichern“. Eine Anfrage wird mit Daten im JSON-Format an den Server gesendet.
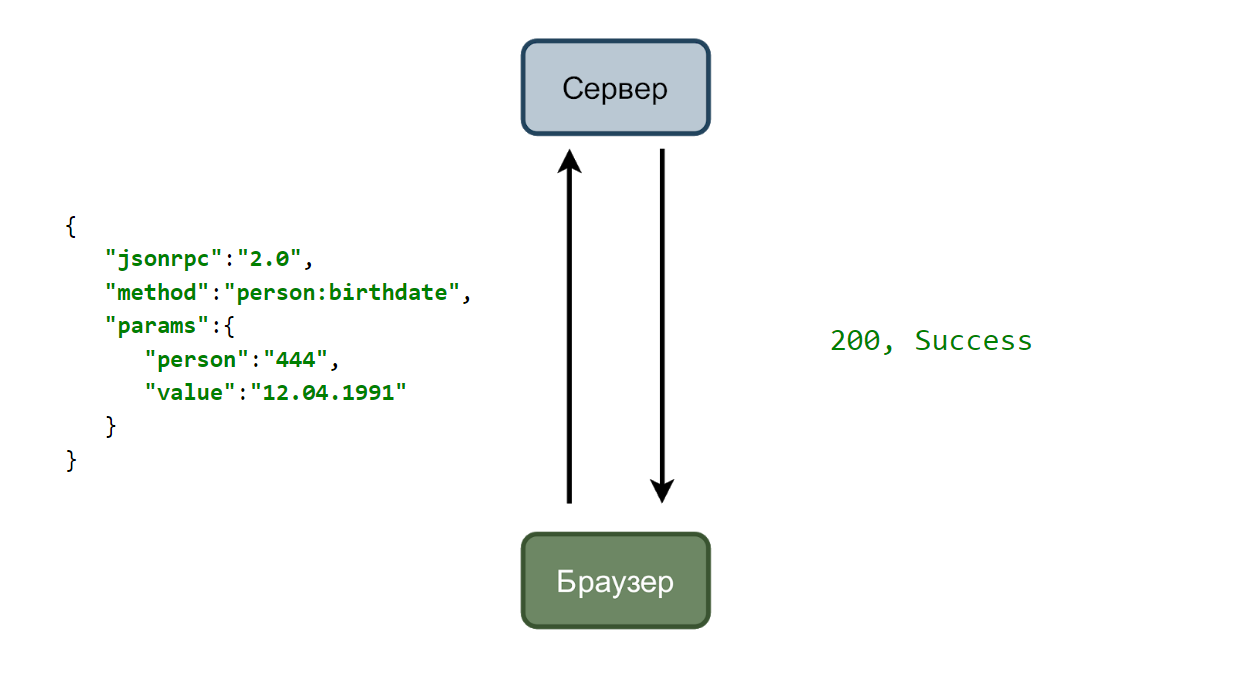
Und wenn alles in Ordnung ist, antwortet der Dienst mit zweihundertstel Code.

Es ist praktisch, programmgesteuert mit json zu arbeiten, und wir können unserem Fuzzing-Tool beibringen, Daten in den übertragenen Daten zu finden und zu bestimmen. Und er wird anfangen, sie durch verschiedene Werte zu ersetzen, zum Beispiel wird es einen nicht existierenden Monat übertragen.

Und wenn wir als Antwort anstelle einer Nachricht über ein ungültiges Datum eine Ausnahme erhalten haben, beheben wir den Fehler.
Das Fuzzing einer API ist nicht schwierig. Hier haben wir die übertragenen Parameter in json, hier senden wir eine Anfrage, empfangen eine Antwort und analysieren sie. Was ist mit der GUI?
Schauen wir uns noch einmal das Programm aus dem Demo-Testbeispiel an. Darin können Sie neue Aufgaben hinzufügen, als erledigt markieren, löschen und den Warenkorb anzeigen.
Wenn wir uns mit Zerlegung befassen, werden wir sehen, dass die Schnittstelle kein einzelner Monolith ist, sondern auch aus separaten Elementen besteht:
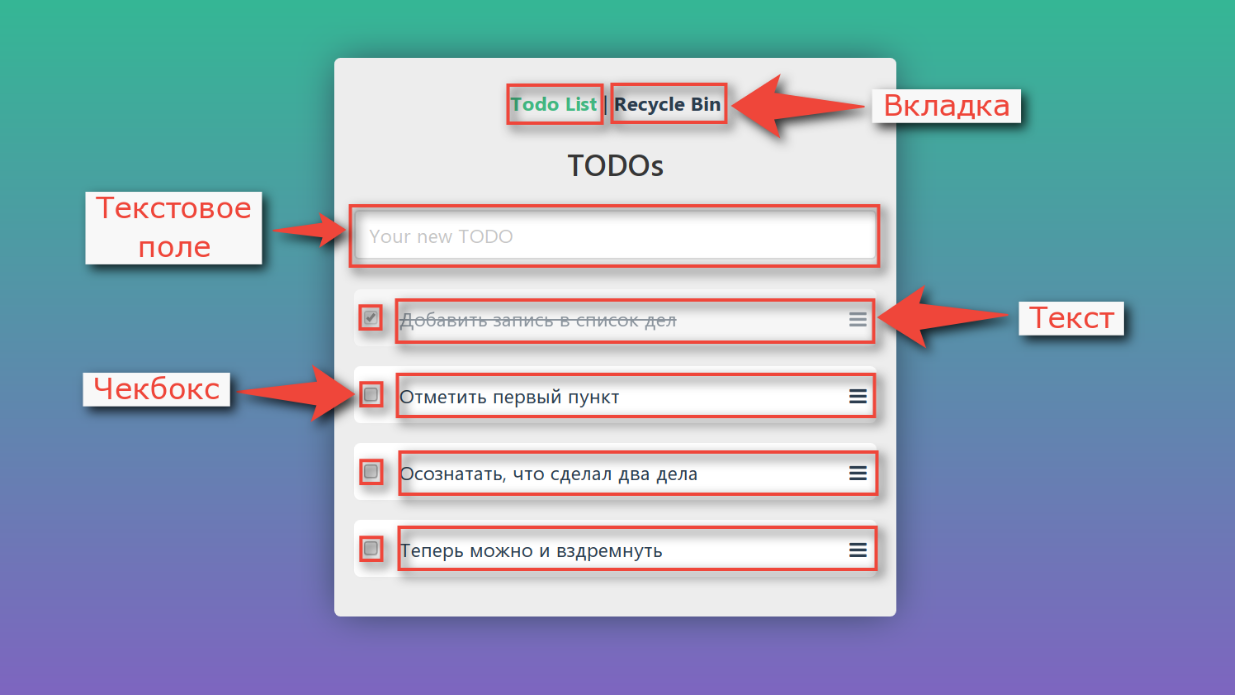
Mit jedem Steuerelement können wir nicht viel anfangen. Wir haben eine Maus mit zwei Tasten, einem Rad und einer Tastatur. Sie können auf ein Element klicken, den Mauszeiger darüber bewegen und Text in Textfelder eingeben.
