In diesem Artikel werde ich auf ein etwas komplexeres und interessanteres Thema eingehen (zumindest für mich, den Entwickler des Suchteams): die Volltextsuche. Wir werden unserer Containerregion einen Elasticsearch-Knoten hinzufügen, lernen, wie man einen Index erstellt und Inhalte sucht, wobei Beschreibungen von fünftausend Filmen aus dem TMDB 5000-Filmdatensatz als Testdaten verwendet werden... Wir werden auch lernen, wie man Suchfilter erstellt und einiges in Richtung Ranking gräbt.
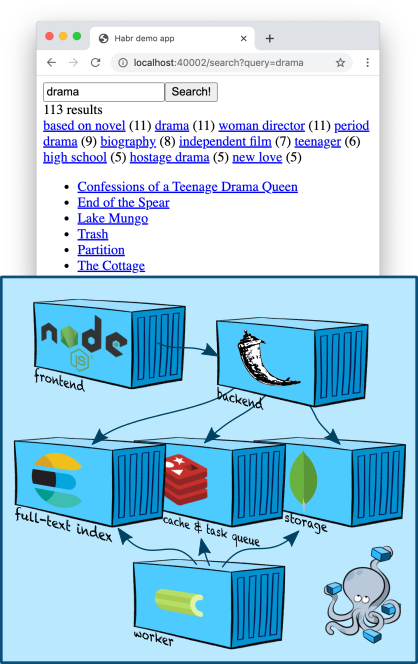
Infrastruktur: Elasticsearch
Elasticsearch ist ein beliebter Dokumentenspeicher, der Volltextindizes erstellen kann und in der Regel speziell als Suchmaschine verwendet wird. Elasticsearch erweitert die Apache Lucene- Engine, auf der es basiert, um Sharding, Replikation, eine praktische JSON-API und eine Million weiterer Details, die es zu einer der beliebtesten Volltextsuchlösungen gemacht haben.
Fügen wir unserem einen Elasticsearch-Knoten hinzu
docker-compose.yml:
services:
...
elasticsearch:
image: "elasticsearch:7.5.1"
environment:
- discovery.type=single-node
ports:
- "9200:9200"
...
Die Umgebungsvariable
discovery.type=single-nodeweist Elasticsearch an, sich auf die Arbeit allein vorzubereiten und nicht nach anderen Knoten zu suchen und diese zu einem Cluster zusammenzuführen (dies ist das Standardverhalten).
Beachten Sie, dass wir Port 9200 nach außen veröffentlichen, obwohl unsere Anwendung innerhalb des von Docker-Compose erstellten Netzwerks navigiert. Dies ist nur zum Debuggen gedacht: Auf diese Weise können wir direkt vom Terminal aus auf Elasticsearch zugreifen (bis wir einen intelligenteren Weg finden - mehr dazu weiter unten).
Das Hinzufügen eines Elasticsearch-Clients zu unserer Verkabelung ist nicht schwierig - das Gute, Elastic bietet einen minimalistischen Python-Client .
Indizierung
Im letzten Artikel haben wir unsere Hauptentitäten - "Karten" - in eine MongoDB-Sammlung aufgenommen. Wir können ihren Inhalt schnell anhand einer Kennung aus einer Sammlung abrufen, da MongoDB einen direkten Index für uns erstellt hat - dafür werden B-Bäume verwendet .
Jetzt stehen wir vor der umgekehrten Aufgabe - anhand des Inhalts (oder seiner Fragmente), die Kennungen der Karten zu erhalten. Deshalb brauchen wir einen umgekehrten Index . Hier bietet sich Elasticsearch an!
Das allgemeine Schema zum Erstellen eines Index sieht normalerweise so aus.
- Erstellen Sie einen neuen leeren Index mit einem eindeutigen Namen und konfigurieren Sie ihn nach Bedarf.
- Wir gehen alle unsere Entitäten in der Datenbank durch und fügen sie in einen neuen Index ein.
- Wir schalten die Produktion so um, dass alle Abfragen zum neuen Index wechseln.
- Entfernen des alten Index. Hier nach Belieben - vielleicht möchten Sie die letzten Indizes speichern, damit es beispielsweise bequemer ist, einige Probleme zu debuggen.
Lassen Sie uns das Skelett des Indexers erstellen und dann mit jedem Schritt näher darauf eingehen.
import datetime
from elasticsearch import Elasticsearch, NotFoundError
from backend.storage.card import Card, CardDAO
class Indexer(object):
def __init__(self, elasticsearch_client: Elasticsearch, card_dao: CardDAO, cards_index_alias: str):
self.elasticsearch_client = elasticsearch_client
self.card_dao = card_dao
self.cards_index_alias = cards_index_alias
def build_new_cards_index(self) -> str:
# .
# .
index_name = "cards-" + datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
# .
# .
self.create_empty_cards_index(index_name)
# .
#
# .
for card in self.card_dao.get_all():
self.put_card_into_index(card, index_name)
return index_name
def create_empty_cards_index(self, index_name):
...
def put_card_into_index(self, card: Card, index_name: str):
...
def switch_current_cards_index(self, new_index_name: str):
...
Indizierung: Erstellen eines Index
Ein Index in Elasticsearch wird durch eine einfache PUT-Anforderung an
/-oder bei Verwendung eines Python-Clients (in unserem Fall) durch Aufruf erstellt
elasticsearch_client.indices.create(index_name, {
...
})
Der Anforderungshauptteil kann drei Felder enthalten.
- Beschreibung der Aliase (
"aliases": ...). Mit dem Alias-System können Sie wissen, welcher Index auf der Elasticsearch-Seite aktuell ist. Wir werden unten darüber sprechen. - Einstellungen (
"settings": ...). Wenn wir große Leute mit echter Produktion sind, können wir hier Replikation, Sharding und andere SRE-Freuden konfigurieren. - Datenschema (
"mappings": ...). Hier können wir angeben, welche Art von Feldern in den Dokumenten wir indizieren möchten, für welches dieser Felder wir inverse Indizes benötigen, für welche Aggregationen unterstützt werden sollen und so weiter.
