
URALCHEM stellt Düngemittel her. Nr. 1 in Russland - für die Herstellung von Ammoniumnitrat zum Beispiel gehört zu den Top 3 der einheimischen Hersteller von Ammoniak, Harnstoff und Stickstoffdüngern. Es entstehen Schwefelsäuren, Zwei-Drei-Komponenten-Düngemittel, Phosphate und vieles mehr. All dies schafft aggressive Umgebungen, in denen Sensoren ausfallen.
Wir haben Data Lake gebaut und gleichzeitig nach Sensoren gesucht, die einfrieren, ausfallen, falsche Daten liefern und sich im Allgemeinen anders verhalten, als sich Informationsquellen verhalten sollten. Und der "Trick" ist, dass es unmöglich ist, mathematische Modelle und digitale Zwillinge auf der Grundlage "schlechter" Daten zu erstellen: Sie werden das Problem einfach nicht richtig lösen und einen Geschäftseffekt erzielen.
Moderne Fabriken benötigen jedoch Data Lake für Datenwissenschaftler. In 95% der Fälle werden "Rohdaten" in keiner Weise erfasst, sondern nur Aggregate im Prozessleitsystem berücksichtigt, die zwei Monate gespeichert werden, und die Punkte der "Änderung der Dynamik" des Indikators werden gespeichert, die durch einen speziell festgelegten Algorithmus berechnet werden, der für Datenwissenschaftler die Qualität der Daten verringert, weil Vielleicht verpassen die "Bursts" des Indikators ... Eigentlich war so etwas bei URALCHEM. Es war notwendig, ein Lager mit Produktionsdaten zu erstellen, die Quellen in den Läden und in MES / ERP-Systemen abzuholen. Dies ist zunächst erforderlich, um mit dem Sammeln von Geschichte für die Datenwissenschaft zu beginnen. Zweitens, damit Datenwissenschaftler eine Plattform für ihre Berechnungen und eine Sandbox zum Testen von Hypothesen haben und nicht dieselbe laden, auf der sich das Prozessleitsystem dreht.Datenwissenschaftler versuchten, die verfügbaren Daten zu analysieren, was jedoch nicht ausreichte. Die Daten wurden dezimiert mit Verlusten gespeichert, die häufig nicht mit dem Sensor übereinstimmen. Es war nicht möglich, einen Datensatz schnell aufzunehmen, und es gab auch keinen Ort, an dem man damit arbeiten konnte.
Kommen wir nun zu dem zurück, was zu tun ist, wenn der Sensor "fährt".
Wenn Sie einen See bauen
