
Ein paar Worte zu Empfehlungssystemen
Sicherlich haben sie alle mehr als einmal getroffen. Empfehlungssysteme sind Programme und Dienste, die versuchen, vorherzusagen, was für einen bestimmten Benutzer interessant / notwendig / nützlich sein könnte, und dies ihnen zu zeigen. „Magst du diese Laufschuhe? Möglicherweise benötigen Sie auch eine Windjacke, einen Herzfrequenzmesser und 15 weitere Sportartikel . " In den letzten Jahren haben Marken Empfehlungssysteme sehr aktiv in ihre Arbeit implementiert, da sowohl der Verkäufer als auch der Käufer von dieser Entscheidung „profitieren“. Verbraucher erhalten ein Tool, mit dem sie in kurzer Zeit eine Auswahl aus einer unendlichen Vielfalt von Waren und Dienstleistungen treffen können, und das Unternehmen steigert Umsatz und Publikum.
Was wurde uns gegeben?
Ich habe an einem Projekt für ein großes globales Unternehmen gearbeitet, das seinen Kunden eine SaaS-Frachtbörsenlösung oder eine Frachtbörsenplattform zur Verfügung stellt.
Es klingt unverständlich, aber wie es tatsächlich passiert: Einerseits sind Benutzer auf der Plattform registriert, die Lasten haben und diese irgendwohin senden müssen. Sie stellen eine Bewerbung wie "Es gibt eine Menge dekorativer Kosmetika, die morgen von Amsterdam nach Antwerpen gebracht werden müssen".und warten auf eine Antwort. Auf der anderen Seite haben wir Leute oder Firmen mit Lastwagen - Frachtunternehmen. Nehmen wir an, sie haben bereits ihren wöchentlichen Standardflug gemacht und Joghurt von Paris nach Brüssel geliefert. Sie müssen zurück und, um nicht mit einem leeren Lastwagen zu fahren, eine Art Fracht finden, die sie auf dem Rückweg transportieren können. Zu diesem Zweck gehen Frachtführer zur Plattform meines Kunden und führen eine Suche (über die englische Suche) durch, wobei sie die Richtung und möglicherweise die Art der Fracht (oder Fracht aus der englischen Fracht) angeben, die für einen LKW geeignet ist. Das System sammelt Anträge von Versendern und zeigt sie den Frachtführern.
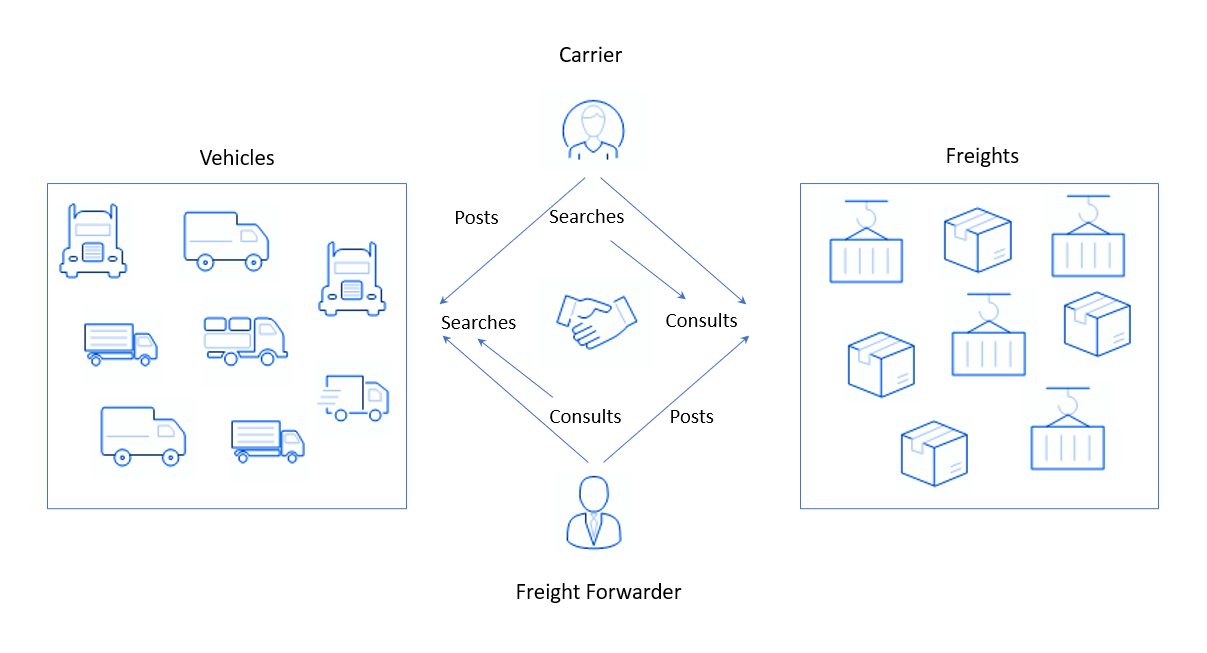
In solchen Plattformen ist das Gleichgewicht zwischen Angebot und Nachfrage wichtig. Hier werden Waren von Frachtführern und Lastwagen von Verladern nachgefragt, und als Angebot gilt das Gegenteil: Autos von Spediteuren und Waren von Unternehmen. Das Gleichgewicht ist aus mehreren Gründen schwierig aufrechtzuerhalten, zum Beispiel:
- Geschlossene Kommunikation zwischen dem Spediteur und dem Kunden. Wenn ein Fahrer oft nur mit einem bestimmten Kunden zusammenarbeitet, funktioniert er auf der Plattform nicht gut. Wenn der Versender den Markt verlässt, kann der Dienstleister auch den Spediteur verlieren, da er Kunde eines anderen Logistikunternehmens wird.
- Das Vorhandensein von Waren, die niemand transportieren möchte. Dies geschieht, wenn kleine Unternehmen Transportaufträge erteilen und diese dann nicht aktualisiert werden und dementsprechend schnell die Anzahl der aktiven Unternehmen verlassen.
Das Unternehmen wollte die Funktionalität seiner Frachtbörsenplattform verbessern und die Benutzererfahrung der Benutzer verbessern, damit sie alle Funktionen des Systems und eine breite Palette von Waren sehen können und auch nicht die Loyalität verlieren. Dies könnte die Zielgruppe davon abhalten, zu einem wettbewerbsfähigen Dienst zu wechseln, und den Frachtführern zeigen, dass geeignete Bestellungen nicht nur von den Unternehmen gefunden werden können, mit denen sie gewohnt sind, zu arbeiten.
Unter Berücksichtigung aller Wünsche stand ich vor der Aufgabe , ein Empfehlungssystem zu entwickeln, das den Spediteuren unmittelbar am Eingang der Plattform die aktuell verfügbare relevante Fracht anzeigt und errät, was sie wohin transportieren möchten. Dieses System sollte in die bestehende Frachtbörsenplattform integriert werden.
Wie werden wir "raten"?
Unser Empfehlungssystem arbeitet wie andere an der Analyse von Benutzerdaten. Und es gibt mehrere Quellen, mit denen Sie arbeiten können:
- Öffnen Sie zunächst Informationen zu Anträgen für den Warentransport.
- Zweitens liefert die Plattform Daten über den Träger. Wenn der Benutzer einen Vertrag mit unseren Kunden abschließt, kann er angeben, wie viele LKWs er hat und welchen Typ. Aber leider nachdem diese Daten nicht aktualisiert wurden. Und das einzige, worauf wir uns verlassen können, ist das Land der Fluggesellschaft, da es sich höchstwahrscheinlich nicht ändern wird.
- Drittens speichert das System den Verlauf der Benutzersuche über mehrere Jahre: sowohl die letzten Anforderungen als auch vor einem Jahr.