Jetzt interessieren wir uns nur noch für das Schema, und wir haben es sehr einfach:
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "english"
},
"text": {
"type": "text",
"analyzer": "english"
},
"tags": {
"type": "keyword",
"fields": {
"text": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
Wir haben das Feld markiert
nameund textals Text in Englisch. Ein Parser ist eine Entität in Elasticsearch, die Text verarbeitet, bevor er im Index gespeichert wird. Im Fall des englishAnalysators wird der Text entlang der Wortgrenzen ( Details ) in Token aufgeteilt , wonach einzelne Token gemäß den Regeln der englischen Sprache lemmatisiert werden (zum Beispiel wird das Wort treesvereinfacht tree), zu allgemeine Lemmas (wie the) werden gelöscht und die verbleibenden Lemmas werden in den umgekehrten Index gesetzt.
Das Feld ist
tagsetwas komplizierter. Eine Artkeywordnimmt an, dass die Werte dieses Feldes einige Zeichenfolgenkonstanten sind, die vom Analysator nicht verarbeitet werden müssen; Der inverse Index wird basierend auf ihren "rohen" Werten erstellt - ohne Tokenisierung und Lemmatisierung. Elasticsearch erstellt jedoch spezielle Datenstrukturen, damit Aggregationen von den Werten dieses Felds gelesen werden können (z. B. damit Sie gleichzeitig mit der Suche herausfinden können, welche Tags in Dokumenten gefunden wurden, die die Suchabfrage erfüllen, und in welcher Menge). Dies ist ideal für Felder, die im Wesentlichen enum sind. Wir werden diese Funktion verwenden, um einige coole Suchfilter zu erstellen.
Damit der Text der Tags auch durch Textsuche durchsucht werden kann, fügen wir ihm ein Unterfeld hinzu
"text", das analog zu nameund konfiguriert isttextoben - im Wesentlichen bedeutet dies, dass Elasticsearch in allen empfangenen Dokumenten ein weiteres "virtuelles" Feld unter dem Namen erstellt tags.text, in das der Inhalt kopiert tags, aber nach unterschiedlichen Regeln indiziert wird.
Indizierung: Füllen Sie den Index
Um ein Dokument zu indizieren, reicht es aus, eine PUT-Anforderung an
/-/_create/id-einen Python-Client zu senden oder bei Verwendung eines Python-Clients einfach die erforderliche Methode aufzurufen. Unsere Implementierung wird folgendermaßen aussehen:
def put_card_into_index(self, card: Card, index_name: str):
self.elasticsearch_client.create(index_name, card.id, {
"name": card.name,
"text": card.markdown,
"tags": card.tags,
})
Achten Sie auf das Feld
tags. Obwohl wir beschrieben haben, dass es ein Schlüsselwort enthält, senden wir keine einzelne Zeichenfolge, sondern eine Liste von Zeichenfolgen. Elasticsearch unterstützt dies; Unser Dokument befindet sich an einem der Werte.
Indizierung: Index wechseln
Um eine Suche zu implementieren, müssen wir den Namen des neuesten vollständig erstellten Index kennen. Der Alias-Mechanismus ermöglicht es uns, diese Informationen auf der Elasticsearch-Seite zu behalten.
Ein Alias ist ein Zeiger auf null oder mehr Indizes. Mit der Elasticsearch-API können Sie bei der Suche einen Aliasnamen anstelle eines Indexnamens verwenden (POST
/-/_searchanstelle von POST /-/_search). In diesem Fall durchsucht Elasticsearch alle Indizes, auf die der Alias verweist.
Wir erstellen einen Alias namens
cards, der immer auf den aktuellen Index verweist. Dementsprechend sieht das Umschalten auf den tatsächlichen Index nach Abschluss der Bauarbeiten folgendermaßen aus:
def switch_current_cards_index(self, new_index_name: str):
try:
# , .
remove_actions = [
{
"remove": {
"index": index_name,
"alias": self.cards_index_alias,
}
}
for index_name in self.elasticsearch_client.indices.get_alias(name=self.cards_index_alias)
]
except NotFoundError:
# , - .
# , .
remove_actions = []
#
# .
self.elasticsearch_client.indices.update_aliases({
"actions": remove_actions + [{
"add": {
"index": new_index_name,
"alias": self.cards_index_alias,
}
}]
})
Ich werde nicht näher auf die Alias-API eingehen. Alle Details finden Sie in der Dokumentation .
Hier muss angemerkt werden, dass ein solcher Wechsel in einem wirklich hoch ausgelasteten Dienst sehr schmerzhaft sein kann und es möglicherweise sinnvoll ist, ein vorläufiges Aufwärmen durchzuführen - laden Sie den neuen Index mit einer Art Pool gespeicherter Benutzerabfragen.
Der gesamte Code, der die Indizierung implementiert, befindet sich in diesem Commit .
Indizierung: Hinzufügen von Inhalten
Für die Demonstration in diesem Artikel verwende ich Daten aus dem TMDB 5000-Filmdatensatz . Um Urheberrechtsprobleme zu vermeiden, gebe ich nur den Code für das Dienstprogramm an , das sie aus einer CSV-Datei importiert. Ich schlage vor, dass Sie sich selbst von der Kaggle-Website herunterladen. Führen Sie nach dem Herunterladen einfach den Befehl aus
docker-compose exec -T backend python -m tools.add_movies < ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv
fünftausend Filmkarten und ein Team zu erstellen
docker-compose exec backend python -m tools.build_index
einen Index erstellen. Beachten Sie, dass der letzte Befehl den Index nicht erstellt, sondern nur die Aufgabe in die Aufgabenwarteschlange stellt, wonach sie auf dem Worker ausgeführt wird. Ich habe diesen Ansatz im letzten Artikel ausführlicher erläutert .
docker-compose logs workerzeig dir, wie der Arbeiter es versucht hat!