Es reicht nicht aus, nur so etwas zu bauen:
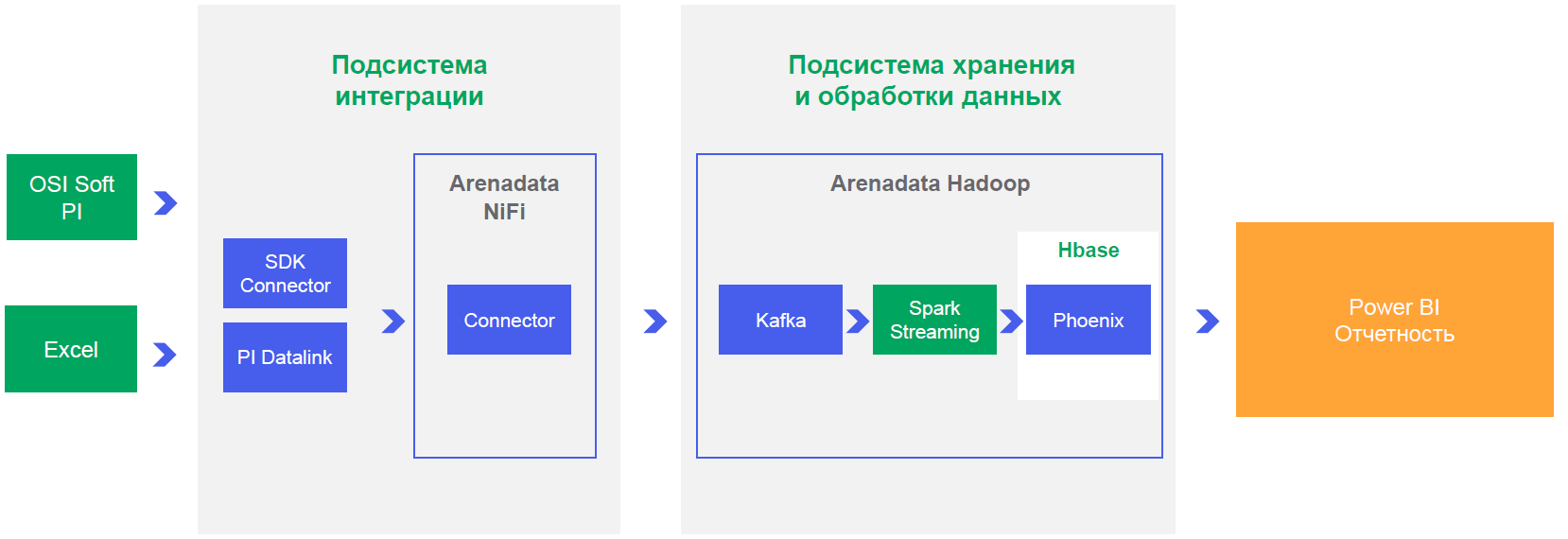
Sie müssen dem Unternehmen auch beweisen, dass alles funktioniert, und ein Beispiel für ein abgeschlossenes Projekt zeigen. Es ist klar, dass es bei einem Projekt für einen solchen Mähdrescher darum geht, den Kommunismus in einem einzigen Land aufzubauen, aber die Bedingungen sind genau das. Wir nehmen ein Mikroskop und beweisen, dass sie einen Nagel einschlagen können.
URALCHEM hat weltweit die Aufgabe, die Produktion zu digitalisieren. Erstellen Sie im Rahmen all dieser Maßnahmen zunächst eine Sandbox zum Testen von Hypothesen, erhöhen Sie die Effizienz des Produktionsprozesses, entwickeln Sie Vorhersagemodelle für Geräteausfälle und Entscheidungsunterstützungssysteme und reduzieren Sie so die Anzahl der Ausfallzeiten und verbessern Sie die Qualität der Produktionsprozesse. Dies ist der Zeitpunkt, an dem Sie im Voraus wissen, dass etwas ausfallen wird, und Sie können es eine Woche vor Beginn der Zerstörung der Maschine reparieren. Nutzen - Reduzierung der Produktionskosten und Verbesserung der Produktqualität.
So erschienen die Kriterien für die Plattform und die grundlegenden Anforderungen für den Piloten: Speichern einer großen Menge an Informationen, sofortiger Zugriff auf Daten aus Business Intelligence-Systemen, Berechnungen nahezu in Echtzeit, um Empfehlungen oder Benachrichtigungen so schnell wie möglich herauszugeben.
Wir haben die Integrationsoptionen ausgearbeitet und festgestellt, dass Sie für die Leistung und den Betrieb im NRT-Modus nur Ihren Connector durcharbeiten müssen, der Daten zu Kafka hinzufügt (einem horizontal skalierbaren Nachrichtenbroker, mit dem Sie das Ereignis der Änderung des Sensorwerts "abonnieren" können und auf dessen Grundlage dieses Ereignisses im laufenden Betrieb, um Berechnungen durchzuführen und Benachrichtigungen zu generieren). Artur Khismatullin, der Leiter der Abteilung für die Entwicklung von Produktionssystemen, eine Niederlassung von OTSO, URALCHEM JSC, hat uns übrigens sehr geholfen.
Was wird zum Beispiel benötigt, um ein Vorhersagemodell für Geräteausfälle zu erstellen?
