
Möchte Ihr Unternehmen Daten sammeln und analysieren, um Trends zu untersuchen, ohne die Privatsphäre zu beeinträchtigen? Oder verwenden Sie bereits verschiedene Tools, um es zu bewahren, und möchten Ihr Wissen vertiefen oder Ihre Erfahrungen teilen? In jedem Fall ist dieses Material für Sie.
Was hat uns dazu veranlasst, diese Artikelserie zu starten? Das NIST (Nationales Institut für Standards und Technologie) hat im vergangenen Jahr den Privacy Engineering Collaboration Space gestartet- eine Plattform für die Zusammenarbeit, die Open-Source-Tools sowie Lösungen und Beschreibungen von Prozessen enthält, die für die Gestaltung der Vertraulichkeit von Systemen und das Risikomanagement erforderlich sind. Als Moderatoren dieses Bereichs helfen wir NIST dabei, verfügbare Tools zum Schutz der Privatsphäre im Bereich der Anonymisierung zu sammeln. NIST veröffentlichte außerdem das Privacy Framework: Ein Tool zur Verbesserung der Privatsphäre durch Enterprise Risk Management und einen Aktionsplan , in dem eine Reihe von Datenschutzbedenken, einschließlich der Anonymisierung, dargelegt werden. Jetzt möchten wir Collaboration Space dabei unterstützen, die im Plan für die Anonymisierung (Deidentifizierung) festgelegten Ziele zu erreichen. Helfen Sie NIST letztendlich dabei, diese Reihe von Veröffentlichungen zu einem ausführlicheren Leitfaden für differenzierte Privatsphäre zu entwickeln.
Jeder Artikel beginnt mit grundlegenden Konzepten und Anwendungsbeispielen, damit Fachleute - wie Geschäftsprozessverantwortliche oder Datenschutzbeauftragte - genug lernen, um gefährlich zu werden (nur ein Scherz). Nachdem wir die Grundlagen überprüft haben, werden wir die verfügbaren Tools und die darin verwendeten Ansätze analysieren, die bereits für diejenigen nützlich sind, die an bestimmten Implementierungen arbeiten.
Wir beginnen unseren ersten Artikel mit der Beschreibung der Schlüsselkonzepte und Konzepte der differenzierten Privatsphäre, die wir in den folgenden Artikeln verwenden werden.
Formulierung des Problems
Wie können Sie Bevölkerungsdaten untersuchen, ohne bestimmte Bevölkerungsmitglieder zu beeinflussen? Versuchen wir zwei Fragen zu beantworten:
- Wie viele Menschen leben in Vermont?
- Wie viele Leute namens Joe Near leben in Vermont?
Die erste Frage betrifft die Eigenschaften der gesamten Bevölkerung und die zweite enthält Informationen über eine bestimmte Person. Wir müssen in der Lage sein, Trends für die gesamte Bevölkerung herauszufinden, ohne Informationen über eine bestimmte Person zuzulassen.
Aber wie können wir die Frage beantworten, wie viele Menschen in Vermont leben? - was wir weiter "Anfrage" nennen werden - ohne die zweite Frage zu beantworten "Wie viele Menschen mit dem Namen Joe Nier leben in Vermont?" Die häufigste Lösung ist die Deidentifizierung (oder Anonymisierung), bei der alle identifizierenden Informationen aus dem Datensatz entfernt werden (im Folgenden glauben wir, dass unser Datensatz Informationen zu bestimmten Personen enthält). Ein anderer Ansatz besteht darin, aggregierte Abfragen beispielsweise nur mit einem Durchschnitt zuzulassen. Leider wissen wir jetzt bereits, dass keiner der Ansätze den notwendigen Schutz der Privatsphäre bietet. Anonymisierte Daten sind das Ziel von Angriffen, die Verbindungen zu anderen Datenbanken herstellen. Die Aggregation schützt die Privatsphäre nur, wenn die Größe der Stichprobengruppe gleich istgroß genug. Aber auch in solchen Fällen sind erfolgreiche Angriffe möglich [1, 2, 3, 4].
Differenzielle Privatsphäre
Differenzielle Privatsphäre [5, 6] ist eine mathematische Definition des Konzepts „Privatsphäre haben“. Es ist kein spezifischer Prozess, sondern eine Eigenschaft, die ein Prozess besitzen kann. Sie können beispielsweise berechnen (beweisen), dass ein bestimmter Prozess den Grundsätzen der unterschiedlichen Privatsphäre entspricht.
Einfach ausgedrückt, für jede Person, deren Daten sich in dem zu analysierenden Datensatz befinden, stellt der differenzielle Datenschutz sicher, dass das Ergebnis der differenziellen Datenschutzanalyse praktisch nicht zu unterscheiden ist, ob sich Ihre Daten im Datensatz befinden oder nicht . Die differenzierte Datenschutzanalyse wird häufig als Mechanismus bezeichnet , und wir werden sie als Mechanismus bezeichnen...
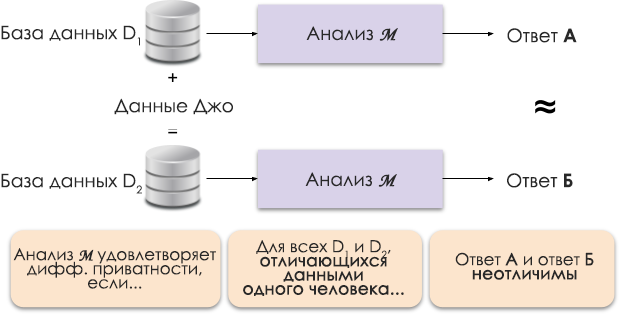
Abbildung 1: Schematische Darstellung der unterschiedlichen Privatsphäre.