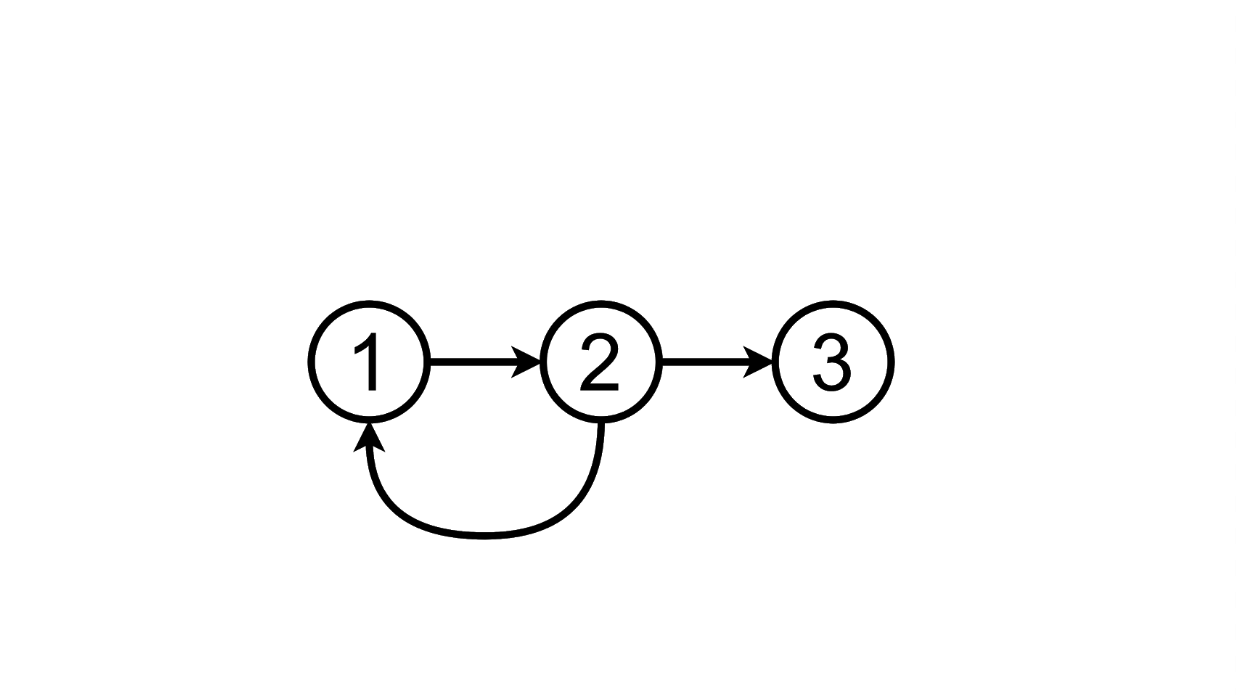
Wenn wir Text in das Textfeld eingeben und die Eingabetaste drücken, wechselt unsere Seite von einem Status in einen anderen:
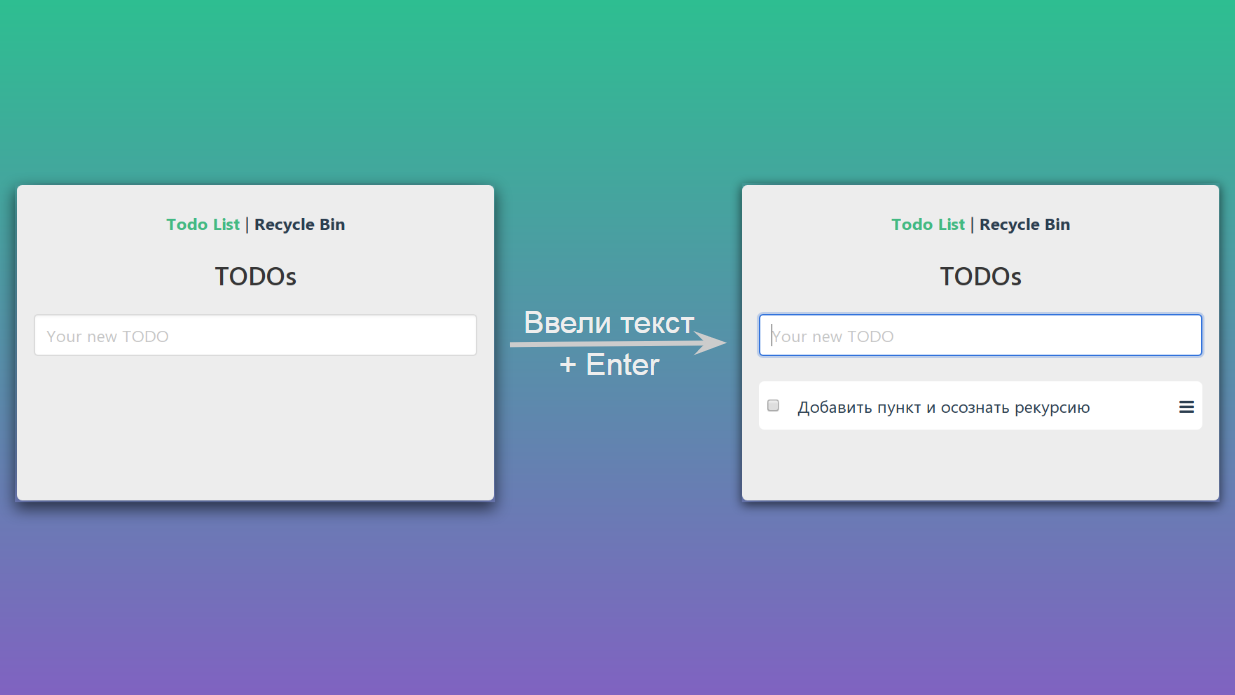
Schematisch kann dies folgendermaßen dargestellt werden:

Von diesem Status aus können wir zum dritten wechseln, indem