Dies erfordert Telemetrie von jedem Knoten in Echtzeit oder in Schichten in der Nähe. Das heißt, nicht einmal pro Stunde ein allgemeiner Status, sondern direkt spezifische Messwerte aller Sensoren für jede Sekunde.
Niemand sammelt oder speichert diese Daten. Darüber hinaus benötigen wir historische Daten für mindestens sechs Monate, und im Prozessleitsystem werden sie, wie gesagt, maximal für die letzten drei Monate gespeichert. Das heißt, Sie müssen mit der Tatsache beginnen, dass Daten von irgendwoher gesammelt, irgendwo geschrieben und irgendwo gespeichert werden. Daten von ca. 10 GB pro Knoten und Jahr.
Außerdem müssen Sie irgendwie mit diesen Daten arbeiten. Dies erfordert eine Installation, mit der Sie normalerweise eine Auswahl aus der Datenbank treffen können. Und es ist wünschenswert, dass bei komplexen Join'ah nicht alles für einen Tag aufsteht. Besonders später, wenn die Produktion beginnt, mehr Probleme bei der Vorhersage der Ehe hinzuzufügen. Nun, auch für vorausschauende Reparaturen, ein abendlicher Bericht, dass die Maschine ausfallen könnte, wenn sie vor einer halben Stunde ausfällt - so lala Fall.
Infolgedessen wird der See für Datenwissenschaftler benötigt.
Im Gegensatz zu anderen ähnlichen Lösungen hatten wir bei Hadoop immer noch die Aufgabe, in Echtzeit zu arbeiten. Denn die nächsten großen Aufgaben sind Daten zur Materialzusammensetzung, Analyse der Stoffqualität, Materialverbrauch der Produktion.
Als wir die Plattform selbst bauten, wollte das Unternehmen als nächstes, dass wir Daten über den Ausfall von Sensoren sammeln und ein System aufbauen, mit dem wir Mitarbeiter schicken können, um sie zu ändern oder zu warten. Und markiert gleichzeitig das Zeugnis von ihnen als falsch in der Geschichte.
Sensoren
In der Produktion - einer aggressiven Umgebung - arbeiten die Sensoren kompliziert und fallen häufig aus. Idealerweise wird auch ein prädiktives Überwachungssystem für Sensoren benötigt, aber zunächst zumindest Bewertungen, welche lügen und welche nicht.
Es stellte sich heraus, dass selbst ein einfaches Modell zur Bestimmung des vorhandenen Sensors für eine andere Aufgabe von entscheidender Bedeutung ist - die Erstellung eines mathematischen Gleichgewichts. Richtige Planung des Prozesses - wie viel und was muss investiert werden, wie wird es erhitzt, wie wird es verarbeitet? Wenn die Planung falsch ist, ist nicht klar, wie viel Rohmaterial benötigt wird. Es werden nicht genügend Produkte produziert - das Unternehmen wird keinen Gewinn erzielen. Wenn es mehr als nötig gibt - wieder ein Verlust, weil Sie speichern müssen. Die richtige Materialbilanz kann nur aus den richtigen Informationen der Sensoren ermittelt werden.
In unserem Pilotprojekt wurde daher die Überwachung der Produktionsdatenqualität gewählt.
Wir haben uns mit den Technologen nach den "Rohdaten" zusammengesetzt und uns die bestätigten Geräteausfälle angesehen. Die ersten beiden Gründe sind sehr einfach.
