Transformator-basierten Modelle haben hervorragende Ergebnisse in einer Vielzahl von Disziplinen erreicht, einschließlich Konversations AI , natürliche Sprachverarbeitung , Bildverarbeitung , und sogar Musik . Die Hauptkomponente jeder Architektur ist das Transformers- Aufmerksamkeitsmodul (Aufmerksamkeitsmodul), das die Ähnlichkeit für alle Paare in der Eingabesequenz berechnet. Es skaliert jedoch nicht gut mit der Zunahme der Länge der Eingabesequenz, was eine quadratische Zunahme der Rechenzeit erfordert, um alle Ähnlichkeitsschätzungen zu erhalten, sowie eine quadratische Zunahme der Speichermenge, die zum Erstellen einer Matrix zum Speichern dieser Schätzungen verwendet wird.
Für Anwendungen, die eine erweiterte Aufmerksamkeit erfordern, wurden mehrere schnellere und kompaktere Proxys vorgeschlagen, wie z. B. Speicher-Caching-Techniken . Die üblichere Lösung besteht jedoch darin, eine geringe Aufmerksamkeit zu verwenden . Eine geringe Aufmerksamkeit reduziert die Rechenzeit und den Speicherbedarf für den Aufmerksamkeitsmechanismus, indem nur eine begrenzte Anzahl von Ähnlichkeitsbewertungen aus einer Sequenz und nicht aus allen möglichen Paaren berechnet wird, was eher zu einer spärlichen als zu einer vollständigen Matrix führt. Diese spärlichen Vorkommen können manuell vorgeschlagen, mithilfe von Optimierungstechniken ermittelt, erlernt oder sogar randomisiert werden, wie Techniken wie Sparse Transformers , Longformers zeigen, Routing-Transformatoren , Reformatoren und Big Bird . Da spärliche Matrizen auch durch Graphen und Kanten dargestellt werden können , werden spärliche Methoden auch durch die Literatur zu neuronalen Netzen von Graphen motiviert , insbesondere hinsichtlich des in Graph Attention Networks beschriebenen Aufmerksamkeitsmechanismus. Solche Sparsity-Architekturen erfordern typischerweise zusätzliche Schichten, um implizit einen vollständigen Aufmerksamkeitsmechanismus zu erzeugen.
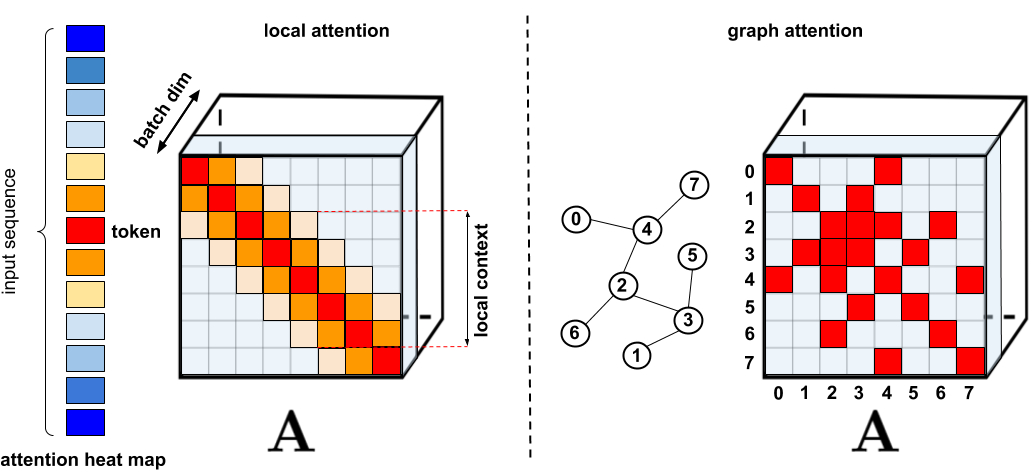
. : , . : Graph Attention Networks, , , . . « : » .