In der Anwendung, in der sie beschlossen, das Empfehlungssystem einzuführen, gab es bereits einen Mechanismus für die Suche nach Waren auf vorherige Anfrage. Aus diesem Grund haben wir uns darauf konzentriert, Muster oder Muster zu identifizieren, anhand derer der Benutzer nach Waren für den Transport sucht. Das heißt, wir empfehlen die Last nicht, sondern wählen die Richtung aus , die für diesen Benutzer heute am besten geeignet ist. Und wir werden die Ware bereits über die Standardsuchmaschine finden.
Im Allgemeinen basieren beliebte Suchanfragen auf geografischen Informationen und zusätzlichen Parametern wie dem LKW-Typ oder dem zu transportierenden Gegenstand. Dies ist leicht zu verfolgen, da sich diese Einstellungen kaum ändern. Unten habe ich die Daten von Anfragen eines der Benutzer für 3 Tage angegeben. Die Reihenfolge des Füllens ist wie folgt: 1 Spalte - Abflugland, 2 - Zielland, 3 - Abflugregion, 4 - Zielregion.

Sie können sehen, dass dieser Benutzer bestimmte Präferenzen in Ländern und Provinzen hat. Dies ist jedoch nicht bei allen der Fall und nicht immer. Sehr oft gibt der Beförderer nur das Bestimmungsland an oder nicht die Abflugregion. Beispielsweise befindet er sich in Belgien und kann in jede Provinz kommen, um die Fracht abzuholen. Im Allgemeinen gibt es verschiedene Arten von Abfragen: "Land-zu-Land", "Land-zu-Region", "Region-zu-Land" oder "Region-Region" (die beste Option).
Algorithmusbeispiele
Wie Sie wissen, sind Strategien zum Erstellen von Empfehlungssystemen hauptsächlich in inhaltsbasierte Filterung und kollaborative Filterung unterteilt. Auf dieser Klassifizierung begann ich, Lösungen zu entwickeln.
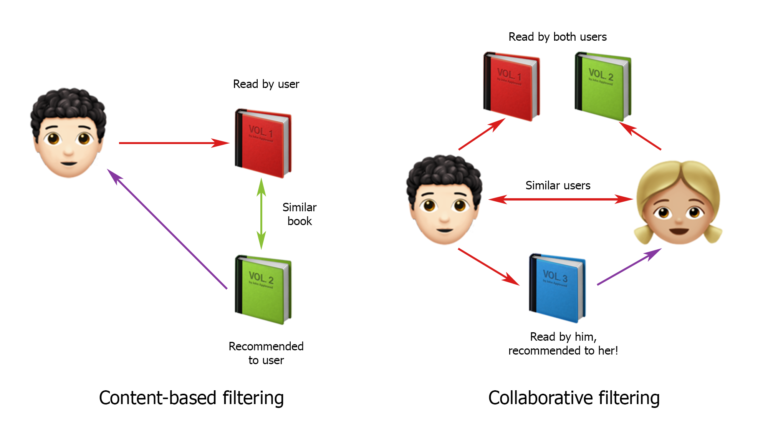
Ich habe das Bild von hub.forklog.com gemacht
Viele Quellen sagen, dass kollaboratives Filtern besser funktioniert. Es ist ganz einfach: Wir versuchen, Benutzer zu finden, die unseren ähnlich sind und ähnliche Verhaltensmuster aufweisen, und wir empfehlen unseren Benutzern dieselben Anforderungen wie ihre. Im Allgemeinen war diese Lösung die erste Option, die ich Kunden vorstellte. Aber sie waren nicht einverstanden mit ihm und sagten, es würde nicht funktionieren. Schließlich hängt alles sehr davon ab, wo sich der LKW jetzt befindet, wo er die Ladung aufgenommen hat, wo er lebt und wo er bequemer zu fahren ist. Wir wissen nicht alles darüber, weshalb es so schwierig ist, sich auf das Verhalten anderer Benutzer zu verlassen, selbst wenn diese auf den ersten Blick ähnlich sind.
