Prolog
Beginnen wir mit der Logikprogrammierung und der Prolog-Sprache. Das Wissen über den Themenbereich wird darin als eine Reihe von Fakten und Regeln dargestellt. Fakten beschreiben unmittelbares Wissen. Die Fakten zu Kunden (ID, Name und E-Mail-Adresse) und Rechnungen (Konto-ID, Kunde, Datum, fälliger Betrag und bezahlter Betrag) aus dem Beispiel aus dem vorherigen Beitrag würden folgendermaßen aussehen
client(1, "John", "john@somewhere.net").
bill(1, 1,"2020-01", 100, 50).Regeln beschreiben abstraktes Wissen, das aus anderen Regeln und Fakten abgeleitet werden kann. Die Regel besteht aus einem Kopf und einem Körper. Im Kopf der Regel müssen Sie den Namen und die Liste der Argumente angeben. Der Hauptteil einer Regel ist eine Liste von Prädikaten, die durch logische Operationen AND (durch Komma angegeben) und OR (durch ein Semikolon angegeben) verbunden sind. Prädikate können Fakten, Regeln oder integrierte Prädikate sein, z. B. Vergleichsoperationen, arithmetische Operationen usw. Die Beziehung zwischen den Argumenten des Regelkopfs und den Argumenten der Prädikate in seinem Hauptteil wird mithilfe von Booleschen Variablen festgelegt. Dies bedeutet, dass diese Argumente identisch sind. Eine Regel gilt als wahr, wenn der logische Ausdruck des Regelkörpers wahr ist. Das Domänenmodell kann als Satz von Referenzierungsregeln definiert werden:
unpaidBill(BillId, ClientId, Date, AmoutToPay, AmountPaid) :- bill(BillId, ClientId, Date, AmoutToPay, AmountPaid), AmoutToPay < AmountPaid.
debtor(ClientId, Name, Email) :- client(ClientId, Name, Email), unpaidBill(BillId, ClientId, _, _, _).Wir haben zwei Regeln festgelegt. Im ersten Fall behaupten wir, dass alle Rechnungen, die weniger als den fälligen Betrag haben, unbezahlte Rechnungen sind. Im zweiten Fall ist der Schuldner ein Kunde, der mindestens eine unbezahlte Rechnung hat.
Die Syntax von Prolog ist sehr einfach: Das Hauptelement des Programms ist die Regel, die Hauptelemente der Regel sind Prädikate, logische Operationen und Variablen. In der Regel konzentriert sich die Aufmerksamkeit auf Variablen - sie spielen die Rolle eines Objekts der modellierten Welt, und Prädikate beschreiben ihre Eigenschaften und die Beziehung zwischen ihnen. In der Definition der Schuldnerregel geben wir an, dass, wenn die Objekte ClientId, Name und E-Mail durch eine Kunden- und eine unbezahlte Rechnungsbeziehung verbunden sind, sie auch durch eine Schuldnerbeziehung verbunden sind. Prolog ist nützlich, wenn ein Problem als eine Reihe von Regeln, Anweisungen oder logischen Anweisungen formuliert wird. Zum Beispiel bei der Arbeit mit Grammatik in natürlicher Sprache, Compilern in Expertensystemen, bei der Analyse komplexer Systeme wie Computer, Computernetzwerke und Infrastrukturobjekte. Komplex,Verschachtelte Regelsysteme werden am besten explizit beschrieben und der Prolog-Laufzeit überlassen, um sie automatisch zu verarbeiten.
Prolog basiert auf Logik erster Ordnung (mit einigen Elementen der Logik höherer Ordnung). Die Inferenz wird unter Verwendung eines Verfahrens durchgeführt, das als SLD-Auflösung (Selective Linear Definite-Klauselauflösung) bezeichnet wird. Vereinfacht ausgedrückt ist sein Algorithmus eine Baumdurchquerung aller möglichen Lösungen. Die Inferenzprozedur findet alle Lösungen für das erste Prädikat des Regelkörpers. Wenn das aktuelle Prädikat in der Wissensbasis nur durch Fakten dargestellt wird, sind die Lösungen diejenigen, die den aktuellen Bindungen von Variablen an Werte entsprechen. Wenn nach Regeln, ist eine rekursive Überprüfung ihrer verschachtelten Prädikate erforderlich. Wenn keine Lösungen gefunden werden, schlägt der aktuelle Suchzweig fehl. Anschließend wird für jede gefundene Teillösung ein neuer Zweig erstellt. In jedem Zweig bindet die Inferenzprozedur die gefundenen Werte an Variablen.im aktuellen Prädikat enthalten und sucht rekursiv nach einer Lösung für die verbleibende Liste von Prädikaten. Die Arbeit endet, wenn das Ende der Prädikatenliste erreicht ist. Die Suche nach einer Lösung kann bei rekursiver Definition von Regeln in eine Endlosschleife eintreten. Das Ergebnis der Suchprozedur ist eine Liste aller möglichen Wertebindungen an boolesche Variablen.
