
Dies ist eine Übersetzung des zweiten Artikels in einer Reihe zum Thema Datenschutz.
Letzte Woche haben wir uns im ersten Artikel dieser Reihe - " Differential Privacy - Analysieren von Daten unter Wahrung der Vertraulichkeit (Einführung in die Serie) " - mit den grundlegenden Konzepten und Verwendungen von Differential Privacy befasst. Heute werden wir mögliche Optionen für das Erstellen von Systemen in Abhängigkeit vom erwarteten Bedrohungsmodell prüfen.
Die Bereitstellung eines Systems, das den Grundsätzen des differenzierten Datenschutzes entspricht, ist keine triviale Aufgabe. In unserem nächsten Beitrag sehen wir uns beispielsweise ein einfaches Python-Programm an, das die Laplace-Rauschaddition direkt in einer Funktion implementiert, die vertrauliche Daten verarbeitet. Damit dies funktioniert, müssen wir jedoch alle erforderlichen Daten auf einem Server sammeln.
Was ist, wenn der Server gehackt wird? In diesem Fall hilft uns die unterschiedliche Privatsphäre nicht weiter, da sie nur die Daten schützt, die durch die Arbeit des Programms erhalten wurden!
Bei der Bereitstellung von Systemen, die auf den Prinzipien der unterschiedlichen Privatsphäre basieren, ist es wichtig, das Bedrohungsmodell zu berücksichtigen: vor welchen Gegnern wir das System schützen wollen. Wenn dieses Modell Angreifer enthält, die einen Server mit vertraulichen Daten vollständig gefährden können, müssen wir das System ändern, um solchen Angriffen zu widerstehen.
Das heißt, die Architekturen von Systemen, die die unterschiedliche Privatsphäre respektieren, müssen sowohl die Privatsphäre als auch die Sicherheit berücksichtigen . Der Datenschutz kontrolliert, was aus den vom System zurückgegebenen Daten abgerufen werden kann. Und Sicherheit kann als die entgegengesetzte Aufgabe angesehen werden: Sie kontrolliert den Zugriff auf einen Teil der Daten, gibt jedoch keine Garantie für deren Inhalt.
Zentrales differenzielles Datenschutzmodell
Das am häufigsten verwendete Bedrohungsmodell in der Arbeit mit differenzierter Privatsphäre ist das zentrale differenzielle Datenschutzmodell (oder einfach "zentrale differenzielle Privatsphäre").
Die Hauptkomponente - der vertrauenswürdige Datenspeicher (Trusted Data Curator) . Jede Quelle sendet ihm seine vertraulichen Daten und sammelt sie an einem Ort (z. B. auf einem Server). Ein Repository ist vertrauenswürdig, wenn wir davon ausgehen, dass es unsere sensiblen Daten selbst verarbeitet, nicht an Dritte überträgt und von niemandem kompromittiert werden kann. Mit anderen Worten, wir glauben, dass ein Server mit vertraulichen Daten nicht kompromittiert werden kann.
Als Teil des zentralen Modells fügen wir den Antworten auf Abfragen normalerweise Rauschen hinzu (wir werden uns die Laplace-Implementierung im nächsten Artikel ansehen). Der Vorteil dieses Modells besteht in der Möglichkeit, den niedrigstmöglichen Rauschwert hinzuzufügen und so die maximale Genauigkeit beizubehalten, die die Prinzipien der differenziellen Privatsphäre zulassen. Unten sehen Sie ein Diagramm des Prozesses. Wir haben eine Datenschutzbarriere zwischen dem vertrauenswürdigen Datenspeicher und dem Analysten eingerichtet, damit nur Ergebnisse, die die angegebenen unterschiedlichen Datenschutzkriterien erfüllen, nach außen gelangen können. Daher muss dem Analysten nicht vertraut werden.
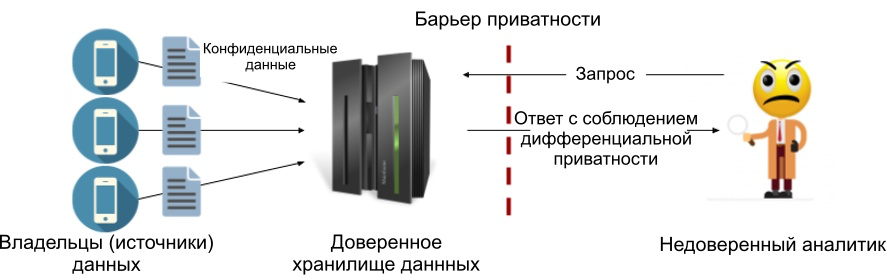
Abbildung 1: Das zentrale differenzielle Datenschutzmodell.