Das Prinzip der unterschiedlichen Privatsphäre ist in Abbildung 1 dargestellt. Antwort A wird ohne Joes Daten berechnet und Antwort B mit seinen Daten. Und es wird argumentiert, dass beide Antworten nicht zu unterscheiden sind. Das heißt, wer sich die Ergebnisse ansieht, kann nicht sagen, in welchem Fall Joes Daten verwendet wurden und in welchem nicht.
Wir steuern das erforderliche Maß an Datenschutz, indem wir den Datenschutzparameter ε ändern, der auch als Datenschutzverlust oder Datenschutzbudget bezeichnet wird. Je kleiner der ε-Wert ist, desto weniger unterscheidbar sind die Ergebnisse und desto sicherer sind die Daten von Personen.
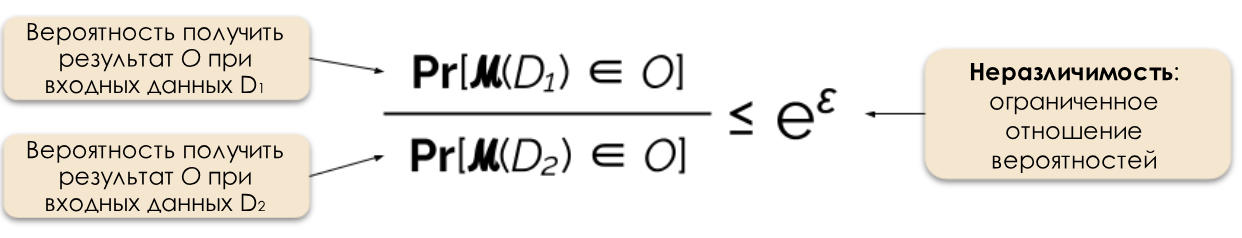
Abbildung 2: Formale Definition der unterschiedlichen Privatsphäre.
Wir können häufig auf eine Anfrage auf unterschiedliche Art und Weise antworten, indem wir der Antwort zufälliges Rauschen hinzufügen. Die Schwierigkeit besteht darin, genau zu bestimmen, wo und wie viel Lärm hinzugefügt werden soll. Einer der beliebtesten Geräuschgeräuschmechanismen ist der Laplace-Mechanismus [5, 7].
Erhöhte Datenschutzanforderungen erfordern mehr Lärm, um den spezifischen Epsilon-Wert der differenziellen Privatsphäre zu erfüllen. Und dieses zusätzliche Rauschen kann die Nützlichkeit der erhaltenen Ergebnisse verringern. In zukünftigen Artikeln werden wir detaillierter auf den Datenschutz und den Kompromiss zwischen Datenschutz und Nützlichkeit eingehen.
Vorteile der unterschiedlichen Privatsphäre
Die unterschiedliche Privatsphäre hat gegenüber früheren Techniken mehrere wichtige Vorteile.
- , , ( ) .
- , .
- : , . , . , .
Aufgrund dieser Vorteile ist die Anwendung differenzierter Datenschutzmethoden in der Praxis einigen anderen Methoden vorzuziehen. Die Kehrseite der Medaille ist, dass diese Methodik ziemlich neu ist und es nicht einfach ist, bewährte Werkzeuge, Standards und bewährte Ansätze außerhalb der akademischen Forschungsgemeinschaft zu finden. Wir glauben jedoch, dass sich die Situation in naher Zukunft aufgrund der wachsenden Nachfrage nach zuverlässigen und einfachen Lösungen zur Wahrung des Datenschutzes verbessern wird.
Was weiter?
Abonnieren Sie unseren Blog, und in Kürze werden wir die Übersetzung des nächsten Artikels veröffentlichen, in dem die Bedrohungsmodelle erläutert werden, die beim Aufbau von Systemen für differenzierte Privatsphäre berücksichtigt werden müssen, sowie die Unterschiede zwischen zentralen und lokalen Modellen für differenzielle Privatsphäre.
Quellen
[1] Garfinkel, Simson, John M. Abowd und Christian Martindale. "Grundlegendes zu Datenbankrekonstruktionsangriffen auf öffentliche Daten." Mitteilungen des ACM 62.3 (2019): 46-53.
[2] Gadotti, Andrea et al. "Wenn das Signal im Rauschen ist: Ausnutzen des klebrigen Rauschens von Diffix." 28. USENIX-Sicherheitssymposium (USENIX-Sicherheit 19). 2019.
[3] Dinur, Irit und Kobbi Nissim. "Offenlegung von Informationen unter Wahrung der Privatsphäre." Vorträge des zweiundzwanzigsten ACM SIGMOD-SIGACT-SIGART-Symposiums zu Prinzipien von Datenbanksystemen. 2003.
[4] Sweeney, Latanya. "Einfache demografische Daten identifizieren Personen häufig eindeutig." Health (San Francisco) 671 (2000): 1-34.
[5] Dwork, Cynthia et al. "Rauschen auf Empfindlichkeit bei der Analyse privater Daten kalibrieren." Konferenz zur Theorie der Kryptographie. Springer, Berlin, Heidelberg, 2006.
[6] Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O'Brien, Thomas Steinke und Salil Vadhan. « Differential Privacy: Eine Einführung für ein nicht technisches Publikum. »Vand. J. Ent. & Technik. L. 21 (2018): 209.
[7] Dwork, Cynthia und Aaron Roth. "Die algorithmischen Grundlagen der unterschiedlichen Privatsphäre." Grundlagen und Trends der Theoretischen Informatik 9, Nr. 3-4 (2014): 211 & ndash; 407.