Im obigen Beispiel für die Schuldnerregel findet die Auflösungsregel zunächst eine Lösung für das Client-Prädikat und ordnet sie Booleschen Werten zu: ClientId = 1, Name = "John", Email = "john@somewhere.net". Dann wird für diese Variante von Variablenwerten eine Lösung für das nächste Prädikat unpaidBill durchgeführt. Dazu müssen Sie zuerst Lösungen für die Prädikatrechnung finden, vorausgesetzt, ClientId = 1. Das Ergebnis sind Bindungen für die Variablen BillId = 1, Date = "2020-01", AmoutToPay = 100, AmountPaid = 50. Am Ende wird AmoutToPay <AmountPaid überprüft im eingebauten Vergleichsprädikat.
Semantische Netzwerke
Semantische Netzwerke sind eine der beliebtesten Arten, Wissen darzustellen. Das Semantic Web ist ein Informationsmodell eines Themenbereichs in Form eines gerichteten Graphen. Die Eckpunkte des Graphen entsprechen den Konzepten der Domäne, und die Bögen definieren die Beziehungen zwischen ihnen.
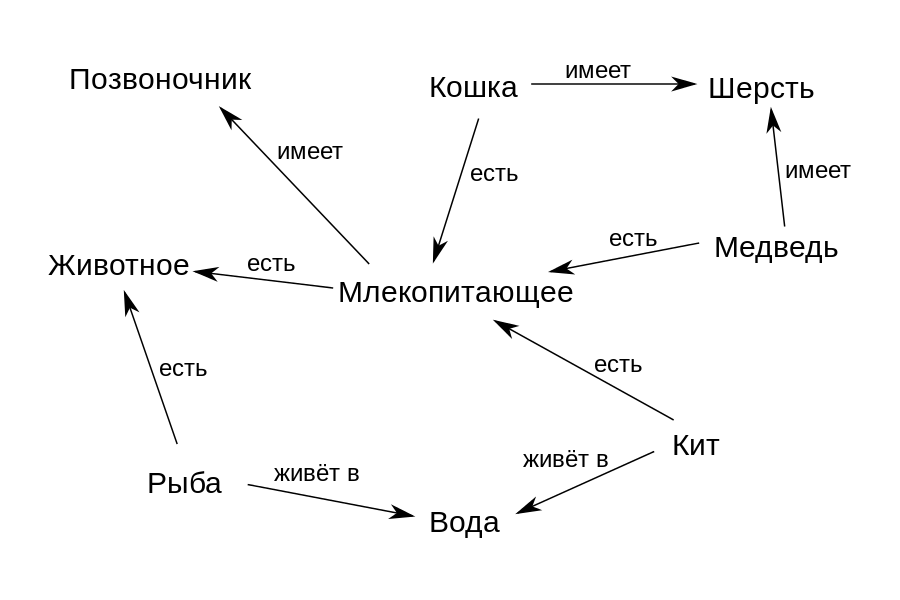
Zum Beispiel ist gemäß dem Diagramm in der obigen Abbildung das Konzept von "Wal" mit der Beziehung "ist" ("ist") mit dem Konzept von "Säugetier" verbunden und "lebt in" mit dem Konzept von "Wasser". Auf diese Weise können wir die Struktur des Themenbereichs formal festlegen - welche Konzepte darin enthalten sind und in welcher Beziehung sie zueinander stehen. Und dann kann ein solches Diagramm verwendet werden, um Antworten auf Fragen zu finden und daraus neues Wissen abzuleiten. Zum Beispiel können wir das Wissen ableiten, dass Whale "Spine" hat, wenn wir entscheiden, dass die Beziehung "is" eine Klassen-Unterklassen-Beziehung bezeichnet und die Unterklasse "Whale" alle Eigenschaften ihrer Klasse "Mammal" erben sollte.
RDF
Das Semantic Web ist ein Versuch, ein globales semantisches Netzwerk aufzubauen, das auf den Ressourcen des World Wide Web basiert, indem die Darstellung von Informationen in einer für die maschinelle Verarbeitung geeigneten Form standardisiert wird. Zu diesem Zweck werden Informationen zusätzlich in Form spezieller Attribute von HTML-Tags in HTML-Seiten eingebettet, wodurch die Bedeutung ihres Inhalts in Form einer Ontologie beschrieben werden kann - einer Reihe von Fakten, abstrakten Konzepten und Beziehungen zwischen ihnen.