, . (1) , ; (2) ; (3) , , ; (4) , , . , , , Pointer Networks. , , , (softmax), .
, Performer, , . , , , ImageNet64, , PG-19. Performer () , , () . (Fast Attention Via Positive Orthogonal Random Features, FAVOR+), . ( , -). , .
, , , . , - . , , .
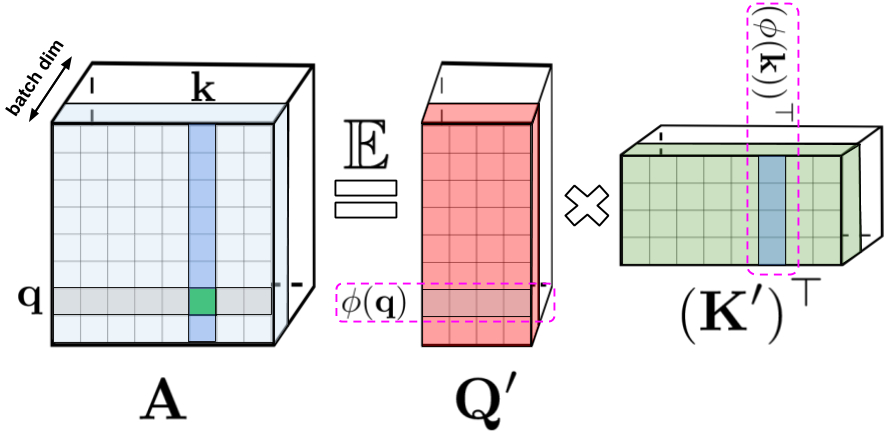
: , , , q k. : Q' K' , /. - , .
, , . , , , , -.
FAVOR+:
, . , . , , . , FAVOR+.
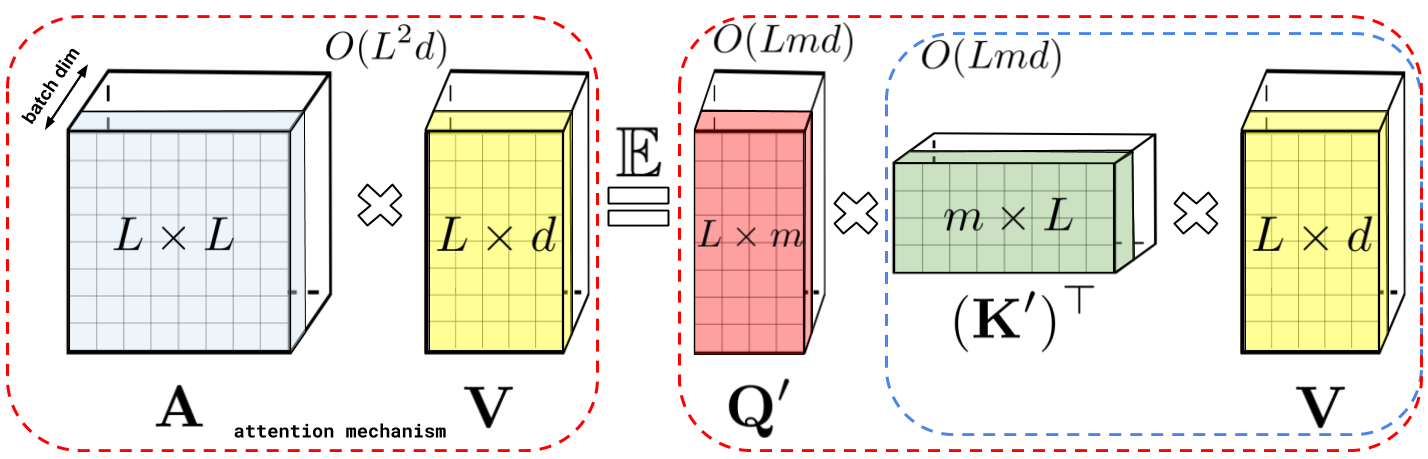
: , A V. : Q' K', A , , , , A .