Hier zeigt der Sensor plötzlich Daten an, die im Prinzip nicht sein sollten:
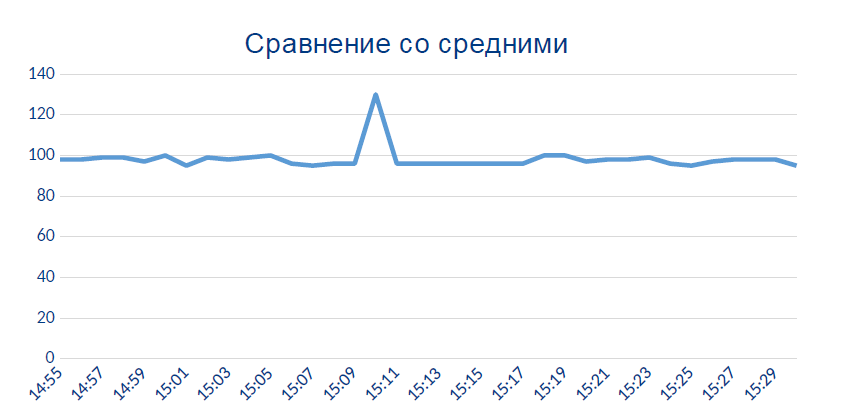
Höchstwahrscheinlich ist dieser lokale Peak der Moment, in dem der Sensor thermisch oder chemisch schlecht wurde.
Es werden auch die zulässigen Messgrenzen überschritten (wenn eine physikalische Größe wie die Wassertemperatur von 0 bis 100 vorliegt). Bei Null bewegt sich kein Wasser durch das System, und bei 200 ist es Dampf, und wir hätten diese Tatsache durch das Fehlen eines Daches über der Werkstatt bemerkt.
Der zweite Fall ist ebenfalls fast trivial: Die
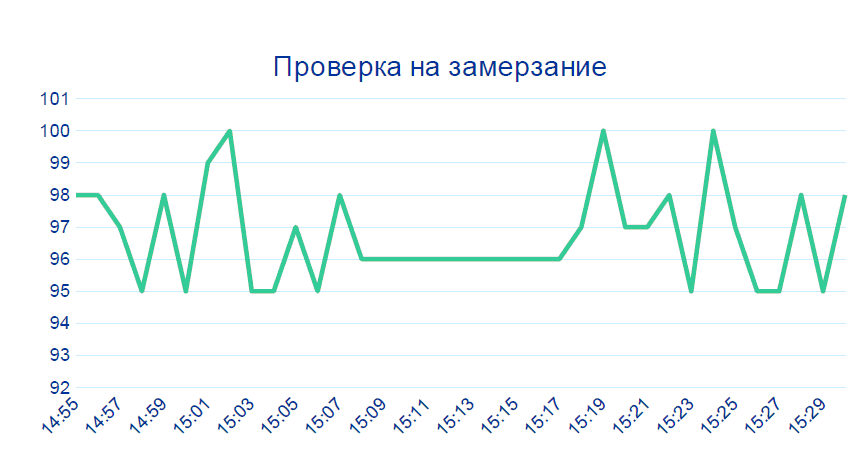
Daten vom Sensor ändern sich mehrere Minuten hintereinander nicht - dies geschieht nicht in einer Live-Produktion. Höchstwahrscheinlich etwas mit dem Gerät.
80% der Probleme werden geschlossen, indem diese Muster ohne Big Data, Korrelationen und Datenverlauf verfolgt werden. Für eine Genauigkeit von mehr als 99% müssen wir jedoch einen weiteren Vergleich mit anderen Sensoren an benachbarten Knoten hinzufügen, insbesondere vor und nach dem Abschnitt, aus dem die zweifelhafte Telemetrie stammt: Die
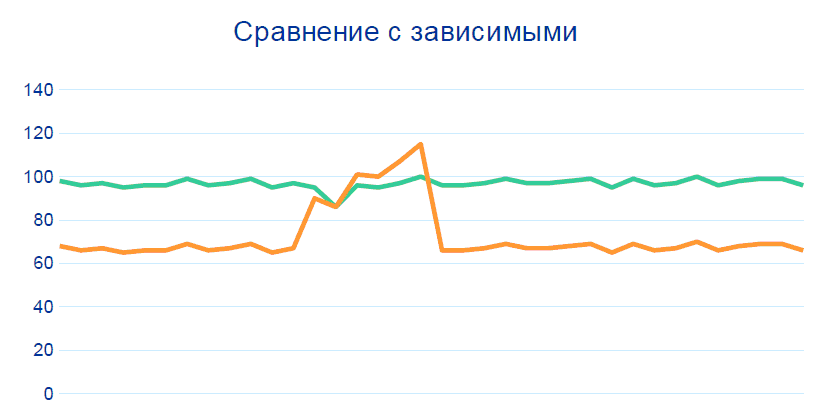
Produktion ist ein ausgeglichenes System: Wenn sich ein Indikator ändert, muss sich auch der andere ändern. Im Rahmen des Projekts wurden Regeln für die Beziehung von Indikatoren gebildet, und diese Beziehungen wurden von Technologen "normalisiert". Basierend auf diesen Richtlinien kann ein Hadoop-basiertes System potenziell funktionsunfähige Sensoren identifizieren.