Nun zu den inhaltsbasierten Systemen. Sie funktionieren folgendermaßen: Zuerst wird ein Benutzerprofil festgelegt und erstellt, und dann wird eine Auswahl von Empfehlungen basierend auf seinen Merkmalen getroffen. Eine gute Option, aber in unserem Fall gibt es ein paar Nuancen. Erstens kann ein Benutzer eine ganze Gruppe von Personen verstecken, die nach Fracht für viele Lastwagen suchen, und sich von verschiedenen IPs aus anmelden. Zweitens haben wir aus den genauen Daten nur das Land des Beförderers, und Informationen über die Anzahl der Lastkraftwagen und ihre Typen werden nur in den vom Benutzer gestellten Anfragen ungefähr "angezeigt". Das heißt, um ein inhaltsbasiertes System für unser Projekt zu erstellen, müssen Sie die Anforderungen jedes Benutzers prüfen und versuchen, das beliebteste unter ihnen zu finden.
Unser erstes Empfehlungssystem verwendete keine komplexen Algorithmen. Wir haben versucht, die Anfragen zu ordnen und die höchsten Herzen zu finden, um sie zu empfehlen. Um das Konzept zu testen, arbeitete unser Team mit echten Benutzern zusammen: schickte ihnen Empfehlungen und sammelte dann Feedback. Grundsätzlich gefiel den Carriern das Ergebnis. Dann verglich ich unsere Empfehlungen mit denen, nach denen Carrier heutzutage suchten, und stellte fest, dass das System für Benutzer mit stabilen Verhaltensmustern sehr gut funktioniert. Leider war die Genauigkeit der Empfehlungen für diejenigen, die ein breiteres Spektrum an Anfragen stellten, nicht sehr hoch - das System musste verbessert werden.
Ich habe weiter herausgefunden, womit wir es hier zu tun haben. Tatsächlich handelt es sich um ein verstecktes Markov-Modell, bei dem sich hinter jedem Benutzer eine Gruppe von Personen befinden kann. Darüber hinaus können sich Benutzer in verschiedenen versteckten Zuständen befinden: Es gibt keine Daten darüber, wo sie derzeit einen LKW haben, wie viele Personen sich auf einem Konto befinden und wann sie das nächste Mal irgendwohin müssen. Zu dieser Zeit kannte ich keine vorgefertigten Lösungen für die Herstellung des Hidden-Markov-Modells, daher entschied ich mich, etwas Einfacheres zu finden.
Treffen Sie PageRank
Daher habe ich auf den PageRank-Algorithmus aufmerksam gemacht, der einst von den Google-Gründern Sergey Brin und Larry Page erstellt wurde und von dieser Suchmaschine immer noch verwendet wird, um Nutzern Websites zu empfehlen. Der PageRank repräsentiert den gesamten Internetbereich in Form eines Diagramms, wobei jede Webseite ihr Knoten ist. Es kann verwendet werden, um die "Wichtigkeit" (oder den Rang) für jeden Knoten zu berechnen. PageRank unterscheidet sich grundlegend von den zuvor existierenden Suchalgorithmen, da es nicht auf dem Inhalt von Seiten basiert, sondern auf den darin enthaltenen Links. Das heißt, der Rang jeder Seite hängt von der Anzahl und Qualität der Links ab, die darauf verweisen. Brin und Page haben die Konvergenz dieses Algorithmus bewiesen, was bedeutet, dass wir immer den Rang eines Knotens in einem gerichteten Graphen berechnen und zu Werten gelangen können, die sich nicht ändern.