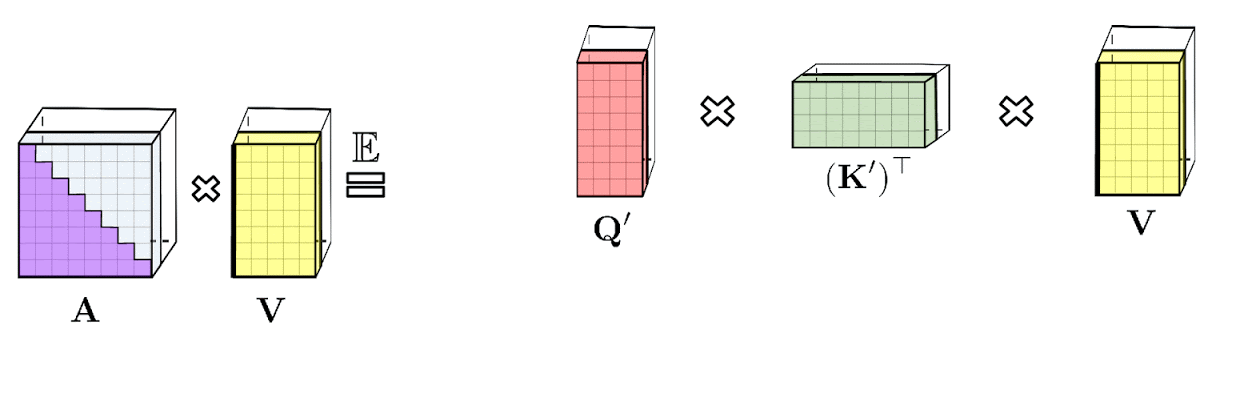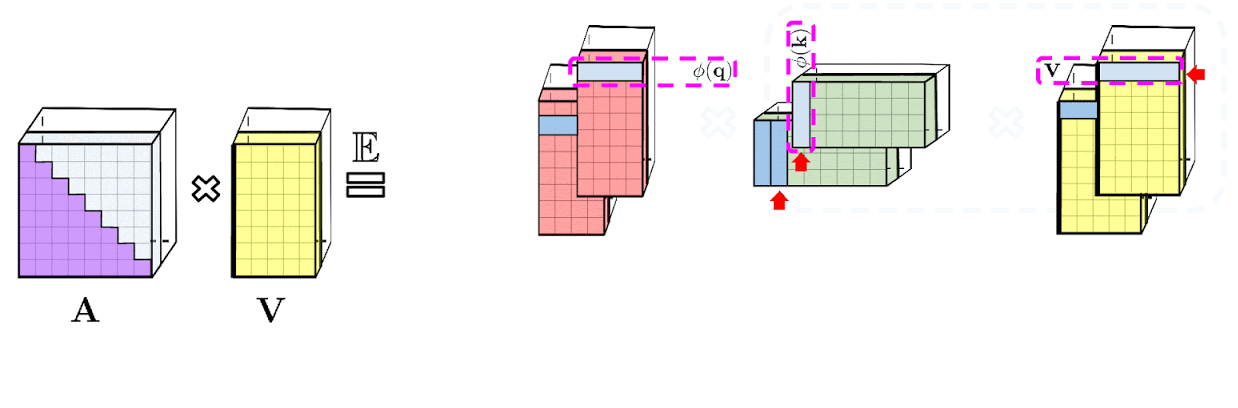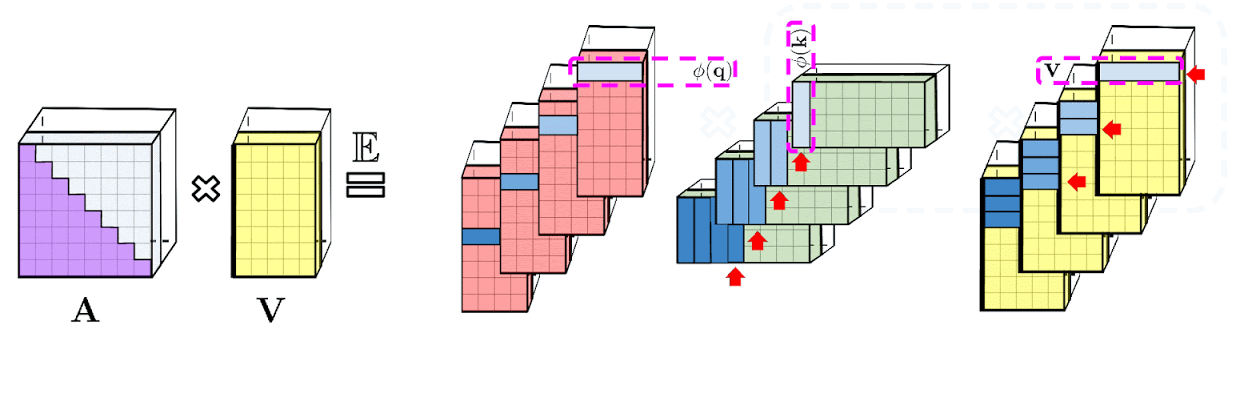