Der Nachteil des zentralen Modells besteht darin, dass ein vertrauenswürdiger Speicher erforderlich ist, viele jedoch nicht. Tatsächlich ist das mangelnde Vertrauen in den Verbraucher der Daten normalerweise der Hauptgrund für die Verwendung unterschiedlicher Datenschutzgrundsätze.
Lokales differenzielles Datenschutzmodell
Mit dem lokalen differenziellen Datenschutzmodell können Sie den vertrauenswürdigen Datenspeicher entfernen: Jede Datenquelle (oder jeder Dateneigentümer) fügt ihren Daten Rauschen hinzu, bevor sie in den Speicher übertragen werden. Dies bedeutet, dass der Speicher niemals vertrauliche Informationen enthält, was bedeutet, dass keine Vollmacht erforderlich ist. Die folgende Abbildung zeigt das Gerät des lokalen Modells: Darin befindet sich eine Datenschutzbarriere zwischen jedem Eigentümer der Daten und dem Speicher (dem möglicherweise vertraut wird oder nicht).
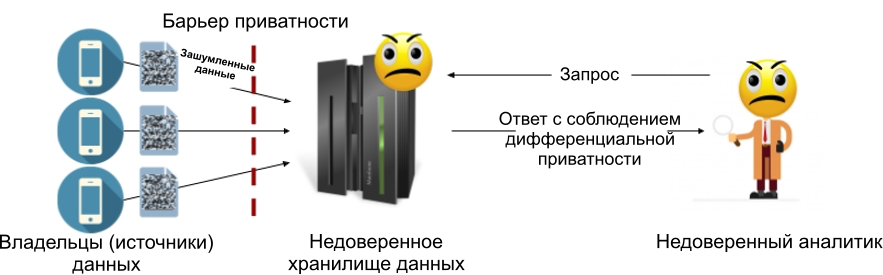
Abbildung 2: Lokales differenzielles Datenschutzmodell.
Das lokale Modell des differenziellen Datenschutzes vermeidet das Hauptproblem des zentralen Modells: Wenn das Data Warehouse kompromittiert wird, haben Hacker nur Zugriff auf verrauschte Daten, die bereits die Anforderungen des differenziellen Datenschutzes erfüllen. Dies ist der Hauptgrund, warum das lokale Modell für Systeme wie Google RAPPOR [1] und Apples Datenerfassungssystem [2] ausgewählt wurde.
Andererseits? Das lokale Modell ist weniger genau als das zentrale. Im lokalen Modell fügt jede Quelle unabhängig Rauschen hinzu, um ihre eigenen unterschiedlichen Datenschutzbedingungen zu erfüllen, sodass das Gesamtrauschen aller Teilnehmer viel größer ist als das Rauschen im zentralen Modell.
Letztendlich ist dieser Ansatz nur für Abfragen mit einem sehr anhaltenden Trend (Signal) gerechtfertigt. Apple verwendet beispielsweise ein lokales Modell, um die Beliebtheit von Emoji abzuschätzen. Das Ergebnis ist jedoch nur für das beliebteste Emoji nützlich (wo der Trend am ausgeprägtesten ist). In der Regel wird dieses Modell nicht für komplexere Abfragen verwendet, wie sie beispielsweise bei der US-Volkszählung [10] oder beim maschinellen Lernen verwendet werden.
Hybridmodelle
Das zentrale und das lokale Modell haben sowohl Vor- als auch Nachteile, und die Hauptanstrengung besteht nun darin, das Beste aus ihnen herauszuholen.
Zum Beispiel können Sie mit dem schlurfenden Modell im Prochlo System implementiert [4]. Es enthält einen nicht vertrauenswürdigen Datenspeicher, viele einzelne Dateneigentümer und mehrere teilweise vertrauenswürdige Shuffler.... Jede Quelle fügt ihren Daten zunächst eine geringe Menge an Rauschen hinzu und sendet sie dann an das Rührwerk, wodurch mehr Rauschen hinzugefügt wird, bevor sie an das Data Warehouse gesendet werden. Das Fazit ist, dass es unwahrscheinlich ist, dass Rührwerke mit dem Datenspeicher oder untereinander "kollidieren" (oder gleichzeitig gehackt werden), sodass ein wenig Rauschen durch die Quellen ausreicht, um die Privatsphäre zu gewährleisten. Jeder Rührer kann wie das zentrale Modell mehrere Quellen verarbeiten, sodass ein geringes Rauschen die Privatsphäre des resultierenden Datensatzes garantiert.