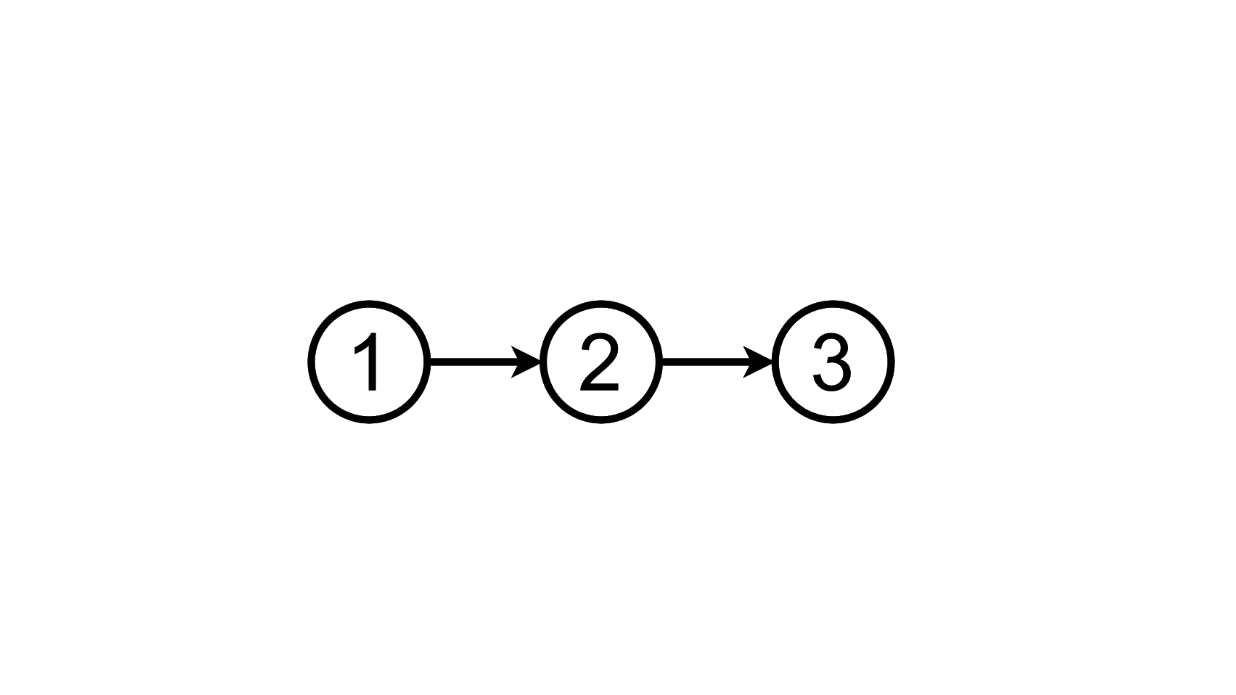
wir der Liste eine weitere Aufgabe hinzufügen: Und wir können die hinzugefügte löschen Aufgabe, Rückkehr zum ersten Zustand:
Oder klicken Sie auf das TODO-Label und bleiben Sie im zweiten Zustand:
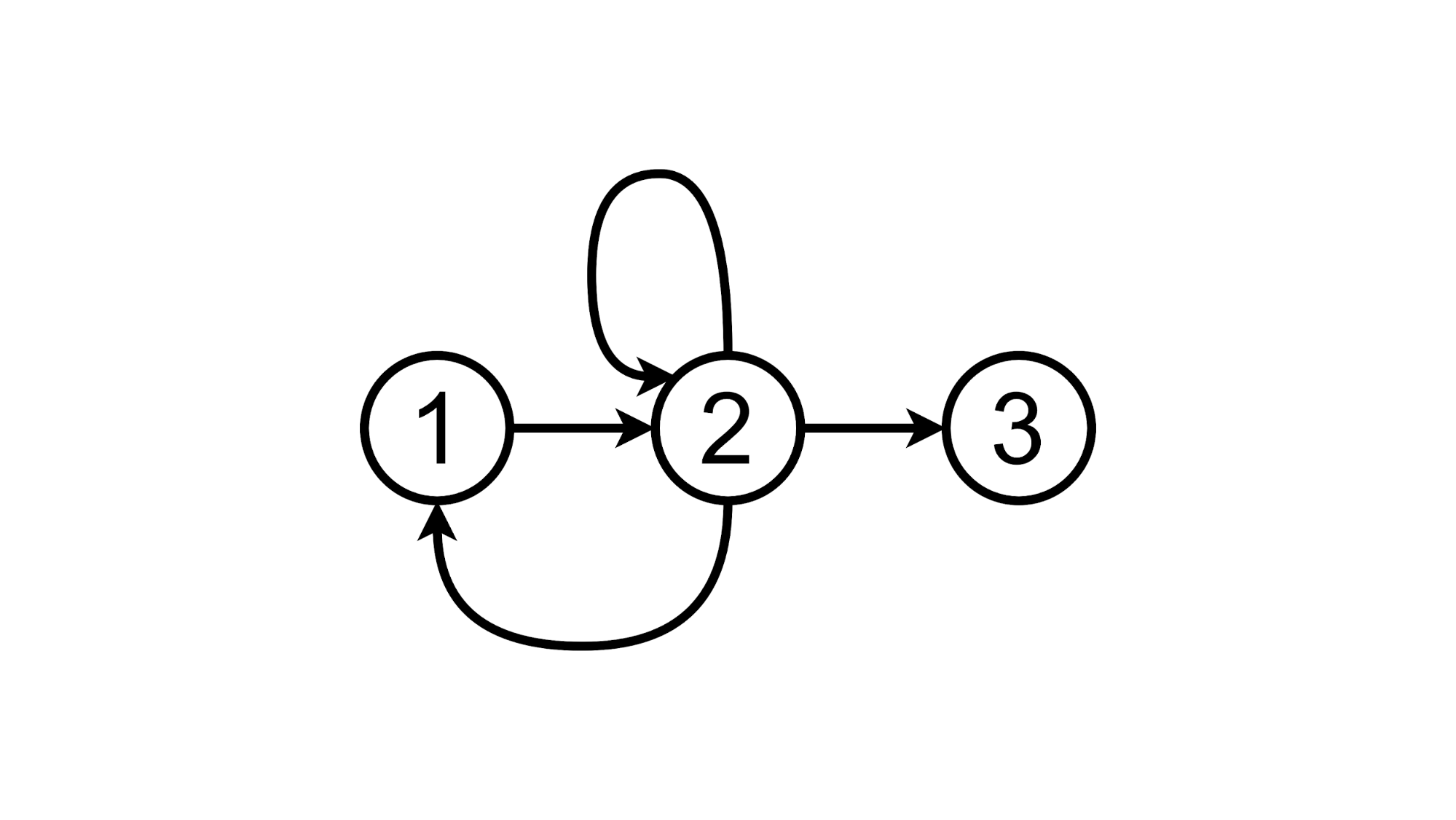
Und jetzt versuchen wir, den Proof-of-Concept dieses Ansatzes zu implementieren.

