
Das Team investiert viel Arbeit, Mühe und Ressourcen in jede Änderung im Spiel: Manchmal dauert die Entwicklung einer neuen Funktionalität oder eines neuen Levels mehrere Monate. Die Aufgabe des Analysten besteht darin, die Risiken aus der Einführung solcher Änderungen zu minimieren und dem Team zu helfen, die richtige Entscheidung über die weitere Entwicklung des Projekts zu treffen.
Bei der Analyse von Entscheidungen ist es wichtig, sich von statistisch signifikanten Daten leiten zu lassen, die eher mit den Vorlieben des Publikums als mit intuitiven Annahmen übereinstimmen. A / B-Tests helfen, solche Daten zu erhalten und auszuwerten.
6 „einfache“ Schritte zum A / B-Testen
Für den Suchbegriff "A / B-Test" oder "Split-Test" bieten die meisten Quellen mehrere "einfache" Schritte für einen erfolgreichen Test an. Meine Strategie besteht aus sechs solchen Schritten.
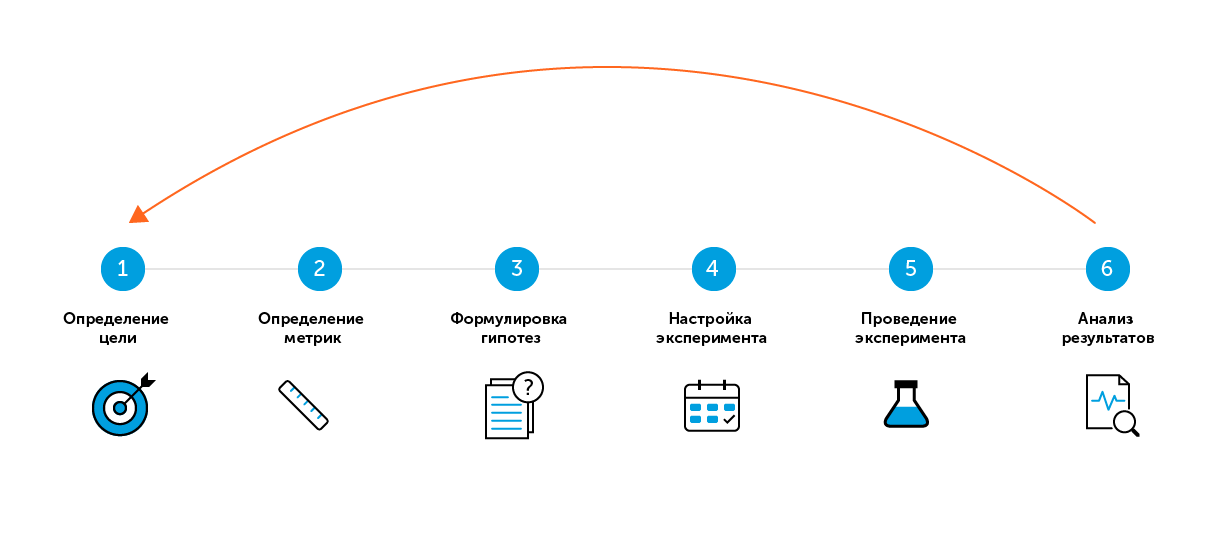
Auf den ersten Blick ist alles einfach:
- Es gibt Gruppe A, Kontrolle, keine Änderungen im Spiel.
- Es gibt einen Test der Gruppe B mit Änderungen. Zum Beispiel wurden neue Funktionen hinzugefügt, der Schwierigkeitsgrad der Level wurde erhöht, das Tutorial wurde geändert;
- Führen Sie den Test aus und sehen Sie, welche Variante eine bessere Leistung aufweist.
In der Praxis ist es schwieriger. Damit das Team die beste Lösung implementieren kann, muss ich als Analyst antworten, wie sicher ich mit den Testergebnissen bin. Lassen Sie uns Schritt für Schritt mit den Schwierigkeiten umgehen.
Schritt 1. Bestimmen Sie das Ziel
Einerseits können wir alles testen, was jedem Teammitglied in den Sinn kommt - von der Farbe der Schaltfläche bis zu den Schwierigkeitsgraden des Spiels. Die technische Fähigkeit, Split-Tests durchzuführen, wird bereits in der Entwurfsphase in unsere Produkte integriert.
Andererseits ist es wichtig, alle Vorschläge zur Verbesserung des Spiels entsprechend dem Grad der Auswirkung auf die Zielmetrik zu priorisieren. Daher erstellen wir zunächst einen Plan, um den Split-Test von der Hypothese mit der höchsten bis zur niedrigsten Priorität zu starten.