Die Anlagenbetreiber waren erfreut darüber, dass die Sensoren korrekt erkannt wurden, da sie schnell eine Reparaturwerkstatt entsenden oder einfach den gewünschten Sensor reinigen konnten.
Tatsächlich listete der Pilot möglicherweise nicht funktionsfähige Sensoren im Shop auf, die falsche Informationen anzeigen.
Sie können sich fragen, wie die Reaktion auf Notfall- und Vor-Notfall-Bedingungen zuvor implementiert wurde und wie sie nach dem Projekt wurde. Ich werde antworten, dass sich die Reaktion auf einen Unfall nicht verlangsamt, da in einer solchen Situation mehrere Sensoren das Problem gleichzeitig anzeigen.
Entweder der Technologe oder der Abteilungsleiter ist für die Effizienz der Installation (und die Maßnahmen bei Unfällen) verantwortlich. Sie verstehen genau, was und wie mit ihren Geräten geschieht, und wissen, wie sie einige der Sensoren ignorieren können. Die der Installation beiliegenden Prozessleitsysteme sind für die Qualität der Daten verantwortlich. In einer normalen Situation wird der Sensor nicht beschädigt, wenn er beschädigt ist. Für den Technologen bleibt er ein Arbeiter, der Technologe muss reagieren. Der Technologe überprüft das Ereignis und stellt fest, dass nichts passiert ist. Es sieht so aus: "Wir analysieren nur die Dynamik, wir betrachten nicht das Absolute, wir wissen, dass sie falsch sind, wir müssen den Sensor anpassen." Wir "weisen" die Spezialisten des automatisierten Prozessleitsystems darauf hin, dass der Sensor falsch ist und wo er falsch ist. Anstelle einer geplanten offiziellen Runde repariert er jetzt zuerst bestimmte Geräte gezielt und macht dann Runden, ohne der Technologie zu vertrauen.
Um klarer zu machen, wie lange ein geplanter Spaziergang dauert, möchte ich einfach sagen, dass sich an jedem Standort drei bis fünftausend Sensoren befinden. Wir haben ein umfassendes Analysetool bereitgestellt, das verarbeitete Daten bereitstellt, auf deren Grundlage ein Spezialist eine Entscheidung über die Überprüfung treffen muss. Basierend auf seiner Erfahrung „heben“ wir genau das hervor, was benötigt wird. Sie müssen nicht mehr jeden Sensor manuell überprüfen, und die Wahrscheinlichkeit, dass etwas übersehen wird, wird verringert.
Was ist das Ergebnis
Erhaltene Geschäftsbestätigung, dass der Stapel zur Lösung von Produktionsproblemen verwendet werden kann. Wir speichern und verarbeiten Standortdaten. Das Unternehmen muss nun die folgenden Prozesse auswählen, damit Datenwissenschaftler arbeiten können. Während sie eine Person ernennen, die für die Datenqualitätskontrolle verantwortlich ist, schreiben Sie Vorschriften für sie und implementieren diese in ihren Produktionsprozess.