Der Standardansatz zur Beschreibung des semantischen Modells von WEB-Ressourcen ist RDF (Resource Description Framework oder Resource Description Framework). Demnach müssen alle Aussagen die Form eines Tripletts "Subjekt - Prädikat - Objekt" haben. Zum Beispiel wird das Wissen über das Konzept des "Wals" wie folgt präsentiert: "Wal" ist ein Subjekt, "lebt in" - ein Prädikat, "Wasser" - ein Objekt. Der gesamte Satz solcher Anweisungen kann unter Verwendung eines gerichteten Graphen beschrieben werden, Subjekte und Objekte sind seine Eckpunkte, und Prädikate sind Bögen, Prädikatenbögen werden von Objekten zu Subjekten gerichtet. Zum Beispiel kann die Ontologie aus dem Tierbeispiel wie folgt beschrieben werden:
@prefix : <...some URL...>
@prefix rdf: <http://www.w3.org/1999/02/rdf-schema#>
@prefix rdfs: <http://www.w3.org/2000/01/22-rdf-syntax-ns#>
:Whale rdf:type :Mammal;
:livesIn :Water.
:Fish rdf:type :Animal;
:livesIn :Water.Diese Notation heißt Turtle und soll für den Menschen lesbar sein. Das Gleiche kann jedoch in XML-, JSON-Formaten oder unter Verwendung von Tags und Attributen eines HTML-Dokuments geschrieben werden. Obwohl in der Turtle-Notation Prädikate und Objekte zur besseren Lesbarkeit nach Subjekt gruppiert werden können, ist auf semantischer Ebene jedes Triplett unabhängig.
RDF ist nützlich in Fällen, in denen das Datenmodell komplex ist und eine große Anzahl von Objekttypen und Beziehungen zwischen ihnen enthält. Beispielsweise bietet Wikipedia Zugriff auf den Inhalt seiner Artikel im RDF-Format. Die in den Artikeln beschriebenen Fakten sind strukturiert, ihre Eigenschaften und Beziehungen werden beschrieben, einschließlich Fakten aus anderen Artikeln.
RDFS
Ein RDF-Modell ist ein Diagramm. Standardmäßig ist keine zusätzliche Semantik darin enthalten. Jeder kann die Links in der Grafik nach eigenem Ermessen interpretieren. Sie können einige Standardlinks mithilfe des RDF-Schemas hinzufügen - einer Reihe von Klassen und Eigenschaften zum Erstellen von Ontologien über RDF. Mit RDFS können Sie Standardbeziehungen zwischen Konzepten beschreiben, z. B. die Zugehörigkeit einer Ressource zu einer bestimmten Klasse, die Hierarchie zwischen Klassen, die Hierarchie der Eigenschaften und die möglichen Arten von Subjekten und Objekten einschränken.
Zum Beispiel die Aussage
:Mammal rdfs:subClassOf :Animal.gibt an, dass "Mammal" eine Unterklasse des Konzepts "Animal" ist und alle seine Eigenschaften erbt. Dementsprechend kann das Konzept des "Wals" auch der Klasse "Tier" zugeordnet werden. Dafür ist jedoch darauf hinzuweisen, dass die Begriffe "Säugetier" und "Tier" Klassen sind:
:Animal rdf:type rdfs:Class.
:Mammal rdf:type rdfs:Class.Das Prädikat kann auch Einschränkungen für die möglichen Werte seines Subjekts und Objekts festlegen.
Erklärung
:livesIn rdfs:range :Environment.gibt an, dass das Objekt der Beziehung "lebt in" immer eine Ressource sein sollte, die zur Klasse "Umgebung" gehört. Daher müssen wir eine Aussage hinzufügen, dass der Begriff "Wasser" eine Unterklasse des Begriffs "Umwelt" ist:
:Water rdf:type :Environment.
:Environment rdf:type rdfs:ClassMit RDFS können Sie das Datenschema beschreiben, um Klassen und Eigenschaften aufzulisten, ihre Hierarchie festzulegen und ihre Werte einzuschränken. Und RDF soll dieses Schema mit konkreten Fakten füllen und die Beziehung zwischen ihnen definieren. Jetzt können wir eine Frage zu diesem Diagramm stellen. Dies kann in einer speziellen Abfragesprache SPARQL erfolgen, die SQL ähnelt:
SELECT ?creature
WHERE {
?creature rdf:type :Animal;
:livesIn :Water.
} Diese Abfrage gibt uns 2 Werte zurück: "Whale" und "Fish".