Wir versuchen, nicht mehrere A / B-Tests gleichzeitig durchzuführen, um genau zu verstehen, welche der neuen Funktionen die Zielmetrik beeinflusst haben. Es scheint, dass mit dieser Strategie mehr Zeit benötigt wird, um alle Hypothesen zu testen. Die Priorisierung hilft jedoch dabei, vielversprechende Hypothesen in der Planungsphase abzuschneiden.
Wir erhalten Daten, die die Wirkung bestimmter Änderungen maximieren, und wir verschwenden keine Zeit damit, Tests mit fragwürdigen Auswirkungen einzurichten.
Wir besprechen den Startplan definitiv mit dem Team, da sich der Fokus des Interesses in verschiedenen Phasen des Produktlebenszyklus verschiebt. Zu Beginn des Projekts ist dies normalerweise Retention D1 - der Prozentsatz der Spieler, die am nächsten Tag nach der Installation zum Spiel zurückgekehrt sind. In späteren Phasen können dies Aufbewahrungs- oder Monetarisierungsmetriken sein: Conversion, ARPU und andere.
Beispiel.Aufbewahrungsmetriken erfordern besondere Aufmerksamkeit, nachdem ein Projekt sanft gestartet wurde. Lassen Sie uns an dieser Stelle eines der möglichen Probleme hervorheben: Retention D1 erreicht nicht das Niveau der Benchmarks des Unternehmens für ein bestimmtes Spielgenre. Es ist notwendig, den Trichter des Passierens der ersten Ebenen zu analysieren. Angenommen, Sie bemerken einen großen Rückgang der Spieler zwischen dem Start und dem Abschluss der 3. Stufe - eine niedrige Abschlussrate der 3. Stufe.
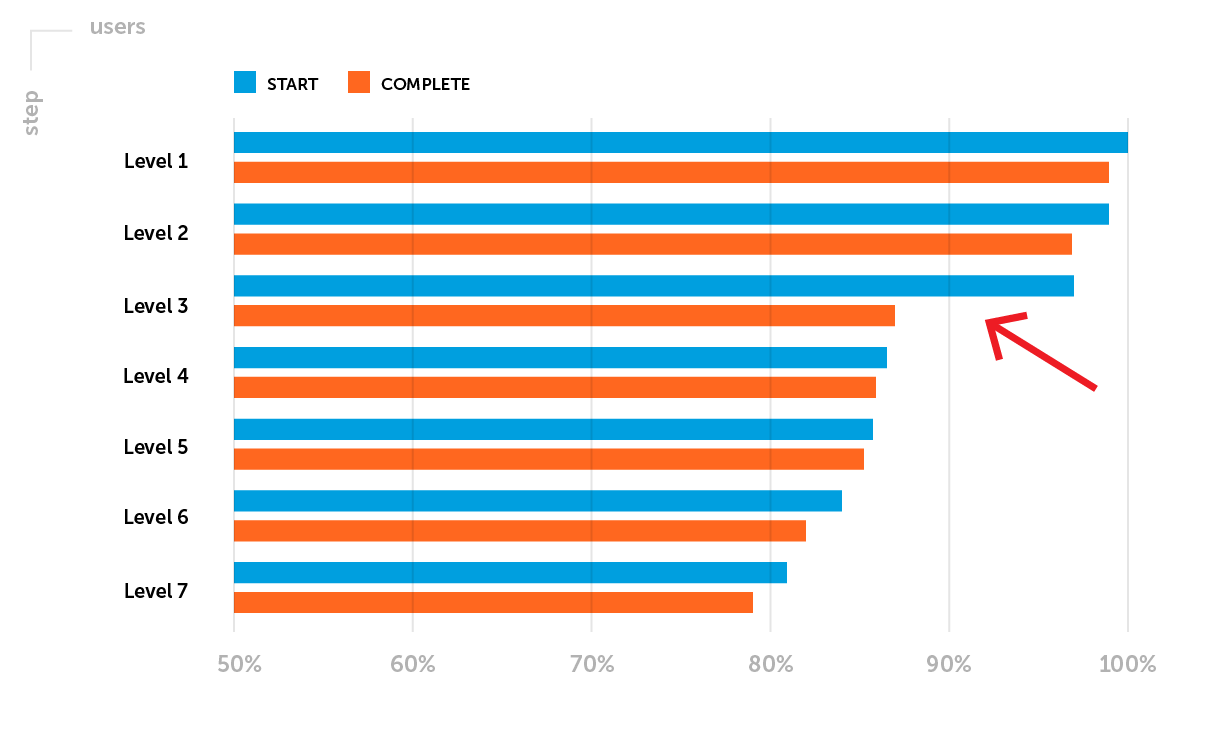
Das Ziel des geplanten A / B-Tests : Erhöhung der Retention D1 durch Erhöhung des Anteils der Spieler, die Level 3 erfolgreich abgeschlossen haben.