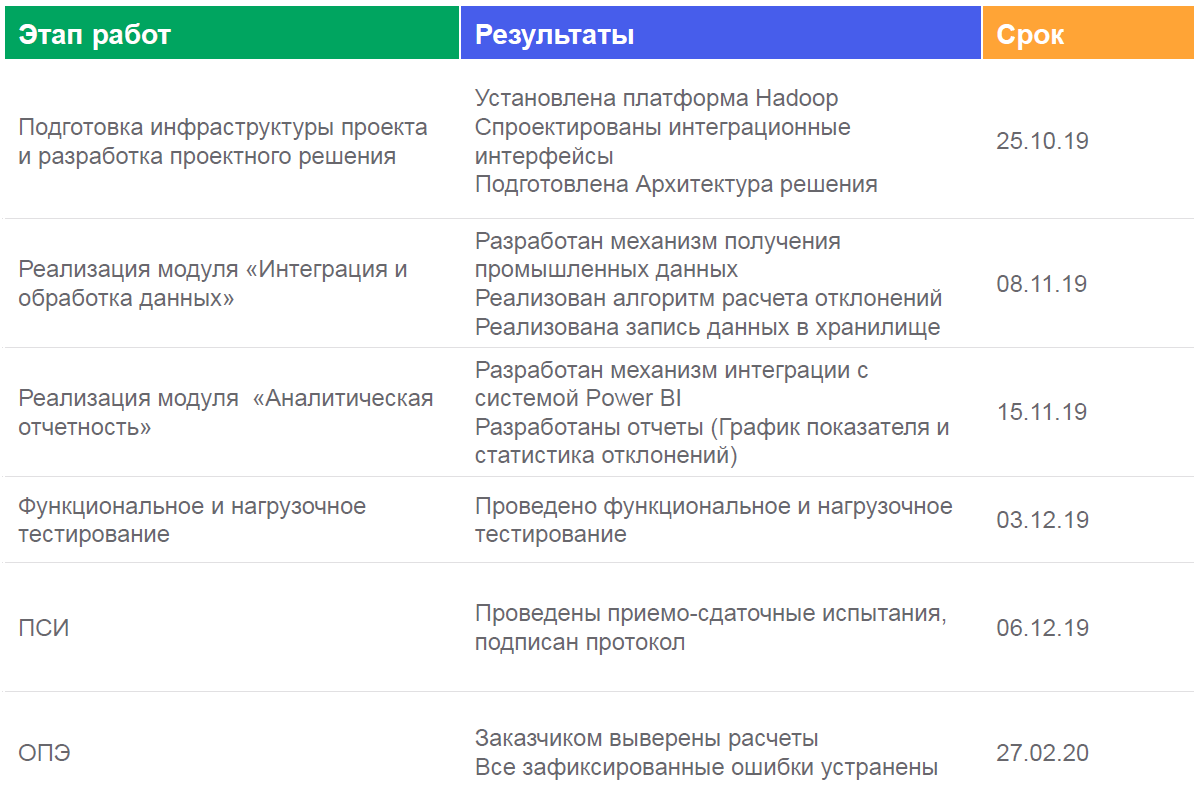
So haben wir diesen Fall implementiert:
Dashboards sehen ungefähr so aus: Sie werden
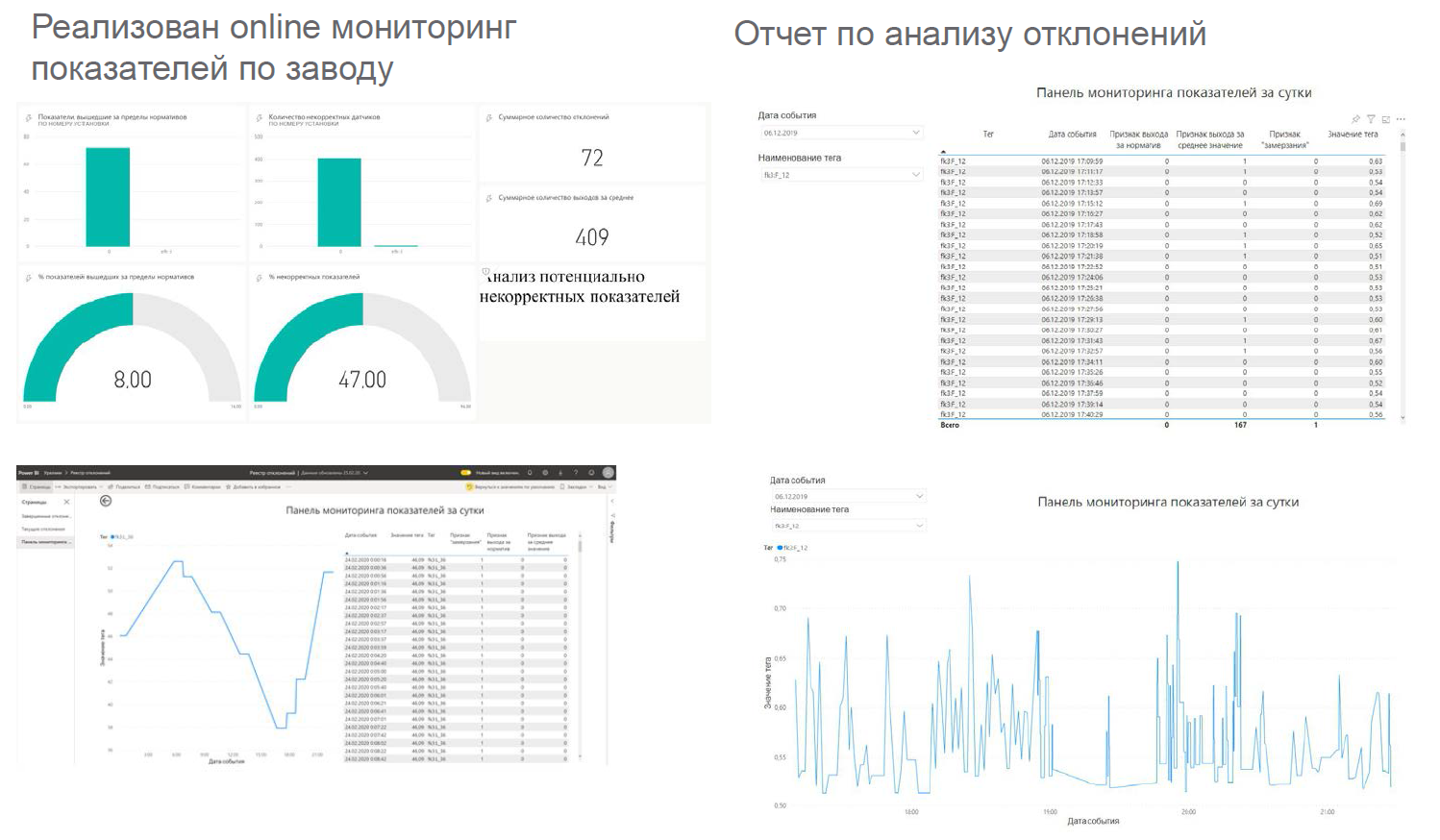
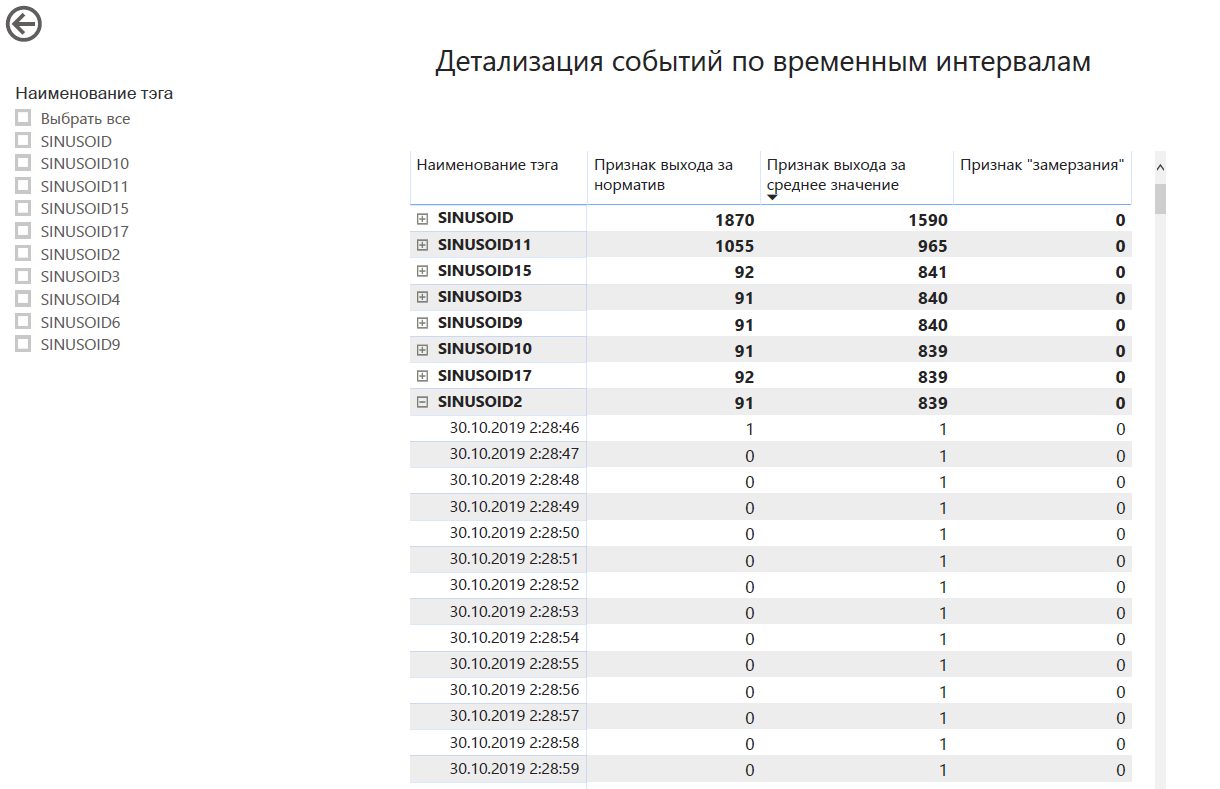
an folgenden Stellen angezeigt :

Was wir haben:
- Auf technologischer Ebene wurde ein Informationsraum geschaffen, um mit Messwerten von Gerätesensoren zu arbeiten.
- überprüfte die Fähigkeit, Daten basierend auf der Big Data-Technologie zu speichern und zu verarbeiten;