Bevor wir zur eigentlichen Suche kommen, möchten wir mit eigenen Augen sehen, ob etwas in Elasticsearch geschrieben wurde und wenn ja, wie es aussieht!
Der direkteste und schnellste Weg, dies zu tun, ist die Verwendung der Elasticsearch-HTTP-API. Lassen Sie uns zunächst überprüfen, wohin der Alias zeigt:
$ curl -s localhost:9200/_cat/aliases
cards cards-2020-09-20-16-14-18 - - - -
Großartig, der Index existiert! Schauen wir es uns genauer an:
$ curl -s localhost:9200/cards-2020-09-20-16-14-18 | jq
{
"cards-2020-09-20-16-14-18": {
"aliases": {
"cards": {}
},
"mappings": {
...
},
"settings": {
"index": {
"creation_date": "1600618458522",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "iLX7A8WZQuCkRSOd7mjgMg",
"version": {
"created": "7050199"
},
"provided_name": "cards-2020-09-20-16-14-18"
}
}
}
}
Schauen wir uns zum Schluss den Inhalt an:
$ curl -s localhost:9200/cards-2020-09-20-16-14-18/_search | jq
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4704,
"relation": "eq"
},
"max_score": 1,
"hits": [
...
]
}
}
Insgesamt umfasst unser Index 4704 Dokumente, und im Feld
hits(das ich übersprungen habe, weil es zu groß ist) können Sie sogar den Inhalt einiger Dokumente sehen. Erfolg!
Eine bequemere Möglichkeit, den Inhalt des Index zu durchsuchen und sich im Allgemeinen mit Elasticsearch zu verwöhnen, ist die Verwendung von Kibana . Fügen wir den Container hinzu zu
docker-compose.yml:
services:
...
kibana:
image: "kibana:7.5.1"
ports:
- "5601:5601"
depends_on:
- elasticsearch
...
Nach einem zweiten Mal können
docker-compose upwir unter der Adresse zu Kibana gehen localhost:5601(Achtung, der Server startet möglicherweise nicht schnell) und nach einer kurzen Einrichtung den Inhalt unserer Indizes in einer schönen Weboberfläche anzeigen.
Ich empfehle dringend die Registerkarte Dev Tools - während der Entwicklung müssen Sie häufig bestimmte Abfragen in Elasticsearch durchführen, und im interaktiven Modus mit automatischer Vervollständigung und automatischer Formatierung ist dies viel praktischer.
Suche
Nach all den unglaublich langweiligen Vorbereitungen ist es Zeit für uns, unserer Webanwendung Suchfunktionen hinzuzufügen!
Lassen Sie uns diese nicht triviale Aufgabe in drei Phasen unterteilen und jede einzeln diskutieren.
- Fügen Sie dem Backend eine Komponente hinzu,
Searcherdie für die Suchlogik verantwortlich ist . Es wird eine Abfrage an Elasticsearch bilden und die Ergebnisse für unser Backend in besser verdauliche konvertieren. - Fügen Sie der API einen Endpunkt hinzu (Handle / Route / wie nennt man ihn in Ihrem Unternehmen?), Der
/cards/searchdie Suche durchführt. Es ruft die Methode der Komponente aufSearcher, verarbeitet die resultierenden Ergebnisse und gibt sie an den Client zurück. - Lassen Sie uns die Suchoberfläche im Frontend implementieren. Er wird sich melden,
/cards/searchwenn der Benutzer entschieden hat, wonach er suchen möchte, und die Ergebnisse (und möglicherweise einige zusätzliche Steuerelemente) anzeigen.
Suche: wir implementieren
Es ist nicht so schwierig, einen Suchmanager zu schreiben, sondern einen zu entwerfen. Beschreiben wir das Suchergebnis und die Manager-Oberfläche und diskutieren, warum dies so ist und nicht anders.
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0) -> CardSearchResult:
pass
Einige Dinge sind offensichtlich. Zum Beispiel Paginierung. Wir sind ein ehrgeiziges junges
Einige sind weniger offensichtlich. Zum Beispiel eine Liste von IDs, nicht Karten als Ergebnis. Elasticsearch speichert standardmäßig unsere gesamten Dokumente und gibt sie in den Suchergebnissen zurück. Dieses Verhalten kann deaktiviert werden, um die Größe des Suchindex zu sparen. Dies ist jedoch eindeutig eine vorzeitige Optimierung für uns. Warum also nicht gleich die Karten zurückgeben? Antwort: Dies würde das Prinzip der Einzelverantwortung verletzen. Vielleicht werden wir eines Tages eine komplexe Logik im Kartenmanager finden, die Karten abhängig von den Einstellungen des Benutzers in andere Sprachen übersetzt. Genau in diesem Moment werden die Daten auf der Kartenseite und die Daten in den Suchergebnissen verteilt, da wir vergessen, dem Suchmanager dieselbe Logik hinzuzufügen. Und so weiter und so fort.
Die Implementierung dieser Schnittstelle ist so einfach, dass ich zu faul war, diesen Abschnitt zu schreiben :-(
# backend/backend/search/searcher_impl.py
from typing import Any
from elasticsearch import Elasticsearch
from backend.search.searcher import CardSearchResult, Searcher
ElasticsearchQuery = Any #
class ElasticsearchSearcher(Searcher):
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query
})
total_count = result["hits"]["total"]["value"]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
)
def _make_text_query(self, query: str) -> ElasticsearchQuery:
return {
# Multi-match query
# ( match
# query, ).
"multi_match": {
"query": query,
# ^ – .
# , .
"fields": ["name^3", "tags.text", "text"],
}
}
_match_all_query: ElasticsearchQuery = {"match_all": {}}
Tatsächlich gehen wir einfach zur Elasticsearch-API und extrahieren sorgfältig die IDs der gefundenen Karten aus dem Ergebnis.