Schritt 2. Metriken definieren
Bevor wir mit dem A / B-Test beginnen, bestimmen wir den überwachten Parameter - wir wählen die Metrik aus, deren Änderungen zeigen, ob die neue Funktionalität des Spiels erfolgreicher ist als die ursprüngliche.
Es gibt zwei Arten von Metriken:
- quantitativ - die durchschnittliche Dauer der Sitzung, der Wert des durchschnittlichen Checks, die Zeit, die zum Abschließen des Levels benötigt wird, die Menge an Erfahrung usw.;
- hohe Qualität - Retention, Conversion Rate und andere.
Die Art der Metrik beeinflusst die Auswahl der Methode und der Werkzeuge zur Beurteilung der Signifikanz der Ergebnisse.
Es ist wahrscheinlich, dass die getestete Funktionalität nicht nur ein Ziel, sondern eine Reihe von Metriken betrifft. Daher betrachten wir Änderungen im Allgemeinen, versuchen jedoch nicht, "irgendetwas" zu finden, wenn die Bewertung der Zielmetrik keine statistische Signifikanz aufweist.
Entsprechend dem Ziel aus dem ersten Schritt werden wir für den bevorstehenden A / B-Test die Abschlussrate der 3. Stufe bewerten - eine qualitative Metrik.
Schritt 3. Formulieren Sie eine Hypothese
Jeder A / B-Test testet eine allgemeine Hypothese, die vor dem Start formuliert wird. Wir beantworten die Frage: Welche Veränderungen erwarten wir in der Testgruppe? Der Wortlaut sieht normalerweise so aus:
"Wir erwarten, dass (Auswirkungen) (Änderungen) verursachen."
Statistische Methoden funktionieren umgekehrt - wir können sie nicht verwenden, um zu beweisen, dass die Hypothese korrekt ist. Daher werden nach der Formulierung einer allgemeinen Hypothese zwei statistische ermittelt. Sie helfen zu verstehen, dass der beobachtete Unterschied zwischen Kontrollgruppe A und Testgruppe B ein Unfall oder das Ergebnis von Änderungen ist.
In unserem Beispiel:
- Nullhypothese ( H0 ): Die Verringerung der Schwierigkeit von Stufe 3 hat keinen Einfluss auf den Anteil der Benutzer, die Stufe 3 erfolgreich abgeschlossen haben. Die Abschlussrate der Stufe 3 für die Gruppen A und B ist nicht wirklich unterschiedlich und die beobachteten Unterschiede sind zufällig.
- Alternative Hypothese ( H1 ): Durch Verringern der Schwierigkeit von Stufe 3 wird der Anteil der Benutzer erhöht, die Stufe 3 erfolgreich abgeschlossen haben. Die Abschlussrate der Stufe 3 ist in Gruppe B höher als in Gruppe A, und diese Unterschiede sind das Ergebnis von Änderungen.
In diesem Stadium ist es zusätzlich zur Formulierung einer Hypothese erforderlich, den erwarteten Effekt zu bewerten.
Hypothese: "Wir erwarten, dass eine Verringerung der Komplexität der 3. Stufe zu einer Erhöhung der Abschlussrate der 3. Stufe von 85% auf 95% führt, dh um mehr als 11%."
(95% -85%) / 85% = 0,117 => 11,7%
In diesem Beispiel möchten wir bei der Bestimmung der erwarteten Abschlussrate von Stufe 3 die durchschnittliche Abschlussrate der Startstufen näher bringen.
Schritt 4. Experiment einrichten
1. Definieren Sie die Parameter für die A / B-Gruppen, bevor Sie mit dem Experiment beginnen: Für welche Zielgruppe starten wir den Test, für welchen Anteil der Spieler, welche Einstellungen stellen wir in jeder Gruppe ein.
2. Wir überprüfen die Repräsentativität der Stichprobe als Ganzes und die Homogenität der Stichproben in den Gruppen. Sie können einen A / A-Test vorab ausführen, um diese Parameter auszuwerten - einen Test, bei dem die Test- und Kontrollgruppe dieselbe Funktionalität haben. Der A / A-Test stellt sicher, dass es in beiden Gruppen keine statistisch signifikanten Unterschiede bei den Zielmetriken gibt. Wenn es Unterschiede gibt, kann ein A / B-Test mit solchen Einstellungen - Stichprobengröße und Vertrauensstufe - nicht ausgeführt werden.
Die Stichprobe wird nicht perfekt repräsentativ sein, aber wir achten immer auf die Struktur der Benutzer in Bezug auf ihre Eigenschaften - neuer / alter Benutzer, Level im Spiel, Land. Alles ist an den Zweck des A / B-Tests gebunden und wird im Voraus ausgehandelt. Es ist wichtig, dass die Struktur der Benutzer in jeder Gruppe bedingt gleich ist.