Um mit dem Browser zu arbeiten, nehmen wir einen Chromedriver, arbeiten mit dem Zustandsdiagramm und den Übergängen durch die NetworkX-Python-Bibliothek und zeichnen durch yEd.

Wir starten den Browser, erstellen eine Diagramminstanz, in der es viele Verbindungen mit unterschiedlichen Richtungen zwischen zwei Scheitelpunkten geben kann. Und wir öffnen unsere Anwendung.

Nun müssen wir den Status der Anwendung beschreiben. Aufgrund des Bildkomprimierungsalgorithmus können wir die Größe des PNG-Bilds als Statuskennung verwenden und mithilfe der Methode __eq__ einen Vergleich dieses Status mit anderen implementieren. Über das iterierte Attribut zeichnen wir auf, dass auf alle Schaltflächen geklickt und Werte in alle Felder in diesem Zustand eingegeben wurden, um eine erneute Verarbeitung auszuschließen.

Wir schreiben einen grundlegenden Algorithmus, der die gesamte Anwendung umgeht. Hier korrigieren wir den ersten Zustand im Diagramm, in der Schleife klicken wir auf alle Elemente in diesem Zustand und korrigieren die resultierenden Zustände. Wählen Sie als nächstes den nächsten unverarbeiteten Zustand aus und wiederholen Sie die Schritte.

Wenn wir den aktuellen Zustand verwischen, müssen wir jedes Mal von einem neuen in diesen Zustand zurückkehren. Dazu verwenden wir die Funktion nx.shortest_path, die eine Liste der Elemente zurückgibt, auf die geklickt werden muss, um vom Basisstatus zum aktuellen zu gelangen.
Um auf das Ende der Antwort der Anwendung auf unsere Aktionen zu warten, verwendet die Wartefunktion die Network Long Task-API, die anzeigt, ob JS mit einer Arbeit beschäftigt ist.
Kehren wir zu unserer Anwendung zurück. Der Ausgangszustand ist wie folgt:
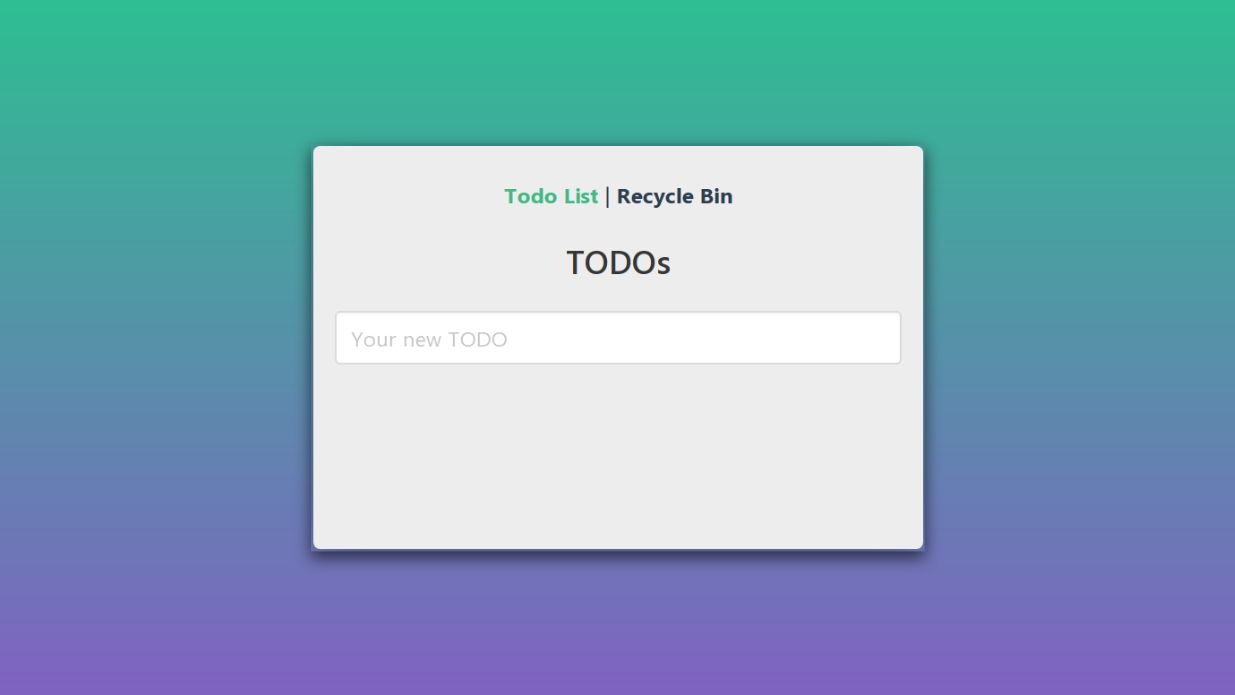
Nach zehn Iterationen der Anwendung erhalten wir das folgende Diagramm mit Zuständen und Übergängen:
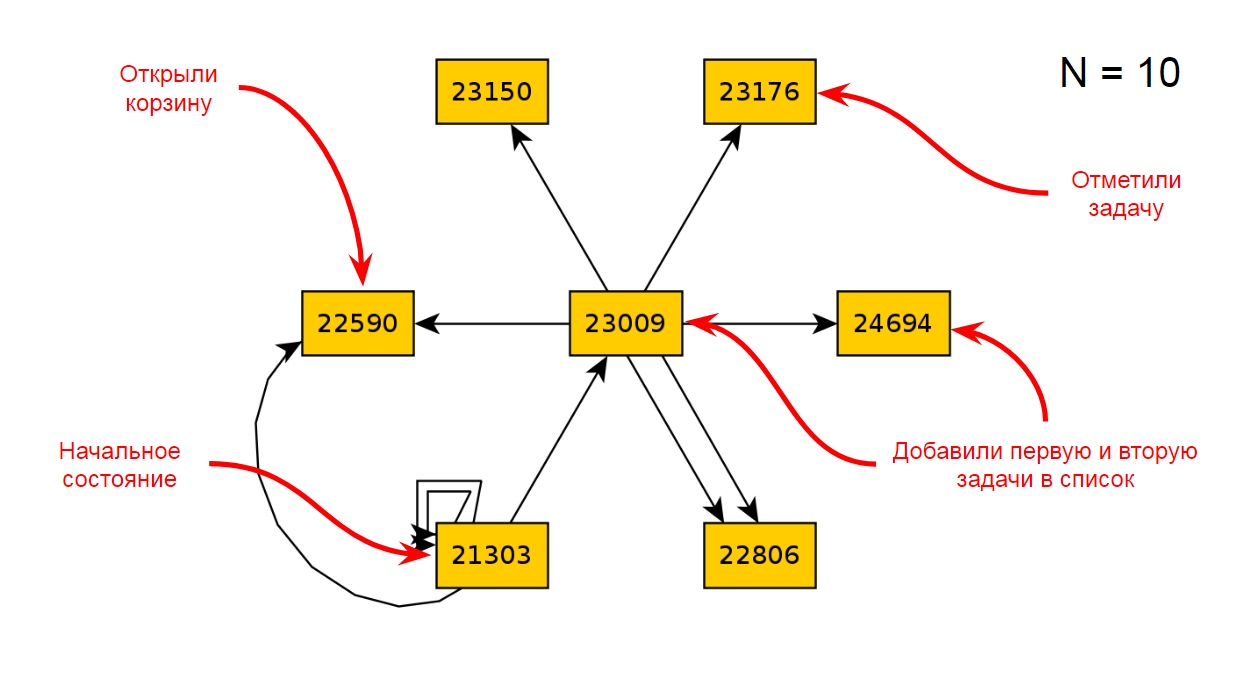