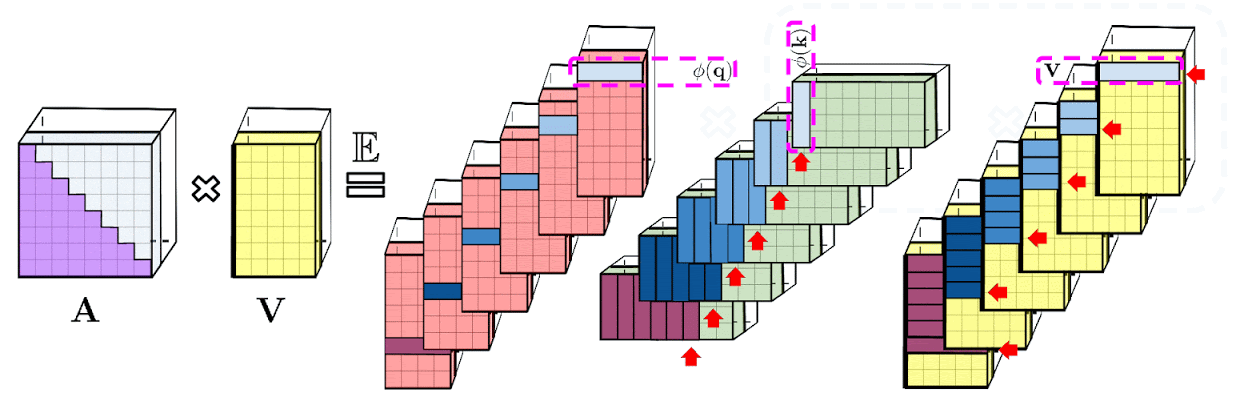
: , . : , .
Performer , , , .
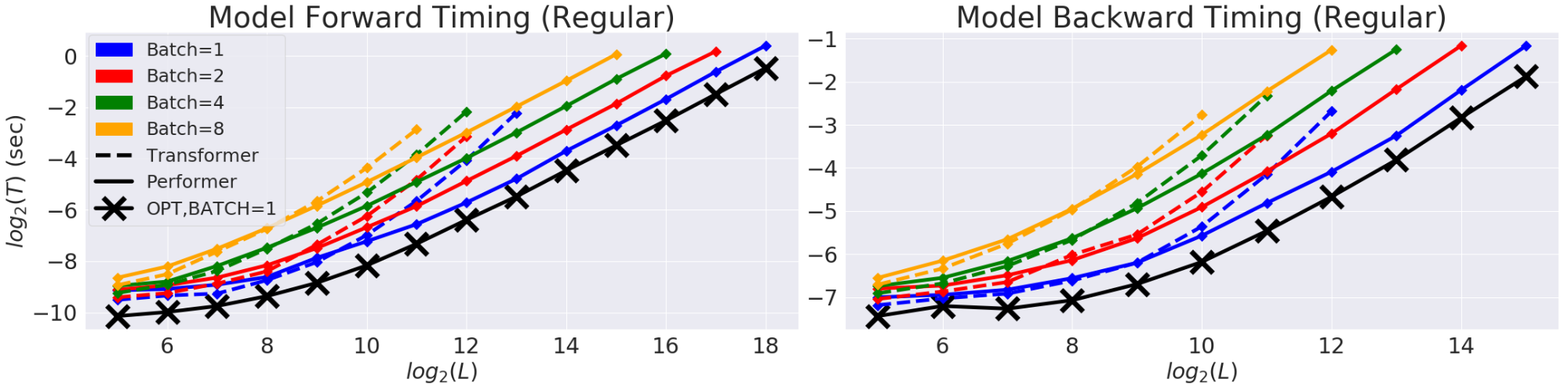
(T) (L). GPU. (X) «» , , , . Performer .