Hier gibt es zwei potenziell gefährliche Fallen:
- Hohe Metriken in Gruppen während eines Experiments können eine Folge der Gewinnung von gutem Verkehr sein. Der Verkehr ist gut, wenn die Engagement-Raten hoch sind. Schlechter Verkehr ist die häufigste Ursache für sinkende Metriken.
- Probenheterogenität. Angenommen, das Projekt aus unserem Beispiel wird für ein englischsprachiges Publikum entwickelt. Dies bedeutet, dass wir eine Situation vermeiden müssen, in der mehr Benutzer aus Ländern, in denen Englisch nicht die vorherrschende Sprache ist, in eine der Gruppen fallen.
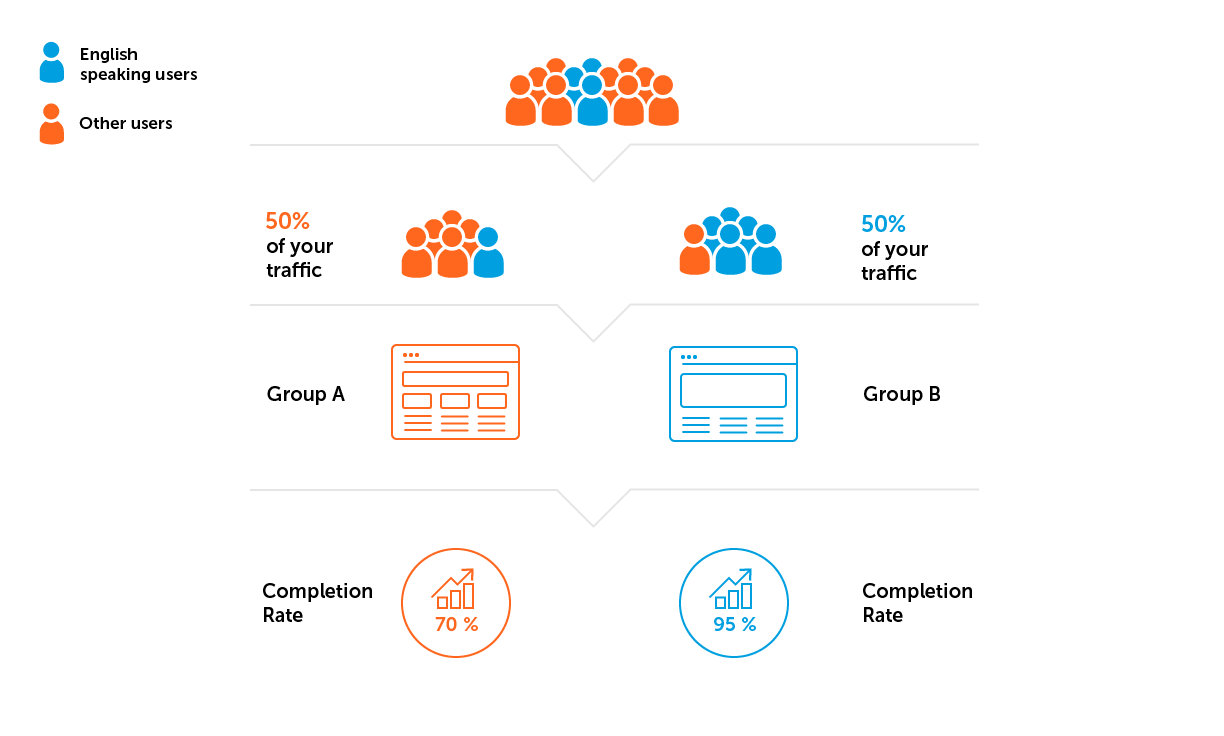
3. Berechnen Sie die Probengröße und die Dauer des Experiments.
Es scheint, dass der Moment transparent ist, wenn man die riesigen Online-Rechner berücksichtigt.
Ihre Verwendung erfordert jedoch die Eingabe spezifischer Anfangsinformationen. Um die geeignete Option für einen Online-Rechner auszuwählen, denken Sie an Datentypen und verstehen Sie die folgenden Begriffe.
- Allgemeinbevölkerung - alle Benutzer, an die die Schlussfolgerungen des A / B-Tests in Zukunft verteilt werden.
- Beispiel - Benutzer, die tatsächlich getestet werden. Basierend auf den Ergebnissen der Analyse der Stichprobe werden Schlussfolgerungen über das Verhalten der gesamten Allgemeinbevölkerung gezogen.
- , . — , , , .
- , . .
- (α) — , (0), .
- (1-α) — , , .
- (1-β) — , , .
Durch die Kombination dieser Parameter können Sie die erforderliche Stichprobengröße in jeder Gruppe und die Dauer des Tests berechnen.
In einem Online-Rechner können Sie mit den Eingabedaten spielen, um die Art ihrer Beziehungen zu verstehen.