- testete die Fähigkeit von Business Intelligence-Systemen (z. B. Power BI), mit einem auf der Arenadata Hadoop-Plattform basierenden Datensee zu arbeiten;
- Es wurde ein einheitlicher analytischer Speicher eingeführt, um Produktionsinformationen von Gerätesensoren mit der Möglichkeit der Langzeitspeicherung von Informationen zu sammeln (das geplante Volumen der gesammelten Daten für ein Jahr beträgt etwa zwei Terabyte).
- Es wurden Mechanismen und Methoden entwickelt, um Daten nahezu in Echtzeit zu erhalten.
- Es wurde ein Algorithmus zur Bestimmung von Abweichungen und zum fehlerhaften Betrieb von Sensoren im Echtzeitmodus entwickelt (Berechnung - einmal pro Minute).
- Es wurden Tests des Systembetriebs und der Fähigkeit zur Erstellung von Berichten im BI-Tool durchgeführt.
Das Fazit ist, dass wir ein vollständiges Produktionsproblem gelöst haben - wir haben einen Routineprozess automatisiert. Wir haben ein Prognosetool herausgegeben und den Technologen Zeit gegeben, intelligentere Probleme zu lösen.
Und wenn Sie noch Fragen haben, die keine Kommentare enthalten, senden Sie bitte die E-Mail-Adresse: chemie@croc.ru