, Performer, -, , .
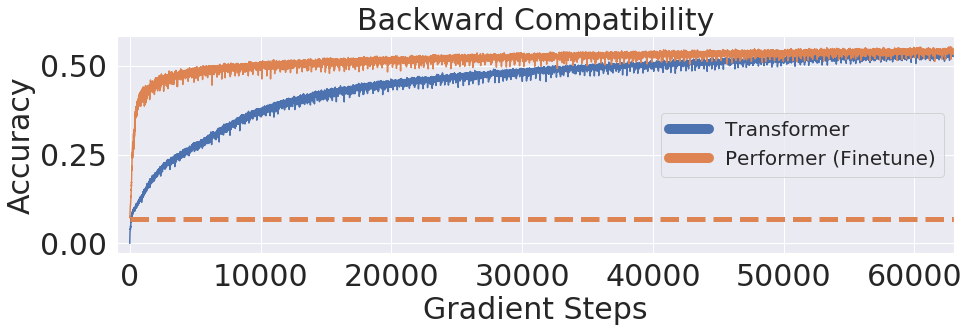
One Billion Word Benchmark (LM1B), Performer, 0.07 ( ). Performer .
:
— , . , , 20 . (, UniRef) , . Performer-ReLU ( ReLU, , ) , Performer-Softmax (accuracy) , .
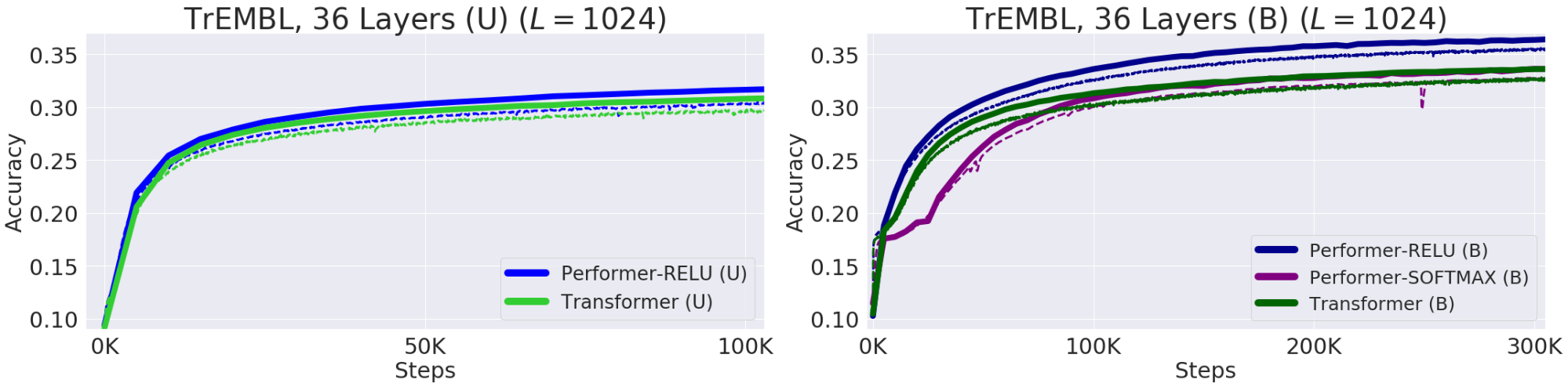
. (Train) — , (Validation) – , — (U), — (B). 36 ProGen (2019) , 16x16 TPU-v2. .