Ein Beispiel . Verwenden Sie den Optimizely- Rechner, um die Stichprobengröße für eine Conversion-Rate von 1% zu berechnen. Beachten Sie, dass die geschätzte Effektgröße bei einem Konfidenzniveau von 95% 5% beträgt (der Indikator wird als 1-α berechnet). Bitte beachten Sie, dass in der Benutzeroberfläche dieses Rechners der Begriff statistische Signifikanz verwendet wird , um „Konfidenzniveau“ bei einem Signifikanzniveau von 5% zu bedeuten.
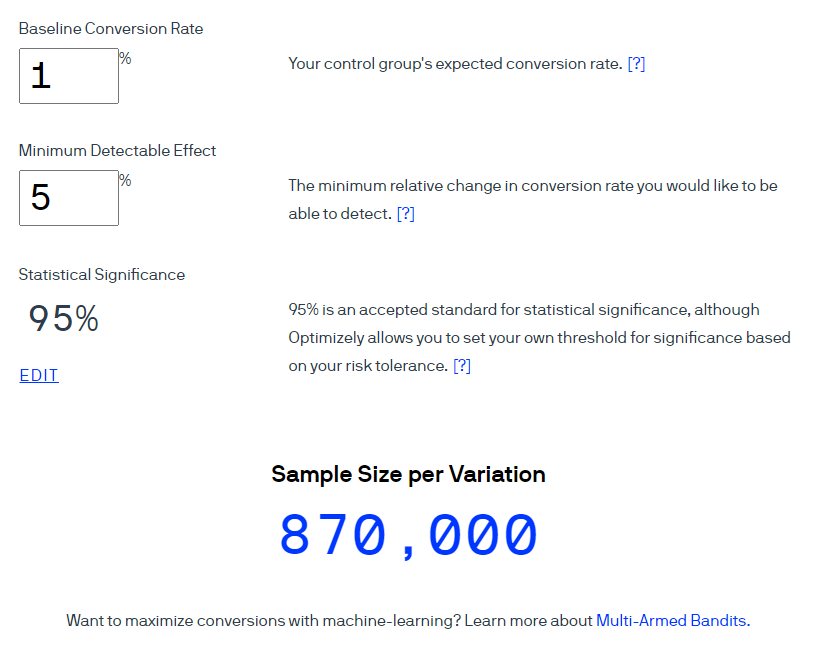
Optimizely behauptet, dass 870.000 Benutzer in jeder Gruppe enthalten sein sollten.
Umrechnung der Stichprobengröße in die ungefähre Testdauer - zwei einfache Berechnungen.
Berechnung Nr. 1. Stichprobengröße × Anzahl der Gruppen im Experiment = Gesamtzahl der erforderlichen Benutzer
Berechnung Nr. 2. Gesamtzahl der erforderlichen Benutzer ÷ durchschnittliche Anzahl der Benutzer pro Tag = ungefähre Anzahl der Tage des Experiments
Wenn die erste Gruppe 870.000 Benutzer benötigt, dann für den Test von zwei Optionen die Gesamtzahl Die Anzahl der Benutzer beträgt 1.740.000. Unter Berücksichtigung des Datenverkehrs von 1.000 Spielern pro Tag sollte der Test 1.740 Tage dauern. Diese Dauer ist nicht gerechtfertigt. In diesem Stadium überarbeiten wir normalerweise die Hypothese, die Basisdaten und die Angemessenheit des Tests.
In unserem Beispiel mit einer Verbesserung der Stufe 3 ist die Konvertierung der Anteil derjenigen, die die Stufe 3 erfolgreich abgeschlossen haben. Das heißt, die Conversion-Rate beträgt 85%. Wir möchten diesen Indikator um mindestens 11% erhöhen. Bei einem Vertrauensniveau von 95% erhalten wir 130 Benutzer pro Gruppe.

Bei gleichem Verkehrsaufkommen von 1000 Benutzern kann der Test grob gesagt in weniger als einem Tag abgeschlossen werden. Diese Schlussfolgerung ist grundsätzlich falsch, da sie die wöchentliche Saisonalität nicht berücksichtigt. Das Benutzerverhalten ist an verschiedenen Wochentagen unterschiedlich, z. B. kann es sich an Feiertagen ändern. Und in einigen Projekten ist dieser Einfluss sehr stark, in anderen kaum spürbar. Dies ist nicht in allen Projekten und nicht für alle Tests eine notwendige Bedingung, aber bei Projekten, mit denen ich gearbeitet habe, wurde immer eine wöchentliche Saisonalität im KPI beobachtet.
Daher runden wir die Testdauer auf Wochen, um die Saisonalität zu berücksichtigen. Je nach Art des A / B-Tests beträgt unser Testzyklus häufiger ein bis zwei Wochen.