Das Rührmodell ist ein Kompromiss zwischen lokalen und zentralen Modellen: Es fügt weniger Rauschen als lokale, aber mehr als zentrale hinzu.
Sie können auch differenzielle Privatsphäre mit Kryptografie kombinieren, z. B. bei der sicheren Mehrparteienberechnung (MPC) oder der vollständig homomorphen Verschlüsselung (FHE). FHE ermöglicht Berechnungen mit verschlüsselten Daten, ohne diese zuerst zu entschlüsseln, und MPC ermöglicht einer Gruppe von Teilnehmern, Abfragen über verteilte Quellen sicher auszuführen, ohne ihre Daten offenzulegen. Berechnung differenzieller privater FunktionenDie Verwendung von kryptosicherem (oder einfach nur sicherem) Computing ist ein vielversprechender Weg, um eine zentrale Modellgenauigkeit mit allen Vorteilen lokaler Funktionen zu erreichen. Darüber hinaus macht in diesem Fall die Verwendung von Secure Computing die Notwendigkeit eines vertrauenswürdigen Speichers überflüssig. Jüngste Arbeiten [5] zeigen ermutigende Ergebnisse aus der Kombination von MPC und differenzierter Privatsphäre, wobei die meisten Vorteile beider Ansätze berücksichtigt werden. In den meisten Fällen sind sichere Berechnungen um mehrere Größenordnungen langsamer als lokal durchgeführte, was besonders für große Datenmengen oder komplexe Abfragen wichtig ist. Secure Computing befindet sich derzeit in der aktiven Entwicklungsphase, sodass die Leistung schnell zunimmt.
Und weiter?
Im nächsten Artikel werfen wir einen Blick auf unser erstes Open-Source-Tool zur praktischen Umsetzung differenzierter Datenschutzkonzepte. Schauen wir uns andere Tools an, die sowohl Neulingen zur Verfügung stehen als auch für sehr große Datenbanken wie die des US Census Bureau gelten. Wir werden versuchen, Bevölkerungsdaten in Übereinstimmung mit den Grundsätzen der unterschiedlichen Privatsphäre zu berechnen.
Abonnieren Sie unseren Blog und verpassen Sie nicht die Übersetzung des nächsten Artikels. Sehr bald.
Quellen
[1] Erlingsson, farlfar, Vasyl Pihur und Aleksandra Korolova. "Rappor: Randomisierte aggregierbare ordinale Antwort zum Schutz der Privatsphäre." In Proceedings of the 2014 ACM SIGSAC Konferenz über Computer- und Kommunikationssicherheit, pp. 1054-1067. 2014.
[2] Apple Inc. "Technischer Überblick über den Datenschutz bei Apple Differential." Zugriff am 31.07.2020. https://www.apple.com/privacy/docs/Differential_Privacy_Overview.pdf
[3] Garfinkel, Simson L., John M. Abowd und Sarah Powazek. "Probleme beim Bereitstellen der unterschiedlichen Privatsphäre." In Proceedings of the 2018 Workshop zum Datenschutz in der elektronischen Gesellschaft, pp. 133-137. 2018.
[4] Bittau, Andrea, Farfar Erlingsson, Petros Maniatis, Ilja Mironow, Ananth Raghunathan, David Lie, Mitch Rudominer, Ushasree Kode, Julien Tinnes und Bernhard Seefeld. "Prochlo: Starke Privatsphäre für Analysen in der Menge." In Proceedings of the 26. Symposium on Operating Systems Principles, pp. 441-459. 2017.
[5] Roy Chowdhury, Amrita, Chenghong Wang, Xi He, Ashwin Machanavajjhala und Somesh Jha. "Cryptε: Crypto-Assisted Differential Privacy auf nicht vertrauenswürdigen Servern." In den Proceedings der 2020 ACM SIGMOD International Conference on Management of Data, pp. 603-619. 2020.