Ein Beispiel aus früheren Veröffentlichungen mit Konten und Kunden kann ungefähr wie folgt implementiert werden. Mit RDF können Sie ein Datenschema beschreiben und mit Werten füllen:
:Client1 :name "John";
:email "john@somewhere.net".
:Client2 :name "Mary";
:email "mary@somewhere.net".
:Bill_1 :client :Client1;
:date "2020-01";
:amountToPay 100;
:amountPaid 50.
:Bill_2 :client :Client2;
:date "2020-01";
:amountToPay 80;
:amountPaid 80.Abstrakte Konzepte wie "Schuldner" und "Unbezahlte Rechnungen" aus dem ersten Artikel dieser Reihe umfassen jedoch arithmetische Operationen und Vergleiche. Sie passen nicht in die statische Struktur des semantischen Konzepts. Diese Konzepte können mithilfe von SPARQL-Abfragen ausgedrückt werden:
SELECT ?clientName ?clientEmail ?billDate ?amountToPay ?amountPaid
WHERE {
?client :name ?clientName;
:email ?clientEmail.
?bill :client ?client;
:date ?billDate;
:amountToPay ?amountToPay;
:amountPaid ?amountPaid.
FILTER(?amountToPay > ?amountPaid).
}Die WHERE-Klausel ist eine Liste von Dreifachmustern und Filterbedingungen. Boolesche Variablen können in Tripletts eingesetzt werden, deren Name mit dem "?" Die Aufgabe des Abfrageausführers besteht darin, alle möglichen Werte der Variablen zu finden, für die alle Triplettmuster im Diagramm enthalten wären und die Filterbedingungen erfüllt wären.
Im Gegensatz zu Prolog, wo Regeln zum Erstellen anderer Regeln verwendet werden können, ist eine Abfrage in RDF nicht Teil des Semantic Web. Eine Anfrage kann nicht als Datenquelle für eine andere Anfrage referenziert werden. Richtig, SPARQL kann Abfrageergebnisse als Diagramm darstellen. Sie können also versuchen, die Abfrageergebnisse mit dem ursprünglichen Diagramm zu kombinieren und die neue Abfrage für das kombinierte Diagramm auszuführen. Eine solche Entscheidung würde jedoch eindeutig über die Ideologie der RDF hinausgehen.
EULE
Ein wichtiger Bestandteil der Semantic Web-Technologien ist OWL (Web Ontology Language) - eine Sprache zur Beschreibung von Ontologien. Mit dem RDFS-Vokabular können Sie nur die grundlegendsten Beziehungen zwischen Konzepten ausdrücken - die Hierarchie von Klassen und Beziehungen. OWL bietet einen viel reichhaltigeren Wortschatz. Beispielsweise können Sie angeben, dass zwei Klassen (oder zwei Entitäten) gleichwertig (oder unterschiedlich) sind. Diese Aufgabe tritt häufig beim Kombinieren von Ontologien auf.
Sie können zusammengesetzte Klassen basierend auf dem Schnittpunkt, der Vereinigung oder dem Hinzufügen anderer Klassen erstellen:
- Im Schnitt müssen alle Instanzen einer zusammengesetzten Klasse auch für alle Quellklassen gelten. Zum Beispiel muss "Marine Mammal" gleichzeitig "Mammal" und "Sea Dweller" sein.
- . , , «» «», «» «». «».
- , . , «» «».
- . , .
- — , .
Solche Ausdrücke, mit denen Sie Konzepte miteinander verknüpfen können, werden als Konstruktoren bezeichnet.
Mit OWL können Sie auch viele wichtige Beziehungseigenschaften festlegen:
- Transitivität. Wenn die Beziehungen P (x, y) und P (y, z) gelten, ist auch die Beziehung P (x, z) erfüllt. Beispiele für solche Beziehungen sind "Mehr" - "Weniger", "Eltern" - "Kind" usw.
- Symmetrie. Wenn die Beziehung P (x, y) erfüllt ist, ist auch die Beziehung P (y, x) erfüllt. Zum Beispiel eine relative Beziehung.
- Funktionale Abhängigkeit. Wenn die Beziehungen P (x, y) und P (x, z) gelten, müssen die Werte von y und z identisch sein. Ein Beispiel ist die Vaterbeziehung - eine Person kann nicht zwei verschiedene Väter haben.
- Umkehrung der Beziehungen. Sie können angeben, dass, wenn die Beziehung P1 (x, y) erfüllt ist, eine weitere Beziehung P2 (y, x) erfüllt sein muss. Ein Beispiel für eine solche Beziehung ist die Eltern-Kind-Beziehung.