Schauen wir uns die Formel an:
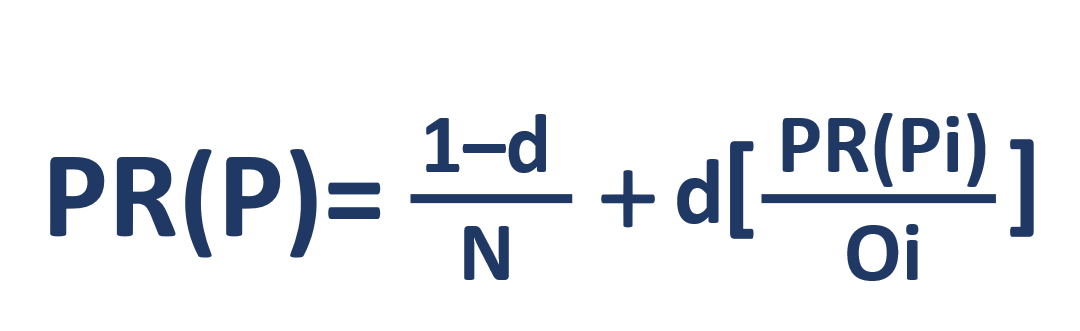
- PR(P) – rank
- N –
- i –
- O –
- d – . -, , - . , . 0 ≤ d ≤ 1 – d 0,85. .
Und nun ein einfaches Beispiel für die Berechnung des PageRank für ein einfaches Diagramm, das aus drei Knoten besteht. Es ist wichtig zu beachten, dass zu Beginn alle Knoten das gleiche Gewicht erhalten, das 1 / Anzahl der Knoten entspricht.
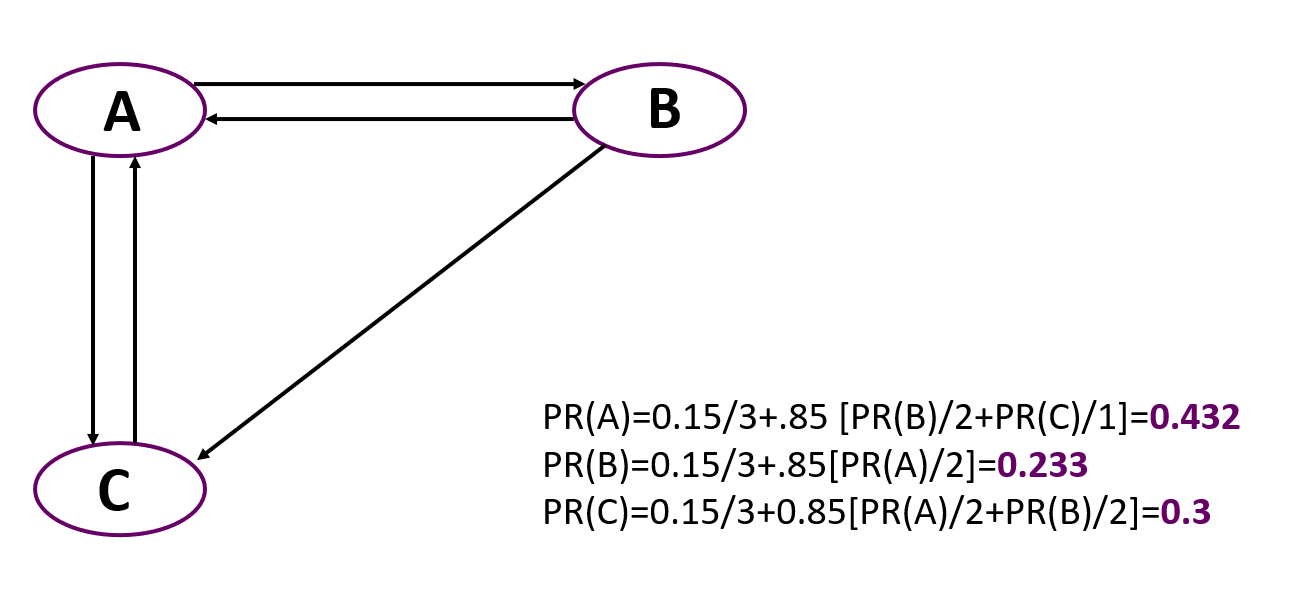
Sie können sehen, dass der wichtigste hier Knoten A ist, obwohl nur zwei Knoten darauf zeigen, wie auf C. Der Rang der Knoten, die auf A zeigen, ist jedoch höher als die Knoten, die zu C führen.