Schritt 5. Experiment durchführen
Nachdem Sie einen A / B-Test gestartet haben, möchten Sie sich sofort die Ergebnisse ansehen. Die meisten Quellen verbieten dies jedoch strikt, um das Peeking-Problem zu beseitigen. Meiner Meinung nach ist es bisher niemandem gelungen, das Wesentliche des Problems in einfachen Worten zu erklären. Die Autoren solcher Artikel stützen ihre Beweise auf die Bewertung von Wahrscheinlichkeiten, verschiedene Ergebnisse der mathematischen Modellierung, die den Leser in die Zone "komplexer mathematischer Formeln" führen. Ihre wichtigste Schlussfolgerung ist eine fast unbestreitbare Tatsache: Sehen Sie sich die Daten nicht an, bevor die erforderliche Probe eingegeben wurde und die erforderliche Anzahl von Tagen nach Beginn des Tests vergangen ist. Infolgedessen interpretieren viele Menschen das Problem des "Guckens" falsch und folgen den Empfehlungen wörtlich.
Wir haben die Prozesse so eingerichtet, dass wir täglich aktuelle Daten für die Überwachung von KPI-Projekten sehen können. In vorbereiteten Dashboards verfolgen wir den Fortschritt des Experiments von Anfang an: Wir prüfen, ob die Gruppen gleichmäßig rekrutiert werden, ob nach dem Start des Tests kritische Probleme auftreten, die sich auf die Ergebnisse auswirken können, und so weiter.
Die Hauptregel besteht darin, keine vorzeitigen Schlussfolgerungen zu ziehen. Alle Schlussfolgerungen werden gemäß dem festgelegten Design des A / B-Tests formuliert und in einem detaillierten Bericht zusammengefasst. Wir haben Änderungen im Indikator seit dem Start des A / B-Tests überwacht.
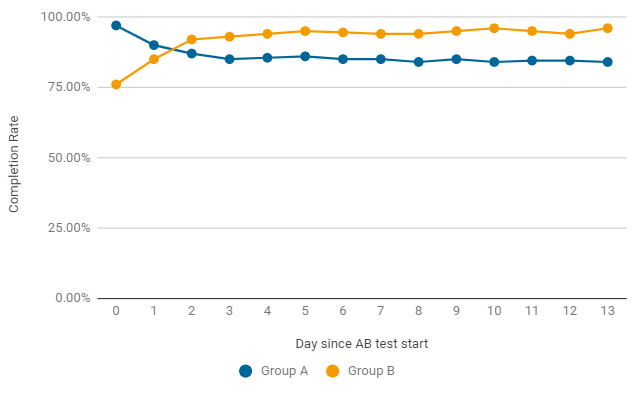
In einem Beispiel wie im A / B-Test kann sich die Abschlussrate von Tag zu Tag ändern.In den ersten zwei Tagen nach dem Start gewann die Spielversion ohne Änderungen (Gruppe A), aber dies war nur ein Unfall. Bereits nach dem zweiten Tag erzielt der Indikator in Gruppe B durchweg bessere Ergebnisse. Um den Test abzuschließen, ist nicht nur statistische Signifikanz, sondern auch Stabilität erforderlich. Wir warten also auf das Ende des Tests.
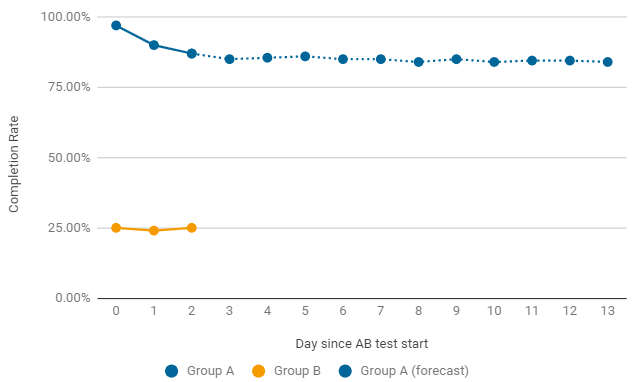
Ein Beispiel dafür, wann es sich lohnt, einen A / B-Test vorzeitig zu beenden. Wenn eine der Gruppen nach dem Start kritisch niedrige Raten angibt, suchen wir sofort nach den Gründen für einen solchen Rückgang. Die häufigsten Fehler sind in der Konfiguration und den Einstellungen des Spiellevels. In diesem Fall wird der aktuelle Test vorzeitig beendet und ein neuer Test mit Korrekturen gestartet.
Schritt 6. Analyse der Ergebnisse
Die Berechnung der wichtigsten Metriken ist nicht besonders schwierig, aber die Beurteilung der Signifikanz der erzielten Ergebnisse ist ein separates Problem.
Online-Rechner können verwendet werden, um die statistische Signifikanz von Ergebnissen bei der Bewertung von Qualitätsmetriken wie Aufbewahrung und Konvertierung zu testen.
