 Vor einiger Zeit tauchte die Apache Ignite-Plattform am Horizont auf und gewann an Popularität. In-Memory-Computing ist Geschwindigkeit, was bedeutet, dass die Geschwindigkeit in allen Arbeitsphasen sichergestellt werden muss, insbesondere beim Laden von Daten.
Vor einiger Zeit tauchte die Apache Ignite-Plattform am Horizont auf und gewann an Popularität. In-Memory-Computing ist Geschwindigkeit, was bedeutet, dass die Geschwindigkeit in allen Arbeitsphasen sichergestellt werden muss, insbesondere beim Laden von Daten.
Unter dem Schnitt finden Sie eine Beschreibung einer Möglichkeit, Daten aus einer relationalen Tabelle schnell in einen verteilten Apache Ignite-Cluster zu laden. Die Vorverarbeitung der SQL-Abfrage-Ergebnismenge auf dem Clientknoten des Clusters und die Verteilung der Daten über den Cluster mithilfe der Map-Reduction-Task werden beschrieben. Beschreibt die Caches und zugehörigen relationalen Tabellen, zeigt, wie ein benutzerdefiniertes Objekt aus einer Tabellenzeile erstellt wird und wie der ComputeTaskAdapter zum schnellen Platzieren der erstellten Objekte verwendet wird. Der gesamte Code kann vollständig im FastDataLoad- Repository angezeigt werden .
Geschichte des Problems
Dieser Text ist eine Übersetzung meines Beitrags im In-Memory Computing-Blog auf der GridGain-Website ins Russische .
Ein bestimmtes Unternehmen beschließt daher, eine langsame Anwendung zu beschleunigen, indem es Computer in einen In-Memory-Cluster verlagert. Die anfänglichen Daten für Berechnungen sind in MS SQL; Das Ergebnis der Berechnungen muss dort abgelegt werden. Der Cluster ist verteilt, da bereits viele Daten vorhanden sind, die Anwendungsleistung am Limit ist und das Datenvolumen wächst. Harte Zeitlimits sind festgelegt.
Vor dem Schreiben von schnellem Code zur Datenverarbeitung müssen die Daten schnell geladen werden. Eine hektische Suche im Web zeigt einen deutlichen Mangel an Codebeispielen, die auf Tabellen mit mehreren zehn oder hundert Millionen Zeilen skaliert werden können. Beispiele, die Sie herunterladen, kompilieren und durch die Schritte beim Debuggen führen können. Dies ist einerseits.
, Apache Ignite / GridGain, . , . " ?", — , .
, .
(World Database)
, data collocation, . world.sql Apache Ignite.
CSV , — SQL :
- countryCache — country.csv;
- cityCache — city.csv;
- countryLanguageCache — countryLanguage.csv.
countryCache country.csv. countryCache — code, — String, — Country, (name, continent, region).

, — , . Country , . org.h2.tools.Csv, CSV java.sql.ResultSet. Apache Ignite , SQL H2.
// define countryCache
IgniteCache<String,Country> cache = ignite.cache("countryCache");
try (ResultSet rs = new Csv().read(csvFileName, null, null)) {
while (rs.next()) {
String code = rs.getString("Code");
String name = rs.getString("Name");
String continent = rs.getString("Continent");
Country country = new Country(code,name,continent);
cache.put(code,country);
}
}. , , . - .
, . , .
Apache Ignite — -. , PARTITIONED - (partition) . ; , . -, affinity function, , .

, :
- HashMap partition_number -> key -> Value
Map<Integer, Map<String, Country>> result = new HashMap<>(); - affinity function partition_number. cache.put() - HashMap partition_number
try (ResultSet rs = new Csv().read(csvFileName, null, null)) { while (rs.next()) { String code = rs.getString("Code"); String name = rs.getString("Name"); String continent = rs.getString("Continent"); Country country = new Country(code,name,continent); result.computeIfAbsent(affinity.partition(key), k -> new HashMap<>()).put(code,country); } }
ComputeTaskAdapter ComputeJobAdapter. ComputeJobAdapter 1024. , .
ComputeJobAdapter . , .
Compute Task,
, "ComputeTaskAdapter initiates the simplified, in-memory, map-reduce process". ComputeJobAdapter map — , . reduce — .
(RenewLocalCacheJob)
targetCache.putAll(addend);RenewLocalCacheJob partition_number .
(AbstractLoadTask)
( loader) — AbstractLoadTask. . ( ), AbstractLoadTask TargetCacheKeyType. HashMap
Map<Integer, Map<TargetCacheKeyType, BinaryObject>> result;countryCache String. . AbstractLoadTask TargetCacheKeyType, BinaryObject. , — .
BinaryObject
— . , JVM, - . class definition , JAR- . Country
IgniteCache<String, Country> countryCache;, , classpath ClassNotFound.
. — classpath, :
- JAR- ;
- classpath ;
- ;
- .
— BinaryObject () . :
-
IgniteCache<String, BinaryObject> countryCache; - Country BinaryObject (. LoadCountries.java)
Country country = new Country(code, name, .. ); BinaryObject binCountry = node.binary().toBinary(country); - HashMap, BinaryObject
Map<Integer, Map<String, BinaryObject>> result
, . , , ClassNotFoundException .
. .
Apache Ignite : .
default-config.xml — . :
- GridGain CE Installing Using ZIP Archive. 8.7.10, FastDataLoad , ;
- {gridgain}\config default-config.xml
<bean id="grid.cfg" class="org.apache.ignite.configuration.IgniteConfiguration"> <property name="peerClassLoadingEnabled" value="true"/> </bean> - , {gridgain}\bin ignite.bat. ; ;
- , . ,
[08:40:04] Topology snapshot [ver=2, locNode=d52b1db3, servers=2, clients=0, state=ACTIVE, CPUs=8, offheap=3.2GB, heap=2.0GB]
. , 8.7.25, pom.xml
<gridgain.version>8.7.25</gridgain.version>
class org.apache.ignite.spi.IgniteSpiException: Local node and remote node have different version numbers (node will not join, Ignite does not support rolling updates, so versions must be exactly the same) [locBuildVer=8.7.25, rmtBuildVer=8.7.10] , , map-reduce. — JAR-, compute task . Windows, Linux.
:
- FastDataLoad;
- ;
mvn clean package - , .
java -jar .\target\fastDataLoad.jar
main() LoadApp LoaderAgrument . map-reduce LoadCountries.
LoadCountries RenewLocalCacheJob , ( ).
#1

#2

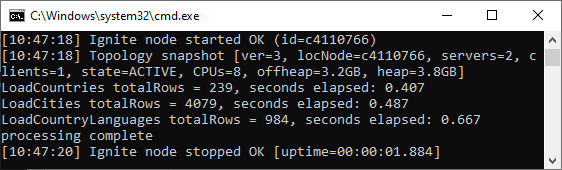
country.csv , CountryCode . cityCache countryLanguageCache; , .
.
.
:
- (SQL Server Management Studio):
- — 44 686 837;
- — 1.071 GB;
- — 0H:1M:35S;
- RenewLocalCacheJob reduce — 0H:0M:9S.
Das Verteilen von Daten über einen Cluster dauert weniger lange als das Ausführen einer SQL-Abfrage.