Die Endpunktimplementierung ist auch ziemlich trivial:
# backend/backend/server.py
...
def search_cards(self):
request = flask.request.json
search_result = self.wiring.searcher.search_cards(**request)
cards = self.wiring.card_dao.get_by_ids(search_result.card_ids)
return flask.jsonify({
"totalCount": search_result.total_count,
"cards": [
{
"id": card.id,
"slug": card.slug,
"name": card.name,
# ,
# ,
# .
} for card in cards
],
"nextCardOffset": search_result.next_card_offset,
})
...
Die Implementierung des Frontends unter Verwendung dieses Endpunkts ist zwar umfangreich, aber im Allgemeinen recht einfach, und in diesem Artikel möchte ich nicht darauf eingehen. Der gesamte Code kann in diesem Commit angezeigt werden .

So weit so gut, lass uns weitermachen.
 Suche: Filter hinzufügen
Suche: Filter hinzufügen
Das Suchen in Text ist cool, aber wenn Sie jemals nach ernsthaften Ressourcen gesucht haben, haben Sie wahrscheinlich alle möglichen Extras wie Filter gesehen.
Unsere Beschreibungen von Filmen aus der TMDB 5000-Datenbank enthalten neben Titeln und Beschreibungen auch Tags. Implementieren Sie daher Filter für Tags für das Training. Unser Ziel ist der Screenshot: Wenn Sie auf ein Tag klicken, sollten nur Filme mit diesem Tag in den Suchergebnissen verbleiben (ihre Nummer ist in Klammern daneben angegeben).

Um Filter zu implementieren, müssen wir zwei Probleme lösen.
- Erfahren Sie auf Anfrage, welche Filter verfügbar sind. Wir möchten nicht alle möglichen Filterwerte auf jedem Bildschirm anzeigen, da es viele davon gibt und die meisten zu einem leeren Ergebnis führen. Sie müssen verstehen, welche Tags die auf Anfrage gefundenen Dokumente haben, und im Idealfall das N am beliebtesten lassen.
- In der Tat lernen, einen Filter anzuwenden - in den Suchergebnissen nur Dokumente mit Tags zu belassen, den Filter, nach dem der Benutzer gewählt hat.
Die zweite in Elasticsearch wird einfach über die Abfrage-API implementiert (siehe Begriffe Abfrage ), die erste über einen etwas weniger trivialen Aggregationsmechanismus .
Wir müssen also wissen, welche Tags in den gefundenen Karten enthalten sind, und in der Lage sein, Karten mit den erforderlichen Tags zu filtern. Lassen Sie uns zunächst das Design des Suchmanagers aktualisieren:
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class TagStats:
tag: str
cards_count: int
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
tag_stats: Iterable[TagStats]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0,
tags: Optional[Iterable[str]] = None) -> CardSearchResult:
pass
Fahren wir nun mit der Implementierung fort. Als erstes müssen wir eine Aggregation nach Feld erstellen
tags:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -10,6 +10,8 @@ ElasticsearchQuery = Any
class ElasticsearchSearcher(Searcher):
+ TAGS_AGGREGATION_NAME = "tags_aggregation"
+
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
@@ -18,7 +20,12 @@ class ElasticsearchSearcher(Searcher):
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query,
+ "aggregations": {
+ self.TAGS_AGGREGATION_NAME: {
+ "terms": {"field": "tags"}
+ }
+ }
})
Im Suchergebnis von Elasticsearch wird nun ein Feld angezeigt,
aggregationsaus dem TAGS_AGGREGATION_NAMEwir mithilfe eines Schlüssels Buckets abrufen können, die Informationen darüber enthalten, welche Werte tagsfür die gefundenen Dokumente im Feld enthalten sind und wie oft sie vorkommen. Lassen Sie uns diese Daten extrahieren und wie oben beschrieben zurückgeben:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -28,10 +28,15 @@ class ElasticsearchSearcher(Searcher):
total_count = result["hits"]["total"]["value"]
+ tag_stats = [
+ TagStats(tag=bucket["key"], cards_count=bucket["doc_count"])
+ for bucket in result["aggregations"][self.TAGS_AGGREGATION_NAME]["buckets"]
+ ]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
+ tag_stats=tag_stats,
)
Das Hinzufügen einer Filteranwendung ist der einfachste Teil:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -16,11 +16,17 @@ class ElasticsearchSearcher(Searcher):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
- def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
+ def search_cards(self, query: str = "", count: int = 20, offset: int = 0,
+ tags: Optional[Iterable[str]] = None) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
- "query": self._make_text_query(query) if query else self._match_all_query,
+ "query": {
+ "bool": {
+ "must": self._make_text_queries(query),
+ "filter": self._make_filter_queries(tags),
+ }
+ },
"aggregations": {
Unterabfragen, die in der must-Klausel enthalten sind, sind erforderlich, werden jedoch auch bei der Berechnung der Geschwindigkeit von Dokumenten und dementsprechend der Rangfolge berücksichtigt. Wenn wir den Texten jemals weitere Bedingungen hinzufügen, ist es besser, sie hier hinzuzufügen. Die Unterabfragen in der Filterklausel filtern nur, ohne die Geschwindigkeit und das Ranking zu beeinflussen.
Es bleibt zu implementieren
_make_filter_queries():
def _make_filter_queries(self, tags: Optional[Iterable[str]] = None) -> List[ElasticsearchQuery]:
return [] if tags is None else [{
"term": {
"tags": {
"value": tag
}
}
} for tag in tags]
Auch hier werde ich nicht auf den Front-End-Teil eingehen; Der gesamte Code befindet sich in diesem Commit .