- Beziehungsketten. Sie können angeben, dass A (oder C) zu einer bestimmten Klasse gehört, wenn A einer Eigenschaft mit B und B - mit C zugeordnet ist. Wenn zum Beispiel A einen Vater für B hat und Vater B seinen Vater C hat, dann ist A der Enkel von C.
Sie können auch Einschränkungen für die Werte der Argumente von Beziehungen festlegen. Geben Sie beispielsweise an, dass Argumente immer zu einer bestimmten Klasse gehören müssen oder dass eine Klasse mindestens eine Beziehung eines bestimmten Typs haben muss, oder begrenzen Sie die Anzahl der Beziehungen dieses Typs für diese Klasse. Oder Sie können angeben, dass alle Instanzen, die durch eine bestimmte Beziehung zu einem bestimmten Wert verknüpft sind, zu einer bestimmten Klasse gehören.
OWL ist jetzt das De-facto-Standardwerkzeug zum Erstellen von Ontologien. Diese Sprache eignet sich besser zum Erstellen großer und komplexer Ontologien als RDFS. Mit der OWL-Syntax können Sie mehr unterschiedliche Eigenschaften von Konzepten und deren Beziehungen ausdrücken. Es führt jedoch auch eine Reihe zusätzlicher Einschränkungen ein. Beispielsweise kann dasselbe Konzept nicht gleichzeitig als Klasse und als Instanz einer anderen Klasse deklariert werden. OWL-Ontologien sind strenger, standardisierter und daher besser lesbar. Wenn RDFS nur ein paar zusätzliche Klassen über einem RDF-Diagramm sind, hat OWL eine andere mathematische Basis - die Beschreibungslogik. Dementsprechend werden formale Inferenzverfahren verfügbar, mit denen Sie neue Informationen aus OWL-Ontologien extrahieren, deren Konsistenz überprüfen und Fragen beantworten können.
Beschreibende Logik ist ein Stück Logik erster Ordnung. Darin sind nur Prädikate mit einer Stelle (z. B. ein Konzept gehört zu einer Klasse), Prädikate mit zwei Stellen (ein Konzept hat eine Eigenschaft und ihren Wert) sowie die oben aufgeführten Klassenkonstruktoren und Beziehungseigenschaften zulässig. Alle anderen Ausdrücke der Logik erster Ordnung in der beschreibenden Logik wurden verworfen. Beispielsweise sind die Aussagen, dass das Konzept der "nicht bezahlten Rechnung" zur Klasse "Rechnung" gehört, das Konzept der "Rechnung" die Eigenschaften "Zu zahlender Betrag" und "Zu zahlender Betrag" akzeptabel. Es kann jedoch nicht funktionieren, eine Erklärung abzugeben, dass das Konzept der Eigenschaft "Unbezahlter Rechnungsbetrag" "Zu zahlender Betrag" größer sein sollte als die Eigenschaft "Bezahlter Betrag". Dies erfordert eine Regel, die ein Prädikat zum Vergleichen dieser Eigenschaften enthält. Leider,Die OWL-Konstruktoren erlauben dies nicht.
Somit ist die Ausdruckskraft der beschreibenden Logik geringer als die der Logik erster Ordnung. Andererseits sind Inferenzalgorithmen in der deskriptiven Logik viel schneller. Darüber hinaus besitzt es die Eigenschaft der Entscheidbarkeit - die Lösung kann garantiert in einer begrenzten Zeit gefunden werden. Es wird angenommen, dass ein solches Vokabular in der Praxis völlig ausreicht, um komplexe und umfangreiche Ontologien aufzubauen, und OWL ist ein guter Kompromiss zwischen Ausdruckskraft und Inferenz-Effizienz.
Erwähnenswert ist auch SWRL (Semantic Web Rule Language), das die Möglichkeit zum Erstellen von Klassen und Eigenschaften in OWL mit dem Schreiben von Regeln in einer eingeschränkten Version der Datalog-Sprache kombiniert. Der Stil dieser Regeln ist der gleiche wie in Prolog. SWRL unterstützt integrierte Prädikate für Vergleichs-, Mathematik-, Zeichenfolgen-, Datums- und Listenmanipulationen. Genau das hat uns gefehlt, um das Konzept der "unbezahlten Rechnung" mit Hilfe eines einfachen Ausdrucks umzusetzen.