Annahmen und Lösung
PageRank beschreibt also einen Markov-Prozess ohne versteckte Zustände. Wenn wir es verwenden, finden wir immer das endgültige Gewicht jedes Knotens, können jedoch keine Änderungen im Diagramm verfolgen. Der Algorithmus ist wirklich gut, wir konnten ihn anpassen und die Genauigkeit der Ergebnisse verbessern. Zu diesem Zweck haben wir eine Modifikation von PageRank vorgenommen - dem personalisierten PageRank-Algorithmus, der sich vom Basisalgorithmus dadurch unterscheidet, dass der Übergang immer zu einer begrenzten Anzahl von Knoten ausgeführt wird. Das heißt, wenn der Benutzer es leid ist, die Links zu „gehen“, wechselt er nicht zu einem zufälligen Knoten, sondern zu einem bestimmten Satz.
In unserem Fall sind die Knoten des Diagramms Benutzeranforderungen. Da unser Algorithmus Empfehlungen für den kommenden Tag geben soll, habe ich alle Anfragen für jeden Carrier nach Tag aufgeschlüsselt. Jetzt erstellen wir ein Diagramm: Knoten A verbindet sich mit Knoten B, wenn die Suche nach Typ B der Suche nach Typ A folgt, dh die Suche nach Typ A wurde vom Benutzer vor dem Tag durchgeführt, an dem er nach Route B suchte. Beispiel: "Paris - Brüssel" am Dienstag (A) und am Mittwoch „Brüssel - Köln“ (B). Einige Benutzer stellen täglich viele Anfragen, sodass mehrere Knoten gleichzeitig miteinander verbunden sind und wir daher ziemlich komplexe Diagramme erhalten.
Um Informationen darüber hinzuzufügen, wie wichtig es ist, von einem Herzen zum anderen zu wechseln, haben wir die Kanten des Diagramms gewichtet. Das Gewicht der A-B-Kante gibt an, wie oft der Benutzer B nach der Suche nach A durchsucht hat. Es ist auch sehr wichtig, das Alter der Abfragen zu berücksichtigen, da der Benutzer seine Vorlage ändert: Er kann die Haupttransportart verschieben oder neu organisieren, wonach er nicht mit einem leeren LKW fahren möchte. Daher müssen Sie den Verlauf der Routen überwachen. Wir fügen eine Aktualitätsvariable hinzu, die sich auch auf das Gewicht des Knotens auswirkt.
Es lohnt sich, die Saisonalität zu berücksichtigen: Wir wissen vielleicht, dass die Fluggesellschaft beispielsweise im September häufig nach Frankreich und im Oktober nach Deutschland reist. Dementsprechend können Herzen, die in einem bestimmten Monat "beliebt" sind, mehr Gewicht erhalten. Darüber hinaus stützen wir uns auf Informationen darüber, wann der Benutzer das letzte Mal gesucht hat. Dies hilft indirekt zu erraten, wo sich der LKW befinden könnte.