Reichweite
Unsere Suche sucht also nach Karten, filtert sie nach einer bestimmten Liste von Tags und zeigt sie in einer bestimmten Reihenfolge an. Aber welcher? Die Reihenfolge ist für eine praktische Suche sehr wichtig, aber alles, was wir während unseres Rechtsstreits in Bezug auf die Reihenfolge getan haben, wurde Elasticsearch angedeutet, dass es rentabler ist, Wörter in der Überschrift der Karte als in der Beschreibung oder den Tags zu finden, indem die Priorität
^3in der Mehrfachübereinstimmungsabfrage angegeben wird.
Trotz der Tatsache, dass Elasticsearch standardmäßig Dokumente mit einer ziemlich kniffligen TF-IDF- basierten Formel bewertetFür unser imaginäres ehrgeiziges Startup ist dies kaum genug. Wenn es sich bei unseren Dokumenten um Waren handelt, müssen wir in der Lage sein, deren Umsatz zu erfassen. Wenn es sich um benutzergenerierte Inhalte handelt, können Sie deren Aktualität berücksichtigen und so weiter. Wir können jedoch nicht einfach nach der Anzahl der Verkäufe / dem Datum der Hinzufügung sortieren, da wir dann die Relevanz für die Suchabfrage nicht berücksichtigen.
Das Ranking ist ein großer und verwirrender Bereich der Technologie, der am Ende dieses Artikels nicht in einem Abschnitt behandelt werden kann. Also wechsle ich hier zu großen Strichen; Ich werde versuchen, allgemein zu sagen, wie das Ranking für Industriezwecke bei der Suche angeordnet werden kann, und ich werde einige technische Details darüber offenlegen, wie es mit Elasticsearch implementiert werden kann.
Die Aufgabe des Rankings ist sehr komplex, daher ist es nicht verwunderlich, dass eine der wichtigsten modernen Lösungsmethoden das maschinelle Lernen ist. Das Anwenden von Technologien für maschinelles Lernen auf das Ranking wird gemeinsam als Lernen zum Ranking bezeichnet .
Ein typischer Prozess sieht so aus.
Wir entscheiden, was wir bewerten wollen . Wir fügen die für uns interessanten Entitäten in den Index ein, lernen, wie Sie für eine bestimmte Suchabfrage eine vernünftige Spitze (z. B. einfaches Sortieren und Abschneiden) dieser Entitäten erhalten, und möchten nun lernen, wie Sie sie intelligenter einstufen.
Bestimmen, wie wir ranken wollen... Wir entscheiden, welche Eigenschaft wir unsere Ergebnisse in Übereinstimmung mit den Geschäftszielen unseres Service einstufen möchten. Wenn es sich bei unseren Unternehmen beispielsweise um Produkte handelt, die wir verkaufen, möchten wir sie möglicherweise in absteigender Reihenfolge der Kaufwahrscheinlichkeit sortieren. wenn Meme - nach Wahrscheinlichkeit von "Gefällt mir" oder "Teilen" und so weiter. Wir wissen natürlich nicht, wie wir diese Wahrscheinlichkeiten berechnen sollen - bestenfalls können wir sie schätzen, und selbst dann nur für alte Entitäten, für die wir genügend Statistiken haben -, aber wir werden versuchen, dem Modell beizubringen, sie anhand indirekter Vorzeichen vorherzusagen.
Zeichen extrahieren... Wir haben eine Reihe von Funktionen für unsere Entitäten entwickelt, mit denen wir die Relevanz von Entitäten für Suchanfragen beurteilen können. Ein typisches Beispiel ist neben der gleichen TF-IDF, die bereits weiß, wie Elasticsearch für uns berechnet wird, die Klickrate (Click-through-Rate): Wir führen die Protokolle unseres Dienstes für die gesamte Zeit durch. Für jedes Paar von Entitäten + Suchabfragen zählen wir, wie oft die Entität in den Suchergebnissen angezeigt wurde Für diese Anfrage und wie oft darauf geklickt wurde, teilen wir sie durch die anderen, et voilà - die einfachste Schätzung der bedingten Klickwahrscheinlichkeit ist fertig. Wir können auch benutzerspezifische Merkmale und Merkmale zwischen Benutzer und Entität entwickeln, um die Rangfolge zu personalisieren. Nachdem wir uns Zeichen ausgedacht haben, schreiben wir einen Code, der sie berechnet, in eine Art Speicher legt und weiß, wie man sie in Echtzeit für eine bestimmte Suchabfrage, einen bestimmten Benutzer und eine Reihe von Entitäten gibt.
Zusammenstellen eines Trainingsdatensatzes . Es gibt viele Optionen, aber alle werden in der Regel aus den Protokollen der Ereignisse "gut" (z. B. ein Klick und dann ein Kauf) und "schlecht" (z. B. ein Klick und eine Rückkehr zur Ausgabe) in unserem Service gebildet. Wenn wir einen Datensatz zusammengestellt haben, sei es eine Liste von Aussagen „Die Bewertung der Relevanz von Produkt X für die Abfrage Q ist ungefähr gleich P“, eine Liste von Paaren „Produkt X ist für Produkt Y relevanter für die Abfrage Q“ oder eine Reihe von Listen „Für die Abfrage Q sind die Produkte P 1 , P 2 , ... korrekt wie diese -das ", wir ziehen die entsprechenden Zeichen an allen darin erscheinenden Linien fest.