Meine Top 3 Online-Rechner für Aufgaben wie diese:
- Evans Awesome A / B Tools ist eines der beliebtesten. Es werden verschiedene Methoden zur Beurteilung der Signifikanz eines Tests implementiert. Bei der Verwendung müssen Sie die Essenz jedes eingegebenen Parameters klar verstehen, die Ergebnisse unabhängig interpretieren und Schlussfolgerungen formulieren.
- , A/B Testguide. , . — , .
- A/B Testing Calculator Neilpatel. -, .
Ein Beispiel . Um solche A / B-Tests zu analysieren, verfügen wir über ein Dashboard, das alle Informationen anzeigt, die zum Ziehen von Schlussfolgerungen erforderlich sind, und das Ergebnis automatisch mit einer signifikanten Änderung des Ziels hervorhebt.

Lassen Sie uns sehen, wie Sie mithilfe von Taschenrechnern Schlussfolgerungen zu diesem A / B-Test ziehen können.
Ausgangsdaten:
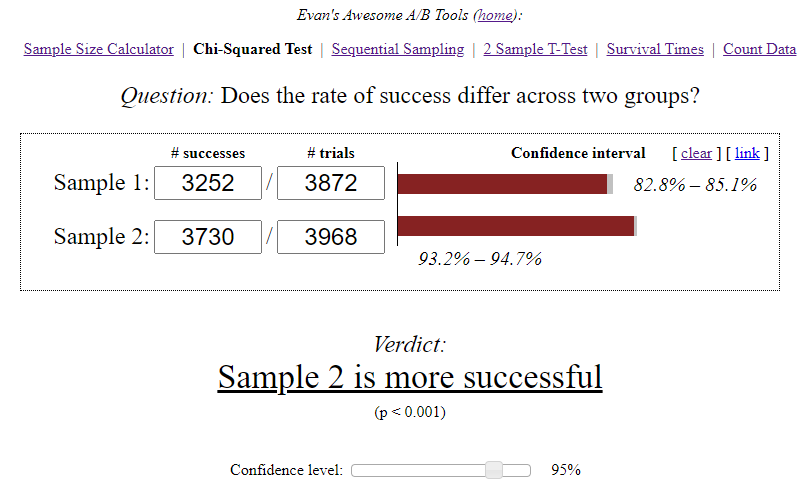
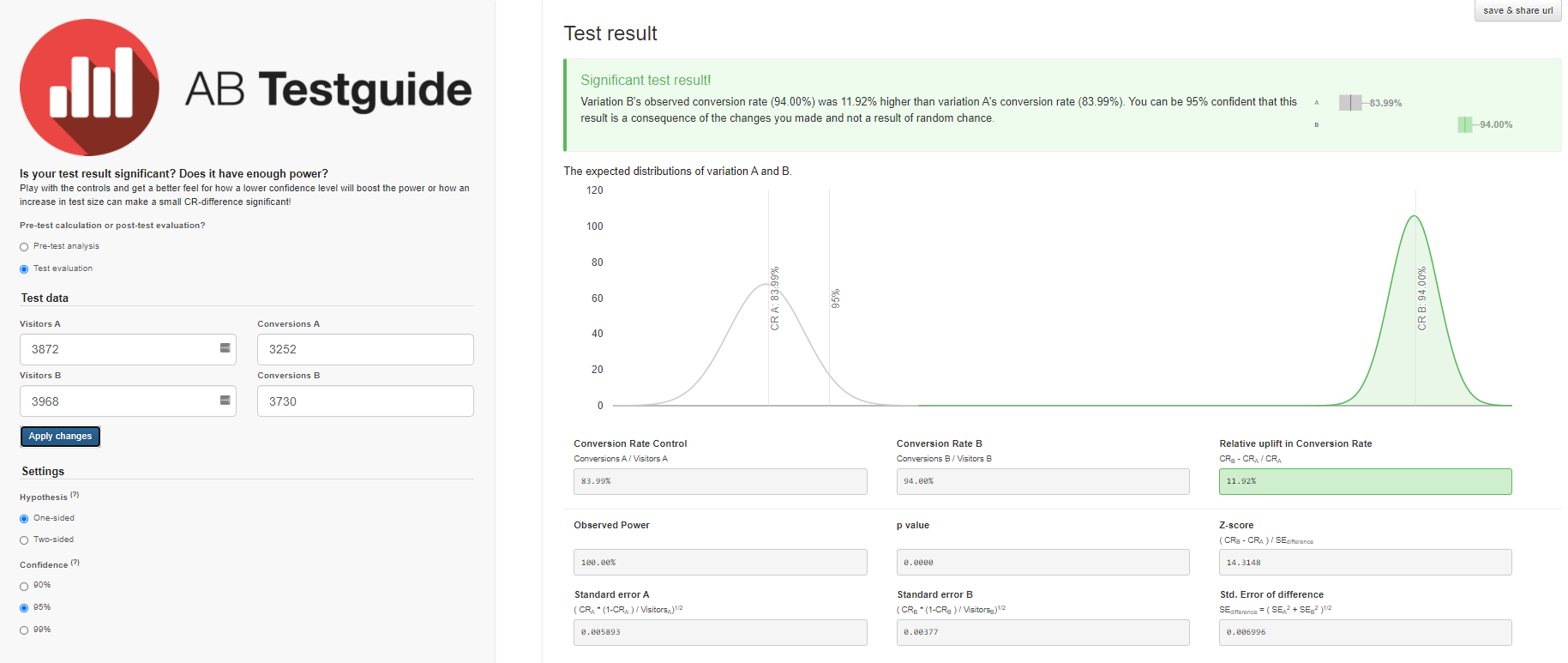
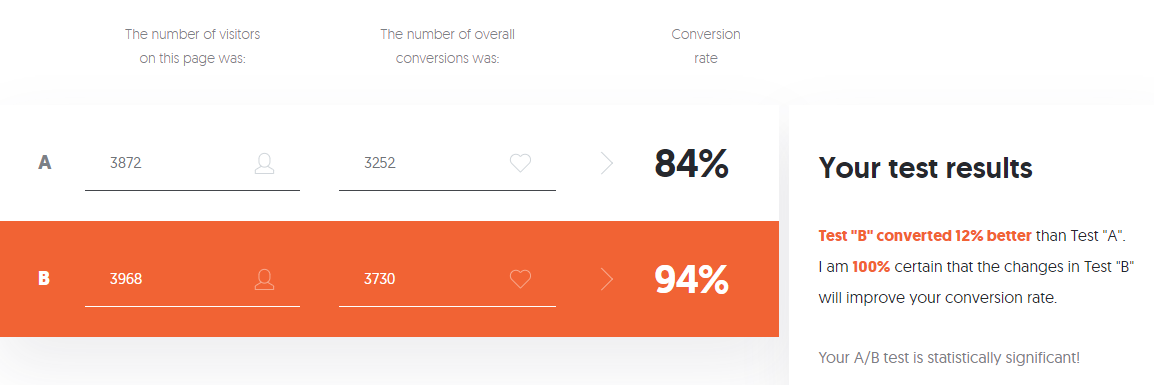
- In Gruppe A haben von 3870 Benutzern, die Stufe 3 gestartet haben, nur 3252 Benutzer diese erfolgreich bestanden - das sind 84%.
- In Gruppe B haben 3730 von 3968 Benutzern das Level erfolgreich bestanden - das sind 94%.
Der Awesome A / B Tools-Rechner von Evan berechnete das Konfidenzintervall für jede Option unter Berücksichtigung der Stichprobengröße und des ausgewählten Signifikanzniveaus.
Unabhängige Schlussfolgerungen:
- A — 84,00%, 82,8%—85,1%. B — 94,00%, 93,2%—94,7%. (94%-84%)/84% = 0,119 => 12%
- 12% , A. — , . 95%.
- .