Ergebnis
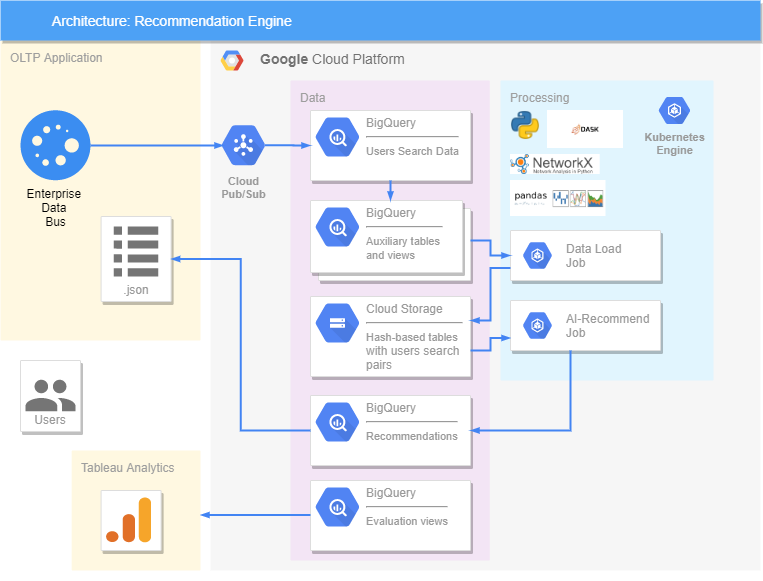
Alles ist auf der Google-Plattform implementiert. Wir haben eine OLTP-Anwendung, von der die Daten zu Abfragen zu BigQuery kommen und gehen, wo zusätzliche Ansichten und Tabellen mit bereits verarbeiteten Informationen gebildet werden. Die DASK-Bibliothek wurde verwendet, um die Verarbeitung großer Datenmengen zu beschleunigen und zu parallelisieren. In unserer Lösung werden alle Daten in den Cloud-Speicher übertragen, da DASK nur damit arbeitet und nicht mit BigQuery interagiert. In Kubernetes wurden zwei Jobs erstellt, von denen einer Daten von BigQuery in den Cloud-Speicher überträgt und der zweite Empfehlungen enthält. Das funktioniert so: Job nimmt Daten über Herzpaare aus dem Cloud-Speicher, verarbeitet sie, generiert Empfehlungen für den kommenden Tag und sendet sie an BigQuery zurück. Von dort aus können wir bereits im JSON-Format Empfehlungen an die OLTP-Anwendung senden, wo die Benutzer sie sehen.Die Genauigkeit der Empfehlungen wird in Tableau bewertet, wo unsere Empfehlungen mit dem verglichen werden, wonach der Benutzer später tatsächlich gesucht hat, sowie mit seiner Reaktion (ob es ihm gefallen hat oder nicht).
Natürlich möchte ich die Ergebnisse teilen. Hier ist zum Beispiel ein Benutzer, der jeden Tag 14 Länderherzen herstellt. Wir haben ihm auch den gleichen Betrag empfohlen:
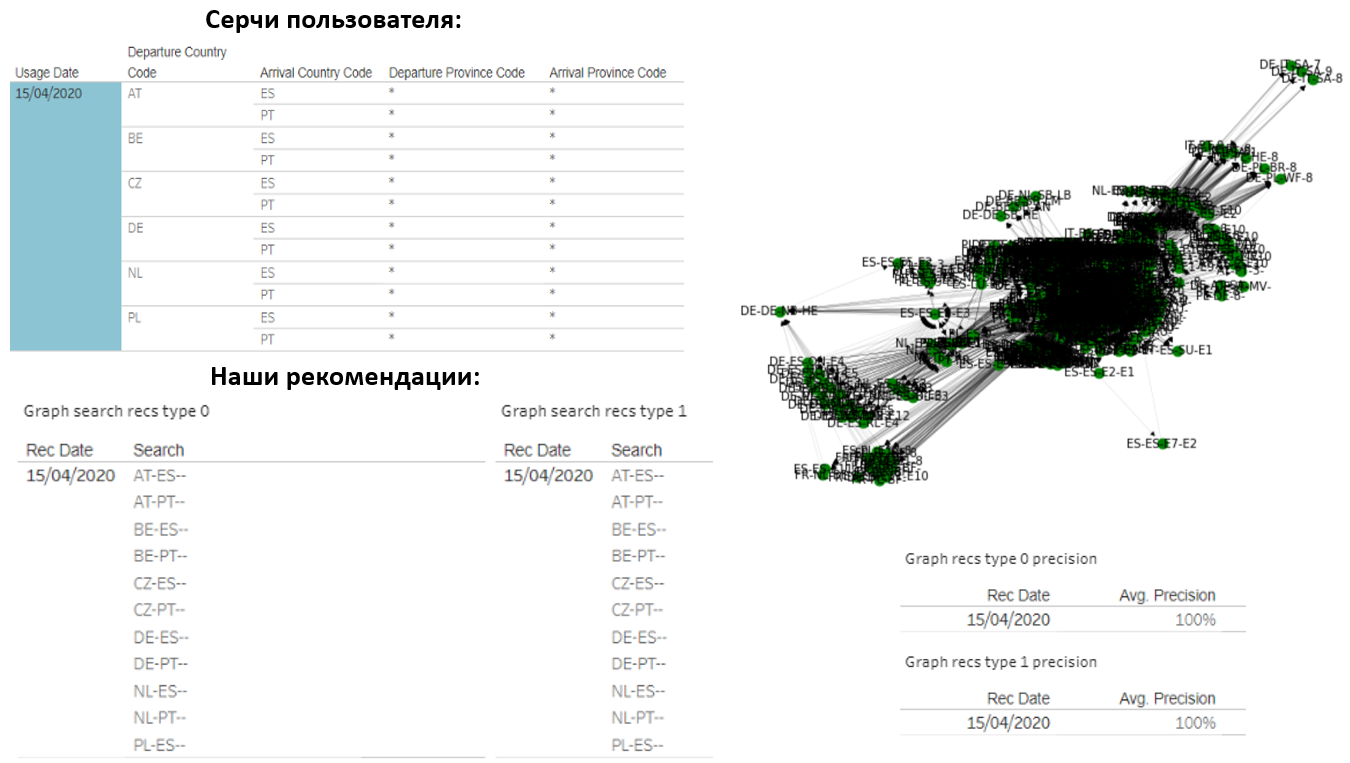
Es stellte sich heraus, dass unsere Optionen völlig mit dem übereinstimmten, wonach er suchte. Das Diagramm dieses Benutzers besteht aus ungefähr 1000 verschiedenen Abfragen, aber wir konnten sehr genau erraten, was ihn interessieren würde.