Nach 22 Iterationen ist dies das folgende:
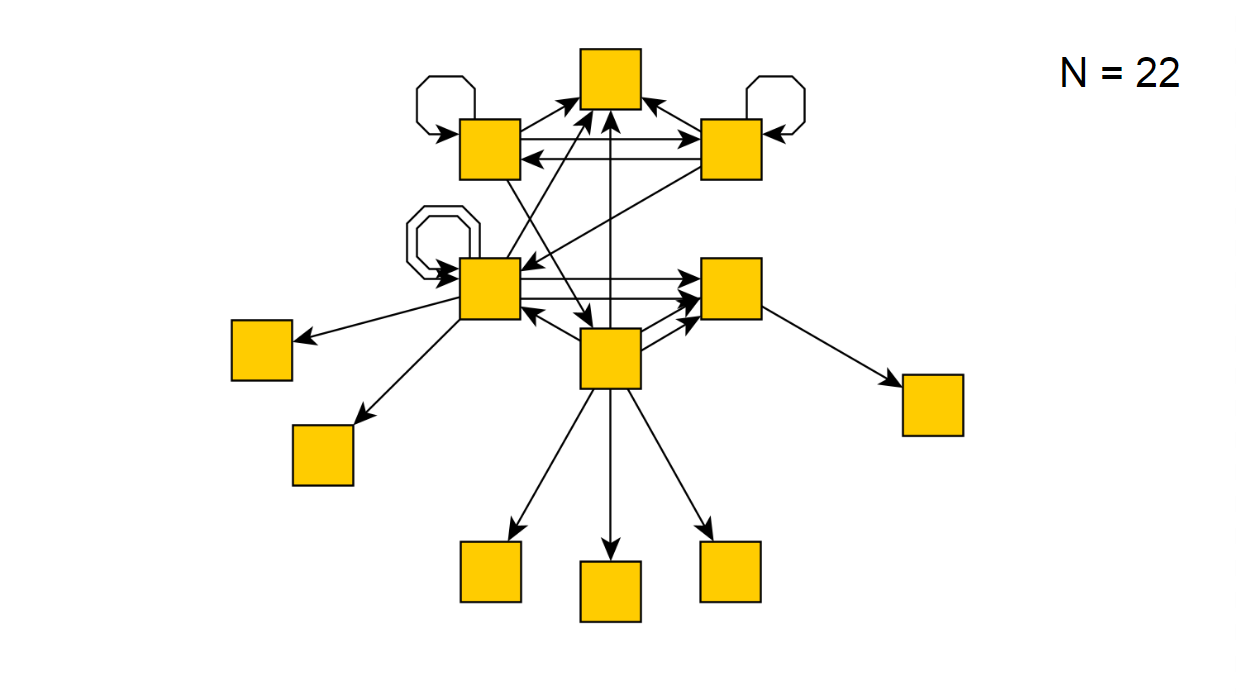
Wenn wir unser Skript mehrere Stunden lang ausführen, wird plötzlich gemeldet, dass es alle möglichen Zustände umgangen hat, und das folgende Diagramm erhalten:

Also mit einer einfachen Demoanwendung Wir haben es geschafft. Und was passiert, wenn Sie dieses Skript in einer echten Webanwendung festlegen? Und es wird Chaos geben:
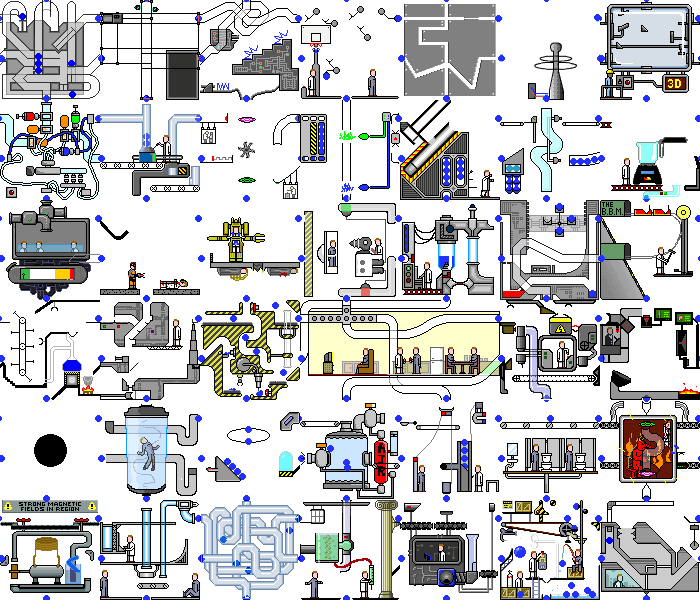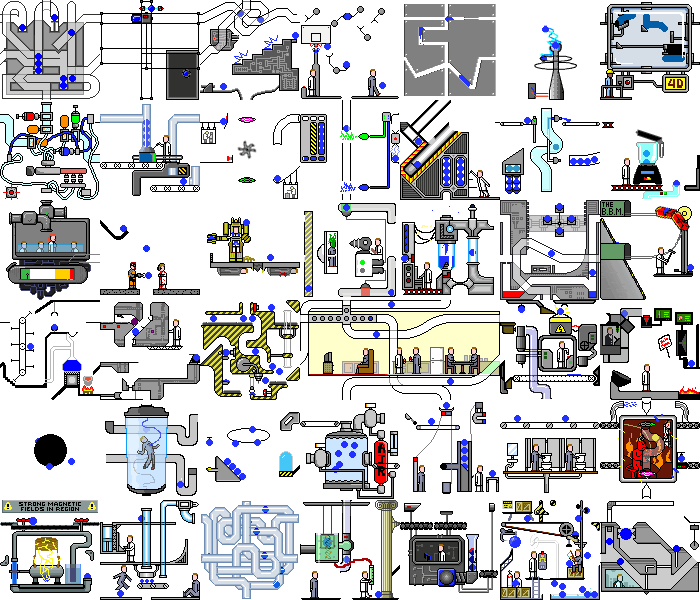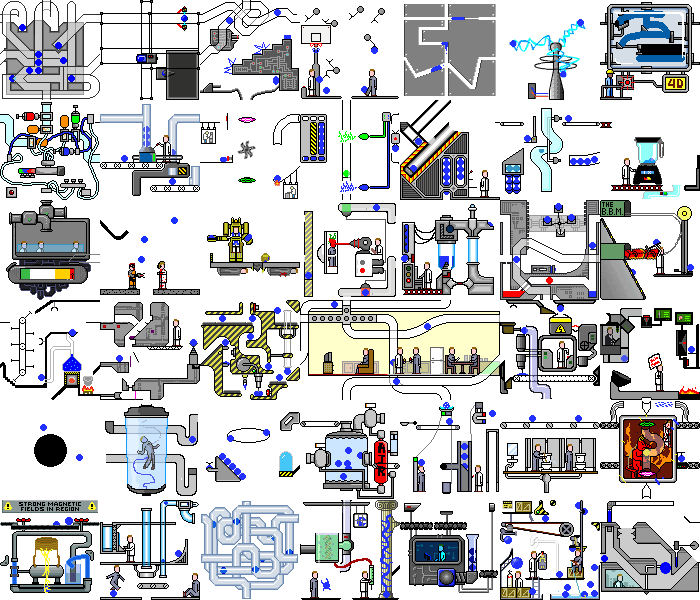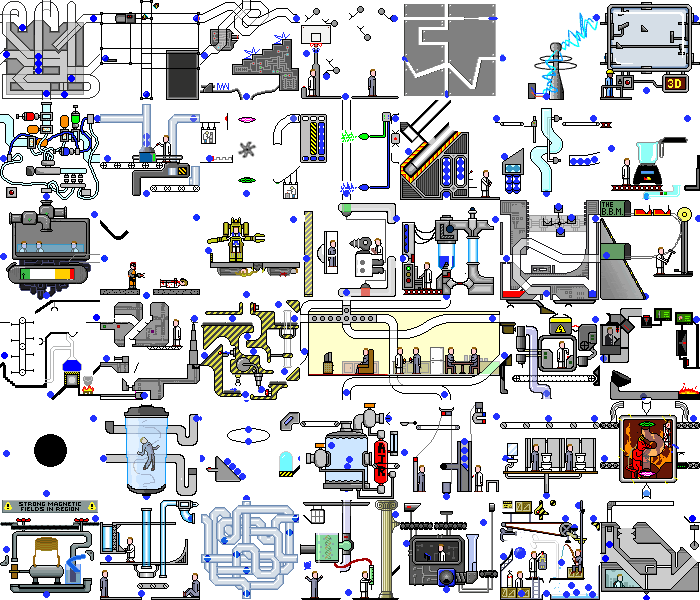
Es treten nicht nur Änderungen im Backend auf, die Seite selbst wird ständig neu gezeichnet, wenn auf Timer oder Ereignisse reagiert wird. Wenn dieselben Aktionen ausgeführt werden, können unterschiedliche Zustände auftreten. Aber auch in solchen Anwendungen finden Sie Funktionen, die unser Skript ohne wesentliche Änderungen verarbeiten kann.