Wir trainieren das Modell . Hier sind alle ML-Klassiker: Zug / Test, Hyperparameter, Umschulung,
Wir binden das Modell ein . Es bleibt für uns, die Berechnung des Modells im laufenden Betrieb für das gesamte Top irgendwie zu schrauben, damit die bereits eingestuften Ergebnisse den Benutzer erreichen. Es gibt viele Möglichkeiten; Zur Veranschaulichung werde ich mich (wieder) auf das einfache Elasticsearch-Plugin Learning to Rank konzentrieren .
Ranking: Elasticsearch Lernen, das Plugin zu bewerten
Elasticsearch Learning to Rank ist ein Plugin, das Elasticsearch die Möglichkeit bietet, ein ML-Modell im SERP zu berechnen und die Ergebnisse sofort nach den berechneten Raten zu ordnen. Es wird uns auch helfen, Funktionen zu erhalten, die mit denen in Echtzeit identisch sind, und gleichzeitig die Funktionen von Elasticsearch (TF-IDF und dergleichen) wiederzuverwenden.
Zuerst müssen wir das Plugin in unserem Container mit Elasticsearch verbinden. Wir brauchen eine einfache Docker-Datei
# elasticsearch/Dockerfile
FROM elasticsearch:7.5.1
RUN ./bin/elasticsearch-plugin install --batch http://es-learn-to-rank.labs.o19s.com/ltr-1.1.2-es7.5.1.zip
und damit verbundene Änderungen an
docker-compose.yml:
--- a/docker-compose.yml
+++ b/docker-compose.yml
@@ -5,7 +5,8 @@ services:
elasticsearch:
- image: "elasticsearch:7.5.1"
+ build:
+ context: elasticsearch
environment:
- discovery.type=single-node
Wir brauchen auch Plugin-Unterstützung im Python-Client. Mit Erstaunen stellte ich fest, dass die Unterstützung für Python nicht vollständig mit dem Plug-In verbunden ist. Speziell für diesen Artikel habe ich es heruntergespült . In
elasticsearch_ltran requirements.txtund den Client in der Verkabelung eines Upgrade:
--- a/backend/backend/wiring.py
+++ b/backend/backend/wiring.py
@@ -1,5 +1,6 @@
import os
+from elasticsearch_ltr import LTRClient
from celery import Celery
from elasticsearch import Elasticsearch
from pymongo import MongoClient
@@ -39,5 +40,6 @@ class Wiring(object):
self.task_manager = TaskManager(self.celery_app)
self.elasticsearch_client = Elasticsearch(hosts=self.settings.ELASTICSEARCH_HOSTS)
+ LTRClient.infect_client(self.elasticsearch_client)
self.indexer = Indexer(self.elasticsearch_client, self.card_dao, self.settings.CARDS_INDEX_ALIAS)
self.searcher: Searcher = ElasticsearchSearcher(self.elasticsearch_client, self.settings.CARDS_INDEX_ALIAS)
Rangliste: Sägeschilder
Jede Anfrage in Elasticsearch gibt nicht nur eine Liste der IDs der gefundenen Dokumente zurück, sondern auch einige davon in Kürze (wie würden Sie die Wortpartitur ins Russische übersetzen?). Wenn es sich also um eine Übereinstimmungs- oder Mehrfachübereinstimmungsabfrage handelt , die wir verwenden, ist schnell das Ergebnis der Berechnung dieser sehr kniffligen Formel mit TF-IDF. wenn die Bool-Abfrage eine Kombination verschachtelter Abfrageraten ist; wenn Funktionsbewertung Abfrage- das Ergebnis der Berechnung einer bestimmten Funktion (z. B. der Wert eines numerischen Felds in einem Dokument) usw. Das ELTR-Plugin bietet uns die Möglichkeit, die Geschwindigkeit jeder Abfrage als Zeichen zu verwenden, sodass wir auf einfache Weise Daten darüber kombinieren können, wie gut das Dokument mit der Anforderung übereinstimmt (über eine Abfrage mit mehreren Übereinstimmungen) und einige vorberechnete Statistiken, die wir im Voraus in das Dokument eingegeben haben (über die Abfrage der Funktionsbewertung). ...
Da wir eine TMDB 5000-Datenbank in unseren Händen haben, die Filmbeschreibungen und unter anderem deren Bewertungen enthält, nehmen wir die Bewertung als beispielhaftes vorberechnetes Merkmal.
In diesem CommitIch habe dem Backend unserer Webanwendung eine grundlegende Infrastruktur zum Speichern von Funktionen hinzugefügt und das Laden der Bewertung aus der Filmdatei unterstützt. Um Sie nicht zu zwingen, einen weiteren Code zu lesen, werde ich die grundlegendsten beschreiben.
- Wir werden die Features in einer separaten Sammlung speichern und sie von einem separaten Manager erhalten. Das Speichern aller Daten in einer Entität ist eine schlechte Praxis.
- Wir werden diesen Manager in der Indizierungsphase kontaktieren und alle verfügbaren Funktionen in die indizierten Dokumente aufnehmen.
- Um das Indexschema zu kennen, müssen wir die Liste aller vorhandenen Features kennen, bevor wir mit der Erstellung des Index beginnen. Wir werden diese Liste vorerst fest codieren.
- Da wir Dokumente nicht nach Attributwerten filtern, sondern nur aus bereits gefundenen Dokumenten zur Berechnung des Modells extrahieren, deaktivieren wir die Konstruktion inverser Indizes durch neue Felder mit einer Option
index: falseim Schema und sparen dadurch etwas Platz.
Ranking: Sammeln des Datensatzes
Da wir erstens keine Produktion haben und zweitens die Ränder dieses Artikels zu klein sind, um über Telemetrie, Kafka, NiFi, Hadoop, Spark und das Erstellen von ETL-Prozessen zu sprechen, werde ich nur zufällige Ansichten und Klicks für unsere Karten und generieren eine Art von Suchanfragen. Danach müssen Sie die Merkmale für die resultierenden Kartenanforderungspaare berechnen.