Flora-2
Betrachten Sie als Alternative zu semantischen Netzwerken eine Technologie wie Frames. Ein Rahmen ist eine Struktur, die ein komplexes Objekt, ein abstraktes Bild, ein Modell von etwas beschreibt. Es besteht aus einem Namen, einer Reihe von Eigenschaften (Merkmalen) und deren Werten. Der Eigenschaftswert kann ein anderer Frame sein. Die Eigenschaft kann auch einen Standardwert haben. Eine Funktion zur Berechnung ihres Werts kann an eine Eigenschaft angehängt werden. Ein Frame kann auch Serviceprozeduren enthalten, einschließlich Handler für solche Ereignisse, z. B. Erstellen, Löschen eines Frames, Ändern des Werts von Eigenschaften usw. Eine wichtige Eigenschaft von Frames ist die Fähigkeit zum Erben. Der untergeordnete Frame enthält alle Eigenschaften der übergeordneten Frames.
Das System der verknüpften Frames bildet ein semantisches Netzwerk, das einem RDF-Graphen sehr ähnlich ist. Bei der Erstellung von Ontologien wurden Frames jedoch durch die OWL-Sprache ersetzt, die heute de facto der Standard ist. OWL ist ausdrucksstärker, hat eine fortgeschrittenere theoretische Grundlage - formale beschreibende Logik. Im Gegensatz zu RDF und OWL, bei denen die Eigenschaften von Konzepten unabhängig voneinander beschrieben werden, werden im Rahmenmodell das Konzept und seine Eigenschaften als ein einziges Ganzes betrachtet - der Rahmen. Während in RDF- und OWL-Modellen die Scheitelpunkte des Diagramms die Namen von Konzepten enthalten und die Kanten ihre Eigenschaften enthalten, enthalten die Scheitelpunkte des Diagramms im Rahmenmodell Konzepte mit all ihren Eigenschaften, und die Kanten enthalten Verbindungen zwischen ihren Eigenschaften oder Vererbungsbeziehungen zwischen Konzepten.
Dabei kommt das Rahmenmodell dem objektorientierten Programmiermodell sehr nahe. Sie sind weitgehend gleich, haben jedoch einen anderen Umfang - Frames zielen darauf ab, ein Netzwerk von Konzepten und Beziehungen zwischen ihnen zu modellieren, und OOP - darauf, das Verhalten von Objekten und ihre Interaktion miteinander zu modellieren. Daher bietet OOP zusätzliche Mechanismen, um die Implementierungsdetails einer Komponente vor anderen zu verbergen und den Zugriff auf Methoden und Felder einer Klasse einzuschränken.
Moderne Framing-Sprachen (wie KL-ONE, PowerLoom, Flora-2) kombinieren die zusammengesetzten Datentypen des Objektmodells mit Logik erster Ordnung. In diesen Sprachen können Sie nicht nur die Struktur von Objekten beschreiben, sondern auch mit diesen Objekten in Regeln arbeiten, Regeln erstellen, die die Bedingungen beschreiben, unter denen ein Objekt zu einer bestimmten Klasse gehört usw. Die Mechanismen der Vererbung und Zusammensetzung von Klassen erhalten eine logische Interpretation, die für Inferenzverfahren zur Verfügung steht. Diese Sprachen sind ausdrucksvoller als OWL und nicht auf Prädikate mit zwei Stellen beschränkt.
Versuchen wir als Beispiel, unser Beispiel mit Schuldnern in der Flora-2- Sprache umzusetzen... Diese Sprache enthält drei Komponenten: die F-Logik-Rahmenlogik, die Rahmen und Logik erster Ordnung kombiniert, die Logik höherer Ordnung HiLog, die Werkzeuge zum Bilden von Anweisungen über die Struktur anderer Anweisungen und die Metaprogrammierung bereitstellt, und die Transaktionslogik-Änderungslogik, die in logischer Form zulässig ist beschreiben Datenänderungen und Nebenwirkungen von Berechnungen. Jetzt interessiert uns nur noch die F-Logik- Rahmenlogik . Zunächst werden wir damit die Struktur von Frames deklarieren, die die Konzepte (Klassen) von Kunden und Schuldnern beschreiben:
client[|name => \string,
email => \string
|].
bill[|client => client,
date => \string,
amountToPay => \number,
amountPaid => \number,
amountPaid -> 0
|].Jetzt können wir Instanzen (Objekte) dieser Konzepte deklarieren:
client1 : client[name -> 'John', email -> 'john@somewhere.net'].
client2 : client[name -> 'Mary', email -> 'mary@somewhere.net'].
bill1 : bill[client -> client1,
date -> '2020-01',
amountToPay -> 100
].
bill2 : bill[client -> client2,
date -> '2020-01',
amountToPay -> 80,
amountPaid -> 80
].Das Symbol '->' bedeutet die Zuordnung eines Attributs zu einem bestimmten Wert in einem Objekt und einem Standardwert in einer Klassendeklaration. In unserem Beispiel hat das Feld amountPaid der Rechnungsklasse den Standardwert Null. Das Symbol ':' bedeutet, dass eine Entität der Klasse erstellt wird: client1 und client2 sind Entitäten der Clientklasse.