Der zweite Benutzer stellt im Durchschnitt alle 2 Tage 8 verschiedene Anfragen und sucht sowohl im Format „Land-Land“ als auch mit Angabe einer bestimmten Abflugregion. Darüber hinaus sind die Herkunfts- und Lieferländer völlig unterschiedlich. Daher konnten wir nicht alles "erraten" und die Genauigkeit der Ergebnisse stellte sich als geringer heraus:

Beachten Sie, dass der Benutzer 2 Diagramme mit unterschiedlichen Gewichten hat. In einem Fall erreichte die Genauigkeit 38%, was bedeutet, dass sich 3 von 8 von uns empfohlenen Optionen als relevant herausstellten. Und wenn wir Lasten in diesen Richtungen finden, wählt der Benutzer sie möglicherweise aus.
Das letzte und einfachste Beispiel. Eine Person macht ungefähr 2 Suchvorgänge pro Tag. Es hat sehr stabile Muster, nicht zu viele Einstellungen und ein einfaches Diagramm. Infolgedessen beträgt die Genauigkeit unserer Vorhersagen 100%.

Leistung in Fakten
- Unsere Algorithmen laufen auf 4 Standard-CPUs und 10 GB Speicher.
- Das Datenvolumen beträgt bis zu 1 Milliarde Datensätze.
- Es dauert 18 Minuten, um Empfehlungen für alle Benutzer von etwa 20.000 zu erstellen.
- Die DASK-Bibliothek wird für die Parallelisierung und die NetworkX-Bibliothek für den PageRank-Algorithmus verwendet.
Ich kann sagen, dass unsere Suchen und Experimente zu sehr guten Ergebnissen geführt haben. Die Darstellung des Verhaltens der Nutzer der Frachtbörsenplattform in Form eines Diagramms und die Verwendung von PageRank ermöglichen es uns, ihre zukünftigen Präferenzen mit hoher Genauigkeit vorherzusagen und so effektive Empfehlungssysteme aufzubauen.