Es ist Zeit, tiefer in die ELTR-Plugin-API einzutauchen. Um Features zu berechnen, müssen wir eine Feature-Store-Entität erstellen (soweit ich weiß, ist dies eigentlich nur ein Index in Elasticsearch, in dem das Plugin alle seine Daten speichert) und dann einen Feature-Set erstellen - eine Liste von Features mit einer Beschreibung der Berechnung der einzelnen Features. Danach reicht es aus, wenn wir mit einer speziellen Anfrage zu Elasticsearch gehen, um einen Vektor mit Merkmalswerten für jede gefundene Entität zu erhalten.
Beginnen wir mit der Erstellung eines Funktionsumfangs:
# backend/backend/search/ranking.py
from typing import Iterable, List, Mapping
from elasticsearch import Elasticsearch
from elasticsearch_ltr import LTRClient
from backend.search.features import CardFeaturesManager
class SearchRankingManager:
DEFAULT_FEATURE_SET_NAME = "card_features"
def __init__(self, elasticsearch_client: Elasticsearch,
card_features_manager: CardFeaturesManager,
cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.card_features_manager = card_features_manager
self.cards_index_name = cards_index_name
def initialize_ranking(self, feature_set_name=DEFAULT_FEATURE_SET_NAME):
ltr: LTRClient = self.elasticsearch_client.ltr
try:
# feature store ,
# ¯\_(ツ)_/¯
ltr.create_feature_store()
except Exception as exc:
if "resource_already_exists_exception" not in str(exc):
raise
# feature set !
ltr.create_feature_set(feature_set_name, {
"featureset": {
"features": [
#
# ,
# ,
# .
self._make_feature("name_tf_idf", ["query"], {
"match": {
# ELTR
# , .
# , ,
# ,
# match query.
"name": "{{query}}"
}
}),
# , .
self._make_feature("combined_tf_idf", ["query"], {
"multi_match": {
"query": "{{query}}",
"fields": ["name^3", "tags.text", "text"]
}
}),
*(
#
# function score.
# -
# , 0.
# (
# !)
self._make_feature(feature_name, [], {
"function_score": {
"field_value_factor": {
"field": feature_name,
"missing": 0
}
}
})
for feature_name in sorted(self.card_features_manager.get_all_feature_names_set())
)
]
}
})
@staticmethod
def _make_feature(name, params, query):
return {
"name": name,
"params": params,
"template_language": "mustache",
"template": query,
}
Jetzt - eine Funktion, die Funktionen für eine bestimmte Abfrage und Karten berechnet:
def compute_cards_features(self, query: str, card_ids: Iterable[str],
feature_set_name=DEFAULT_FEATURE_SET_NAME) -> Mapping[str, List[float]]:
card_ids = list(card_ids)
result = self.elasticsearch_client.search({
"query": {
"bool": {
# ,
# — ,
# .
# ID.
"filter": [
{
"terms": {
"_id": card_ids
}
},
# — ,
# SLTR.
#
# feature set.
# ( ,
# filter, .)
{
"sltr": {
"_name": "logged_featureset",
"featureset": feature_set_name,
"params": {
# .
# , ,
#
# {{query}}.
"query": query
}
}
}
]
}
},
#
# .
"ext": {
"ltr_log": {
"log_specs": {
"name": "log_entry1",
"named_query": "logged_featureset"
}
}
},
"size": len(card_ids),
})
# (
# ) .
# ( ,
# , Kibana.)
return {
hit["_id"]: [feature.get("value", float("nan")) for feature in hit["fields"]["_ltrlog"][0]["log_entry1"]]
for hit in result["hits"]["hits"]
}
Ein einfaches Skript, das CSV mit Anforderungen und ID-Karten als Eingabe akzeptiert und CSV mit den folgenden Funktionen ausgibt:
# backend/tools/compute_movie_features.py
import csv
import itertools
import sys
import tqdm
from backend.wiring import Wiring
if __name__ == "__main__":
wiring = Wiring()
reader = iter(csv.reader(sys.stdin))
header = next(reader)
feature_names = wiring.search_ranking_manager.get_feature_names()
writer = csv.writer(sys.stdout)
writer.writerow(["query", "card_id"] + feature_names)
query_index = header.index("query")
card_id_index = header.index("card_id")
chunks = itertools.groupby(reader, lambda row: row[query_index])
for query, rows in tqdm.tqdm(chunks):
card_ids = [row[card_id_index] for row in rows]
features = wiring.search_ranking_manager.compute_cards_features(query, card_ids)
for card_id in card_ids:
writer.writerow((query, card_id, *features[card_id]))
Endlich können Sie alles ausführen!
# feature set
docker-compose exec backend python -m tools.initialize_search_ranking
#
docker-compose exec -T backend \
python -m tools.generate_movie_events \
< ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv \
> ~/Downloads/habr-app-demo-dataset-events.csv
#
docker-compose exec -T backend \
python -m tools.compute_features \
< ~/Downloads/habr-app-demo-dataset-events.csv \
> ~/Downloads/habr-app-demo-dataset-features.csv
Jetzt haben wir zwei Dateien - mit Ereignissen und Zeichen - und können mit dem Training beginnen.
Ranking: Trainieren und implementieren Sie das Modell
Lassen Sie uns die Details zum Laden von Datasets weglassen (das vollständige Skript kann in diesem Commit angezeigt werden ) und kommen Sie direkt zum Punkt.