Nehmen wir es zum TestenVLSI- Authentifizierungsseite :

Und dafür stellte sich schnell genug heraus, um ein vollständiges Diagramm der Zustände und Übergänge zu erstellen:
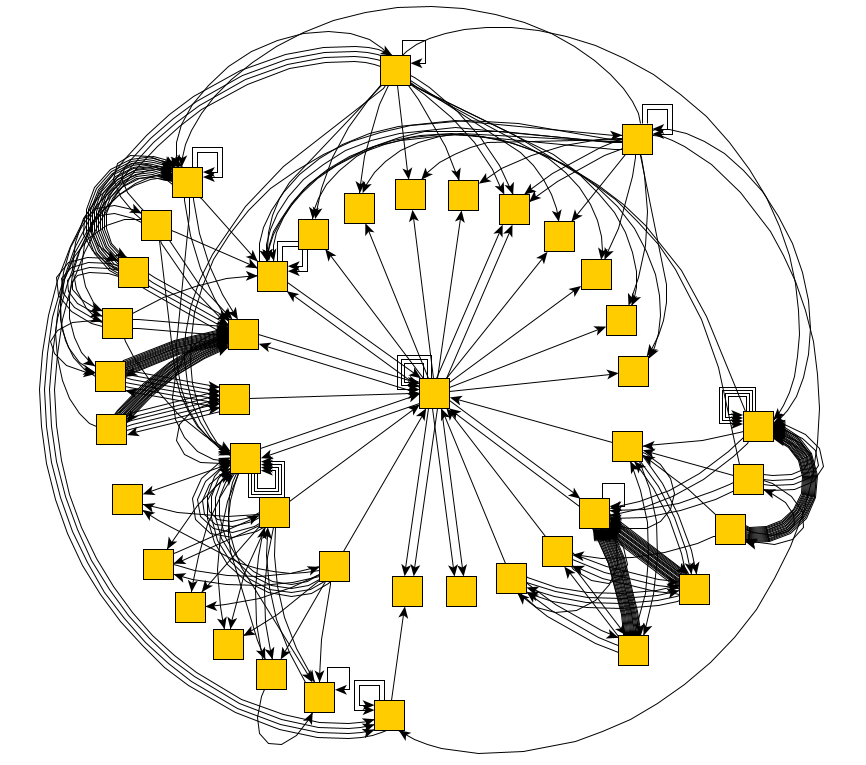

Ausgezeichnet! Wir können jetzt alle Zustände der Anwendung durchlaufen. Und rein theoretisch finden Sie alle Fehler, die von den Aktionen abhängen. Aber wie bringt man einem Programm bei, zu verstehen, dass ein Fehler vorliegt?
Beim Testen werden die Antworten des Programms immer mit einem bestimmten Standard verglichen, der als Orakel bezeichnet wird. Dies können technische Spezifikationen, Modelle, Programmanaloga, frühere Versionen, Testerfahrung, formale Anforderungen, Testfälle usw. sein. Wir können auch einige dieser Orakel in unserem Werkzeug verwenden.

Betrachten wir das letzte Muster „es war vorher anders“. Autotests führen Regressionstests durch.
Kehren wir nach 10 Iterationen von TODO zum Diagramm zurück:
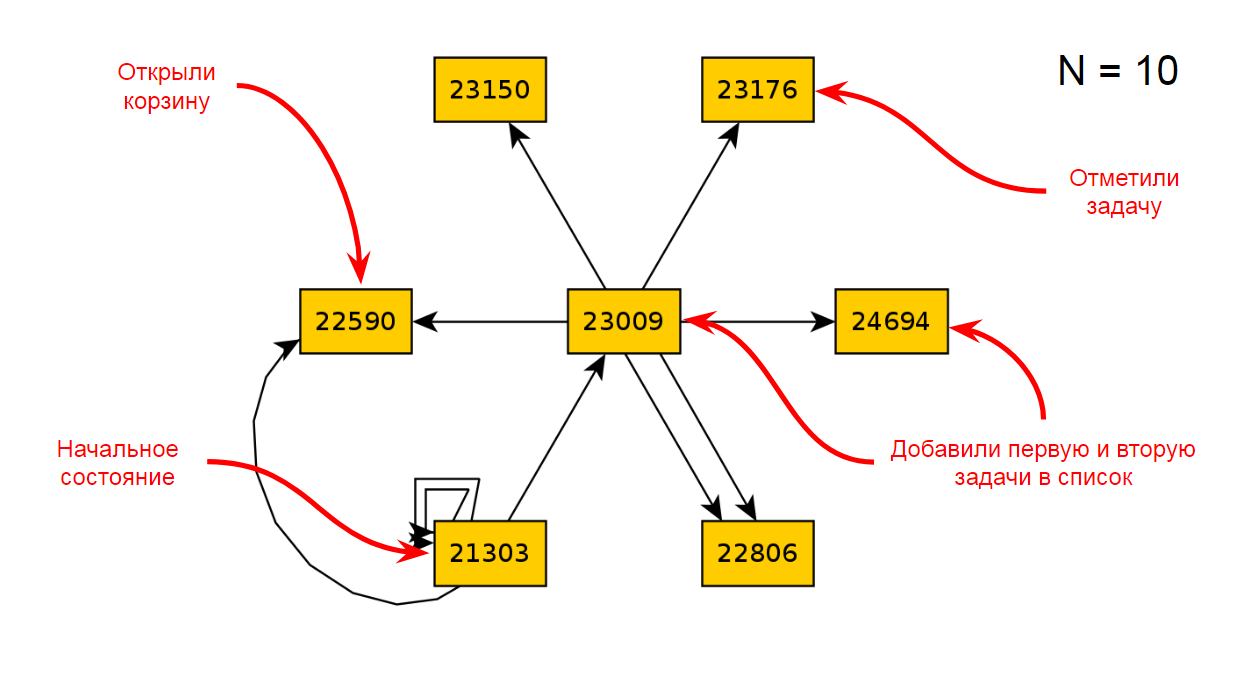
Lassen Sie uns den Code brechen, der für das Öffnen des Einkaufswagens verantwortlich ist, und erneut 10 Iterationen ausführen:
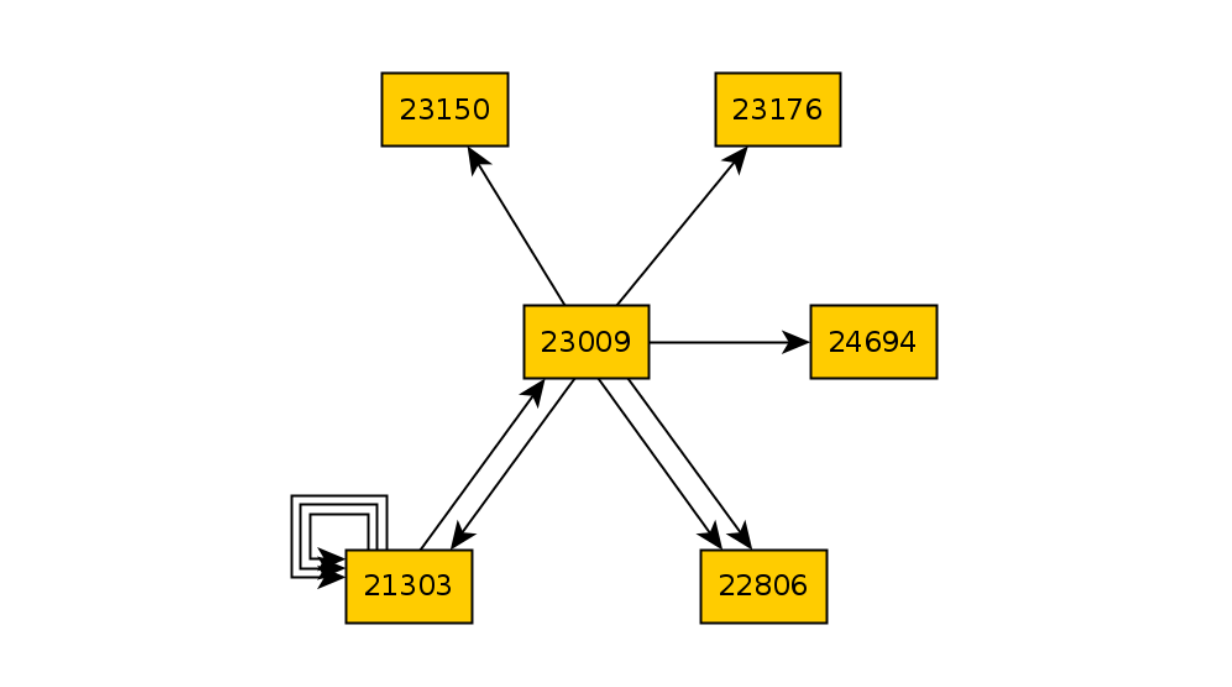
Vergleichen Sie dann die beiden Diagramme und ermitteln Sie den Unterschied in den Zuständen:
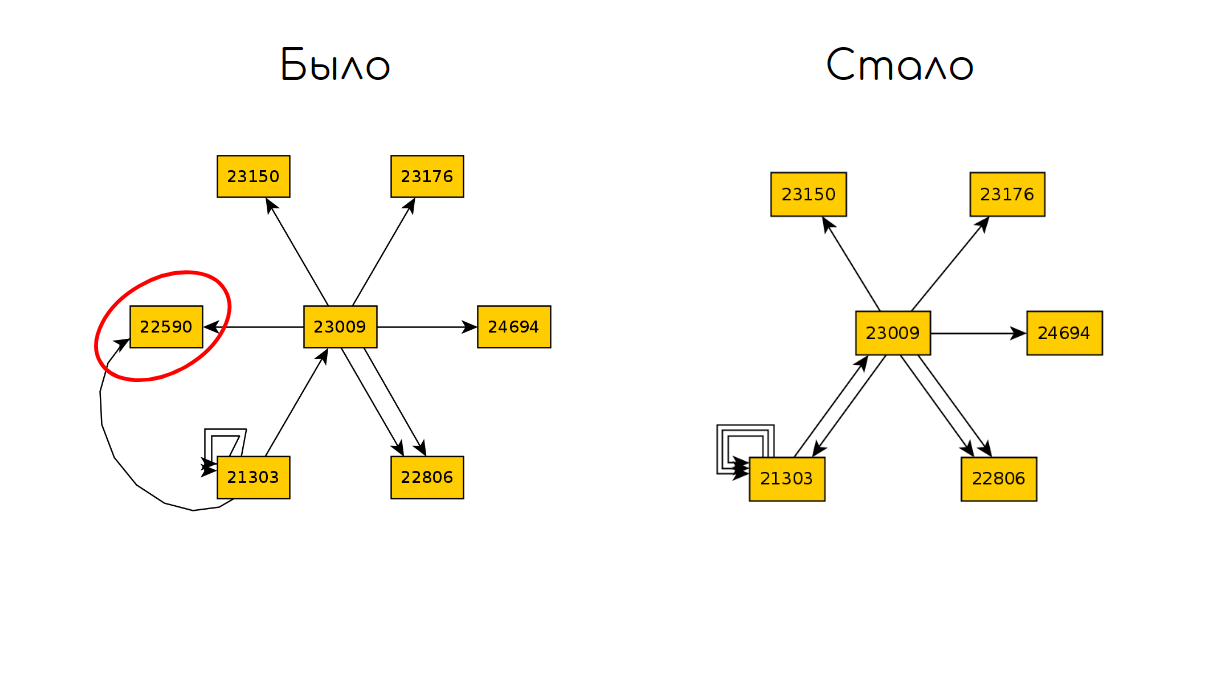
Wir können diesen Ansatz zusammenfassen: Mit

dieser Technik können Sie derzeit eine kleine Anwendung testen und offensichtliche oder Regressionsfehler identifizieren. Damit die Technik für große Anwendungen mit instabilen GUIs eingesetzt werden kann, sind erhebliche Verbesserungen erforderlich.
Der gesamte Quellcode und eine Liste der verwendeten Materialien finden Sie im Repository: https://github.com/svdokuchaev/venom . Für diejenigen, die die Verwendung von Fuzzing beim Testen verstehen möchten, empfehle ich The Fuzzing Book . Dort wird in einem der Teile der gleiche Ansatz zum Fuzzing einfacher HTML-Formulare beschrieben .