Jetzt können wir erklären, dass die Konzepte "Unbezahlte Rechnung" und "Schuldner" Unterklassen der Konzepte "Konto" und "Kunde" sind:
unpaidBill :: bill.
debtor :: client.Das Symbol '::' deklariert eine Vererbungsbeziehung zwischen Klassen. Die Struktur der Klasse wird vererbt, Methoden und Standardwerte für alle ihre Felder. Es bleiben die Regeln zu deklarieren, in denen die Zugehörigkeit zu den Klassen unbezahlte Rechnungen und Schuldner angegeben ist:
?x : unpaidBill :- ?x : bill[amountToPay -> ?a, amountPaid -> ?b], ?a > ?b.
?x : debtor :- ?x : client, ?_ : unpaidBill[client -> ?x]. Die erste Anweisung besagt, dass eine Variable
?eine UnpaidBill-Entität ist, wenn es sich um eine Rechnungsentität handelt und das Feld amountToPay größer als amountPaid ist. Im zweiten ?Fall , was zur unpaidBill-Klasse gehört, wenn es zur Client-Klasse gehört und mindestens eine Entität der unpaidBill-Klasse vorhanden ist, in der der Wert des Client-Felds einer Variablen entspricht ?. Diese Entität der unpaidBill-Klasse wird einer anonymen Variablen zugeordnet ?_, deren Wert nicht weiter verwendet wird.
Sie können eine Liste der Schuldner mit der Abfrage erhalten:
?- ?x:debtor.Wir bitten Sie, alle Werte zu finden, die sich auf die Schuldnerklasse beziehen. Das Ergebnis ist eine Liste aller möglichen Werte für die Variable
?x:
?x = client1Die Rahmenlogik kombiniert die Sichtbarkeit eines objektorientierten Modells mit der Kraft der Logikprogrammierung. Dies ist praktisch, wenn Sie mit Datenbanken arbeiten, komplexe Systeme modellieren und unterschiedliche Daten integrieren - in Fällen, in denen Sie sich auf die Struktur von Konzepten konzentrieren müssen.
SQL
Schauen wir uns zum Schluss die Hauptfunktionen der SQL-Syntax an. In der letzten Veröffentlichung haben wir gesagt, dass SQL eine logische theoretische Grundlage hat - die relationale Berechnung - und die Implementierung des Beispiels mit Schuldnern in LINQ in Betracht gezogen. In Bezug auf die Semantik kommt SQL Framing-Sprachen und OOP-Modellen sehr nahe. In einem relationalen Datenmodell ist das Hauptelement eine Tabelle, die als Ganzes und nicht als Satz separater Eigenschaften wahrgenommen wird.
Die SQL-Syntax passt perfekt zu dieser Tabellenorientierung. Die Anfrage ist in Abschnitte unterteilt. Die Entitäten des Modells, die durch Tabellen, Ansichten und verschachtelte Abfragen dargestellt werden, wurden in den Abschnitt FROM verschoben. Verknüpfungen zwischen ihnen werden mithilfe von JOIN-Operationen angegeben. Abhängigkeiten zwischen Feldern und anderen Bedingungen finden Sie in den WHERE- und HAVING-Klauseln. Anstelle von booleschen Variablen, die Prädikatargumente binden, bearbeiten wir Tabellenfelder direkt in der Abfrage. Diese Syntax beschreibt die Struktur des Domänenmodells klarer als die „lineare“ Prolog-Syntax.
Wie ich den Syntaxstil der Modellierungssprache sehe
Anhand des Beispiels für unbezahlte Rechnungen können wir Ansätze wie Logikprogrammierung (Prolog), Rahmenlogik (Flora-2), Semantic-Web-Technologien (RDFS, OWL und SWRL) und relationale Berechnung (SQL) vergleichen. Ich habe ihre Hauptmerkmale in einer Tabelle zusammengefasst:
| Sprache | Mathematische Basis | Stilorientierung | Geltungsbereich |
|---|---|---|---|
| Prolog | Logik erster Ordnung | Auf die Regeln | Regelbasierte Systeme, Mustervergleich. |
| RDFS | Graph | Über die Verbindung zwischen Konzepten | WEB-Ressourcendatenschema |
| EULE | Beschreibende Logik | Über die Verbindung zwischen Konzepten | Ontologien |
| SWRL | Eine abgespeckte Version der Logik erster Ordnung von Datalog | Über Regeln über Verknüpfungen zwischen Konzepten | Ontologien |
| Flora-2 | Frames + Logik erster Ordnung | Über Regeln über der Objektstruktur | Datenbanken, Modellierung komplexer Systeme, Integration unterschiedlicher Daten |
| SQL | Beziehungsrechnung | Auf Tischstrukturen | Datenbank |
Jetzt müssen Sie die mathematische Basis und den Syntaxstil für eine Modellierungssprache finden, die für die Arbeit mit halbstrukturierten Daten und die Integration von Daten aus unterschiedlichen Quellen ausgelegt ist und mit objektorientierten und funktionalen Programmiersprachen für allgemeine Zwecke kombiniert wird.