# backend/tools/train_model.py
...
if __name__ == "__main__":
args = parser.parse_args()
feature_names, features = read_features(args.features)
events = read_events(args.events)
# train test 4 1.
all_queries = set(events.keys())
train_queries = random.sample(all_queries, int(0.8 * len(all_queries)))
test_queries = all_queries - set(train_queries)
# DMatrix — , xgboost.
#
# . 1, ,
# 0, ( . ).
train_dmatrix = make_dmatrix(train_queries, events, feature_names, features)
test_dmatrix = make_dmatrix(test_queries, events, feature_names, features)
# !
#
# ML,
# XGBoost.
param = {
"max_depth": 2,
"eta": 0.3,
"objective": "binary:logistic",
"eval_metric": "auc",
}
num_round = 10
booster = xgboost.train(param, train_dmatrix, num_round, evals=((train_dmatrix, "train"), (test_dmatrix, "test")))
# .
booster.dump_model(args.output, dump_format="json")
# , :
# ROC-.
xgboost.plot_importance(booster)
plt.figure()
build_roc(test_dmatrix.get_label(), booster.predict(test_dmatrix))
plt.show()
Starten
python backend/tools/train_search_ranking_model.py \
--events ~/Downloads/habr-app-demo-dataset-events.csv \
--features ~/Downloads/habr-app-demo-dataset-features.csv \
-o ~/Downloads/habr-app-demo-model.xgb
Bitte beachten Sie, dass dieses Skript nicht mehr im Docker ausgeführt werden muss, da wir alle erforderlichen Daten mit den vorherigen Skripten exportiert haben. Es muss auf Ihrem Computer ausgeführt werden, nachdem es zuvor installiert wurde
xgboostund sklearn. In ähnlicher Weise müssten in der realen Produktion die vorherigen Skripte an einem Ort ausgeführt werden, an dem Zugriff auf die Produktionsumgebung besteht, dies ist jedoch nicht der Fall.
Wenn alles richtig gemacht ist, wird das Modell erfolgreich trainiert und wir werden zwei schöne Bilder sehen. Das erste ist ein Diagramm der Bedeutung von Merkmalen:

Obwohl die Ereignisse zufällig generiert wurden,
combined_tf_idfEs stellte sich heraus, dass es viel bedeutender ist als andere - weil ich einen Trick gemacht und die Wahrscheinlichkeit eines Klicks für Karten, die in den Suchergebnissen niedriger sind, künstlich gesenkt habe, die auf unsere alte Weise eingestuft wurden. Die Tatsache, dass das Modell dies bemerkt hat, ist ein gutes Zeichen und ein Zeichen dafür, dass wir im Lernprozess keine völlig dummen Fehler gemacht haben.
Das zweite Diagramm ist die ROC-Kurve : Die

blaue Linie befindet sich über der roten Linie, was bedeutet, dass unser Modell Etiketten etwas besser vorhersagt als ein Münzwurf. (Die ML-Ingenieurkurve von Mamas Freund sollte fast die obere linke Ecke berühren.)
Die Angelegenheit ist recht klein - wir fügen ein Skript zum Ausfüllen des Modells hinzu , füllen es aus und fügen der Suchabfrage ein kleines neues Element hinzu - Rescoring:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -27,6 +30,19 @@ class ElasticsearchSearcher(Searcher):
"filter": list(self._make_filter_queries(tags, ids)),
}
},
+ "rescore": {
+ "window_size": 1000,
+ "query": {
+ "rescore_query": {
+ "sltr": {
+ "params": {
+ "query": query
+ },
+ "model": self.ranking_manager.get_current_model_name()
+ }
+ }
+ }
+ },
"aggregations": {
self.TAGS_AGGREGATION_NAME: {
"terms": {"field": "tags"}
Nachdem Elasticsearch die von uns benötigte Suche durchgeführt und die Ergebnisse mit seinem (ziemlich schnellen) Algorithmus bewertet hat, werden wir die 1000 besten Ergebnisse verwenden und mithilfe unserer (relativ langsamen) maschinell erlernten Formel eine neue Rangfolge erstellen. Erfolg!
Fazit
Wir haben unsere minimalistische Webanwendung verwendet und sind von keiner Suchfunktion an sich zu einer skalierbaren Lösung mit vielen erweiterten Funktionen übergegangen. Das war nicht so einfach. Aber es ist auch nicht so schwierig! Die endgültige Anwendung befindet sich im Repository auf Github in einem Zweig mit einem bescheidenen Namen
feature/searchund erfordert Docker und Python 3 mit maschinellen Lernbibliotheken.
Ich habe Elasticsearch verwendet, um zu zeigen, wie dies im Allgemeinen funktioniert, welche Probleme auftreten und wie sie gelöst werden können, aber dies ist sicherlich nicht das einzige Tool, aus dem Sie auswählen können. Solr , PostgreSQL-Volltextindizes und andere Engines verdienen ebenfalls Ihre Aufmerksamkeit, wenn Sie auswählen, worauf Ihr
Und natürlich gibt diese Lösung nicht vor, vollständig und produktionsbereit zu sein, sondern ist nur ein Beispiel dafür, wie alles gemacht werden kann. Sie können es fast endlos verbessern!
- Inkrementelle Indizierung. Wenn Sie unsere Karten ändern, sollten
CardManagerSie sie sofort im Index aktualisieren. UmCardManagernicht zu wissen, dass wir auch eine Suche im Service haben und auf zyklische Abhängigkeiten verzichten möchten, müssen wir die Abhängigkeitsinversion in der einen oder anderen Form schrauben . - Für die Indizierung in unserem speziellen Fall, MongoDB-Bundles mit Elasticsearch, können Sie vorgefertigte Lösungen wie Mongo-Connector verwenden .
- , — Elasticsearch .
- , , .
- , , . -, -, - … !
- ( , ), ( ). , .
- , , .
- Das Orchestrieren eines Knotenclusters mit Sharding und Replikation ist ein ganz anderes Vergnügen.
Aber um den Artikel in seiner Größe lesbar zu halten, werde ich hier anhalten und Sie mit diesen Herausforderungen in Ruhe lassen. Vielen Dank für Ihre Aufmerksamkeit!