Wir werden ähnliche Ergebnisse mit dem A / B Testguide-Rechner erhalten . Aber hier können Sie bereits mit den Einstellungen spielen, ein grafisches Ergebnis erhalten und Schlussfolgerungen formulieren.
Wenn Sie Angst vor so vielen Einstellungen haben, keine Lust haben oder mit der Vielfalt der vom Taschenrechner berechneten Daten umgehen müssen, können Sie den A / B-Testrechner von Neilpatel verwenden .
Jeder Online-Rechner hat seine eigenen Kriterien und Algorithmen, die möglicherweise nicht alle Merkmale des Experiments berücksichtigen. Infolgedessen ergeben sich Fragen und Zweifel bei der Interpretation der Ergebnisse. Wenn die Zielmetrik quantitativ ist - durchschnittliche Prüfung oder durchschnittliche Länge der ersten Sitzung -, sind die aufgeführten Online-Rechner nicht mehr anwendbar und es sind fortgeschrittenere Bewertungsmethoden erforderlich.
Ich erstelle einen detaillierten Bericht über jeden A / B-Test, daher habe ich Methoden und Kriterien ausgewählt und implementiert, die für meine Aufgaben geeignet sind, um die statistische Signifikanz der Ergebnisse zu bewerten.
Fazit
Der A / B-Test ist ein Tool, das die Frage "Welche Option ist besser?" Nicht eindeutig beantwortet, sondern nur die Unsicherheit auf dem Weg zu optimalen Lösungen verringert. Bei der Durchführung sind die Details in allen Phasen der Vorbereitung wichtig. Jede Ungenauigkeit kostet Ressourcen und kann die Zuverlässigkeit der Ergebnisse beeinträchtigen. Ich hoffe, dieser Artikel war hilfreich für Sie und hilft Ihnen, Fehler bei A / B-Tests zu vermeiden.