Die ausdrucksstärksten Sprachen sind Prolog und Flora-2 - sie basieren auf einer vollständigen Logik erster Ordnung mit Elementen höherer Logik. Der Rest der Ansätze sind Teilmengen davon. Mit Ausnahme von RDFS hat dies überhaupt nichts mit formaler Logik zu tun. In diesem Stadium scheint mir eine vollwertige Logik erster Ordnung die bevorzugte Option zu sein. Zunächst habe ich vor, darüber nachzudenken. Die eingeschränkte Option in Form eines relationalen Kalküls oder einer deduktiven Datenbanklogik hat aber auch ihre Vorteile. Es bietet eine hervorragende Leistung bei der Arbeit mit großen Datenmengen. Es sollte in Zukunft separat betrachtet werden. Die beschreibende Logik scheint zu begrenzt und nicht in der Lage zu sein, dynamische Beziehungen zwischen Konzepten auszudrücken.
Aus meiner Sicht ist die Rahmenlogik für die Arbeit mit halbstrukturierten Daten und die Integration unterschiedlicher Datenquellen besser geeignet als der regelorientierte Prolog oder OWL, der sich auf Beziehungen und Konzeptklassen konzentriert. Das Rahmenmodell beschreibt explizit die Strukturen von Objekten und lenkt die Aufmerksamkeit auf sie. Bei Objekten mit vielen Eigenschaften ist die Rahmenform viel besser lesbar als Regeln oder Triplets für Subjekteigenschaften und Objekte. Vererbung ist auch ein sehr nützlicher Mechanismus, der die Menge an sich wiederholendem Code drastisch reduzieren kann. Im Vergleich zum relationalen Modell können Sie mit der Rahmenlogik komplexe Datenstrukturen wie Bäume und Diagramme auf natürlichere Weise beschreiben. Und das Wichtigste:Die Nähe des Rahmenmodells der Wissensbeschreibung zum OOP-Modell ermöglicht die natürliche Integration in eine Sprache.
Ich möchte eine Abfragestruktur aus SQL ausleihen. Die Definition eines Konzepts kann eine komplexe Form haben und es schadet nicht, es in Abschnitte zu unterteilen, um seine Bestandteile hervorzuheben und die Wahrnehmung zu erleichtern. Für die meisten Entwickler ist die SQL-Syntax ziemlich vertraut.
Daher möchte ich die Rahmenlogik als Grundlage für die Modellierungssprache verwenden. Da das Ziel jedoch darin besteht, Datenstrukturen zu beschreiben und unterschiedliche Datenquellen zu integrieren, werde ich versuchen, die regelorientierte Syntax aufzugeben und durch eine strukturierte Version zu ersetzen, die aus SQL entlehnt wurde. Das Hauptelement des Domänenmodells wird ein "Konzept" (Konzept) sein. In seine Definition möchte ich alle Informationen aufnehmen, die zum Extrahieren seiner Entitäten aus den Quelldaten erforderlich sind:
- der Name des Konzepts;
- eine Reihe seiner Attribute;
- () , ;
- , ;
- , .
Die Definition des Konzepts ähnelt einer SQL-Abfrage. Und das gesamte Domänenmodell wird in Form miteinander verbundener Konzepte vorliegen.
Ich plane, die resultierende Syntax der Modellierungssprache in der nächsten Veröffentlichung zu zeigen. Für diejenigen, die sich jetzt damit vertraut machen möchten, gibt es hier einen vollständigen Text in wissenschaftlichem Stil in englischer Sprache:
Hybrid Ontology-Oriented Programming für die halbstrukturierte Datenverarbeitung
Links zu früheren Veröffentlichungen:
Entwerfen einer Programmiersprache mit mehreren Paradigmen. Teil 1 - Wofür ist es?
Wir entwerfen eine Multi-Paradigma-Programmiersprache. Teil 2 - Vergleich der Modellbildung in PL / SQL, LINQ und GraphQL