Protein Performer, ReLU. Performer , , . , , . Performer' . , , Performer - .
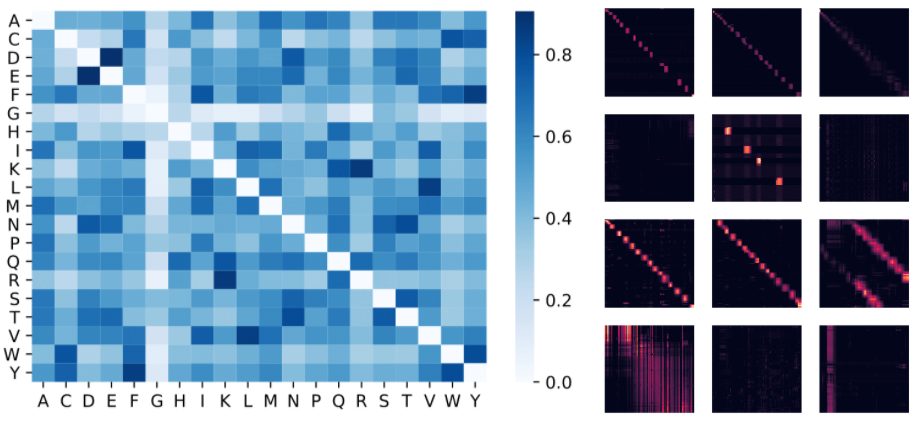
: , . , (D, E) (F, Y), . : 4 () 3 «» () BPT1_BOVIN, .
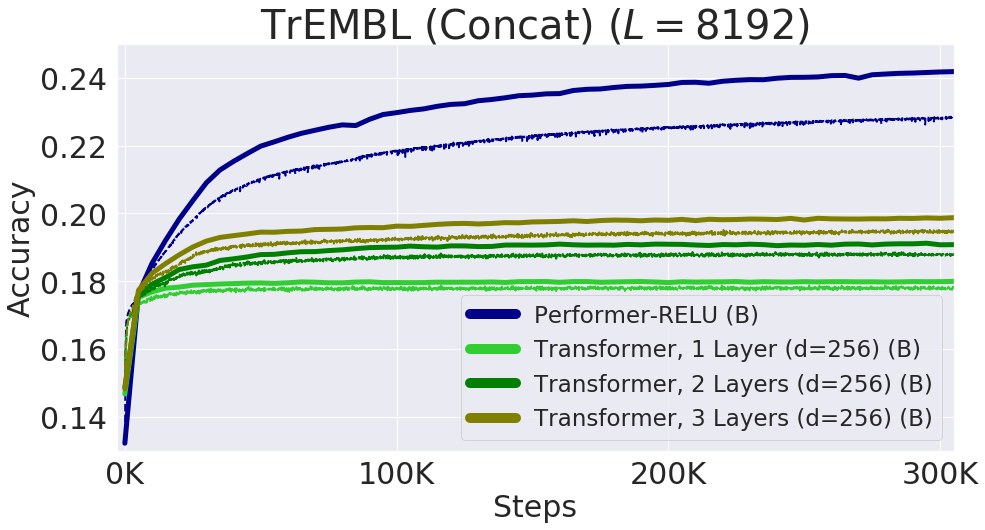
8192, . TPU, ( ) .
, . , , FAVOR Reformer. , Performer' . , , .
- — Krzysztof Choromanski, Lucy Colwell
- —
- Bearbeitung und Layout - Sergey Shkarin